
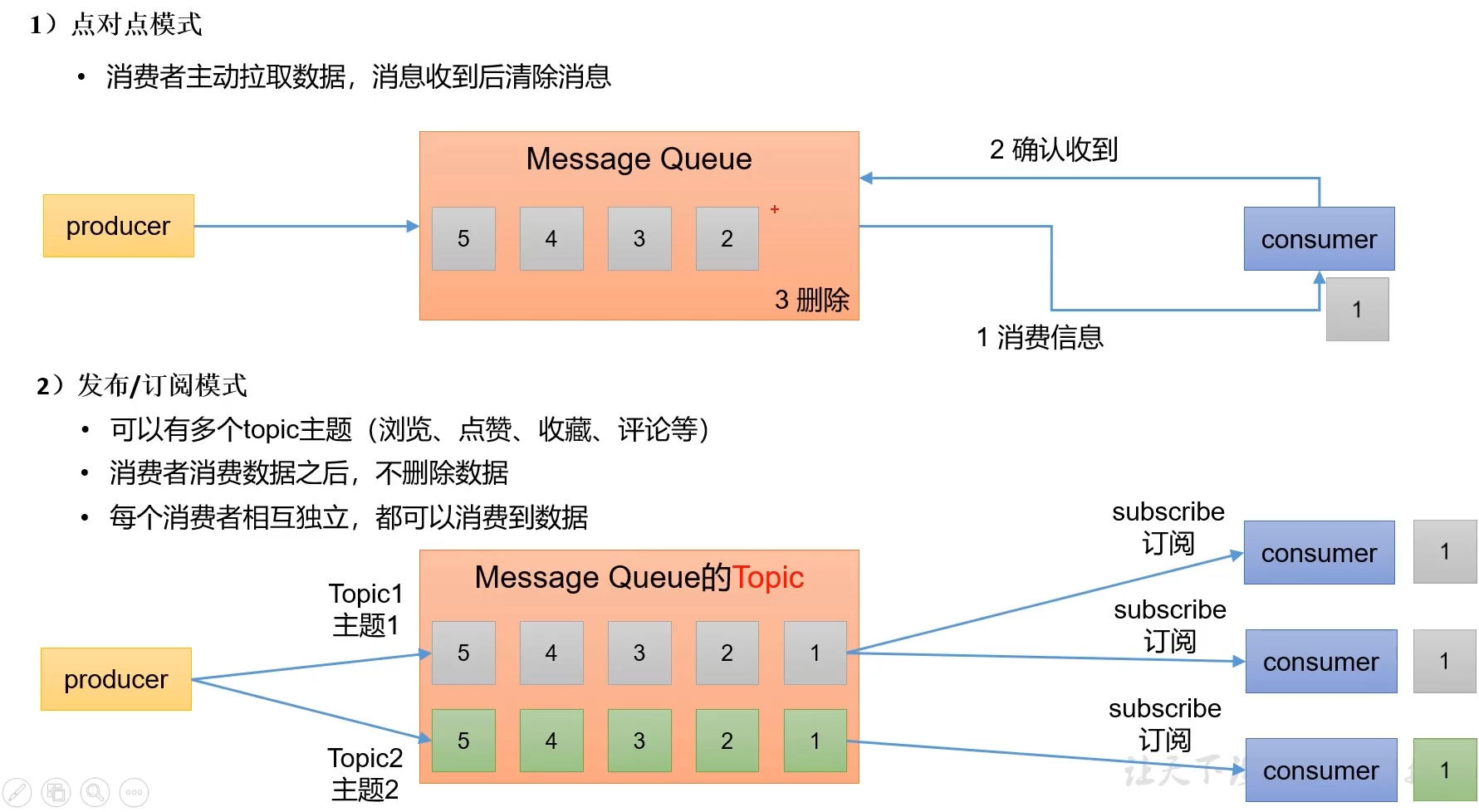
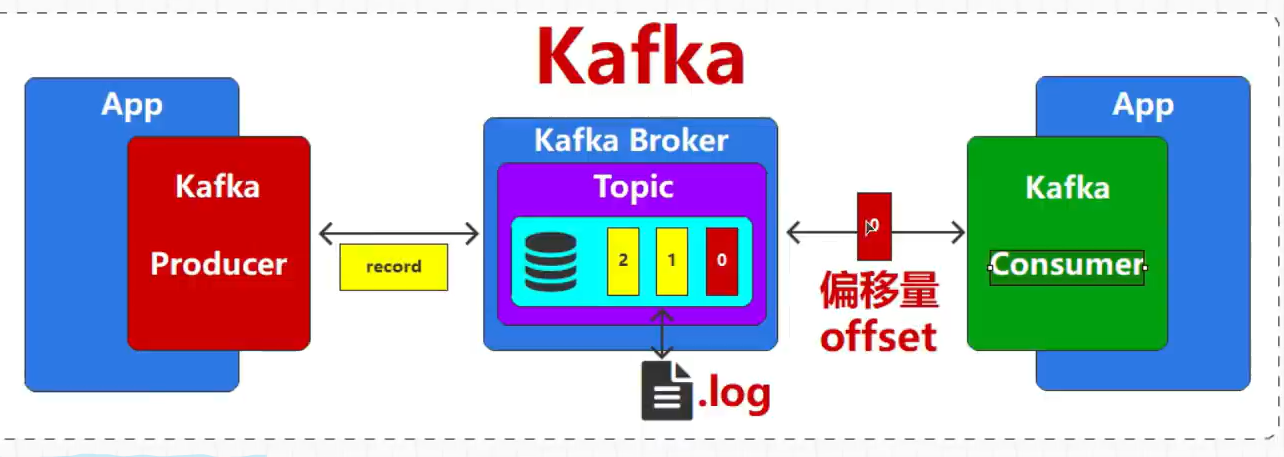
Kafka消息中间件

window中的安装
①、下载并解压kafka压缩包,进入config目录下修改zookeeper.properties配置文件
因为kafka内置了zookeeper,所以不需安装zookeeper。设置zookeeper数据存储位置,如果该路径不存在,则自动创建
dataDir = E:/kafka/data/zk
②、进入bin目录下(linux脚本命令),进入window下属于window命令
cd bin/windows
执行:zookeeper-server-start.bat …/…/config/zookeeper.properties
为了后续的方便启动,可以创建一个zk.cmd文件
文件内容如下:

③、进入kafka的config目录下,修改server.properties配置文件
log.dirs=E:/kafka/local/data/
④、进入bin/windows目录下启动:kafka-server-start.bat …/…/config/server.properties
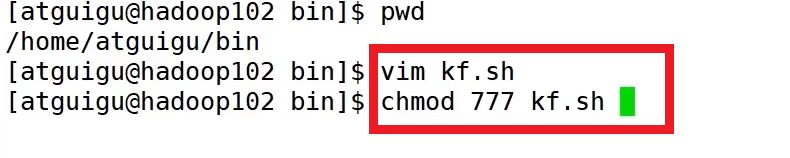
为了后续的方便启动,可以创建一个kfk.cmd文件
文件内容如下:

⑤、查看启动后的进程

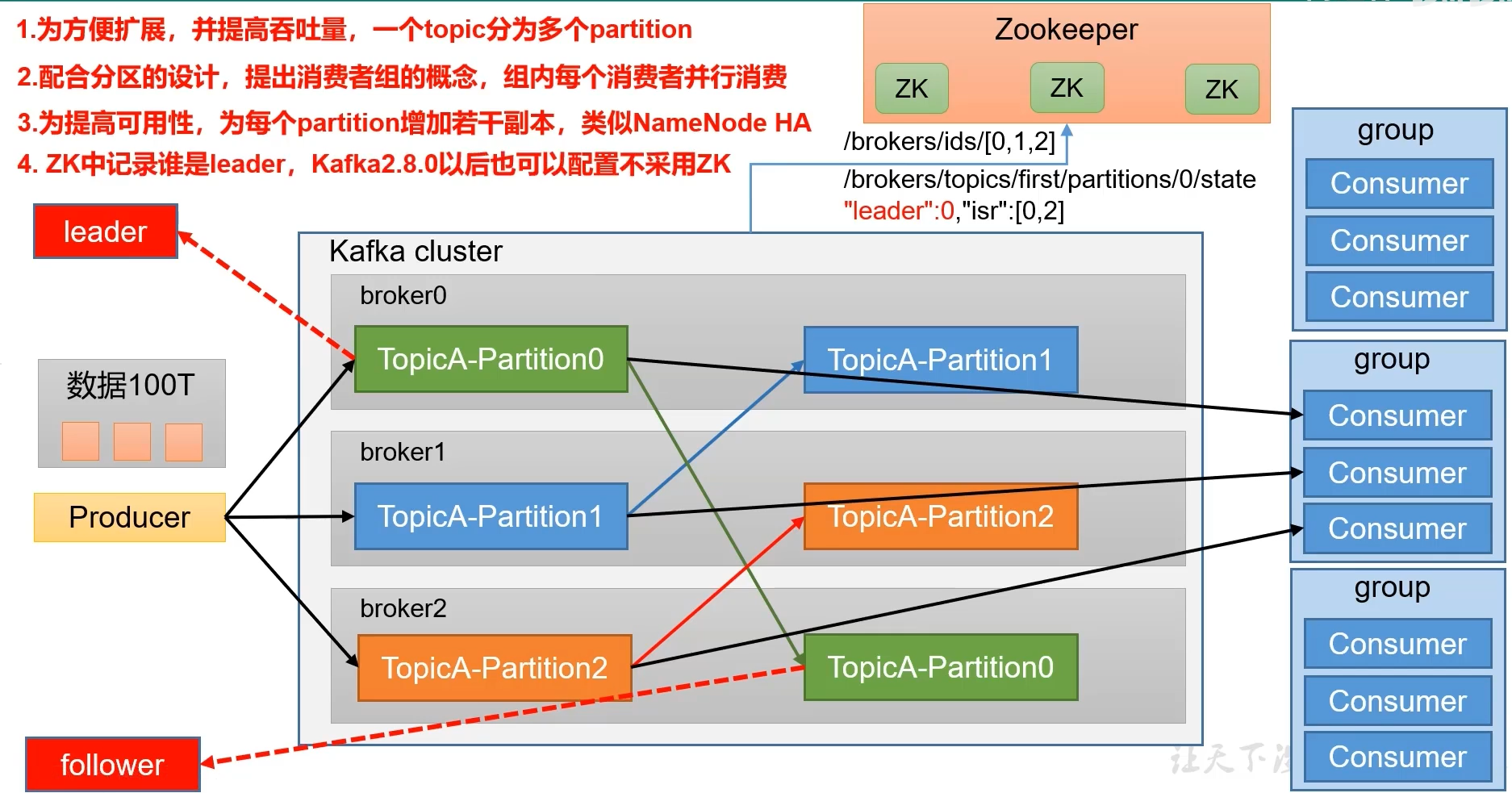
集群规划安装
①、准备三台服务器

②、在其中一台服务器上操作:

server.properties主要修改的内容:



③、通过命令xsync kafka 将其分发到其他服务器,并修改每台服务器的server.properties中broker.id的值


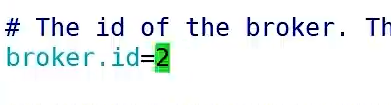
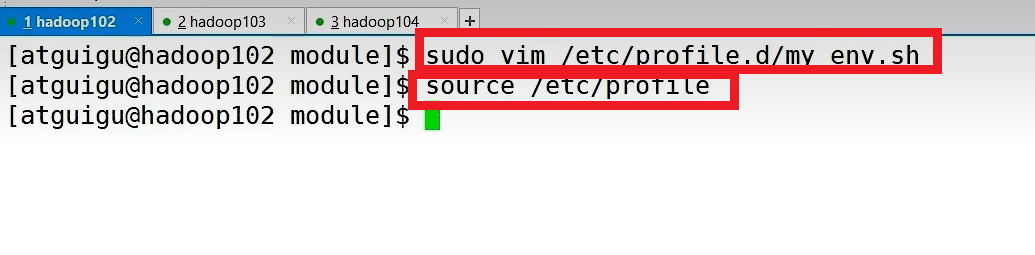
④、配置kafka环境变量

将xsync脚本分发到其他服务器

④、启动zookeeper:sk.sh start
启动kafka:

启动、停止脚本
#!/bin/bash case $1 in "start") for i in hadoop102 hadoop103 hadoop104 do echo "---启动 $i kafka ---" ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -ddaemon /opt/module/kafka/config/server.properties" done ;; "stop") for i in hadoop102 hadoop103 hadoop103 do echo "---停止 $i kafka ---" ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh" done ;; esac

命令行操作:
-
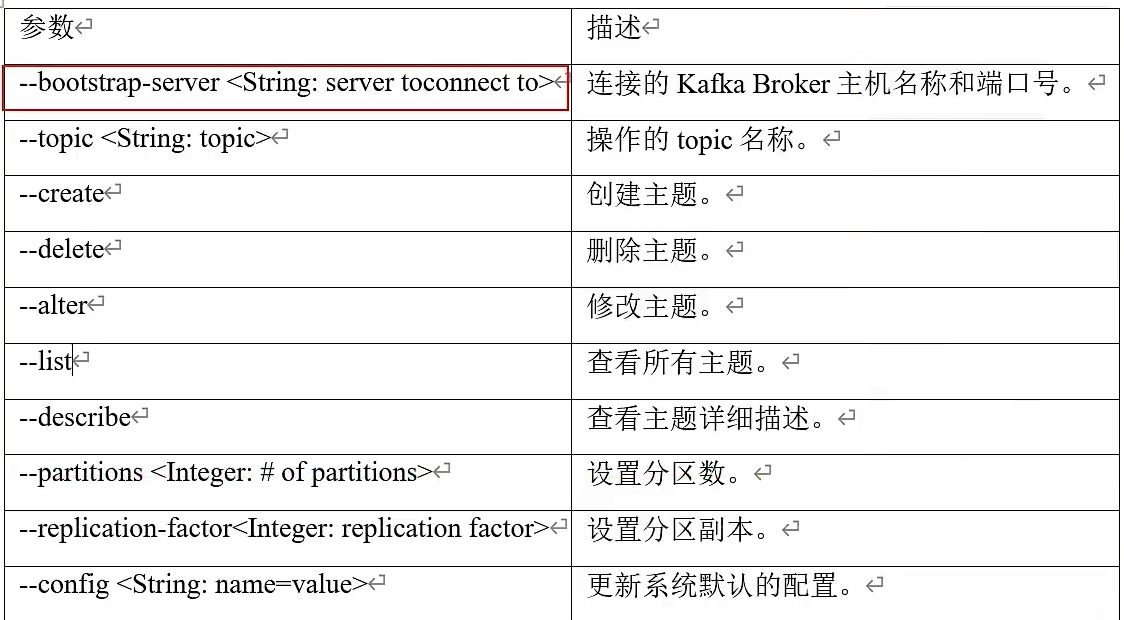
主题 kafka-topic.sh
(1) --bootstrap-server hadoop102:9092,hadoop103:9092 连接服务器
(2) --topic first
(3) --create
(4) --delete
(5) --partitions 分区
(6) --replication-factor 副本
-
生产者 kafka-console-producer.sh
(1) --bootstrap-server hadoop102:9092,hadoop103:9092 连接服务器
(2) --topic first
-
消费者 kafka-console-consumer.sh
(1) --bootstrap-server hadoop102:9092,hadoop103:9092 连接服务器
(2) --topic first
window命令行
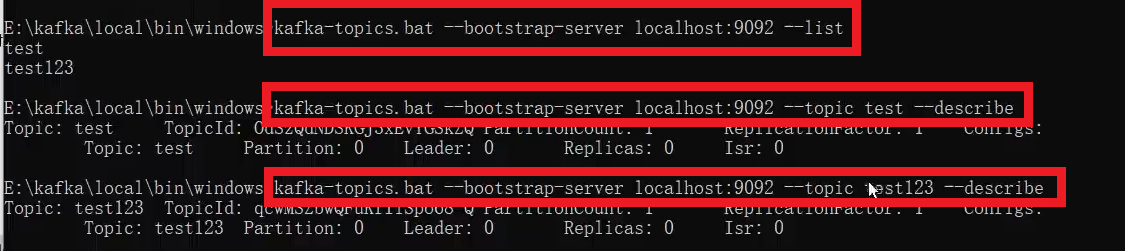
主题创建

如果JDK版本过低,会出现很多日志,所以提高JDK的版本,再创建主题

可以修改以下文件,重新设置JDK环境变量:

查看(包括详细查看):
修改:

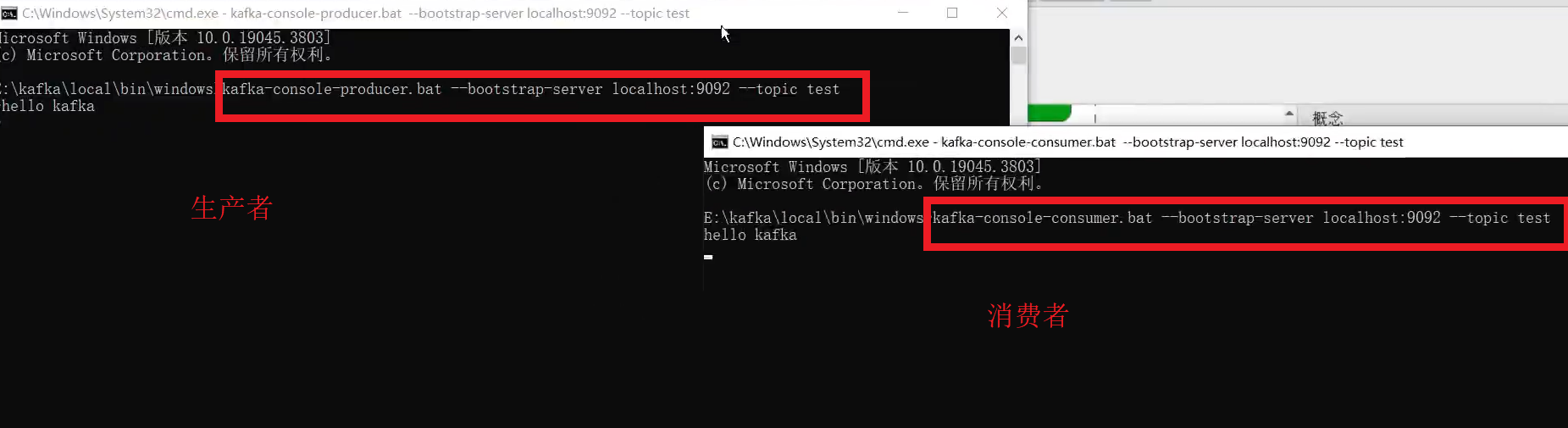
生产者和消费者
linux命令行
bin/kafka-topics.sh # 显示所有操作选项 bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list #查看当前服务器所有的topic #创建first主题,指定分区,指定副本数 bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first --create --partitions 1 --replication-factor 3

# 修改分区数,只能增加,不能减少 bin/kafka-topics.sh --bootstrap=server hadoop102:9092 --topic first --alter --partitions 3
# 生产者连接 hadoop102:9092的first主题,生产消息 bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first >hello # 消费者相对应地消费消息 bin/kafla-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first bin/kafla-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --from-beginning #查看消费所有的历史记录
代码操作
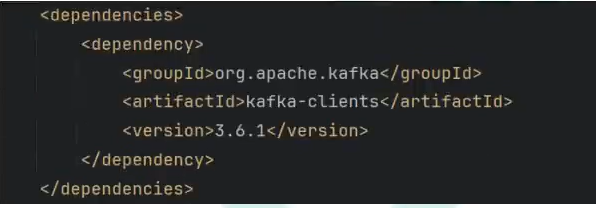
①、创建项目并添加依赖
②、生产者
public class KafkaProducerTest{ public static void main(String[] args){ //创建配置对象 Map configMap = new HashMap(); configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092"); configMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//对key/value进行序列化 configMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); //创建生产者 KafkaProducer producer = new KafkaProducer(configMap); //创建数据 ProducerRecord record = new ProducerRecord( "test", "key", "value" ); //通过生产者对象将数据发送到kafka producer.send(record); //关闭生产者对象 producer.close(); } }③、消费者
public class KafkaConsumerTest{ public static void main(String[] args){ Map consumerConfig = new HashMap(); consumerConfig.put(ConsumerConfig.BOOTSTRAP_ERVERS_CONFIG,"localhost:9092"); consumerConfig.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());//对key/value进行反序列化 consumerConfig.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); consumerConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"atguigu") KafkaConsumer consumer = new KafkaConsumer(consumerConfig); //订阅主题 consumer.subscribe(Collections.singletonList("test")); //从kafka的主题中获取数据,参数为超时时间 final ConsumerRecords datas = consumer.poll(100); for(ConsumerRecord data:datas){ System.out.println(data); } //关闭消费者对象 consumer.close(); } }Kafka工具

双击安装之后
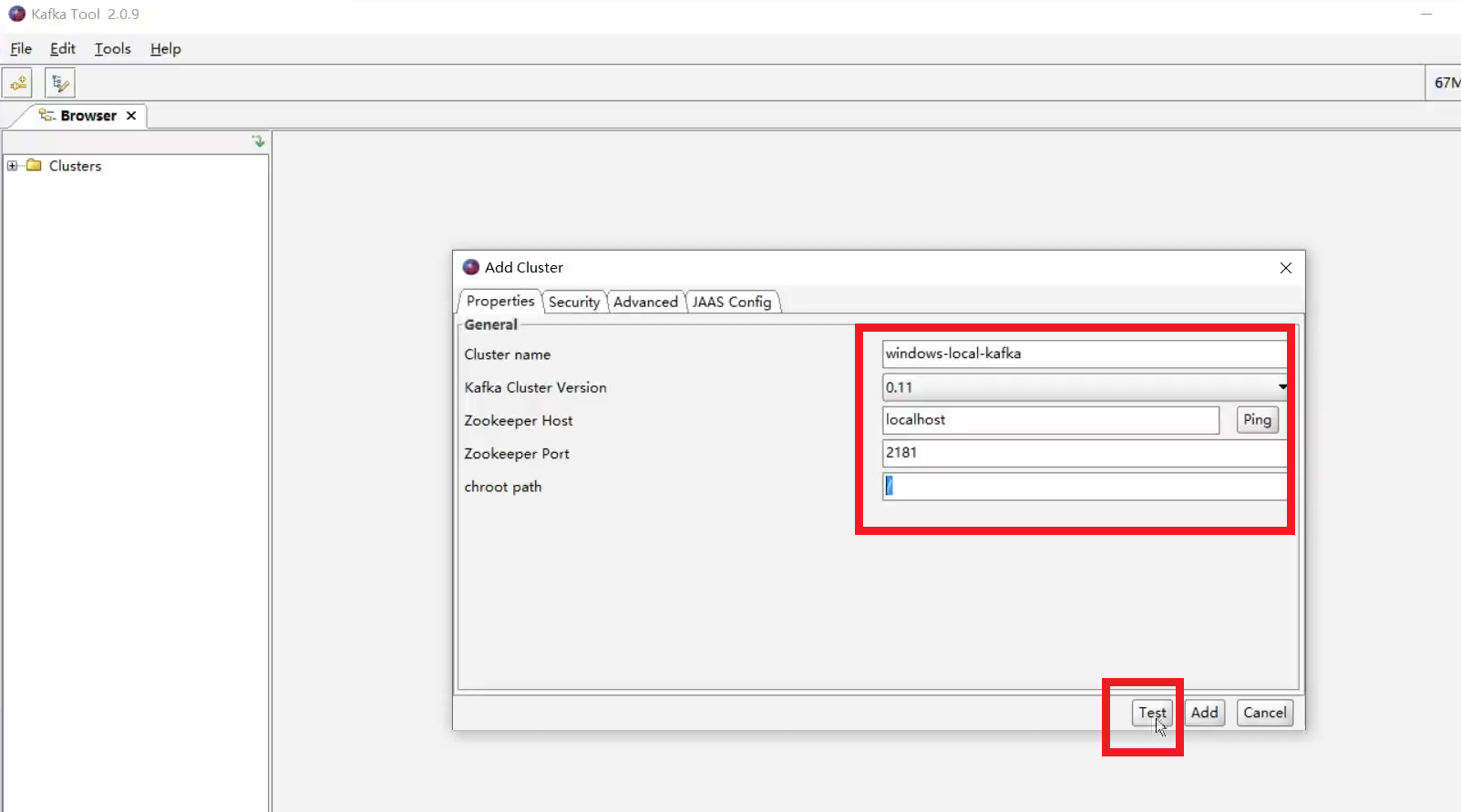
创建主题
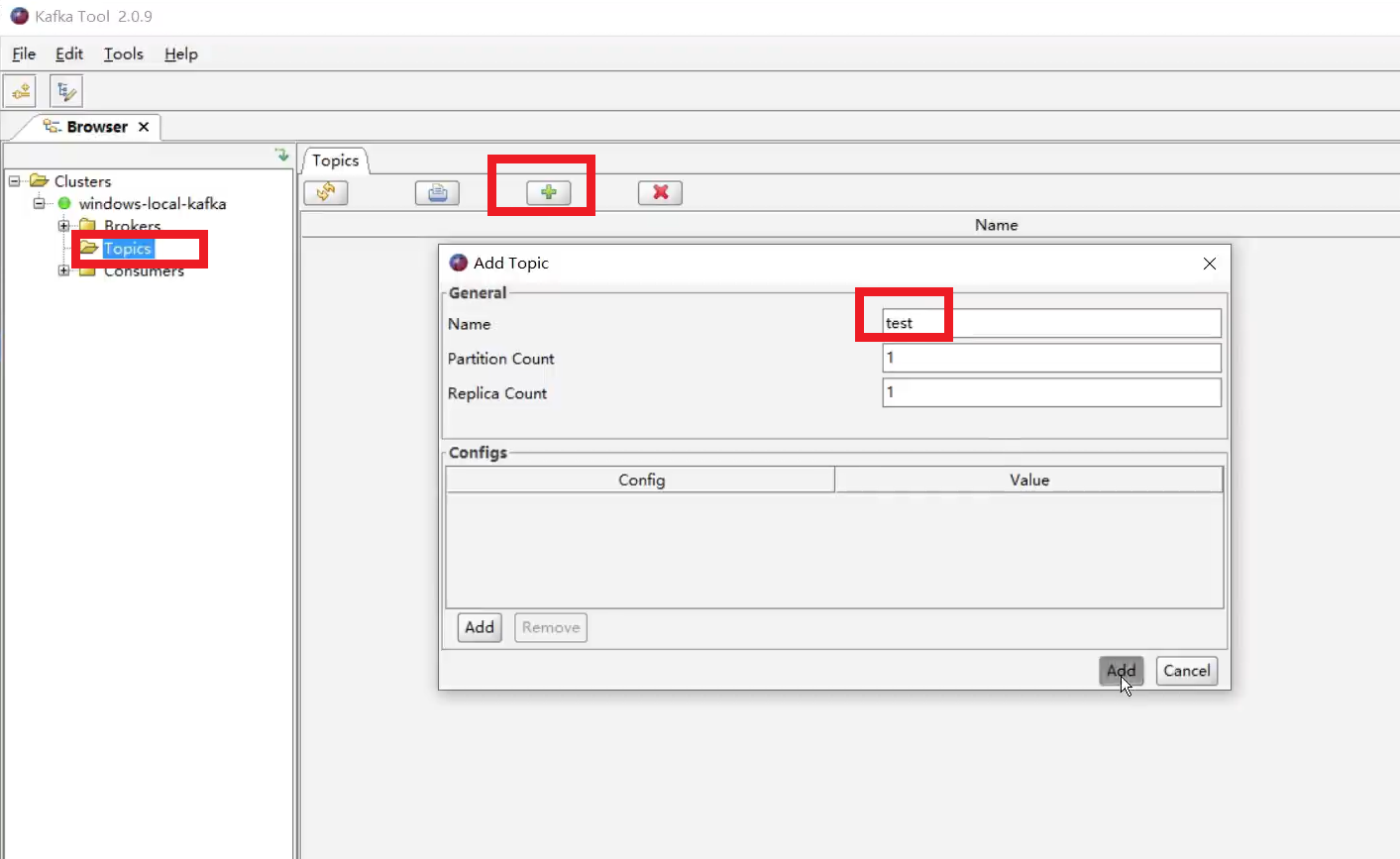
添加数据
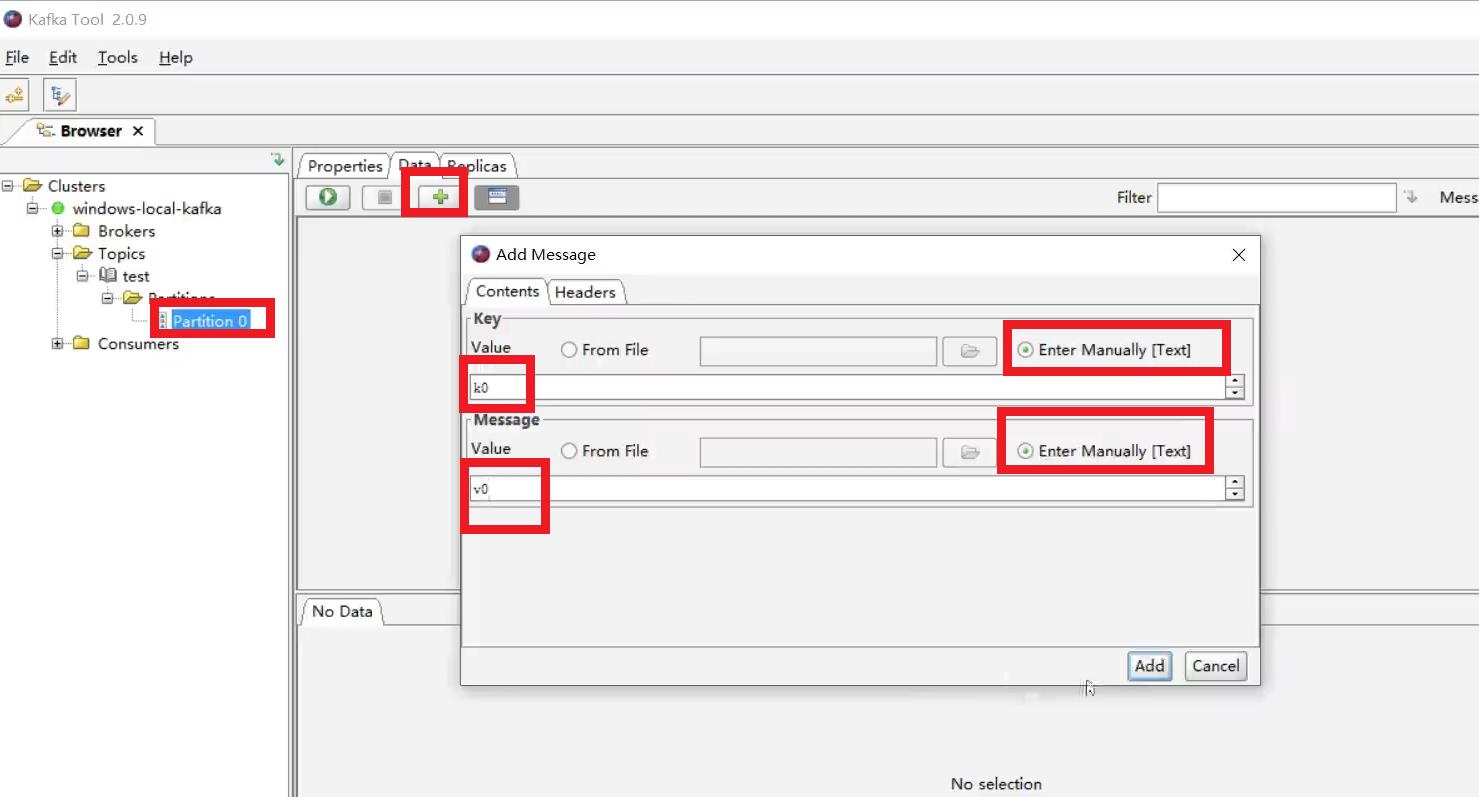
查看数据
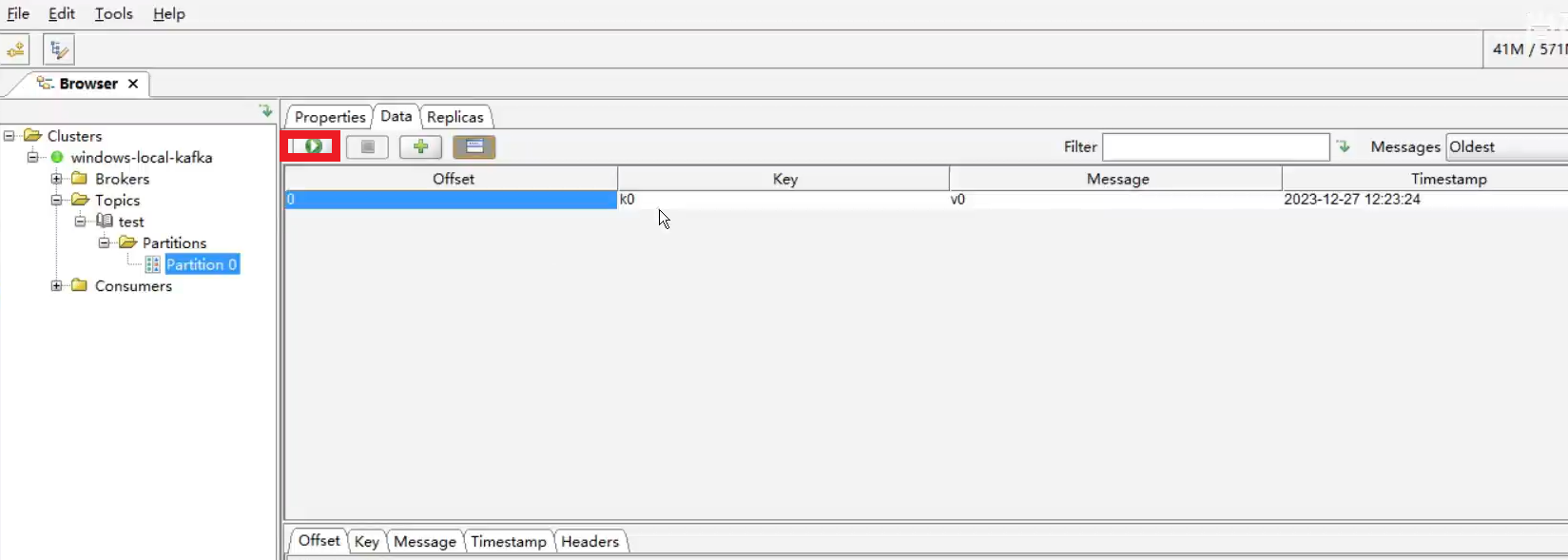
生产者
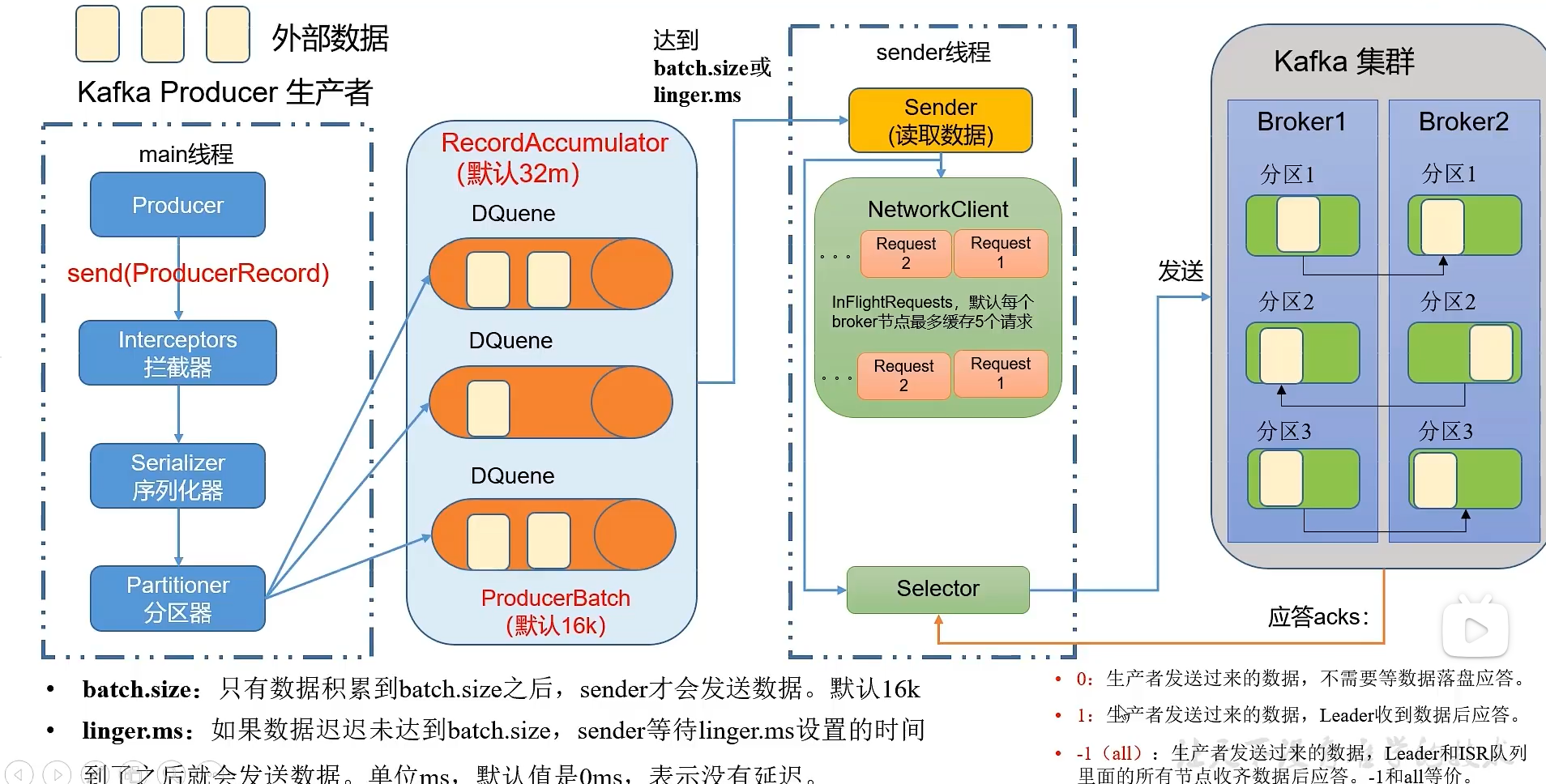
生产者三种发送方式:
- 异步发送 kafkaProducer.send(new ProducerRecord(“first”,“atguigu”+i));
- 异步回调发送 kafkaProducer.send(new ProducerRecord(“first”,“atguigu” + i),new Callback(){}
- 同步发送 kafkaProducer.send(new ProducerRecord(“first”,“atguigu”+i)).get();
public class CustomProducer{ public static void main(){ //配置 Properteis properties = new Properties(); //连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092"); properties.put(PorducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); properties.put(PorducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); //1.创建Kafka生产者对象 KafkaProducer kafkaProducer = new KafkaProducer(properties); //2.发送数据 for(int i=0;i //异步发送 kafkaProducer.send(new ProducerRecord @Override public void onCompletion(RecordMetadata metadata,Exception exception){ if(exception == null){ System.out.println("主题:"+metadata.topic()+"分区:"+metadata.partition()); } } }); //发送同步数据 kafkaProducer.send(new ProducerRecord @Override public void onCompletion(RecordMetadata metadata,Exception exception){ if(exception == null){ System.out.println("主题:"+metadata.topic()+" 分区: "+metadata.partition()); } } }); @Override public int partition(String topic,Object key,byte[] keyBytes,Object value,byte[] valueBytes,cluster cluster){ String msgValues = value.toString(); int patition; if(msgValues.contains("atguigu")){ partition = 0; }else{ partition = 1; } return partition; } @Override public void close(){ } @Override public void configure(Map } } public static void main(){ //配置 Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); //缓存区大小 properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432); //批次大小 properties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384); //linger.ms properties.put(ProducerConfig.LINGER-MS_CONFIG,1); //压缩 properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy"); //生产者 KafkaProducer kafkaProducer.send(new ProducerRecord public static void main(){ //配置 Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName()); //acks,数据的可靠性 properties.put(ProducerConfig.ACKS_CONFIG,"1"); //重复次数 properties.put(ProduceConfig.RETRIES_CONFIG,3); //发送数据 for(int i = 0;i kafkaProducer.send(new ProducerRecord for(int i = 0;i







