
Linux资源使用,监控、优化与管理指南?如何高效监控Linux资源?Linux资源监控怎么做?

** ,《Linux资源使用、监控、优化与管理指南》提供了全面策略,帮助用户高效管理Linux系统资源,监控是优化的基础,推荐使用内置工具(如top、htop、vmstat、iostat)实时跟踪CPU、内存、磁盘I/O及网络性能,sar(系统活动报告)适合长期分析,而dmesg可排查硬件或内核问题,优化需针对性调整:通过cgroups或nice限制进程资源,优化内核参数(如/proc/sys配置),清理冗余服务以降低负载,管理方面,定期日志轮转(logrotate)、自动化监控(如Prometheus+Grafana)及定期维护(更新、备份)是关键,高效监控需结合主动告警(如Zabbix)与可视化工具,快速定位瓶颈,确保系统稳定与性能最大化。
Linux作为一款高效稳定的操作系统,凭借其卓越的性能和出色的灵活性,已成为服务器、嵌入式设备和开发环境的首选平台,随着业务规模的扩大和系统负载的增加,如何有效地监控、优化和管理Linux系统资源,已成为系统管理员和开发工程师必须掌握的核心技能,本文将系统性地介绍Linux资源管理的完整方法论,涵盖从基础监控到高级优化的全套解决方案,帮助您构建高性能、高可用的Linux系统环境。
Linux资源监控体系
CPU资源监控
CPU作为系统的核心计算单元,其使用效率直接影响整体性能表现,以下是常用的CPU监控工具及其实践应用:
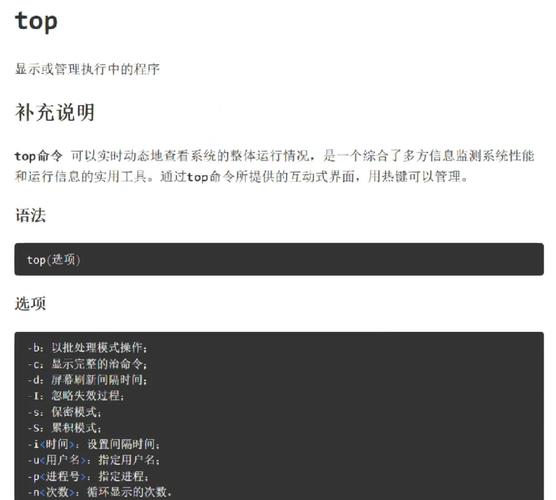
-
top/htop:实时监控工具,可直观展示CPU使用率、负载均衡和进程状态
top -b -n 1 | head -n 15 # 批处理模式获取CPU快照 htop --sort-key=PERCENT_CPU # 按CPU使用率排序
-
mpstat:多核CPU监控利器(需安装sysstat包)
mpstat -P ALL 2 5 # 每2秒采样一次,共5次,显示所有核心状态
-
perf:性能分析神器
perf stat -d ls # 基础性能统计 perf record -g -p <PID> # 记录进程调用栈
-
pidstat:进程级CPU监控
pidstat -u 1 5 # 每1秒监控一次进程CPU使用,共5次
内存资源监控
Linux采用先进的内存管理机制,理解其工作原理对性能优化至关重要:
-
free命令深度解析
free -h -s 3 # 每3秒刷新显示,人性化单位
-
smem高级内存分析
smem -t -k -p -u # 表格形式显示各用户内存占用比例
-
pmap进程内存剖析
pmap -x $(pgrep nginx) # 分析Nginx内存分布
-
内存泄漏检测方案
valgrind --leak-check=full ./application # 应用级内存检测
磁盘I/O监控
存储性能往往是系统瓶颈所在,需重点关注:
-
iostat全方位监控
iostat -xdm 2 # 每2秒显示扩展统计信息
-
iotop实时分析
iotop -oPa # 只显示活跃I/O进程,累计统计
-
LVM存储监控技巧

lvdisplay -v # 详细逻辑卷信息
-
Btrfs/ZFS高级监控
btrfs filesystem df / # Btrfs空间使用详情
网络资源监控
网络性能直接影响服务响应速度:
-
iftop流量分析
iftop -nNP -i eth0 # 不解析IP,显示端口号
-
nethogs进程追踪
nethogs -d 5 eth0 # 每5秒刷新eth0网卡进程流量
-
ss替代netstat
ss -tulnp4 # 显示所有TCP/UDP监听端口
-
tcpdump深度抓包
tcpdump -i eth0 -nn -w capture.pcap # 原始数据包捕获
系统优化策略精要
CPU性能调优
-
CPU亲和性设置
taskset -pc 0-3 1234 # 将PID1234绑定到0-3核
-
cgroups v2资源限制
echo "50000 100000" > /sys/fs/cgroup/cpu.max # 限制CPU使用
-
内核参数调优
echo "performance" > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
内存优化方案
-
透明大页配置
echo "madvise" > /sys/kernel/mm/transparent_hugepage/enabled
-
zRAM内存压缩
zramctl --find --size 2G --algorithm lz4 # 创建2G压缩交换设备
-
OOM Killer策略
echo "-17" > /proc/1234/oom_adj # 保护关键进程
存储I/O优化
-
调度器选择策略

echo "mq-deadline" > /sys/block/nvme0n1/queue/scheduler # NVMe优化
-
文件系统挂载选项
/dev/sda1 /data xfs noatime,nodiratime,logbufs=8 0 0
-
LVM缓存配置
lvcreate --type cache --size 10G --name cache0 vg/data # 创建缓存卷
网络性能调优
-
TCP协议栈优化
sysctl -w net.ipv4.tcp_fastopen=3 # 启用TFO客户端和服务器
-
网卡多队列配置
ethtool -L eth0 combined 16 # 启用16个队列
-
QoS流量控制
tc qdisc add dev eth0 root cake bandwidth 1Gbit # 现代QoS算法
自动化运维体系
监控系统集成
-
Prometheus+Grafana方案
# prometheus.yml示例 scrape_configs: - job_name: 'node' static_configs: - targets: ['localhost:9100'] -
ELK日志分析平台
filebeat modules enable system nginx # 启用系统日志收集
自动化运维脚本
-
资源监控脚本
#!/bin/bash LOG_FILE="/var/log/resource_monitor_$(date +%Y%m%d).log" echo "$(date) System snapshot:" >> $LOG_FILE top -b -n1 | head -10 >> $LOG_FILE free -h >> $LOG_FILE
-
自动扩容方案
# 磁盘空间自动检测 if [ $(df / --output=pcent | tail -1 | tr -d '%') -gt 90 ]; then lvextend -r -L +5G /dev/vg/root fi
典型问题解决方案
性能瓶颈诊断流程
- 症状分析:通过
dmesg、journalctl检查系统日志 - 资源定位:使用
atop进行综合资源分析 - 进程追踪:
strace -p <PID>跟踪系统调用 - 性能剖析:
perf record -g生成火焰图
生产环境最佳实践
- 建立性能基线:定期运行
sysbench测试 - 实施变更管理:使用
etckeeper跟踪配置变更 - 灾难恢复方案:配置
drbd实现实时数据同步
掌握Linux资源管理需要理论知识与实践经验的结合,建议读者:
- 建立系统性能基准档案
- 实施渐进式优化策略
- 定期进行压力测试验证
- 关注Linux内核最新发展动态
通过本文介绍的全套方法论,您将能够构建出高性能、高可用的Linux系统环境,为业务发展提供坚实的底层支撑,优秀的系统管理员不仅会解决问题,更能预见问题。



