
Spark on Hive表结构变更

Spark on Hive表结构变更
-
-
-
- 1、表结构变更概述
-
-
1、表结构变更概述
在Spark on Hive架构中,表结构(Schema)变更是一个常见且重要的操作。理解其背景、使用场景以及具体方式对于大数据平台管理至关重要
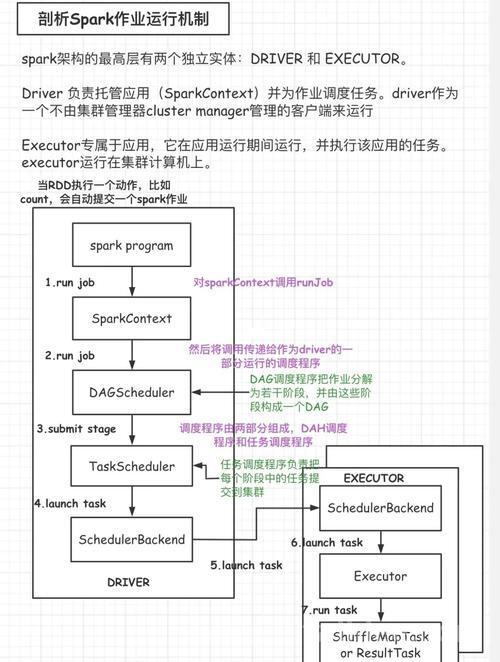
1.1、Spark on Hive元数据管理
- Hive Metastore(HMS): 核心组件。它是一个独立的关系型数据库(如MySQL、PostgreSQL),存储了Hive表、分区、列、数据类型、存储位置等元数据信息
- Spark: Spark本身不存储元数据。当Spark需要处理Hive表时,它通过HMS连接到Hive Metastore数据库,获取表的元数据(Schema、分区、文件位置等)
- Spark on Hive: 指Spark被配置为使用Hive的Metastore服务。这意味着:
- Spark可以读取Hive中定义的表
- Spark可以创建表,并将元数据写入Hive Metastore,使得这些表也能被Hive或其他配置了相同Metastore的工具访问
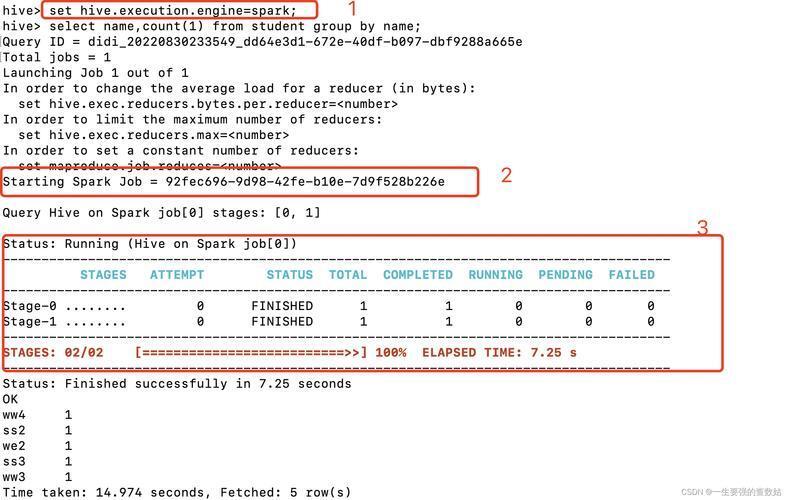
- SparkSQL的CREATE/ALTER TABLE等DDL语句实质上是通过Spark向Hive Metastore发出操作指令,由Hive Metastore执行元数据变更
1.2、表结构变更的背景
- 1)业务需求演进
- 新增业务指标需要记录新的字段
- 业务逻辑变化,业务口径改变
- 2)数据模型优化
- 调整数据类型以提高存储效率或计算精度(例如STRING改为TIMESTAMP用于时间计算,INT改为BIGINT防止溢出)
- 添加分区字段以大幅提升特定查询性能和管理效率
- 添加分桶字段优化JION和采样性能
- 3)数据治理
- 添加列注释、表注释,以提高可理解性
- 执行新的贯标,使数据符合新的标准和规范
- 4)错误修正
- 初次建表时定义有误(列名写错、数据类型选错等)
1.3、表结构变更的常见操作
- 添加列 (ADD COLUMN): 在表末尾添加新列,通常对现有数据无影响
- 删除列 (DROP COLUMN): 移除不再需要的列,在Hive中,这通常只对元数据操作,物理数据文件中的旧数据可能不会立即删除,Spark读取时将忽略这些被删除列的数据
- 重命名列 (RENAME/CHANGE COLUMN): 修改列名,需要更新所有引用旧列名的查询和作业
- 修改列数据类型 (CHANGE COLUMN): 更改现有列的数据类型,风险较高,必须确保现有数据能安全转换为新类型,否则查询可能失败或数据损坏,Spark/Hive不会自动转换现有文件中的数据
- 修改列顺序 (CHANGE COLUMN
(图片来源网络,侵删)
(图片来源网络,侵删)

(图片来源网络,侵删)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







