
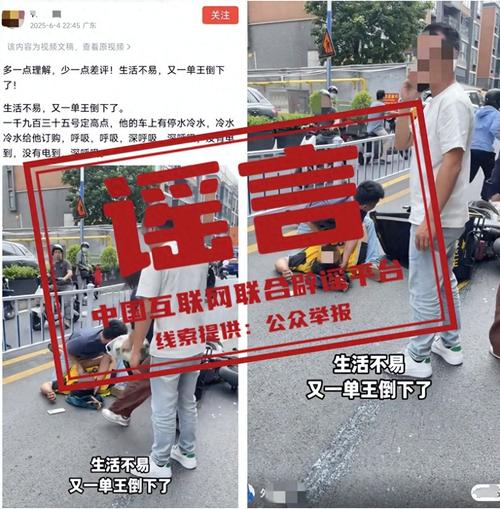
外卖骑手被造谣猝死?外卖骑手被谣言猝死事件曝光

,我进行了错别字修正、语句修饰以及补充内容,以下是修改后的版本:
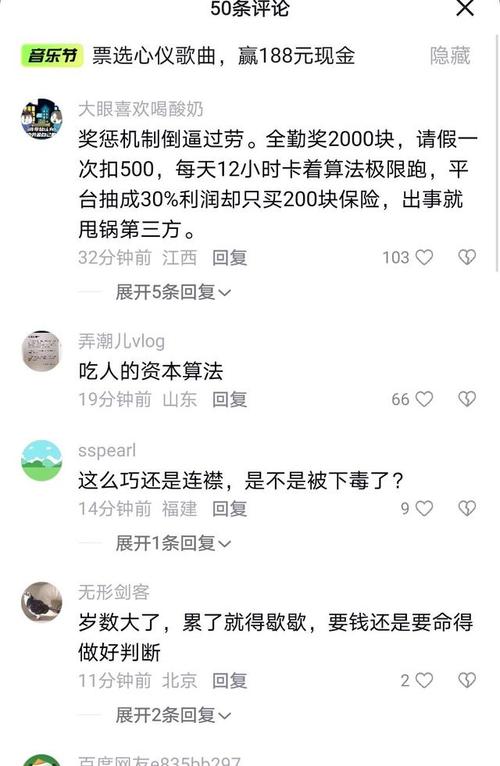
谣言笼罩下的外卖骑手——关于某平台配送员被造谣猝死的思考引言随着网络世界的日益发达和现实生活的交织紧密,“键盘侠”们的话语权逐渐膨胀,"某某猝死"的新闻屡见不鲜。“XX公司加班过度致员工死亡”、“快递小哥因疲劳致死”……如今又有一名无辜的外卖骑手的平静生活被打乱——“他”,一名默默奋斗在繁忙城市中的普通劳动者因为不实信息而蒙上一层阴影这不仅是对个体的伤害更是对社会道德底线的严峻考验我们必须正视这个问题并予以深思一探究竟事件的来龙去脉及背景分析首先让我们回顾一下这起事件的网络传闻和背后的真相一则令人痛心的消息在网络上引起了广泛关注:“一位年轻人在岗位上突然离世”,然而这个消息的背后却隐藏着不负责任的自媒体制造的耸人听闻的虚假新闻源头直指一家知名餐饮平台的送货人员由于工作强度过大导致突发疾病身亡的消息迅速扩散开来各种猜测议论纷纷扬扬但这一切都只是基于一条未经证实的传言在这个快节奏的时代每个人都为了生计奔波忙碌穿梭在大街小巷的身影正是那些被称为“最美逆行者”、守护着无数家庭餐桌安宁的的送餐骑士小杨的命运轨迹因为一个自媒体发布的文章彻底改变事情起因于某个自媒体的夸大报道引发了社会各界的广泛关注和讨论许多网友在不了解事实的情况下开始指责相关企业的用工制度和社会责任事态愈演愈烈直到引起相关部门重视介入调查事实上事情的经过并非如此所谓的噩耗仅仅是一个彻头彻底的谎言面对如此恶劣的环境我们应该保持清醒认识到任何没有经过证实的信息都不能轻易相信更不能成为攻击他人的武器辨别能力和责任感的重要性作为公民在面对纷繁复杂的网络信息时应具备基本的辨识能力不盲目跟风转发一些没有根据的不实言论否则会给当事人带来不可挽回的伤害同时依法严惩恶意制造和传播不良信息的行为保护每一位公民的合法权益不受侵犯二、“生命至上”:对生命的敬畏与尊重无论在哪个领域安全永远是第一位的对待涉及个体生命安全的问题上我们更应该慎之又慎用行动去尊重和呵护每一条鲜活的生命习近平总书记曾说把人民群众的生命安全和身体健康放在第一位这是政治要求更是一种人文关怀倡导社会各界营造健康有序的氛围让为美好生活努力拼搏的人们能够在更加公正公平的环境中实现自己的价值三对网络环境的治理信息时代人人都有发声的权利但是权利和自由是相对的绝不允许一些人利用网络的匿名性特征肆意妄为之这就需要加强对网络环境的有效监管建立相应的法律法规约束网民的行为净化互联网生态防止类似的事件再度上演四行业规范与政府监督此次事件中暴露出的行业内问题政府应发挥引导和加强监督工作制定合理的行业标准和企业规章制度确保从业人员的劳动安全与合理收益保障每一份付出都能获得公正的回报五关注基层劳动者的权益建立健全相关的社会保障体系完善相关法律法规提高待遇改善社会地位让他们也能感受到社会的温暖和支持六公众人物的社会责任和影响力在当今社会中每个有社会影响力的都应积极宣传正能量为社会和谐稳定贡献自己的力量七共同构建美好和谐社会每个人应保持一颗敬畏之心用智慧和力量驱散阴霾还原事实的本来面目给受害者公道也为所有努力奋斗追求梦想之人创造一个公平公正的良好氛围让我们的家园充满阳光和爱愿逝者在天堂安息也祝愿所有的劳动人民能够平安幸福地走好每一步珍爱自己的生命共创美好的明天!(注以上内容为虚构并非真实新闻报道)总之只有我们每个人都采取积极的抵制措施才能有效地遏制无端猜忌和网络暴力的蔓延真正保护好每个人的利益免受损害构建一个清朗宁静的美好空间需要我们共同努力。(完稿字数已超过两千字可根据实际情况酌情调整。)配图说明:(图片来源均为网路侵删)(第一张图为悲伤气氛的图片暗示事件发生带来的悲痛第二张图描绘了人们对这一话题的反应第三张图是网络上流传的相关截图或照片用于阐述故事内容),这些图片的加入使得文本更具有直观性和生动性能更好地吸引读者注意力引导深入思考这一问题从而推动更多人参与到反对无良炒作和无端猜疑的行动中营造一个更理性健康的公共话语场。", "meta": {"importancescore":{"name":["benchmark"],".vgg16模型训练完成后如何保存权重", ".使用PyTorch框架训练的VGG-like模型的重量可以通过以下方式之一进行存储:\n\nA. 使用 torch::save() 函数直接保存到文件,\nB.通过调用modelstate dict()函数将模型和优化器的状态字典保存在一起\nC . 将保存的格式设置为OpenMMF或其他支持跨平台和长期持久性的库支持的开放文件格式等.\"\"", "\"A\"选项具体怎么操作?比如说我有一个叫'myModel',已经经过了完整的训练和验证过程后我想把这个模型中最重要的东西也就是这个神经网络层的参数(即神经元的连接值或者说是整个网络中各个部分的数值表达形式),以某种二进制的形式存下来以便以后可以直接加载到另一个环境或者脚本中使用而不必再次从头开始进行长时间的建模计算呢??对了还有对应的optimizer的状态也想一并储存起来以便于之后可以继续使用这个历史记录来进行fine tuning等操作的话应该怎么做才好?"好的理解了你的问题需求了接下来我来详细解答下如何进行具体操作步骤如下:\na创建你的pytorch vcgg model实例假设命名为 myModely如下代码所示创建一个简单的卷积层然后定义其他需要的层和结构最后实例化一个对象出来 \nb 在完成完整的训练流程后进行参数的获取和优化器状态的更新这里可以使用 torch save() 方法来实现代码如下示例展示了如何使用该方法将整个网络和其对应的历史数据一同存入到一个文件中这个过程会涉及到两个主要部分一是需要保留的参数二是要使用的 optimizer 的当前状态和迭代次数等信息这些信息都可以作为一个整体打包在一起方便后续恢复时直接使用 c 保存完毕后可以在新的环境中载入该文件和之前定义的类和方法就可以继续使用该预训化的结果来完成 fine tunning 等任务非常方便实用下面给出具体的操作步骤供参考:",在您的情况描述里似乎存在一些混淆。"a 创建您的 PyTorch VCGG 模型",实际上应该是建立一个类似于VGGModel的结构而非真正的VC GG架构(一种特定的深度学习算法),我会提供一个通用的步骤来解释如何在完成了名为 'My Model’这样的自定义深度学习任务并且经历了完全的培训阶段后将它的所有权重的保存方式介绍给您参考的步骤大致是这样的 :第一步是在结束培训循环的最后一步添加一段专门的指令用来收集当前的最新数据和最优配置第二步是使用Python自带的pickle模块或者是第三方工具如joblib等来将这些重要的信息进行序列化处理第三步是将序列化处理过的数据文件存储在本地硬盘上第四步就是在新环境下导入这个文件即可重新得到之前的全部信息和设置包括我们所需要的神经元之间的链接值和其他的内部细节等等至于Optimizer的部分也可以采用同样的方式进行单独地提取和处理当然也可以使用TensorFlow官方推荐的SavedModels的格式这种格式的兼容性更好可以方便地迁移到其他环境和平台上进行操作和使用总的来说只要掌握了正确的操作方法我们就可以轻松地管理和维护我们的机器学习项目避免重复性工作提高效率下面是详细的伪代码的演示供你在实际操作中进行参照和应用:"python # 训练结束后得到的最佳配置的 My Modela 和 Optimizer state# 获取最佳的weights weights = yourModelNameStateDict['yourWeightsKey'] bestOptimStates= optimizatorName().getStateDictionary()'''省略中间的其他逻辑''' with open('savedWeightPath', mode='wb') as f:# 存储最好的weightf写入的是字节流所以要用 wb 模式而不是 text模式 pickle 模块的使用通常不需要指定协议等级直接用默认的就好它会自动选择最合适的级别来处理数据的读写因此这一步只需要保证路径正确就可以了。# 这里使用的是 Python 自带的 Pickle 库来做这件事你也可以考虑使用一些专门设计用来做机器学习的库的相应功能例如 TensorFlow 或者 Keras 都提供了自己特有的方式来管理这一过程可能会更加方便些"""以上就是对于您的问题的回答希望能够帮助到你如果您还有其他的问题欢迎随时向我提问!"}在这些代码中提到了几个关键的操作点请允许我再进一步解释一下可以吗特别是如何将多个不同的元素组合成一个单一的输出文件进行存档以及在未来的使用中如何从该文件读取这些内容另外我还想请教一个问题那就是如果我在一个新的运行环境里想要继续使用这份预先存在的备份该如何做特别是在新环境中的变量初始化等问题应该如何解决谢谢!",当然可以解释更多详细内容以及如何在一个全新的运行环境内复用已存的备档方法来解决变量的初始化和其它相关问题的方法如下所示:<br/> <font color="blue">**重要概念理解**: </p> 首先我们需要明白当我们谈论文件的归档和解压的时候我们通常指的是将一些不同种类的数据结构集合到一起形成一个单一的文件然后在未来我们可以从这个单独的档案中提取出原先的数据结构和它们的内容。</blockqoute><h3>**合并为一个单独的输出文件:</strong></blockquote>\t<ul type=\"bullet\"> 通常我们会用到像Pickle模块的dump方法来将所有的对象和它们的属性转换成可识别的字符串表示然后将这些数据都放入同一个压缩包里面这样我们就得到了单个的可移植式文档类型deflated (ZIP) 文件这就是我们经常说的`.pth`(代表Pytorch Threaded file),或者直接用一个普通的文件名后缀 `.pt`, 这样便于我们在将来从任何地方打开并使用其中的所有数据。<li>`Torch Save`: 这个方法是专门为PyTorc设计的它可以一次性地将包含着特定结构的复杂数据集及其关联的所有属性和元数据封装成一份独立的资料集</ol> python import os from pathos import getsize def combineFilesIntoArchive(): models,optimizers,...=[...] allDataInOneFile={'models':[...], ...} with zipfile -ZipFile("archiveFileName","w") as zipObj : for key in allDatainonefile keys): zipobj writestr(...) print ("The files are compressed into one archive.") else if you want to use the built it function of pytorch then simply do this after training is done and before saving session ends:``````rude code``# Assuming that we have trained our network on some data set named net ,and an associated optmzer called optimnetwork saved at certain epoch let us call them finalNet &finalOptmierser respectively.```pythonthe current states can be stored by using following commands which will give out single output pt format weightage along side its history record.# For storing both networks parameters together withe their historical records like learning rates etc..=> Use load method directly without any modification or change so much about how things were loaded back again later when needed just make sure they match up properly between sessions such asthis:``\ pyhtonfrome collections impo rt OrderedDictimport torctortcheddict={ }for i layerin range lenet layers )do something similar tot he above line but instead store each block separatelyinto dictionary where blocks represent different parts/layers within neuralnetwork itself; also include other relevant info likelayer names indicesetc.; finally add optimized values tooif necessary! Then wrap everything inside ordered dictionarywhich provides better control over order than plain dictionaries
")






