
100天精通Python(爬虫篇)——第122天:基于selenium接管已启动的浏览器(反反爬策略)

文章目录
- 1、问题描述
- 2、问题推测
- 3、解决方法
- 3.1 selenium自动启动浏览器
- 3.2 selenium接管已启动的浏览器
- 3.3 区别总结
- 4、代码实战
- 4.1 手动方法(手动打开浏览器输入账号密码)
- 4.2 自动方法(.bat文件启动的浏览器)
1、问题描述
使用selenium自动化测试爬取pdd的时候,通过携带cookie登录或者控制selenium输入账号密码登录,都出现了:错误代码10001:请求异常请升级客户端后重新尝试
2、问题推测
这个错误的产生是由于pdd可以检测selenium自动化测试的脚本,因此可以阻止selenium的继续访问。现在大厂网站基本上都能检测到selenium脚本了。
3、解决方法
直接用selenium启动浏览器会被检测到,博主测试用selenium接管已经启动的浏览器就不会(原因:接管已经启动的浏览器所携带的浏览器指纹 ≈ 正常访问的浏览器指纹)
使用selenium自动启动浏览器和接管已启动的浏览器,在浏览器指纹方面存在一些区别。以下是详细的分析:
3.1 selenium自动启动浏览器
-
默认行为:
- selenium在自动启动浏览器时,通常会使用默认的配置和设置。
- 浏览器会生成一个新的用户数据目录,这意味着它会创建一个全新的浏览器环境,与之前的会话或用户数据无关。
-
指纹特征:
- 由于是新启动的浏览器实例,许多浏览器指纹特征(如用户代理、插件列表、屏幕分辨率等)可能会与常规用户有所不同。
- selenium可能会在浏览器对象中留下一些特定的标记,如 window.navigator.webdriver 属性,这可能会被网站用来检测自动化工具的使用。
-
检测风险:
- 网站可能会通过检测这些指纹特征来识别出 selenium自动化启动的浏览器,从而采取反爬措施,如限制访问、封禁账号等。
3.2 selenium接管已启动的浏览器
-
现有环境:
- selenium接管已启动的浏览器时,会使用现有的浏览器实例和用户数据目录。
- 这意味着浏览器会保留之前的会话信息、登录状态、用户设置等。
-
指纹特征:
- 由于是使用现有的浏览器环境,接管后的浏览器指纹特征与常规用户的使用环境更为接近。
- 浏览器中的插件、扩展、用户代理等设置都会与常规用户保持一致,这有助于降低被检测的风险。
-
检测难度:
- 网站在检测接管后的浏览器时,可能会发现其指纹特征与常规用户更为相似,从而难以准确识别出自动化工具的使用。
- 然而,如果 selenium在接管过程中留下了特定的标记或行为模式,仍然有可能被网站检测到。
3.3 区别总结
- 指纹特征一致性:接管已启动的浏览器在指纹特征上与常规用户更为一致,而自动启动的浏览器则可能因默认配置和设置而与常规用户有所不同。
- 检测风险:由于指纹特征的一致性差异,接管已启动的浏览器在降低检测风险方面可能更具优势。
- 使用场景:自动启动浏览器适用于需要全新浏览器环境的场景,而接管已启动的浏览器则适用于需要保留现有会话信息或用户设置的场景。
4、代码实战
4.1 手动方法(手动打开浏览器输入账号密码)
第一步:找到谷歌浏览器的启动路径,默认在:C:\Program Files\Google\Chrome\Application复制去打开进入路径,如下所示有chrome.exe程序(待会我们需要启动它):

第二步:当前路径下输入cmd,点击回车:

进入cmd控制台:

第三步:我们可以利用Chrome DevTools协议。它允许客户检查和调试Chrome浏览器。在命令行中输入命令,回车:
chrome.exe --remote-debugging-port=9222 --user-data-dir="E:\selenium_data"
-
-remote-debugging-port=端口号:可以指定任何打开的端口。
-
-user-data-dir:指定创建新Chrome配置文件的目录。它是为了确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
-
E:\selenium_data:数据存储的目录,这里可以自己修改希望的存储位置
-
注意:如果失败不要忘了在环境变量中PATH里将chrome的路径添加进去。
第四步:输入命令回车后会启动一个空白浏览器,接下来手动去登录自己目标网站即可:

第五步:现在,我们需要接管上面手动登录好的浏览器。新建一个python文件,运行以下代码:
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 通过端口号接管已打开的浏览器 driver = webdriver.Chrome(chrome_options=chrome_options) print(driver.title) # 打印标题第六步:运行结果,成功打印目标网站标题,表示接管成功

问题描述:通用方法需要手动打开,手动输入账号密码,基本可以解决所有问题,但是不够智能不够自动化
4.2 自动方法(.bat文件启动的浏览器)
可以把上一种方式的目标路径设置写进 bat 文件(Windows系统),运行 bat 文件来启动浏览器,再用程序接管。
1、新建一个start_chrome.bat文件,复制下面内容(注意:chrome.exe路径改为自己的安装路径,端口号看情况修改):
@echo off set CHROME_PATH="C:\Program Files\Google\Chrome\Application\chrome.exe" set DEBUG_PORT=9222 %CHROME_PATH% --remote-debugging-port=%DEBUG_PORT%
点击测试能否自动启动谷歌:
2、在 Python 中启动 .bat 文件可以借助subprocess模块实现(注意:start_chrome.bat的文件路径)
import subprocess try: # 一、启动 .bat 文件,确保子进程在 Python 程序关闭后仍能继续运行 # 使用 DETACHED_PROCESS 和 CREATE_NEW_PROCESS_GROUP 标志 DETACHED_PROCESS = 0x00000008 CREATE_NEW_PROCESS_GROUP = 0x00000200 bat_file_path = "start_chrome.bat" # .bat 文件路径 subprocess.Popen([bat_file_path], creationflags=DETACHED_PROCESS | CREATE_NEW_PROCESS_GROUP, shell=True) print("已启动谷歌浏览器,Python 程序关闭后浏览器将继续运行。") except Exception as e: print(f"启动过程中出现错误: {e}")运行上面代码启动谷歌成功,并且保留我们正常启动浏览器的缓存:
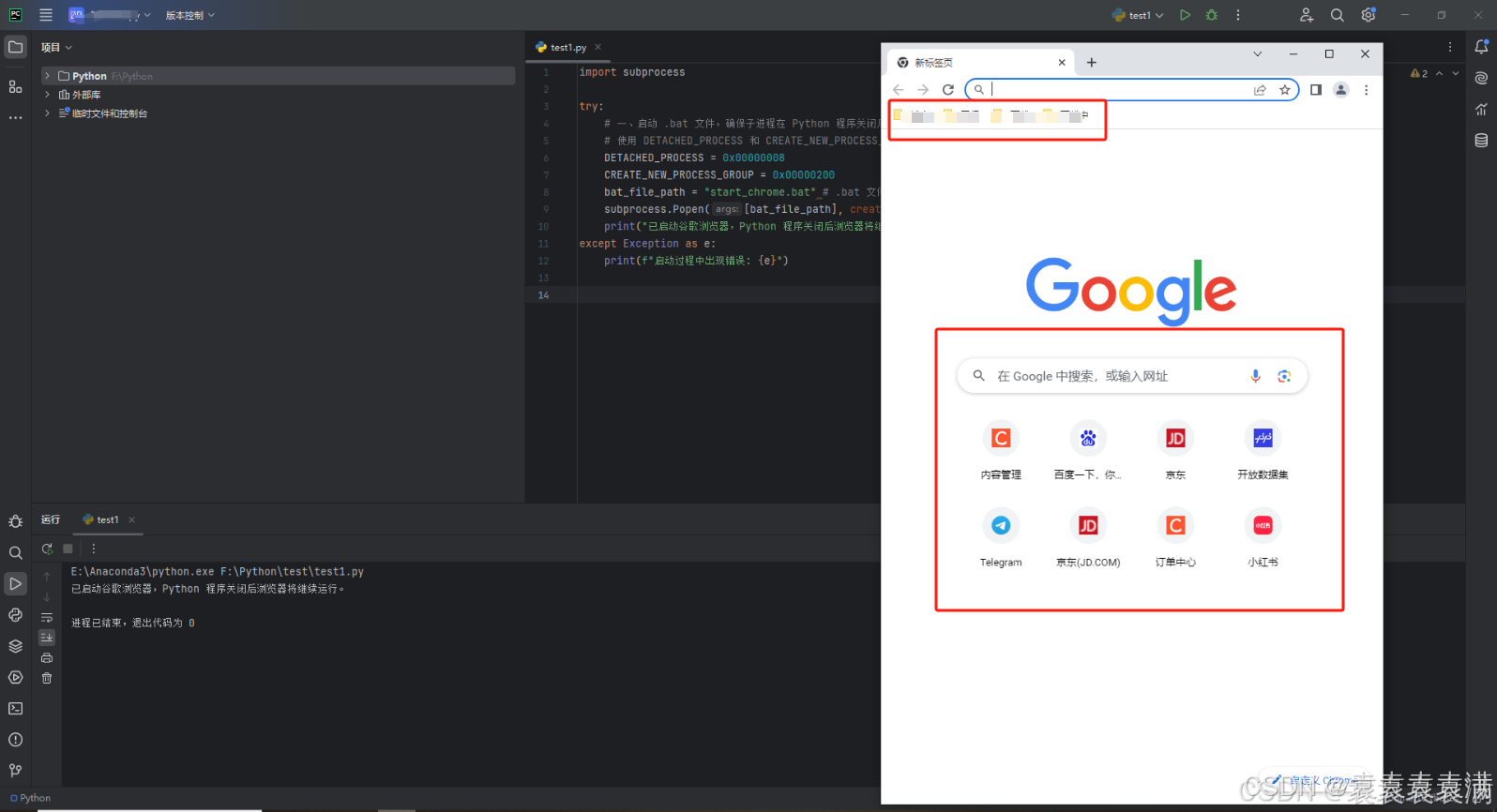
3、python启动 .bat 文件,然后selenium通过端口号去接管浏览器:
import subprocess from selenium import webdriver from selenium.webdriver.chrome.options import Options try: # 一、启动 .bat 文件,确保子进程在 Python 程序关闭后仍能继续运行 # 使用 DETACHED_PROCESS 和 CREATE_NEW_PROCESS_GROUP 标志 DETACHED_PROCESS = 0x00000008 CREATE_NEW_PROCESS_GROUP = 0x00000200 bat_file_path = "start_chrome.bat" # .bat 文件路径 subprocess.Popen([bat_file_path], creationflags=DETACHED_PROCESS | CREATE_NEW_PROCESS_GROUP, shell=True) print("已启动谷歌浏览器,Python 程序关闭后浏览器将继续运行。") # 二、通过端口号去接管启动的浏览器 chrome_options = Options() chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 创建 Chrome 浏览器实例 driver = webdriver.Chrome(options=chrome_options) print(driver.title) # 打印页面的标题 # 三、发送请求 url = "https://www.baidu.com" driver.get(url) print(driver.title) # 打印页面的标题 # 四、后续再去干别的操作就不容易被检测了,代码省略....... print('后续再去干别的操作就不容易被检测了,代码省略.......') except Exception as e: print(f"启动过程中出现错误: {e}")运行动图展示:

4、后续再去干别的操作就不容易被检测了,代码省略…
-
-







