
使用 n8n 实现你的第一个爬虫程序:从零到自动化

在当今数据驱动的时代,网络爬虫(Web Scraping)是获取和分析数据的重要方式之一。传统爬虫需要编写代码(如 Python + Scrapy),但如果你不想折腾代码,又想快速实现爬虫功能,n8n 是一个绝佳的选择!
n8n 是一个 开源、可视化、低代码的自动化工具,可以轻松搭建爬虫工作流,甚至能自动存储、清洗和转换数据。
在这篇教程中,我将带你 从零开始,用 n8n 实现第一个爬虫程序,目标是从一个示例网站(比如 Quotes to Scrape)抓取名言数据,并保存为结构化格式(如 JSON 或 CSV)。
🔧 准备工作
在开始之前,确保你已经安装好 n8n:
-
在线体验:n8n.cloud(免费试用)
-
本地安装(推荐):
npm install n8n -g n8n start
访问 http://localhost:5678 即可进入 n8n 面板。
🚀 第一步:创建你的第一个爬虫工作流
1. 新建 Workflow
-
进入 n8n 面板,点击 Workflows → + New Workflow
-
命名为 First Web Scraper
2. 添加 HTTP Request 节点(获取网页内容)
-
点击 + Add Node,搜索 HTTP Request 并选择
-
配置节点:
-
URL: http://quotes.toscrape.com/
-
Method: GET
-
点击 Execute Node 测试,你应该能看到网页的 HTML 内容
 (图片来源网络,侵删)
(图片来源网络,侵删)
-
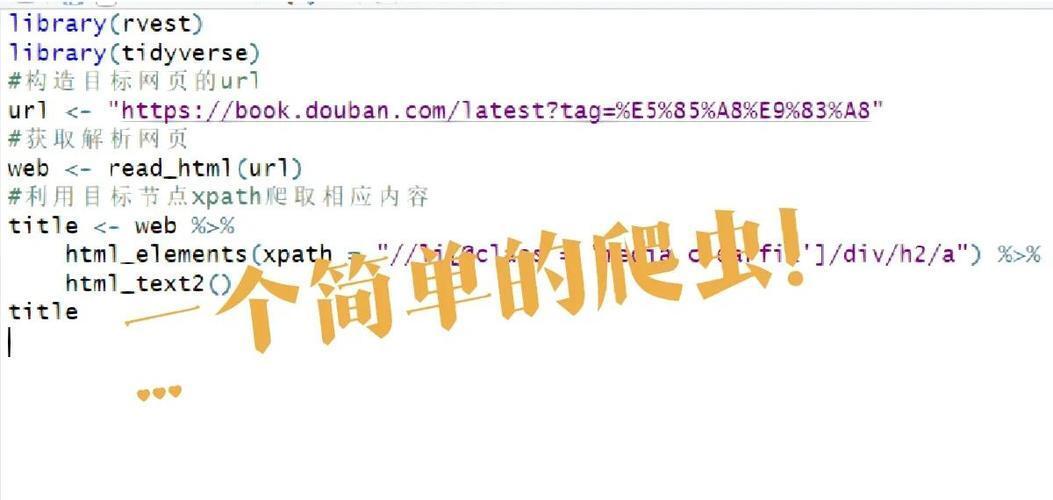
3. 使用 HTML Extract 节点(提取数据)
现在我们需要从 HTML 中提取 名言、作者、标签 等信息。
-
添加 HTML Extract 节点,并连接到 HTTP Request
 (图片来源网络,侵删)
(图片来源网络,侵删) -
配置提取规则(示例):
-
Extraction Values:
-
quote(名言): .quote .text(CSS 选择器)
-
author(作者): .quote .author
-
tags(标签): .quote .tags
-
点击 Execute Node,你应该能看到结构化数据
-
-
4. 存储数据(可选)
你可以将数据保存到 文件、数据库或 Google Sheets,例如:
-
JSON 文件:使用 Write Binary File 节点
-
CSV/Excel:使用 Spreadsheet File 节点
-
数据库:使用 PostgreSQL / MySQL 节点
📌 进阶优化
1. 分页爬取
如果想爬取多页数据,可以使用 Loop 节点(如 Function 或 HTTP Request 循环):
http://quotes.toscrape.com/page/1/ http://quotes.toscrape.com/page/2/ ...
2. 动态网页爬取(如 JavaScript 渲染)
如果目标网站是 SPA(单页应用),可以使用:
-
Puppeteer(Headless Chrome) 节点
-
Playwright 节点
3. 定时自动爬取
使用 Cron 节点,让爬虫每天自动运行:
0 8 * * * # 每天 8:00 运行
💡 最终效果
完成后的工作流大致如下:
HTTP Request → HTML Extract → (可选: 数据清洗) → 存储(JSON/CSV/Database)
你可以在 n8n 的 JSON 导出 里保存这个工作流,方便下次复用!
🎯 总结
-
n8n 是一个强大的低代码爬虫工具,比传统爬虫更简单
-
无需写代码,只需拖拽节点即可完成数据抓取
-
支持动态网页、分页爬取、定时任务等高级功能
-
数据可自动存储到文件、数据库或云端
如果你遇到问题,欢迎在 评论区留言!🚀
👉 下一篇预告:《如何用 n8n 爬取动态渲染网页(Puppeteer 实战)》
(附:完整 n8n 爬虫 JSON 配置,可在评论区获取!)
-
-
-







