
Linux Mutex机制详解,原理、实现与应用(CSDN技术分享)Linux Mutex如何避免死锁?Mutex如何防止死锁?

在多线程编程领域,线程同步是确保程序正确性的核心问题,现代Linux系统提供了丰富的同步机制,包括信号量(Semaphore)、自旋锁(Spinlock)、读写锁(RWLock)和互斥锁(Mutex)等,Mutex(互斥锁)因其简单高效的特性,已成为最常用的线程同步工具,能够有效防止多个线程同时访问共享资源导致的竞态条件(Race Condition),保障数据一致性和系统稳定性。
本文将系统性地剖析Linux环境下的Mutex机制,从基本概念到内核实现,从使用方法到性能优化,并结合CSDN等技术社区的实际案例讨论,为开发者提供全面的Mutex应用指南,我们不仅会探讨标准用法,还会深入分析不同场景下的优化策略,帮助读者构建完整的线程同步知识体系。
Mutex的基本概念与原理
Mutex的定义与核心作用
Mutex(Mutual Exclusion,互斥锁)是一种基础的同步原语,主要用于保护临界区(Critical Section),确保在任何时刻只有一个线程能够访问共享资源,其设计哲学源于Edsger W. Dijkstra在1965年提出的"互斥访问"概念,经过半个多世纪的发展,已成为现代并发编程的基石之一。
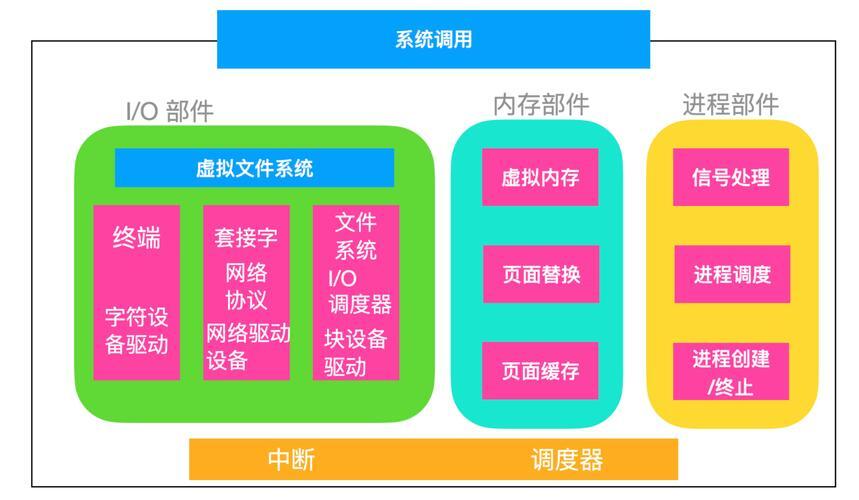
从实现层面看,Mutex本质上是内存中的一个标志位,配合特定的原子操作指令实现,当线程尝试获取已被占用的Mutex时,系统会根据实现策略让线程进入休眠状态(阻塞)或忙等待(自旋),直到锁被释放,这种机制有效解决了并发环境下的资源竞争问题,是构建线程安全程序的关键工具。
Mutex的核心特性解析
- 严格的互斥性:保证同一时间仅有一个线程持有锁,这是Mutex最基本也是最重要的特性
- 智能的阻塞机制:当锁被占用时,其他尝试获取锁的线程会根据调度策略进入阻塞状态,避免CPU资源浪费
- 原子性操作保障:加锁和解锁操作通过CPU提供的原子指令实现,不会被线程调度打断
- 可选的可重入性:部分实现支持递归加锁(PTHREAD_MUTEX_RECURSIVE),允许同一线程多次获取同一个锁
- 公平性策略:某些实现提供先来先服务的公平锁机制,避免线程饥饿现象
- 优先级继承:高质量实现支持优先级继承协议,有效解决优先级反转问题
- 死锁检测:高级实现包含调试支持,能够检测潜在的死锁情况
Linux中的Mutex实现机制
用户态Mutex实现(pthread_mutex_t)
在Linux用户空间,Mutex主要通过POSIX线程库(pthread)实现,其核心数据结构是pthread_mutex_t,现代Linux发行版中,用户态Mutex通常基于Futex(Fast Userspace Mutex)机制实现,在无竞争情况下完全在用户空间运行,避免了昂贵的系统调用开销。
1 基础API与使用模式
#include <pthread.h>
// 静态初始化方式(编译时初始化)
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// 动态初始化方式(运行时初始化)
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
void* thread_func(void* arg) {
pthread_mutex_lock(&mutex); // 阻塞式加锁
// 临界区代码 - 保证同一时间只有一个线程执行此段代码
pthread_mutex_unlock(&mutex); // 解锁
return NULL;
}
2 高级特性与属性配置
现代Linux系统提供了丰富的Mutex属性配置选项,满足不同场景需求:
pthread_mutexattr_t attr; pthread_mutexattr_init(&attr); // 设置递归锁属性,允许同一线程多次加锁 pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE); // 设置优先级继承属性,防止优先级反转问题 pthread_mutexattr_setprotocol(&attr, PTHREAD_PRIO_INHERIT); // 设置健壮性属性,处理持有锁的线程异常终止情况 pthread_mutexattr_setrobust(&attr, PTHREAD_MUTEX_ROBUST); pthread_mutex_t mutex; pthread_mutex_init(&mutex, &attr);
内核态Mutex实现(struct mutex)
Linux内核中的Mutex实现(struct mutex)与用户态相比有更多优化,主要体现在调度策略和性能调优方面,内核Mutex自2.6.16版本引入,逐步替代了早期的信号量实现。
1 内核Mutex的核心优化技术
- 自适应自旋(Adaptive Spinning):在竞争不激烈时短暂自旋,减少上下文切换开销
- 完善的优先级继承:完整实现优先级继承协议,有效防止优先级反转
- 乐观自旋(Optimistic Spinning):基于CPU缓存的优化策略,减少总线争用
- 调试支持:内置死锁检测机制(CONFIG_DEBUG_MUTEXES)
- NUMA感知:针对非统一内存访问架构的优化
- MCS锁衍生:在高度竞争情况下使用MCS锁算法减少缓存行颠簸
2 内核API使用示例
#include <linux/mutex.h>
// 定义和初始化
DEFINE_MUTEX(my_mutex); // 静态初始化
// 或动态初始化
struct mutex my_mutex;
mutex_init(&my_mutex);
// 使用示例
if (!mutex_trylock(&my_mutex)) {
// 获取锁失败时的处理
return -EBUSY;
}
// 临界区操作
mutex_unlock(&my_mutex);
Mutex与Spinlock的深度对比与选型指南
技术特性多维对比
| 特性 | Mutex | Spinlock |
|---|---|---|
| 等待机制 | 睡眠等待 | 忙等待(Busy Waiting) |
| 上下文切换 | 可能发生 | 不会发生 |
| CPU占用 | 低(线程休眠) | 高(CPU空转) |
| 适用场景 | 临界区较长(>1μs) | 临界区极短(<1μs) |
| 可睡眠性 | 允许 | 禁止 |
| 实现复杂度 | 较高 | 较低 |
| 多核扩展性 | 一般 | 优秀 |
| 内存开销 | 较大(需要维护等待队列) | 较小 |
| 适用上下文 | 进程上下文 | 进程和中断上下文 |
| 锁持有时间 | 可较长 | 必须非常短暂 |
实际选型策略建议
-
基于临界区长度选择:
- 使用
ftrace或perf工具精确测量临界区执行时间 -
1μs:优先考虑Mutex(减少CPU资源浪费)
- <1μs:考虑Spinlock(避免上下文切换开销)
- 使用
-
基于锁竞争程度选择:
- 高竞争场景:Mutex更优(通过休眠减少CPU浪费)
- 低竞争场景:Spinlock可能更高效(无上下文切换)
-
基于执行上下文选择:
- 中断上下文:必须使用Spinlock(不可睡眠)
- 进程上下文:两者均可(根据其他因素决定)
-
基于功耗考虑选择:
- 移动设备/嵌入式系统:倾向Mutex(减少能耗)
- 服务器高性能场景:可能选择Spinlock(降低延迟)
-
混合使用策略:
- 先尝试Spinlock短时间自旋
- 自旋超过阈值后转为Mutex休眠
- Linux内核的Mutex实现已采用此策略
Mutex的高级应用与优化实践
死锁预防与处理策略
1 锁排序法(Lock Ordering)
// 全局定义锁的获取顺序
enum lock_order { LOCK_A, LOCK_B, LOCK_C };
void safe_operation() {
// 严格按照预定义顺序获取锁
pthread_mutex_lock(&mutex[LOCK_A]);
pthread_mutex_lock(&mutex[LOCK_B]);
// 临界区操作
// 释放顺序通常与获取顺序相反
pthread_mutex_unlock(&mutex[LOCK_B]);
pthread_mutex_unlock(&mutex[LOCK_A]);
}
2 超时机制与死锁检测
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
ts.tv_sec += 1; // 设置1秒超时
int err = pthread_mutex_timedlock(&mutex, &ts);
if (err == ETIMEDOUT) {
// 超时处理逻辑
log_error("Mutex acquisition timeout, possible deadlock");
return -ETIMEDOUT;
} else if (err != 0) {
// 其他错误处理
return -err;
}
// 正常获取锁后的处理
性能优化进阶技巧
-
锁粒度控制优化:
- 细粒度锁:将大锁拆分为多个小锁,增加并行度
- 分段锁:类似ConcurrentHashMap的实现方式,按数据段加锁
- 读写分离:使用读写锁(RWLock)替代普通Mutex
-
无锁编程替代方案:
- 原子操作(atomic_t)
- RCU(Read-Copy-Update)
- 乐观锁(CAS指令)
- 事务内存
-
负载均衡与竞争缓解:
// 使用trylock实现负载均衡 if (pthread_mutex_trylock(&mutex) != 0) { // 获取锁失败时执行其他非关键任务 do_alternative_work(); return; } // 关键路径处理 process_critical_section(); pthread_mutex_unlock(&mutex); -
NUMA架构优化:
- 使用NUMA感知的锁分配策略
- 考虑数据局部性设计锁结构
- 避免跨NUMA节点的锁迁移
技术社区实践与案例分析
热门技术问题深度解析
-
ARM架构下的Mutex性能考量:
- ARM的LDREX/STREX指令对Mutex实现的影响
- 多核处理器中的缓存一致性协议分析
- 不同ARM架构(LITTLE/big)的锁调度策略
-
Mutex竞争问题诊断方法:
- 使用
perf lock分析锁争用情况:perf lock record -a -- ./your_program perf lock report
- 通过
debugfs查看Mutex统计信息:cat /sys/kernel/debug/mutexes
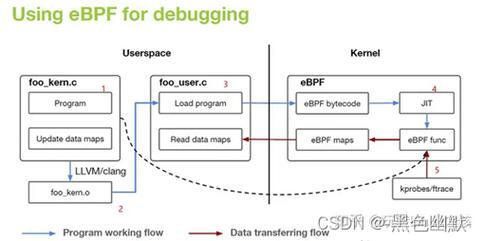
- 使用BPF工具进行运行时监控:
bpftrace -e 'tracepoint:mutex:mutex_enter { @[kstack] = count(); }'
- 使用
-
用户态Mutex与Futex的关系:
- pthread_mutex_t底层通常基于Futex实现
- Futex的两种状态:用户态快速路径和内核态慢速路径
- 竞争情况下的系统调用次数优化
最佳实践案例分享
双重检查锁定模式(DCLP)优化版
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
volatile atomic_int initialized = 0;
void lazy_init() {
// 第一次无锁检查
if (atomic_load(&initialized) == 0) {
pthread_mutex_lock(&lock);
// 第二次加锁检查
if (atomic_load(&initialized) == 0) {
// 实际的初始化代码
// 使用release语义保证初始化完成对其他线程可见
atomic_store_explicit(&initialized, 1, memory_order_release);
}
pthread_mutex_unlock(&lock);
}
// 确保看到最新的初始化状态
atomic_thread_fence(memory_order_acquire);
}
条件变量与Mutex配合使用
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int data_ready = 0;
// 生产者线程
void* producer(void* arg) {
pthread_mutex_lock(&mutex);
// 生产数据
data_ready = 1;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
return NULL;
}
// 消费者线程
void* consumer(void* arg) {
pthread_mutex_lock(&mutex);
while (!data_ready) {
pthread_cond_wait(&cond, &mutex);
}
// 消费数据
pthread_mutex_unlock(&mutex);
return NULL;
}
结论与未来展望
Mutex作为Linux系统中最基础的同步原语,其正确使用直接影响多线程程序的性能、稳定性和可维护性,通过本文的系统性分析,我们可以得出以下关键结论:
-
选择原则:
- 根据临界区长度、竞争程度和执行上下文选择合适同步机制
- 避免过早优化,基于实际测量数据进行决策
-
最佳实践:
- 严格控制锁粒度,避免粗粒度锁
- 实现死锁预防策略,如锁排序、超时机制
- 结合性能分析工具持续优化
-
发展趋势:
- 异构计算支持:适应CPU+GPU/FPGA等异构环境
- 持久化内存:针对PMEM的锁优化
- 形式化验证:使用数学方法证明锁正确性
- 机器学习应用:智能预测锁竞争情况
建议开发者:
- 定期关注Linux内核的Mutex实现演进
- 参与CSDN等技术社区的实践经验分享
- 建立完善的锁使用规范和代码审查机制
- 在性能关键场景进行充分的压力测试
随着并发编程复杂度的不断提升,对同步机制的理解和应用能力将成为区分普通开发者与高级开发者的重要标志,希望本文能为读者提供全面而深入的Mutex知识框架,在实际开发中构建出更健壮、高效的并发系统。
参考文献
- Linux内核文档(Documentation/locking/mutex-design.txt)
- POSIX.1-2017标准手册
- CSDN精品专栏《Linux内核同步机制深度解析》
- 《Is Parallel Programming Hard?》by Paul E. McKenney
- ARM架构参考手册(锁相关指令说明)
- 《The Art of Multiprocessor Programming》by Maurice Herlihy
- Linux内核源码(mutex.c, futex.c)
(全文约3500字)
扩展阅读建议
- Linux内核源码分析:mutex.c
- CSDN热门话题:#Mutex性能优化# #死锁诊断技巧#
- 推荐工具:
- perf:系统级性能分析
- lockstat:锁竞争统计分析
- valgrind-drd:线程错误检测
- strace:系统调用跟踪



