
Linux中的过滤命令,高效处理数据的利器?Linux过滤命令有多高效?Linux过滤命令真能提速?

在Linux系统中,数据过滤是一项核心技能,无论是日常系统管理、日志分析还是大数据处理,高效的文本处理能力都能显著提升工作效率,Linux提供了丰富而强大的命令行工具集,通过灵活组合这些工具,用户可以轻松应对各种复杂的数据处理需求,本文将全面介绍Linux中最常用的过滤命令,包括grep、awk、sed、cut、sort和uniq等,并通过实用示例展示它们在实际工作中的应用场景,帮助您掌握文本处理的精髓。
grep:文本搜索的瑞士军刀
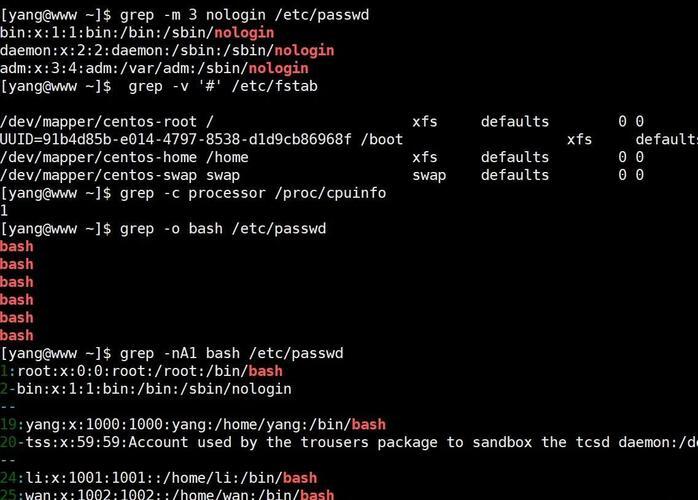
grep(Global Regular Expression Print)是Linux中最基础也最强大的文本搜索工具,它使用正则表达式进行模式匹配,是每位Linux用户必须掌握的利器。

核心功能与应用
# 基本搜索语法 grep "搜索模式" 文件名
实用示例:
# 在Nginx日志中查找404错误 grep " 404 " /var/log/nginx/access.log # 递归搜索目录下所有Java文件中的"main"方法 grep -r "public static void main" /project/src/ # 搜索时显示彩色高亮结果 grep --color=auto "error" system.log
高级选项详解
| 选项 | 功能描述 | 使用示例 |
|---|---|---|
-i |
忽略大小写 | grep -i "error" log.txt |
-v |
反向匹配(排除) | grep -v "DEBUG" app.log |
-n |
显示行号 | grep -n "Exception" error.log |
-c |
统计匹配行数 | grep -c "GET" web.log |
-A |
显示匹配行后的n行 | grep -A3 "panic" system.log |
-B |
显示匹配行前的n行 | grep -B2 "segfault" kern.log |
-E |
扩展正则表达式 | grep -E "50[0-9]" http.log |
-P |
Perl兼容正则表达式 | grep -P "\d{3}-\d{4}" contacts.txt |
-l |
只显示包含匹配项的文件名 | grep -l "deprecated" *.java |
专业技巧:
# 同时搜索多个模式(OR逻辑)
grep -e "Error" -e "Warning" -e "Critical" application.log
# 在压缩文件中搜索(需zgrep)
zgrep "OOM" /var/log/syslog.*.gz
# 使用上下文查看(显示匹配行前后内容)
grep -C2 "connection timeout" network.log
# 排除特定目录的搜索
grep -r --exclude-dir={.git,node_modules} "function" /project/
awk:数据处理的全能选手
awk不仅是一个命令,更是一门专门用于文本处理的编程语言,特别适合处理结构化数据(如CSV、日志等),其名称来自三位创始人Aho、Weinberger和Kernighan的姓氏首字母。
基础语法结构
awk 'BEGIN {初始化操作} 模式 {操作} END {结束操作}' 文件名
实际应用场景
数据提取与转换
# 提取/etc/passwd中的用户名和Shell(制表符分隔)
awk -F: '{print $1 "\t" $7}' /etc/passwd
# 转换日期格式(MM/DD/YYYY → YYYY-MM-DD)
awk -F'/' '{printf "%s-%02d-%02d\n", $3, $1, $2}' dates.txt
# 提取URL的域名部分
awk -F/ '{print $3}' url_list.txt
条件过滤与计算
# 筛选内存使用超过1GB的进程
ps aux | awk '$6 > 1048576 {print $0}'
# 计算CSV文件第二列的平均值(跳过空值)
awk -F, '$2 ~ /^[0-9]+$/ {sum+=$2; count++} END {print "平均值:",sum/count}' data.csv
# 统计不同HTTP状态码出现的次数
awk '{status[$9]++} END {for(s in status) print s,status[s]}' access.log
高级文本处理
# 多文件关联处理(类似数据库JOIN操作)
awk 'NR==FNR{a[$1]=$2; next} $1 in a {print $0,a[$1]}' file1 file2
# 生成数据报告(带格式化输出)
awk '{
count++;
sum+=$3;
if($3 > max || NR==1) max=$3;
if($3 < min || NR==1) min=$3
}
END {
printf "%-15s %12d\n", "记录数:", count;
printf "%-15s %12.2f\n", "平均值:", sum/count;
printf "%-15s %12d\n", "最大值:", max;
printf "%-15s %12d\n", "最小值:", min
}' sales.dat
性能优化技巧
- 预处理过滤:对于大文件处理,预先使用
grep过滤可以减少awk处理的数据量 - 变量初始化:在
BEGIN块中设置变量和初始值,避免重复计算 - 字符串处理:使用内置函数(如
substr、index)而非正则表达式 - IO优化:减少
print语句调用次数,合并输出操作 - 字段分隔:对于固定宽度数据,使用
FIELDWIDTHS而非FS
sed:流编辑大师
sed(Stream Editor)擅长对文本进行流式编辑,特别适合批量修改和转换任务,它以行为单位进行处理,是脚本自动化中不可或缺的工具。
核心语法模式
sed [选项] '编辑指令' 文件名
实用案例集锦
文本替换
# 全局替换(保留原文件备份) sed -i.bak 's/旧文本/新文本/g' file.txt # 条件替换(仅在第5-10行执行) sed '5,10s/foo/bar/g' data.txt # 仅替换每行的第二个匹配项 sed 's/pattern/replacement/2' file
行操作
# 删除空行和注释行 sed -e '/^$/d' -e '/^#/d' config.ini # 在匹配行后插入内容 sed '/pattern/a\插入的内容' file # 提取特定范围的行(类似head/tail) sed -n '10,20p' logfile # 删除HTML标签 sed 's/<[^>]*>//g' webpage.html
高级转换
# URL编码解码 sed 's/%\([0-9A-F][0-9A-F]\)/\\\\x\1/g' | xargs -0 printf "%b" # 多步编辑(使用-e连接多个命令) sed -e 's/foo/bar/' -e '/baz/d' -e 's/^/# /' config.ini # 转换Markdown标题为HTML sed -E 's/^# (.*)/<h1>\1<\/h1>/' doc.md
文件预处理
# 去除Windows换行符(CRLF → LF)
sed 's/\r$//' winfile.txt > unixfile.txt
# 标准化CSV文件(统一引号)
sed 's/"[^"]*"/\n&\n/g' data.csv | sed '/^"/s/,/;/g' | tr '\n' ' '
# 格式化JSON(简单缩进)
sed 's/[{[]/\n&\n/g;s/[]}]/\n&\n/g;s/,/\n,\n/g' compact.json
数据加工三剑客:cut、sort、uniq
cut:精准的列提取工具
# 提取特定列(CSV文件) cut -d',' -f1,3-5 data.csv # 提取第1,3,4,5列 # 按字符位置提取(固定宽度文件) cut -c1-8,20-30 access.log # 提取特定字符范围 # 排除特定列 cut -d';' --complement -f2 config.ini # 处理包含空格的字段 cut -d' ' -f1-3 --output-delimiter='|' log.txt
sort:智能排序引擎
# 多条件排序(数字+字母) sort -t',' -k2,2n -k3,3r sales.csv # 第2列数字升序,第3列降序 # 处理大文件(使用临时文件和并行) sort -T /tmp --parallel=4 -S2G hugefile.txt # 自然排序(版本号等) ls -v | sort -V # 忽略前导空格和标点 sort -f -b -k2,2 words.txt # 随机排序(洗牌) sort -R data.list
uniq:高效去重专家
# 统计出现频率(需先排序) cut -d' ' -f1 access.log | sort | uniq -c | sort -nr # 查找重复项(显示所有重复行) sort user_emails.txt | uniq -d # 比较两个文件的差异 comm -3 <(sort file1.txt | uniq) <(sort file2.txt | uniq) # 显示唯一行(不重复的行) sort log.txt | uniq -u # 忽略大小写去重 sort -f | uniq -i
命令组合的艺术:管道实战
Linux的真正威力在于命令的组合使用,通过管道(|)将简单工具连接成强大的处理流程,这种"组合大于复杂"的哲学是Unix设计理念的核心。
典型工作流示例
日志分析管道
# 分析Nginx日志:统计每个IP的请求数,按访问量降序
awk '{print $1}' access.log | sort | uniq -c | sort -nr | head -20
# 分解说明:
# 1. awk提取IP地址(第1列)
# 2. sort排序准备去重
# 3. uniq统计每个IP出现次数
# 4. sort按访问量数字降序
# 5. head显示前20条
# 进阶版:包含时间段的请求统计
grep "25/May/2023" access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -20
系统监控管道
# 找出内存占用最高的5个进程(带完整命令)
ps aux | sort -rnk4 | head -5 | awk '{print $4 "\t" $11}'
# 监控目录大小变化(带时间戳)
date +"%Y-%m-%d %H:%M:%S"; du -sh * | sort -h | tee dir_sizes.txt | tail -5
# 实时监控网络连接数
watch -n 1 "netstat -an | grep ESTABLISHED | wc -l"
数据清洗管道
# 清洗CSV数据:去重、过滤无效行、格式转换
grep -v "NULL" raw_data.csv |
awk -F, 'length($1)==10 && $2 > 0 {gsub(/"/, ""); print}' |
sort -u -t, -k1,1 |
sed 's/ */ /g' > cleaned_data.csv
# 处理后的数据可直接导入数据库或用于分析
进阶工具集锦
tr:字符转换专家
# 大小写转换 echo "Hello World" | tr 'a-z' 'A-Z' # 删除非打印字符 cat binary.log | tr -cd '\11\12\15\40-\176' # 压缩重复字符 tr -s ' ' < file_with_extra_spaces.txt # 加密解密(凯撒密码) echo "secret" | tr 'a-z' 'n-za-m' # 加密 echo "frperg" | tr 'a-z' 'n-za-m' # 解密
column:表格美化工具
# 格式化/etc/passwd为整齐的表格 column -t -s':' /etc/passwd # 结合其他命令使用 ps aux | head -5 | column -t # 自定义列宽 column -t -s $'\t' -c 80 wide_data.tsv
paste:文件合并工具
# 水平合并两个文件(并行行) paste file1.txt file2.txt > combined.txt # 使用分隔符连接 paste -d',' names.txt ages.txt > people.csv # 合并多个文件的列 paste -d $'\t' file*.txt > merged_data.tsv
join:关系型合并
# 类似SQL的JOIN操作(需先排序) join -t':' -1 3 -2 1 <(sort -t':' -k3 file1) <(sort -t':' -k1 file2) # 左连接(保留左边文件的所有行) join -a1 -t',' file1.csv file2.csv # 输出不匹配的行 join -v1 -t$'\t' sorted1.txt sorted2.txt
性能优化与最佳实践
-
处理大文件时的技巧:
- 使用
LC_ALL=C提升排序速度:LC_ALL=C sort bigfile.txt - 对于超大型文件,考虑使用
split分割后处理 - 使用
mawk替代gawk获得更好的性能 - 减少管道数量,合并相似操作
- 使用
-
正则表达式优化:
- 尽量使用具体模式而非通配符
- 避免过度使用反向引用和回溯
- 使用
fgrep或grep -F进行固定字符串搜索 - 在可能的情况下,使用
^和锚定模式
-
资源管理:
- 使用
ulimit控制内存使用 - 通过
nice调整进程优先级 - 考虑使用
pv监控管道数据流 - 对大文件处理使用
tmpfs或/dev/shm
- 使用
-
脚本化复杂操作:
#!/usr/bin/env bash
# 专业日志分析脚本示例
set -euo pipefail # 更安全的脚本设置
LOG_FILE="${1:-/var/log/application.log}"
OUTPUT_FILE="${LOG_FILE}.analysis.$(date +%Y%m%d%H%M%S)"
THRESHOLD="${2:-10}"
analyze_log() {
local input="$1"
local output="$2"
local threshold="$3"
echo "开始分析日志文件: $input" >&2
# 使用临时文件减少内存使用
local temp_file=$(mktemp)
# 多阶段处理
grep -E "(ERROR|WARN|CRITICAL)" "$input" |
awk -v threshold="$threshold" '
{
count++;
severity[$3]++;
last=$1 " " $2
}
END {
print "分析报告生成时间: " strftime("%Y-%m-%d %H:%M:%S")
print "===================================="
print "日志文件: " FILENAME
print "分析时间段: " $1 " - " last
print "总事件数: " count
print "------------------------------------"
print "按严重级别统计:"
for (s in severity) {
printf "%-10s %6d\n", s, severity[s]
}
print "===================================="
}' > "$temp_file"
# 格式化和排序
column -t "$temp_file" > "$output"
rm -f "$temp_file"
echo "分析完成,结果保存到: $output" >&2
echo "前$threshold条最频繁的错误:" >&2
grep "ERROR" "$input" | sort | uniq -c | sort -nr | head -n "$threshold"
}
analyze_log "$LOG_FILE" "$OUTPUT_FILE" "$THRESHOLD"
构建你的数据处理工具箱
Linux过滤命令的强大之处在于它们的模块化设计和完美的协作能力,通过熟练掌握这些工具,您可以:
- 快速分析:处理GB级别的日志文件只需简单命令组合
- 自动化:将复杂的数据转换任务脚本化,实现一键处理
- 构建管道:设计高效的数据处理流水线,提高工作效率
- 开发工具:创建专业的文本处理实用程序,解决特定问题
真正的技巧不在于记住所有选项,而在于理解每个工具的核心能力,并根据具体问题选择最佳组合,建议从实际需求出发,逐步构建自己的命令行工具集,最终成为数据处理的高手。
"在Linux中,没有数据处理问题,只有尚未找到的正确命令组合,掌握这些工具,就拥有了解决文本处理难题的万能钥匙。" —— 资深系统管理员经验谈
进阶学习资源:
- 《sed & awk》- Dale Dougherty
- 《Linux命令行与Shell脚本编程大全》- Richard Blum
- 《The Art of Command Line》- GitHub开源项目
- GNU官方文档(grep/sed/awk手册)
- Stack Overflow的Unix/Linux板块







