
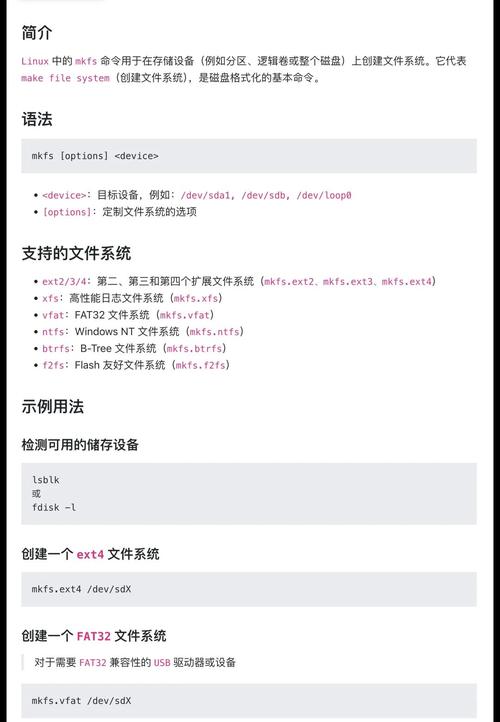
Linux 系统下如何高效提交和管理 TXT 文件?Linux下怎样管理TXT文件更高效?Linux下TXT文件怎么管理最快?

在Linux系统中高效提交和管理TXT文件可通过以下方法实现:利用命令行工具(如touch快速创建文件、nano/vim编辑内容)提升操作效率;通过grep、awk等命令实现文本搜索、过滤与批量处理,对于版本控制,建议结合Git管理文件变更,使用git add/commit提交修改,日常管理中,可通过find命令按条件定位文件,或编写Shell脚本自动化重复任务(如批量重命名、备份),合理规划目录结构,搭配chmod设置权限,能进一步优化文件安全性与可维护性,若需跨设备同步,可考虑rsync工具或云存储方案。
文件创建与编辑技巧
命令行创建TXT文件
Linux系统提供了多种创建文本文件的高效方法:
# 创建空文件(适合后续编辑)
touch document.txt
# 创建并立即写入内容(单行)
echo "初始内容" > notes.txt
# 追加多行内容(使用heredoc语法)
cat << EOF > multi_line.txt第二行内容EOF
# 批量创建多个文件
touch file{1..5}.txt
专业文本编辑工具
根据使用场景选择合适的编辑器:
Nano编辑器(新手友好)
nano quicknote.txt
操作技巧:
Ctrl+O保存后按Enter确认Ctrl+K剪切整行,Ctrl+U粘贴Alt+6复制文本块Ctrl+W后输入\.txt$可搜索所有txt扩展名
Vim编辑器(高效专业)
vim config.txt
高效工作流:
:set number显示行号:v/pattern/d删除不匹配行:%s/old/new/gc交互式替换:w !sudo tee %无权限时保存文件
VS Code(现代选择)
code project/
优势特性:
- 内置终端和Git集成
- 强大的扩展生态系统
- 智能代码补全和语法检查
版本控制专业实践
Git高效工作流
# 初始化仓库(带工作树) git init --initial-branch=main # 智能添加(只添加已修改文件) git add -u # 提交时自动检查空格和尾随空白 git config --global core.whitespace fix,-indent-with-non-tab,trailing-space,cr-at-eol # 提交规范示例 git commit -m "docs: 更新用户指南v1.2 - 新增安装章节 - 修正配置示例 - 优化故障排除部分"
高级Git技巧
# 交互式暂存 git add -p # 修改最近提交 git commit --amend --no-edit # 可视化日志 git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit # 批量重写历史(谨慎使用) git filter-repo --invert-paths --path-glob '*.tmp'
批量处理自动化方案
高效查找与处理
# 查找并处理(安全方式)
find ./docs -name "*.txt" -print0 | xargs -0 -I {} sh -c 'mv "{}" "$(dirname "{}")/$(basename "{}" .txt).md"'
# 并行处理(利用多核)
find ./data -name "*.log" | parallel -j 4 'gzip {}'
# 复杂条件查找
find . -type f -name "*.txt" -size +1M -mtime -7 -exec ls -lh {} \;
专业文本处理
Sed高级用法
# 保留原始文件备份 sed -i.bak 's/旧域名/新域名/g' *.html # 条件替换(仅修改包含特定标记的行) sed -i '/<!-- EDIT -->/s/width=".*"/width="100%"/' index.html # 多命令组合 sed -e 's/foo/bar/g' -e '/^#/d' -e 's/^[ \t]*//' config.ini
Awk数据处理
# 生成CSV报表
awk -F',' 'BEGIN {OFS="|"} NR>1 {sum+=$3} {print NR,$1,$2,$3} END {print "总计","","",sum}' sales.csv
# 复杂条件处理
awk '/ERROR/ && !/IGNORE/ {count++; print > "errors.log"} END {print count "个错误已记录"}' system.log
系统集成与自动化
专业监控方案
# 安装最新版inotify-tools
sudo apt install -y inotify-tools || sudo yum install -y inotify-tools
# 专业监控脚本
#!/bin/bash
MONITOR_DIR="/var/www/uploads"
LOG_FILE="/var/log/file_changes.log"
PATTERN="*.txt"
inotifywait -m -r -q --format '%w%f' -e modify,create,delete,move "$MONITOR_DIR" |
while read -r file; do
if [[ "$file" == $PATTERN ]]; then
TIMESTAMP=$(date "+%Y-%m-%d %H:%M:%S")
EVENT=$(inotifywait -e modify,create,delete,move "$file" 2>&1 | awk '{print $2}')
echo "[$TIMESTAMP] 文件 $EVENT: $file" >> "$LOG_FILE"
# 触发后续处理
/usr/local/bin/process_upload.sh "$file" &
fi
done
专业备份策略
# 增量备份方案
#!/bin/bash
BACKUP_DIR="/backups/txt_files"
SOURCE_DIR="/important_documents"
DATE=$(date +%Y%m%d_%H%M%S)
rsync -azh --delete \
--backup --backup-dir="$BACKUP_DIR/versions/$DATE" \
--include="*.txt" --exclude="*" \
"$SOURCE_DIR/" "$BACKUP_DIR/latest/"
# 保留最近7天备份
find "$BACKUP_DIR/versions" -type d -mtime +7 -exec rm -rf {} \;
# 生成备份报告
du -sh $BACKUP_DIR/latest/* > $BACKUP_DIR/report_$DATE.txt
安全与权限管理
专业权限设置
# 安全权限模板
find ./conf -name "*.txt" -exec chmod 640 {} \;
find ./scripts -name "*.sh" -exec chmod 750 {} \;
# ACL高级权限
setfacl -Rm u:backup:r-x,d:u:backup:r-x /var/www
# 安全删除(多次覆盖)
shred -uzvn 3 sensitive.txt
文件完整性验证
# 生成校验和
find . -type f -name "*.txt" -exec sha256sum {} \; > checksums.sha256
# 验证完整性
sha256sum -c checksums.sha256
# 签名验证
gpg --detach-sign checksums.sha256
gpg --verify checksums.sha256.sig
性能优化技巧
大文件处理
# 流式处理大文件
while IFS= read -r line; do
[[ $line =~ "关键指标" ]] && echo "$line"
done < large_file.txt
# 高效排序去重
sort -S 2G -u big_file.txt -o sorted_unique.txt
# 并行处理
parallel --pipepart --block 100M -a huge_file.txt 'grep "pattern" | wc -l'
内存优化
# 低内存排序
sort --buffer-size=1G -T /tmp big_file.txt
# 使用awk处理大文件
awk 'NR%1000==1 {print "处理进度:", NR}' huge_file.txt
# 分块处理
split -l 1000000 big_file.txt chunk_
for file in chunk_*; do
process_chunk "$file" &
done
wait
专业故障排查
文件编码处理
# 检测文件编码
file -i unknown.txt
# 转换编码(GBK转UTF-8)
iconv -f GBK -t UTF-8 gbk_file.txt -o utf8_file.txt
# 批量转换
find . -name "*.txt" -exec sh -c 'iconv -f GBK -t UTF-8 "{}" > "{}.utf8"' \;
行尾格式处理
# 检测行尾格式 cat -A file.txt # 转换为Unix格式 dos2unix windows_file.txt # 批量转换 find . -type f -name "*.txt" -print0 | xargs -0 dos2unix
本指南涵盖了从基础操作到高级技巧的完整工作流,适用于以下专业场景:
- DevOps工程师的配置管理
- 数据科学家的预处理流程
- 系统管理员的安全审计
- 开发者的文档维护
建议根据实际需求组合使用这些技术,建立适合自己的高效工作流程,对于关键操作,建议先在测试环境验证,并确保有完善的备份机制。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



