
使用 Spring AI Aliabab Module RAG 构建 Web Search 应用

使用 Spring AI Alibaba 构建大模型联网搜索应用
Spring AI 实现了模块化 RAG 架构,架构的灵感来自于论文“模块化 RAG:将 RAG 系统转变为类似乐高的可重构框架”中详述的模块化概念。
Spring AI 模块化 RAG 体系
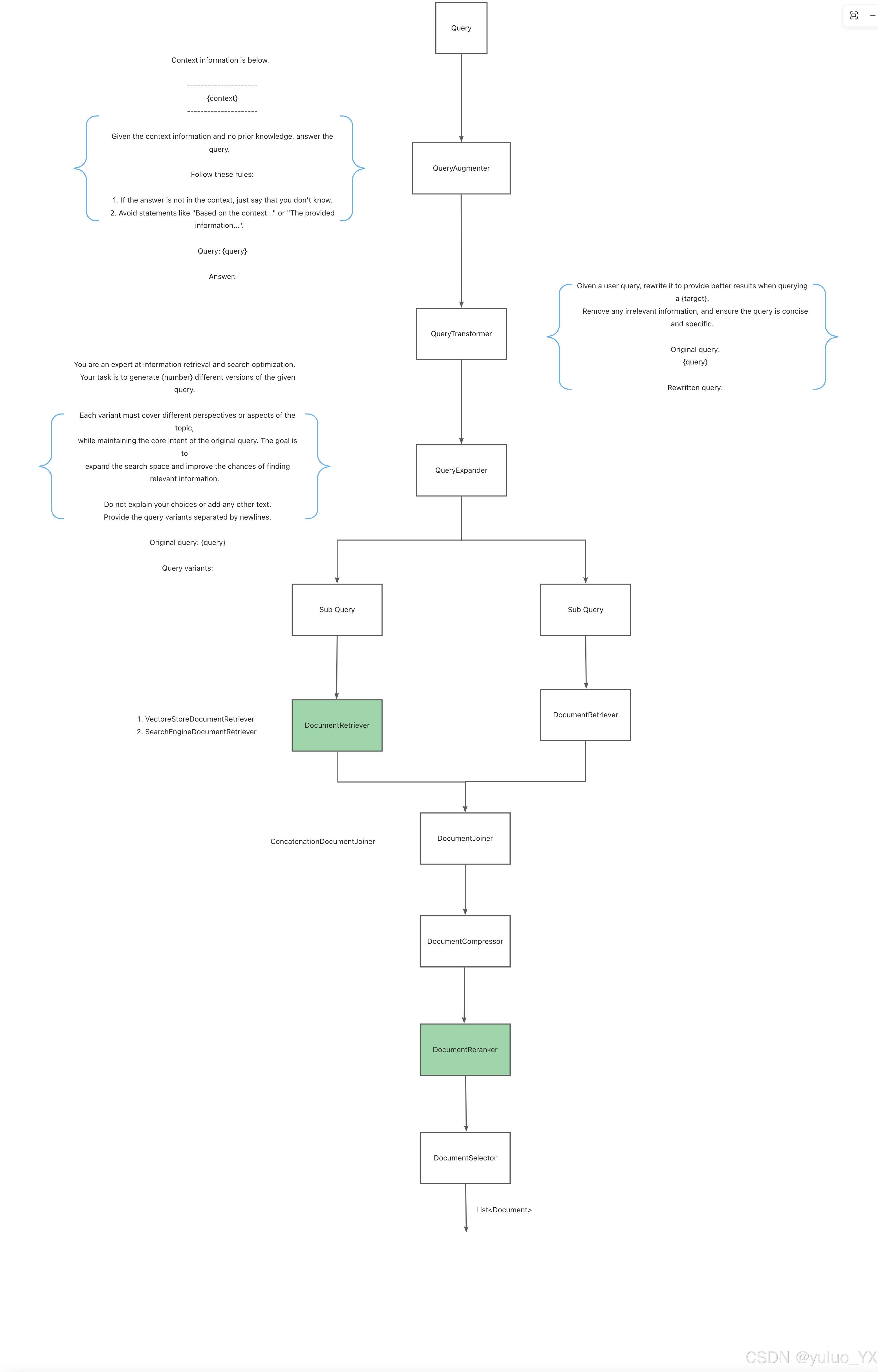
总体上分为以下几个步骤:
Pre-Retrieval
增强和转换用户输入,使其更有效地执行检索任务,解决格式不正确的查询、query 语义不清晰、或不受支持的语言等。
- QueryAugmenter 查询增强:使用附加的上下文数据信息增强用户 query,提供大模型回答问题时的必要上下文信息;
- QueryTransformer 查询改写:因为用户的输入通常是片面的,关键信息较少,不便于大模型理解和回答问题。因此需要使用 prompt 调优手段或者大模型改写用户 query;
- QueryExpander 查询扩展:将用户 query 扩展为多个语义不同的变体以获得不同视角,有助于检索额外的上下文信息并增加找到相关结果的机会。
Retrieval
负责查询向量存储等数据系统并检索和用户 query 相关性最高的 Document。
- DocumentRetriever:检索器,根据 QueryExpander 使用不同的数据源进行检索,例如 搜索引擎、向量存储、数据库或知识图等;
- DocumentJoiner:将从多个 query 和从多个数据源检索到的 Document 合并为一个 Document 集合;
Post-Retrieval
负责处理检索到的 Document 以获得最佳的输出结果,解决模型中的中间丢失和上下文长度限制等。
- DocumentRanker:根据 Document 和用户 query 的相关性对 Document 进行排序和排名;
- DocumentSelector:用于从检索到的 Document 列表中删除不相关或冗余文档;
- DocumentCompressor:用于压缩每个 Document,减少检索到的信息中的噪音和冗余。
生成
生成用户 Query 对应的大模型输出。
Web Search 实践
接下来,将演示如何使用 Spring AI Alibaba 和阿里云 IQS 服务搭建联网搜索 RAG 的实现。
资源准备
DashScope apiKey:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
阿里云 IQS 服务 apiKey:https://help.aliyun.com/product/2837261.html
Pre-Retrieval
将用户 Query 使用 qwen-plus 大模型进行增强改写。
CustomContextQueryAugmenter.java
public class CustomContextQueryAugmenter implements QueryAugmenter {
// 定义 prompt tmpl。
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate(
// ......
);
private static final PromptTemplate DEFAULT_EMPTY_PROMPT_TEMPLATE = new PromptTemplate(
// ...
);
@NotNull
@Override
public Query augment(
@Nullable Query query,
@Nullable List documents
) {
// 1. collect content from documents.
AtomicInteger idCounter = new AtomicInteger(1);
String documentContext = documents.stream()
.map(document -> {
String text = document.getText();
return "[[" + (idCounter.getAndIncrement()) + "]]" + text;
})
.collect(Collectors.joining("\n-----------------------------------------------\n"));
// 2. Define prompt parameters.
Map promptParameters = Map.of(
"query", query.text(),
"context", documentContext
);
// 3. Augment user prompt with document context.
return new Query(this.promptTemplate.render(promptParameters));
}
// 当上下文为空时,返回 DEFAULT_EMPTY_PROMPT_TEMPLATE
private Query augmentQueryWhenEmptyContext(Query query) {
if (this.allowEmptyContext) {
logger.debug("Empty context is allowed. Returning the original query.");
return query;
}
logger.debug("Empty context is not allowed. Returning a specific query for empty context.");
return new Query(this.emptyPromptTemplate.render());
}
public static final class Builder {
// ......
}
}
QueryTransformer 配置 bean,用于 rewrite 用户 query:
@Bean
public QueryTransformer queryTransformer(
ChatClient.Builder chatClientBuilder,
@Qualifier("transformerPromptTemplate") PromptTemplate transformerPromptTemplate
) {
ChatClient chatClient = chatClientBuilder.defaultOptions(
DashScopeChatOptions.builder()
.withModel("qwen-plus")
.build()
).build();
return RewriteQueryTransformer.builder()
.chatClientBuilder(chatClient.mutate())
.promptTemplate(transformerPromptTemplate)
.targetSearchSystem("联网搜索")
.build();
}
QueryExpander.java 查询变体
public class MultiQueryExpander implements QueryExpander {
private static final Logger logger = LoggerFactory.getLogger(MultiQueryExpander.class);
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate(
// ...
);
@NotNull
@Override
public List expand(@Nullable Query query) {
// ...
String resp = this.chatClient.prompt()
.user(user -> user.text(this.promptTemplate.getTemplate())
.param("number", this.numberOfQueries)
.param("query", query.text()))
.call()
.content();
// ...
List queryVariants = Arrays.stream(resp.split("\n")).filter(StringUtils::hasText).toList();
if (CollectionUtils.isEmpty(queryVariants) || this.numberOfQueries != queryVariants.size()) {
return List.of(query);
}
List queries = queryVariants.stream()
.filter(StringUtils::hasText)
.map(queryText -> query.mutate().text(queryText).build())
.collect(Collectors.toList());
// 是否引入原查询
if (this.includeOriginal) {
logger.debug("Including original query in the expanded queries for query: {}", query.text());
queries.add(0, query);
}
return queries;
}
public static final class Builder {
// ......
}
}
Retrieval
从不同数据源查询和用户 query 相似度最高的数据。(这里使用 Web Search)
WebSearchRetriever.java
public class WebSearchRetriever implements DocumentRetriever {
// 注入 IQS 搜索引擎
private final IQSSearchEngine searchEngine;
@NotNull
@Override
public List retrieve(
@Nullable Query query
) {
// 搜索
GenericSearchResult searchResp = searchEngine.search(query.text());
// 清洗数据,将数据转换为 Spring AI 的 Document 对象
List cleanerData = dataCleaner.getData(searchResp);
logger.debug("cleaner data: {}", cleanerData);
// 返回结果
List documents = dataCleaner.limitResults(cleanerData, maxResults);
logger.debug("WebSearchRetriever#retrieve() document size: {}, raw documents: {}",
documents.size(),
documents.stream().map(Document::getId).toArray()
);
return enableRanker ? ranking(query, documents) : documents;
}
private List ranking(Query query, List documents) {
if (documents.size() == 1) {
// 只有一个时,不需要 rank
return documents;
}
try {
List rankedDocuments = documentRanker.rank(query, documents);
logger.debug("WebSearchRetriever#ranking() Ranked documents: {}", rankedDocuments.stream().map(Document::getId).toArray());
return rankedDocuments;
} catch (Exception e) {
// 降级返回原始结果
logger.error("ranking error", e);
return documents;
}
}
public static final class Builder {
// ...
}
}
DocumentJoiner.java 合并 Document
public class ConcatenationDocumentJoiner implements DocumentJoiner {
@NotNull
@Override
public List join(
@Nullable Map documentsForQuery
) {
// ...
Map selectDocuments = selectDocuments(documentsForQuery, 10);
Set seen = new HashSet();
return selectDocuments.values().stream()
// Flatten List to Stream
List
if (!seen.add(key)) {
logger.info("Duplicate document metadata: {}",doc.getMetadata());
// Duplicate keys found.
return false;
}
}
// All keys are unique.
return true;
})
.collect(Collectors.toList());
}
private Map
Map
return selectDocumentsForQuery;
}
int baseCount = totalDocuments / numberOfQueries;
int remainder = totalDocuments % numberOfQueries;
// To ensure consistent distribution. sort the keys (optional)
List
Query query = sortedQueries.get(i);
int documentToSelect = baseCount + (i
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



