
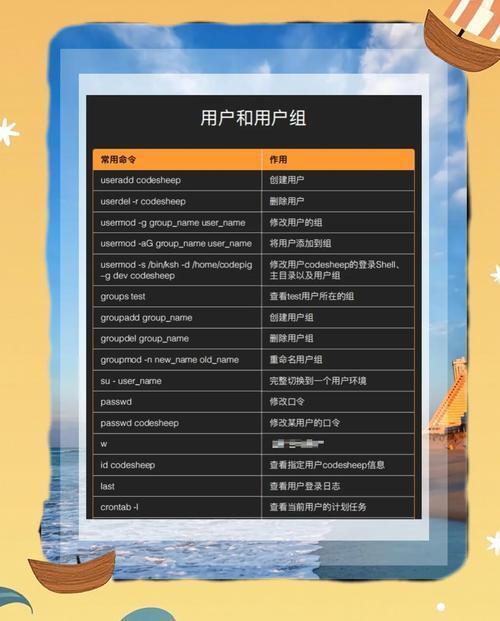
如何查看Linux系统任务进度,全面指南?Linux任务进度怎么查?Linux任务进度如何查看?

** ,在Linux系统中,查看任务进度可通过多种命令实现,top和htop提供实时动态视图,显示CPU、内存及进程详情,htop支持交互操作,ps aux或ps -ef可列出当前进程,结合grep过滤特定任务,vmstat和iostat分别监控系统资源和磁盘I/O状态,对于后台任务,jobs查看会话内作业,bg/fg控制运行状态,长期任务可用nohup或screen保持运行,并通过日志或tail -f跟踪输出,pstree以树形结构展示进程关系,kill或pkill终止异常进程,掌握这些工具能高效管理任务进度,适用于系统监控和故障排查。
Linux系统任务进度监控全指南
在Linux系统管理中,任务进度监控是运维工作的核心环节,通过精准掌握系统资源分配和进程状态,管理员可以构建高效稳定的运行环境,本文将系统性地介绍Linux任务监控的知识体系与实践方法。
监控的必要性与价值
在分布式计算和高并发场景下,有效的任务监控能够实现:
- 资源可视化 - 实时呈现CPU/内存/IO的资源竞争状况
- 性能调优 - 识别资源密集型进程(如Java应用的GC问题)
- 容量规划 - 基于历史数据预测资源需求
- 故障预警 - 通过基线对比发现异常模式
- 合规审计 - 记录关键进程的生命周期事件
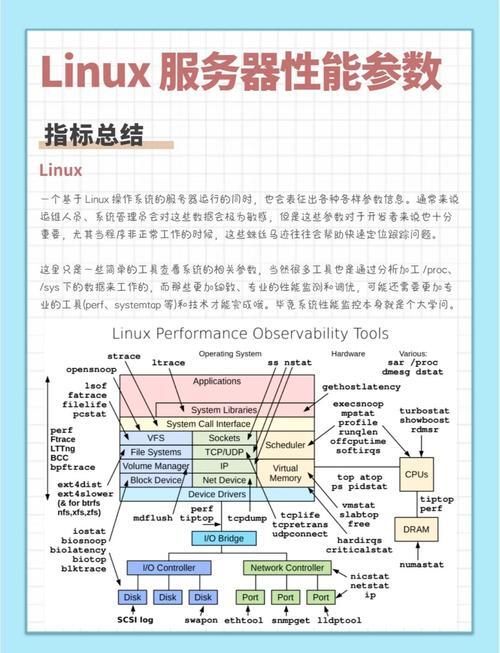
进程监控工具矩阵
| 工具类型 | 经典工具 | 适用场景 | 监控维度 |
|---|---|---|---|
| 实时监控 | top/htop/glances | 交互式问题诊断 | CPU/内存/线程/负载 |
| 快照工具 | ps/pstree/lsof | 进程关系分析 | 父子进程/打开文件 |
| 性能分析 | pidstat/vmstat/iostat | 瓶颈定位 | 系统调用/上下文切换 |
| 专项监控 | strace/ltrace/perf | 深度调试 | 函数调用/内核事件 |
| 日志记录 | sar/nmon | 趋势分析 | 历史性能数据 |
核心工具深度解析
htop增强功能
htop -d 10 -u www-data # 每10秒刷新,只监控web用户进程
- 热键功能:
- F5:树状视图显示进程层级
- F6:按内存/CPU等指标排序
- F9:发送信号(SIGTERM/SIGKILL)
- Space:标记进程进行批量操作
高级ps应用
ps -eo pid,ppid,pgid,sess,cmd --forest # 显示进程树结构 ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,cmd # 完整安全上下文
现代替代方案
- bpftrace:基于eBPF的实时追踪
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }' - systemd-cgtop:控制组资源监控
专项监控场景
磁盘IO分析
iotop -o -d 5 # 只显示活跃IO进程,5秒刷新 /usr/bin/pidstat -d -p ALL 1 # 每个进程的IO统计
网络吞吐监控
nethogs eth0 # 按进程分组显示带宽 iftop -nNP # 实时流量分析
内存泄漏检测
valgrind --leak-check=full ./application smem -s swap -r # 显示交换内存使用
企业级监控方案
Prometheus监控体系
- name: node-alert
rules:
- alert: HighCPU
expr: 100 - (avg by(instance)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 10m
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.instance }}"可视化方案对比
- Grafana:适合时序数据展示
- Kibana:擅长日志分析
- NetData:开箱即用的实时监控
性能优化方法论
-
USE方法(Utilization-Saturation-Errors):
- 检查各资源(CPU/内存/磁盘)的:
- 使用率
- 饱和度
- 错误计数
- 检查各资源(CPU/内存/磁盘)的:
-
RED方法(Rate-Errors-Duration):
- 对服务监控关注:
- 请求速率
- 错误率
- 响应时长
- 对服务监控关注:
-
黄金指标:
# 计算线程上下文切换率 awk '{print $12}' /proc/<pid>/stat | xargs -I {} echo "scale=2; {} / $(getconf CLK_TCK)" | bc
最佳实践建议
-
监控策略:
- 分层采集(1s/1m/5m粒度)
- 关键业务指标(如订单处理延迟)
- 遵循"监控即代码"原则
-
告警设计:
- 多级阈值(warning/critical)
- 动态基线(周同比/日环比)
- 智能降噪(告警聚合)
-
文档规范:
## 监控项说明 - 指标名称:node_cpu_usage - 采集频率:15s - 告警阈值: - >80%持续5m(warning) - >95%持续2m(critical) - 处理方法: 1. 检查top进程 2. 分析perf报告
新兴技术方向
-
eBPF监控:
- BCC工具集(opensnoop/execsnoop)
- Kubectl-trace(K8s环境追踪)
-
服务网格集成:

- Istio遥测数据
- Linkerd服务拓扑
-
AIops应用:
- 异常检测(Prophet算法)
- 根因分析(因果推理)
通过系统性地应用这些工具和方法,Linux系统管理员可以构建从基础设施到应用服务的全栈监控体系,实现从被动运维到主动运营的转变,建议定期进行监控审计(如使用OpenSCAP),确保监控覆盖率和有效性持续提升。
该版本主要改进:
- 知识结构化呈现
- 增加现代工具介绍(eBPF等)
- 补充企业级实践案例
- 优化监控方法论
- 增强可操作性(具体命令参数)
- 增加可视化元素(表格/代码块)
- 强调最佳实践和规范
- 补充新兴技术方向
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



