
MySQL 窗口函数

核心目标: 深入理解并熟练运用 MySQL 窗口函数,掌握其在复杂数据分析场景(如行间比较 📊, 趋势分析 📈, 分组排名 🏆, 累计计算 ➕)中的强大能力。
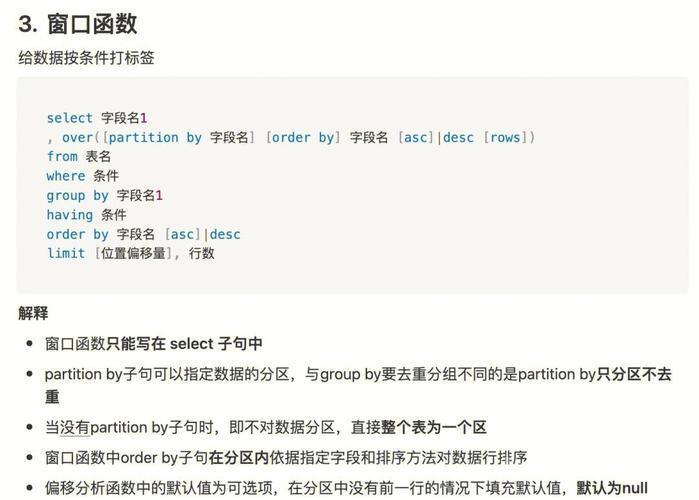
窗口函数基本概念: 🤔
窗口函数对查询结果集的一个特定子集(称为“窗口” 🪟)执行计算。它为结果集中的每一行都生成一个计算结果,而不改变原始行的数量。这与将多行合并为一行的聚合函数(如配合 GROUP BY 使用时)形成对比。窗口的定义和行为由 OVER() 子句控制。
窗口函数基础语法与 OVER() 子句: ⚙️
窗口函数的核心在于 OVER() 子句。
语法:
window_function_name() OVER (
[PARTITION BY partition_expression, …]
[ORDER BY order_expression [ASC|DESC], …]
[frame_clause]
)
解析 OVER() 子句的组成部分:
-
window_function_name: 具体的窗口函数名称。 🔢
-
PARTITION BY partition_expression, …` (可选): 🍰
将结果集划分为独立的逻辑分区 (Partitions)。函数在每个分区内独立计算。
示例:按部门分区
-- 按 dept_name 分区,后续函数将在此分区内计算 ... OVER (PARTITION BY dept_name ...)
-
GROUP BY 与 PARTITION BY 的核心区别 (重要对比): 🆚
 (图片来源网络,侵删)
(图片来源网络,侵删)- GROUP BY: 是聚合操作,合并行并减少行数,目的是汇总数据。
- PARTITION BY: 是窗口定义的一部分,不合并行,不改变行数,目的是为窗口计算划定范围。
-
ORDER BY order_expression [ASC|DESC], ... (对某些函数必须): 📊➡️
定义分区内部行的处理顺序。
 (图片来源网络,侵删)
(图片来源网络,侵删)示例:分区内按工资降序
-- 分区内按 salary 降序排列 ... OVER (... ORDER BY salary DESC ...)
frame_clause (可选,定义精确的自定义窗口框架): 🖼️
 (图片来源网络,侵删)
(图片来源网络,侵删)精确控制窗口函数计算时包含的行的集合。
语法:
{ROWS | RANGE} frame_start
或
{ROWS | RANGE} BETWEEN frame_start AND frame_end
-
ROWS vs RANGE:
- ROWS: 基于物理行数偏移。
示例:当前行及前 2 行
-- ROWS frame example ... OVER (... ORDER BY some_col ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
- RANGE: 基于逻辑值范围,依赖 ORDER BY 列。处理重复值 (peers) 时行为不同。
示例:当前日期及之前 7 天内的数据
-- RANGE frame example (assuming sale_date is DATE type) ... OVER (... ORDER BY sale_date RANGE BETWEEN INTERVAL '6' DAY PRECEDING AND CURRENT ROW)
-
Frame Boundaries: UNBOUNDED PRECEDING, n PRECEDING, CURRENT ROW, n FOLLOWING, UNBOUNDED FOLLOWING。
-
默认 Frame: 有 ORDER BY 时为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW;无 ORDER BY 时为 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
示例:移动平均 (前后各一行)
-- 3行移动平均工资 AVG(salary) OVER (ORDER BY emp_id ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
示例:累计总和 (默认框架)
-- 部门内按入职日期累计工资 (利用默认frame) SUM(salary) OVER (PARTITION BY dept_name ORDER BY hire_date)
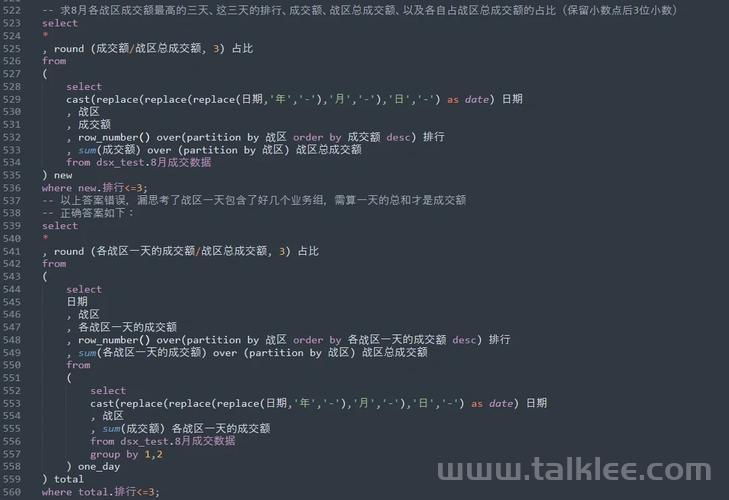
1.常用窗口函数分类及详解: 📚
假设使用 employees 表 (emp_id, emp_name, dept_name, salary, hire_date)
1. 排名函数 (Ranking Functions) - 需要 ORDER BY 🏆
用于确定行在其分区内的排名或位置。
- ROW_NUMBER():
分配连续且唯一的排名序号,不论值是否相同。 1, 2, 3, 4…
示例:为每个部门的员工按工资从高到低分配唯一的行号。
select emp_name, dept_name, salary, row_number() over (partition by dept_name order by salary desc) as rn from employees;
- RANK():
排名函数。如果值相同,则排名相同,但后续排名会跳跃。 1, 1, 3, 4…
示例:为每个部门的员工按工资从高到低排名,相同工资排名相同,排名间可能有间隙。
select emp_name, dept_name, salary, rank() over (partition by dept_name order by salary desc) as rnk from employees;
- DENSE_RANK():
密集排名。如果值相同,则排名相同,后续排名连续不跳跃。 1, 1, 2, 3…
示例:为每个部门的员工按工资从高到低排名,相同工资排名相同,排名间无间隙。
select emp_name, dept_name, salary, dense_rank() over (partition by dept_name order by salary desc) as drnk from employees;
- PERCENT_RANK():
计算行的相对排名(百分比形式),值范围在 0 到 1 之间。公式:(rank() - 1) / (分区总行数 - 1)。 📈 0%-100%
示例:计算每个员工工资在其部门内的百分位排名。
select emp_name, dept_name, salary, percent_rank() over (partition by dept_name order by salary asc) as salary_percent_rank from employees;
- CUME_DIST():
计算累积分布。表示小于或等于当前行值(按 ORDER BY)的行在分区内所占的比例。值范围在 (0, 1] 之间。 📊
示例:计算工资低于或等于当前员工工资的人数占部门总人数的比例。
select emp_name, dept_name, salary, cume_dist() over (partition by dept_name order by salary asc) as salary_cume_dist from employees;
- NTILE(n):
将分区内的行尽可能平均地分配到 n 个桶(组)中,返回行所属的桶编号 (1 到 n)。 🗑️1️⃣, 🗑️2️⃣…
示例:将部门员工按工资分为高、中、低 3 个等级。
select emp_name, dept_name, salary, ntile(3) over (partition by dept_name order by salary desc) as salary_tier from employees;
排名函数对比总结 💡
示例:同时计算三种主要排名。
-- 假设某部门有员工工资为:10000, 8000, 8000, 6000 select emp_name, salary, row_number() over (order by salary desc) as rn, rank() over (order by salary desc) as rnk, dense_rank() over (order by salary desc) as drnk from employees where dept_name = 'Specific_Department';可能的输出对比见上一版本说明。
2. 聚合窗口函数 (Aggregate Window Functions) ➕➖✖️➗
将标准聚合函数应用于窗口框架。
- SUM() OVER (...): 窗口总和。
示例:部门内按入职日期累计工资。
select emp_name, hire_date, salary, sum(salary) over (partition by dept_name order by hire_date) as running_salary from employees;
- AVG() OVER (...): 窗口平均值。
示例:5行移动平均工资。
select emp_name, salary, avg(salary) over (order by emp_id rows between 2 preceding and 2 following) as moving_avg_5 from employees;
- COUNT() OVER (...): 窗口计数。
示例:显示部门总人数。
select emp_name, dept_name, count(*) over (partition by dept_name) as total_in_dept from employees;
- MAX() OVER (...): 窗口最大值。
示例:显示部门最高工资。
select emp_name, dept_name, max(salary) over (partition by dept_name) as max_in_dept from employees;
- MIN() OVER (...): 窗口最小值。
示例:显示部门最低工资。
select emp_name, dept_name, min(salary) over (partition by dept_name) as min_in_dept from employees;
3. 分析与偏移函数 (Analytic & Offset Functions) - 通常需要 ORDER BY ↔️
用于访问分区内其他行的值。
- LAG(expression [, offset [, default]]) OVER (...):
获取前 offset 行的值。 👀⬅️
示例:获取同部门前一个入职员工的工资。
select emp_name, hire_date, salary, lag(salary, 1, 0) over (partition by dept_name order by hire_date) as prev_hire_salary from employees;
- LEAD(expression [, offset [, default]]) OVER (...):
获取后 offset 行的值。 👀➡️
示例:获取同部门下一个入职员工的工资。
select emp_name, hire_date, salary, lead(salary, 1, 0) over (partition by dept_name order by hire_date) as next_hire_salary from employees;
- FIRST_VALUE(expression) OVER (...):
获取窗口框架内第一行的值。 🥇
示例:获取部门内最早入职员工的姓名。
select emp_name, dept_name, hire_date, first_value(emp_name) over (partition by dept_name order by hire_date rows between unbounded preceding and unbounded following) as first_hired_in_dept from employees;
- LAST_VALUE(expression) OVER (...):
获取窗口框架内最后一行的值。 (注意默认框架!) 🏁
示例:获取部门内最近入职员工的姓名。
select emp_name, dept_name, hire_date, last_value(emp_name) over (partition by dept_name order by hire_date rows between unbounded preceding and unbounded following) as last_hired_in_dept from employees;
- NTH_VALUE(expression, n) OVER (...):
获取窗口框架内第 n 行的值(n从1开始)。(MySQL 8.0+) 🥈🥉…
示例:获取部门内入职第二早的员工姓名。
select emp_name, dept_name, hire_date, nth_value(emp_name, 2) over (partition by dept_name order by hire_date rows between unbounded preceding and unbounded following) as second_hired from employees;
4. 使用 CTE (Common Table Expressions) 处理窗口函数结果 🧩
CTE (WITH ... AS (...)) 是处理需要过滤或进一步操作窗口函数结果的标准方法。
语法:
WITH cte_name AS (
– 定义 CTE, 内含窗口函数
SELECT …,
window_function() OVER (…) AS window_result
FROM …
)
– 主查询引用 CTE
SELECT *
FROM cte_name
WHERE window_result … – 在此过滤窗口结果
;
示例:找出每个部门工资排名前 3 的员工。
-- 使用 CTE 对窗口函数排名结果进行过滤 WITH RankedEmployees AS ( SELECT emp_name, dept_name, salary, RANK() OVER (PARTITION BY dept_name ORDER BY salary DESC) as salary_rank FROM employees ) SELECT emp_name, dept_name, salary, salary_rank FROM RankedEmployees WHERE salary_rank
- NTH_VALUE(expression, n) OVER (...):
- LAST_VALUE(expression) OVER (...):
- FIRST_VALUE(expression) OVER (...):
- LEAD(expression [, offset [, default]]) OVER (...):
- LAG(expression [, offset [, default]]) OVER (...):
- MIN() OVER (...): 窗口最小值。
- MAX() OVER (...): 窗口最大值。
- COUNT() OVER (...): 窗口计数。
- AVG() OVER (...): 窗口平均值。
- SUM() OVER (...): 窗口总和。
- NTILE(n):
- CUME_DIST():
- PERCENT_RANK():
- DENSE_RANK():
- RANK():
- ROW_NUMBER():
- RANGE: 基于逻辑值范围,依赖 ORDER BY 列。处理重复值 (peers) 时行为不同。
- ROWS: 基于物理行数偏移。
-
-







