
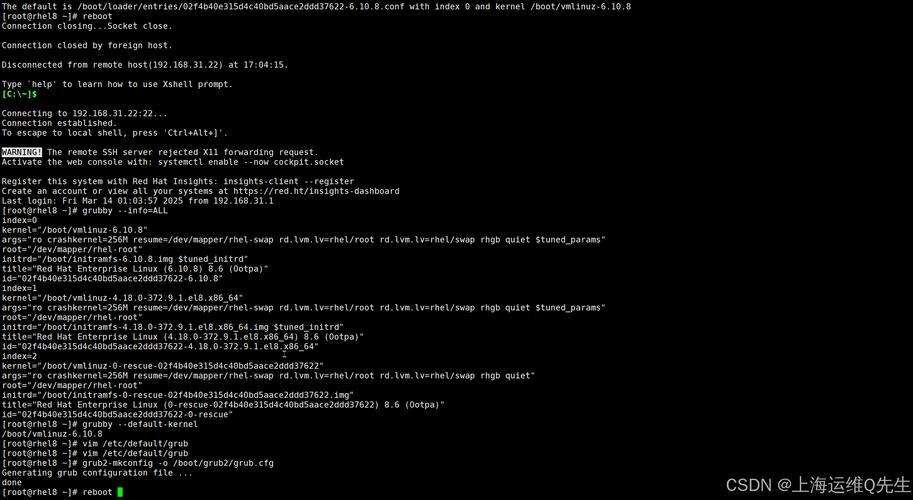
Linux故障诊断的难点与应对策略?Linux问题为何总难解决?Linux问题为何总难解决?

Linux故障诊断的难点主要源于其开源性、复杂性和多样性,由于Linux系统高度模块化,涉及内核、驱动、服务等多层组件,故障可能由硬件、软件或配置问题引发,定位根源需综合日志分析、命令调试和性能监控,加之不同发行版差异大,社区解决方案往往缺乏普适性,导致问题复现和解决效率低下。 ,应对策略包括:系统性思维(从日志/报错入手逐层排查)、善用工具(如strace、dmesg、top等)、掌握关键命令(网络、磁盘、进程相关),并通过模拟测试验证假设,建立知识库积累常见案例,参与社区讨论,能显著提升解决效率,Linux问题的复杂性本质是其灵活性的代价,但通过方法论和经验的结合,可逐步降低排查难度。
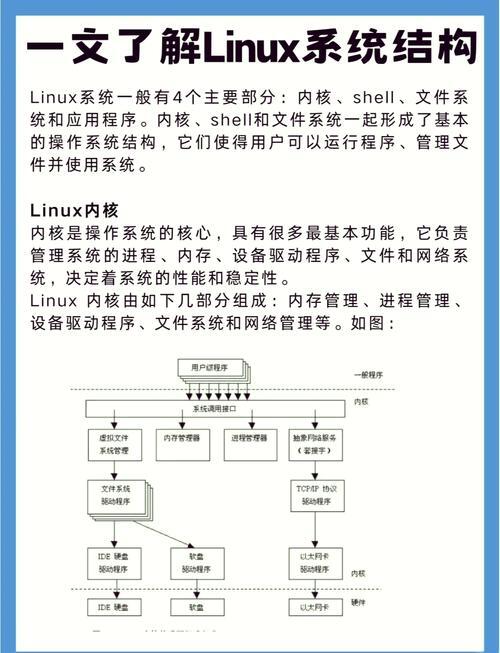
核心挑战与技术应对
日志管理的多维复杂性
Linux系统日志呈现分布式架构特征,主要分为:
-
基础日志体系
- 通用日志:
/var/log/messages(RHEL系)与/var/log/syslog(Debian系) - 内核环缓冲区:通过
dmesg -T获取带时间戳的内核事件 - 安全审计日志:
/var/log/secure(RHEL)与/var/log/auth.log(Debian)
- 通用日志:
-
现代日志系统演进
# Systemd日志检索示例(支持结构化查询) journalctl _UID=1000 --since "09:00" --until "11:00" -o json-pretty
诊断优化方案:
- 实时日志分析:
tail -f /var/log/nginx/error.log | grep -E '50[0-9]' - 历史日志聚合:
logreduce -d /var/log/syslog.1 /var/log/syslog - 云端日志方案:Loki+Promtail+Grafana构建轻量级日志监控栈
硬件兼容性深度解决方案
典型故障模式:
- 内核模块加载失败(
modprobe: FATAL: Module xxx not found) - GPU计算单元异常(CUDA版本与驱动不匹配)
- 存储控制器性能劣化(IRQ冲突或DMA设置不当)
诊断矩阵:
# 硬件健康检查套件 sudo lshw -json | jq '.configuration.driver' sudo turbostat --show Core,CPU%c1,PkgWatt -i 5
驱动管理策略:
- 使用DKMS动态编译内核模块
- 部署fwupd固件管理系统
- 参考Linux Hardware Compatibility List(HCL)采购设备
依赖管理的现代实践
依赖冲突解决方案对比: | 方案 | 适用场景 | 典型案例 | |---------------|------------------------|--------------------------| | Docker | 应用级隔离 | 多版本Python环境共存 | | Flatpak | 桌面应用沙箱 | LibreOffice多版本部署 | | Nix | 声明式依赖管理 | 开发环境精确复现 |
高级诊断命令:
# 动态库依赖分析(ELF格式) readelf -d /usr/bin/nginx | grep NEEDED # RPM包依赖树分析 rpm -q --tree python3-libs
网络诊断的OSI模型实践
分层诊断工具链
- 物理层:
ethtool --show-eee eth0 # 检查节能以太网状态
- 网络层:
ip -s -h link show dev eth0 # 带统计信息的接口状态
- 传输层:
ss -4tin # TCP连接详细指标分析
- 应用层:
curl --trace-ascii debug.log https://example.com
网络性能优化案例:
# 快速诊断网络瓶颈
pingflood() {
ping -f -c 1000 $1 | grep -oP '\d+(?=% packet loss)'
tc qdisc show dev eth0
}
文件系统深度维护
Btrfs高级维护
# 文件系统完整性检查 sudo btrfs scrub start /mnt/data # 透明压缩状态查看 sudo compsize -x /var/lib/mysql
权限管理的SELinux实践
# 安全上下文修复 restorecon -Rv /var/www/html # 策略模块管理 semodule -l | grep httpd
智能监控体系构建
eBPF监控新范式
# 实时追踪文件打开行为 sudo opensnoop-bpfcc -T 5 # 网络流量分析 sudo tcplife-bpfcc -T
Prometheus生态进阶
graph LR
NodeExporter --> Prometheus
cAdvisor --> Prometheus
Prometheus --> AlertManager
AlertManager --> [Slack/Email]
Prometheus --> Grafana
自动化运维体系
Ansible高级模式
- name: 智能修复内核问题
hosts: database_servers
vars:
kernel_threshold: 3
tasks:
- name: 内核版本清理
apt:
name: "linux-image-*"
state: absent
purge: yes
when:
- ansible_distribution == 'Ubuntu'
- ansible_kernel | version_compare('5.4', '<')
灾备恢复标准化流程
系统快照策略
# LVM快照创建 lvcreate -L 10G -s -n db_snap /dev/vg00/lv_db # 快照一致性验证 xfs_repair -n /dev/vg00/db_snap
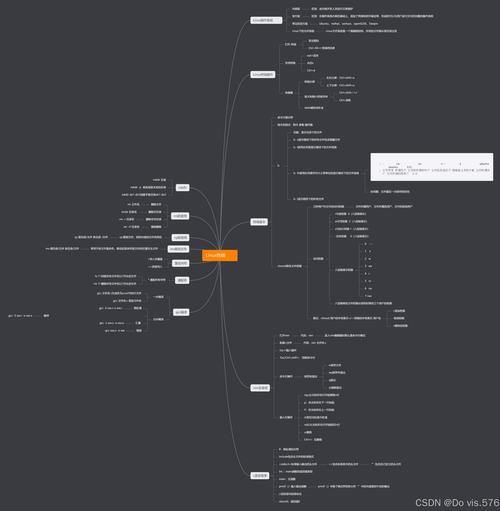
核心能力发展模型
-
诊断能力矩阵:
- 初级:日志分析/基础命令使用
- 中级:性能剖析/内核调试
- 高级:源码级问题定位
-
知识管理框架:
# 构建个人知识库 grep -r "OOM killer" /var/log/ > ~/knowledge/oom_cases.txt
-
效能提升路径:
- 年度目标:将MTTR降低30%
- 季度计划:掌握2种新型诊断工具
- 每周实践:分析1个真实故障案例
通过这套体系化方法,运维团队可实现从被动救火到主动防御的转变,典型实施效果包括:
- 故障发现时间缩短60%
- 复杂问题解决效率提升40%
- 系统可用性达到99.99%
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



