
数据分析:3小时速通SQL必学必会(第一节)

数据库基础
什么是数据库?
DataBase(DB):数据库就是存放数据的地方。
什么是数据库管理系统?
DateBase Management System(DBMS):熟知的MySQL,SQL Server,Orcle,PostgreSQL。。。都是数据库管理系统。简单理解,是一个软件用来操作数据库的。
数据库里面有什么?
数据库:按照数据结构组织存储和管理数据的地方。
表:结构化的集合,存放数据的记录;表要有列名,数据类型和约束;
字段:表中的一列就是一个字段;
记录:表中的一行一条记录
视图:通过查询表来生成的一张数据视图;本身不存储数据;会随着表数据变化而更新;主要用于提高数据安全性,实现逻辑数据独立性;
索引:加速数据检索,帮助数据库引擎快速定位数据,而不是扫描整个表;
元数据信息:表名、字段名、数据类型、约束(主键、外键)。
数据类型:整型(int),浮点型(float,double,)decimal,字符串(varchar),string;
数据库里面的东西:表;视图;函数;事件;查询;报表;备份(以MySQL为例;图片是以Navicat连接MySQL的可视化图形;Navicat就是一个可以使用和管理数据库的工具);
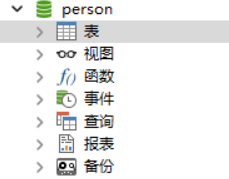
数据库怎么用?
数据的导入导出,存储数据+增删改查
数据流程链路
Data Flow Pipline:数据从产生到最终应用的全生命周期路径;
数据采集(获取)->数据传输->数据存储->数据处理(清洗)->数据分析与挖掘->数据应用
数据采集:系统数据,日志数据…通过某种方式对数据进行记录;
举个例子:用户浏览点击通过埋点记录;
数据传输:将记录的数据传输到存储或处理的地方;
数据存储:持久化存储数据;使用数据库;
数据处理(清洗):ETL(extract-transform-load):提取-转化-加载;
关键处理:缺失值、异常值,处理日期格式;
数据分析与挖掘:数据洞察或数据价值挖掘;
数据应用:洞察结果和数据价值反馈业务,进行落地监控迭代;
SQL
大家都在讲SQL,SQL,什么是SQL?
SQL:用于管理和操作关系型数据库的标准编程语言。
可以使用SQL对数据进行 增、删、更、查;以及管理数据库结构。
SQL非常简单只要会写SELECT…FROM…WHERE
select no,name,age --你要查询的字段,select 列名1,列名2,列名3 from student_info --你要查询的表名 from 表名称 where no=0001 --你要限制的筛选条件where 条件,no是0001,name是‘牛马小joker’ and name='牛马小joker'
你就可以查询数据了!
从哪里查数据呢?
数据库的数据表中…
如果创建数据库数据表呢?
CREATE DATABASE mydatabase; --create DATABASE 你的数据库名称
CREATE TABLE employees ( -- create Table 你的表名
id INT PRIMARY KEY, --列名:id 数据类型:int,约束:主键
name VARCHAR(100) NOT NULL, --列名:name 数据类型:字符串,约束:非空
email VARCHAR(100) UNIQUE, --列名:email 数据类型:字符串,约束:唯一
department VARCHAR(50),
salary DECIMAL(10,2) DEFAULT 0,
hire_date DATE,
--INDEX idx_department (department) --index :创建索引,给department列创建索引,当查询departent列时查询速度会更快;
);
建表的图:帮助大家理解一下
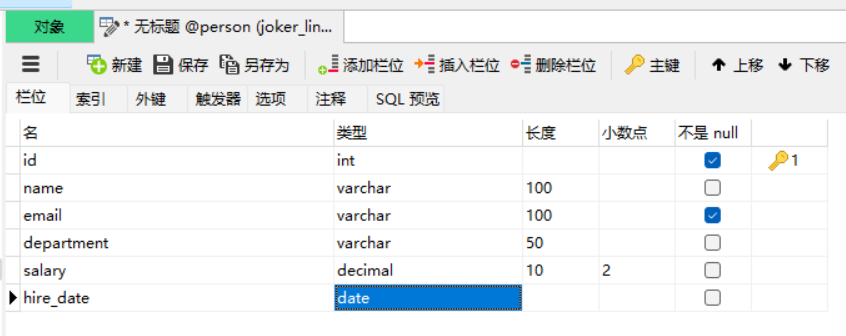
输入表名就创建好了;创建好了之后长这样;
怎么插入数据库中的数据呢?
怎么更新数据呢?
怎么删除数据库表呢?
这三个问题问问AI
数仓分层
为什么要进行数仓分层?
为了更好的对数据进行规范化的管理,高效复用以及业务解耦;
什么是数据仓库?
简单理解一个数据集成平台;
数据仓库与数据库的区别是什么?
数据库是用于高效存储、管理和操作业务实时数据的软件系统,支持数据的增删改查(CRUD),专注于处理高并发、低延迟的在线事务处理(OLTP);
数据仓库是面向分析的历史数据集成平台,通过清洗、转换、整合多源数据,支持复杂查询和决策分析(OLAP);
简单理解一下:数据库主要用来存储数据(直接接入进来的最底层数据);数据仓库主要用来分析数据;(这样的表述可能不太准确,主要是为了方便理解)
数仓是怎么分层的?
复习一下数据链路:数据采集(获取)->数据传输->数据存储->数据处理(清洗)->数据分析与挖掘->数据应用
看数仓分层:
ODS:操作数据层(原始数据层):与业务数据保持同步;直接接入业务数据库;
DWD: 明细数据层:面向业务过程的干净明细数据;是ODS经过数据清洗后的数据;
DWS:服务数据层:面向业务主题的汇总数据;用于通用分析场景;一般是按照一定主题(维度)进行聚合指标;构建宽表;
ADS:应用数据层:高度定制化加工数据,直接适配BI工具和报表需求;可直接对接下游应用(如API和数据大屏);
DIM:(维度层):存储维度数据(如:时间地域和商品类目):提供一致性维度(确保不同事实表的维度ID一致)需要全量更新;
举个例子:
以电商场景为例,说明数据如何逐层加工:
- ODS层: 原始订单表 ods_order(含未清洗的脏数据)。
- DWD层: 清洗后生成 dwd_order_detail(去重、补全用户ID、标准化金额单位)。
- DWS层: 按用户聚合生成 dws_user_order_summary(总订单数、月消费金额)。
- ADS层: 生成 ads_vip_user_analysis(高价值用户名单,供运营推送优惠券)。
分层设计要注意什么?
- 高内聚低耦合:每层仅依赖下层,禁止跨层调用。
- 数据一致性:统一维度(DIM层如时间、区域)贯穿所有分层。
- 效率与成本平衡:
ODS层保留全量数据(存储成本高但可回溯)。
ADS层按需存储(查询快但冗余可能增加)。
- 元数据管理:记录各层表的血缘关系
全量更新与增量更新
刚才讲DIM层维表要全量更新,
什么是全量更新?
简单理解:每次更新时覆盖之前的数据;无论是否发生变化,都要重新写入全量数据;全量数据表一般以df结尾;
举个例子:dwd_user_order_info_df
什么是增量更新
仅更新新增(或者修改)的数据,未变化的部分不动。
适用场景:实时日志数据;
举个例子:dws_user_log_di
因为业务每天都在发生,数据每一分每一秒都在产生;所以考虑资源存储以及方便查询;选择不同的更新方式很重要!
怎么更新的?
分区概念:将大表按照一定规则(时间或者区域)分割成独立存储的小块;物理存储上分离但逻辑上还是一张表;
的思想!(类似Hadoop集群分布式存储和计算)
简单理解:一个大文件夹A里面多个小文件夹abc,物理上分离指的是a,b,c存储在不同的磁盘上DEF,但当你查询A时,可以看到abc;
一张图看懂全量更新和增量更新:按天分区;分区字段ds:
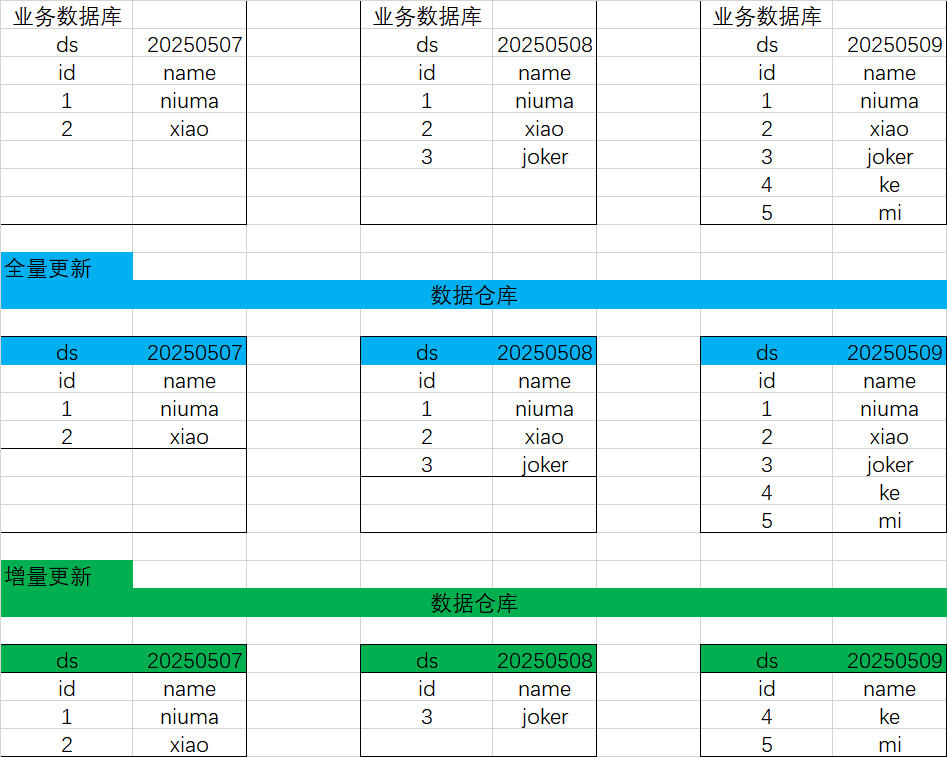
简单理解:全量更新-覆盖之前的分区,全部写入新分区;
增量更新:新分区只更新新增或修改部分;
下一节:SQL必会函数语法、表的连接,子查询嵌套with子句,窗口函数等。。。







