
Spring AI开发RAG示例,理解RAG执行原理

在当今信息爆炸的时代,如何高效地管理和利用海量的知识数据成为了企业和开发者面临的重大挑战。基于AI的大模型和检索增强生成(RAG, Retrieval-Augmented Generation)技术为这一难题提供了全新的解决方案。通过结合向量数据库、Embedding技术以及先进的大语言模型,我们可以构建一个强大的本地知识库系统,并实现高效的检索增强生成流程。
本文将详细介绍如何使用Spring AI、Milvus 和 Spring AI Alibaba 开源框架,搭建并验证一个基于AI大模型的本地知识库系统。我们将深入探讨各个关键知识点,包括向量数据库的使用、Embedding生成、大语言模型的选择与应用、文档切片技术、重排序算法的设计,以及如何充分利用Spring AI框架来简化开发过程。通过这一系列步骤,我们将展示如何从零开始构建一个完整的RAG流程,并验证其在实际应用中的效果。
1、前提条件
- JDK为17以上版本,本人使用的jdk21版本;
- SpringBoot版本为3.x以上,本项目使用的是SpringBoot 3.3.3版本;
- 本文采用了阿里巴巴的Qwen大模型进行实验与验证,但您同样可以选择使用DeepSeek大模型作为替代方案。若选用阿里巴巴的AI服务,则需首先在阿里云平台上开通相应的大型模型服务,并获取所需的API密钥,以便在后续代码中调用。具体的开通与配置步骤,请参阅阿里云大模型服务平台“百炼”的相关文档和指南如何获取API Key_大模型服务平台百炼(Model Studio)-阿里云帮助中心。这样可以确保您能够顺利地集成和使用这些先进的AI资源。
- 提前安装部署好Milvus数据库,本文示例使用的Milvus2.5.4版本
2、添加maven依赖
创建springboot工程后,在pom.xml文件里引入第三方Jar包。
com.alibaba.cloud.ai
spring-ai-alibaba-starter
${spring-ai-alibaba.version}
org.springframework.ai
spring-ai-pdf-document-reader
${spring-ai.version}
org.springframework.ai
spring-ai-milvus-store
${spring-ai.version}
本示例使用的是milvus2.5.4最新版本,Java sdk 接口参考文档:About - Milvus java sdk v2.5.x
注意使用sdk版本跟milvus版本的对应关系,milvus2.5.x版本建议使用sdk2.5.2以上版本,否则可能会出现一些诡异问题。
Pom.xml完整内容如下:
4.0.0 com.yuncheng spring-ai-demo 1.0-SNAPSHOT 21 21 UTF-8 1.0.0-M5 1.0.0-M5.1 org.springframework.boot spring-boot-starter-parent 3.3.3 org.springframework.boot spring-boot-starter-web com.alibaba.cloud.ai spring-ai-alibaba-starter ${spring-ai-alibaba.version} org.springframework.ai spring-ai-pdf-document-reader ${spring-ai.version} org.springframework.ai spring-ai-milvus-store ${spring-ai.version} spring-milestones Spring Milestones https://repo.spring.io/milestone false spring-snapshots Spring Snapshots https://repo.spring.io/snapshot false aliyun aliyun Repository http://maven.aliyun.com/nexus/content/groups/public/ false3、配置yml文件
#配置milvus向量数据库的IP、端口以及阿里云AI服务的api-key
server: port: 8080 milvus: host: 192.168.3.17 port: 19530 spring: application: name: spring-ai-helloworld ai: dashscope: api-key: sk-b90ad31bb3eb4a158524928354f37dc5
4、创建VectorStore初始化类
以下源代码定义了一个Spring配置类 VectorStoreConfig,用于配置和初始化与Milvus向量数据库的连接以及基于Spring AI框架的向量存储(Vector Store)。
import io.milvus.client.MilvusServiceClient; import io.milvus.param.ConnectParam; import io.milvus.param.IndexType; import io.milvus.param.MetricType; import org.springframework.ai.embedding.EmbeddingModel; import org.springframework.ai.embedding.TokenCountBatchingStrategy; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.ai.vectorstore.milvus.MilvusVectorStore; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class VectorStoreConfig { @Value("${milvus.host}") private String host; @Value("${milvus.port}") private Integer port; /** * 定义一个名为 milvusServiceClient 的Bean,用于创建并返回一个 MilvusServiceClient 实例。 */ @Bean public MilvusServiceClient milvusServiceClient() { return new MilvusServiceClient( ConnectParam.newBuilder() .withHost(host) .withPort(port) .build()); } /** * 定义一个名为 vectorStore2 的Bean,用于创建并返回一个 VectorStore 实例。 * 使用 MilvusVectorStore.builder 方法构建向量存储对象,并设置以下参数: * collectionName:集合名称为 "vector_store_02"。 * databaseName:数据库名称为 "default"。 * embeddingDimension:嵌入维度为 1536。 * indexType:索引类型为 IVF_FLAT,这是一种常见的近似最近邻搜索索引类型。 * metricType:度量类型为 COSINE,用于计算向量之间的余弦相似度。 * batchingStrategy:使用 TokenCountBatchingStrategy 策略进行批量处理。 * initializeSchema:设置为 true,表示在构建时初始化数据库模式。 */ @Bean(name = "vectorStore2") public VectorStore vectorStore(MilvusServiceClient milvusClient, EmbeddingModel embeddingModel) { return MilvusVectorStore.builder(milvusClient, embeddingModel) .collectionName("vector_store_02") .databaseName("default") .embeddingDimension(1536) .indexType(IndexType.IVF_FLAT) .metricType(MetricType.COSINE) .batchingStrategy(new TokenCountBatchingStrategy()) .initializeSchema(true) .build(); } }以上代码展示了如何在Spring应用中集成Milvus向量数据库,并配置相应的向量存储组件,以支持高效的向量检索和相似度计算。主要完成了以下任务:
- 连接到Milvus向量数据库:通过 MilvusServiceClient 连接到指定的Milvus服务实例。
- 配置向量存储:使用 MilvusVectorStore 类构建并配置一个向量存储实例,包括设置集合名称、数据库名称、嵌入维度、索引类型、度量类型等参数。
- 集成嵌入模型:结合Spring AI的嵌入模型(EmbeddingModel),实现对文本或其他数据的嵌入表示,并将其存储在向量数据库中。
5、创建RAG逻辑处理类
这段源代码定义了一个Spring Boot控制器 DocumentEmbeddingController02,用于处理文档嵌入、向量存储和基于检索增强生成(RAG)的聊天响应。
注意:在本示例中,Spring Boot工程的 `resources/data/` 目录下放置了一个名为 `spring_ai_alibaba_quickstart.pdf` 的PDF文件。该文件将被解析并进行向量化处理,以便后续的检索增强生成(RAG)流程能够基于此文档内容进行检索和验证。通过这一过程,可以评估RAG在本地知识库检索中的准确性和有效性。用户可以根据需要替换为自己的PDF文档,以进行类似的验证和测试。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.ai.document.Document; import org.springframework.ai.document.DocumentReader; import org.springframework.ai.reader.pdf.PagePdfDocumentReader; import org.springframework.ai.transformer.splitter.TokenTextSplitter; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Qualifier; import java.io.IOException; import com.alibaba.cloud.ai.advisor.RetrievalRerankAdvisor; import com.alibaba.cloud.ai.model.RerankModel; import org.springframework.ai.chat.client.ChatClient; import org.springframework.ai.chat.model.ChatModel; import org.springframework.ai.chat.model.ChatResponse; import org.springframework.ai.vectorstore.SearchRequest; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.beans.factory.annotation.Value; import org.springframework.core.io.Resource; import org.springframework.http.MediaType; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import reactor.core.publisher.Flux; import java.nio.charset.StandardCharsets; import java.util.List; @RestController @RequestMapping("/milvus2") public class DocumentEmbeddingController02 { private static final Logger log = LoggerFactory.getLogger(DocumentEmbeddingController02.class); @Value("classpath:/prompts/system-qa.st") private Resource systemResource; @Value("classpath:/data/spring_ai_alibaba_quickstart.pdf") private Resource springAiResource; @Autowired @Qualifier("vectorStore2") private VectorStore vectorStore; @Autowired private ChatModel chatModel; @Autowired private RerankModel rerankModel; /** * 处理PDF文档的解析、分割和嵌入存储。 * 使用 PagePdfDocumentReader 解析PDF文档并生成 Document 列表。 * 使用 TokenTextSplitter 将文档分割成更小的部分。 * 将分割后的文档添加到向量存储中,以便后续检索和生成。 */ @GetMapping("/insertDocuments") public void insertDocuments() throws IOException { // 1. parse document DocumentReader reader = new PagePdfDocumentReader(springAiResource); List documents = reader.get(); log.info("{} documents loaded", documents.size()); // 2. split trunks List splitDocuments = new TokenTextSplitter().apply(documents); log.info("{} documents split", splitDocuments.size()); // 3. create embedding and store to vector store log.info("create embedding and save to vector store"); vectorStore.add(splitDocuments); } /** * 根据用户输入的消息生成JSON格式的聊天响应。 * 创建一个 SearchRequest 对象,设置返回最相关的前2个结果。 * 从 systemResource 中读取提示模板。 * 使用 ChatClient 构建聊天客户端,调用 RetrievalRerankAdvisor 进行检索和重排序,并生成最终的聊天响应内容。 */ @GetMapping(value = "/ragJsonText", produces = MediaType.APPLICATION_STREAM_JSON_VALUE) public String ragJsonText(@RequestParam(value = "message", defaultValue = "如何使用spring ai alibaba?") String message) throws IOException { SearchRequest searchRequest = SearchRequest.builder().topK(2).build(); String promptTemplate = systemResource.getContentAsString(StandardCharsets.UTF_8); return ChatClient.builder(chatModel) .defaultAdvisors(new RetrievalRerankAdvisor(vectorStore, rerankModel, searchRequest, promptTemplate, 0.1)) .build() .prompt() .user(message) .call() .content(); } /** * 根据用户输入的消息生成流式聊天响应。 * 类似于 ragJsonText 方法,但使用 stream() 方法以流的形式返回聊天响应。 * 返回类型为 Flux,适合需要实时更新的场景。 */ @GetMapping(value = "/ragStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux ragStream(@RequestParam(value = "message", defaultValue = "如何使用spring ai alibaba?") String message) throws IOException { SearchRequest searchRequest = SearchRequest.builder().topK(2).build(); String promptTemplate = systemResource.getContentAsString(StandardCharsets.UTF_8); return ChatClient.builder(chatModel) .defaultAdvisors(new RetrievalRerankAdvisor(vectorStore, rerankModel, searchRequest, promptTemplate, 0.1)) .build() .prompt() .user(message) .stream() .chatResponse(); } }这段代码展示了如何在Spring应用中集成文档解析、向量存储和基于AI的聊天响应生成,适用于构建智能问答系统或知识管理系统。
6、创建prompts模板
在springboot工程的resources\prompts目录下,创建一个prompts模板文件system-qa.st,文件内容如下:
上下文信息如下: --------------------- {question_answer_context} --------------------- 根据上下文和提供的历史信息,而不是先验知识,回复用户问题。 如果答案不在上下文中,请通知用户您无法回答该问题。7、测试验证RAG
7.1、在向量库中创建Collection
以上代码编写完成后,启动springboot工程,启动时会在Milvus数据库中自动创建vectorStore2的collection,创建向量表的逻辑是由上述VectorStoreConfig 类控制的。

生成的collection集合中的doc_id、content、metadata、embedding这几个字段是默认生成的,当然用户也可以指定字段名称。
7.2、导入本地PDF文档到向量库
浏览器中输入:http://localhost:8080/milvus2/insertDocuments
执行成功后,也可以通过Milvus自带的webui工具查看。

7.3、RAG检索测试
浏览器中输入:http://localhost:8080/milvus2/ragJsonText
调用本方法时,默认使用检索关键词“如何使用spring ai alibaba?”。我们期望检索增强生成(RAG)系统能够返回与 `spring_ai_alibaba_quickstart.pdf` 文档中的相关内容,并提供最优结果。通过这一过程,可以验证RAG是否依据本地知识库文档进行准确检索和输出。以下是RAG的实际返回结果,其内容与刚刚导入的本地PDF文件高度一致,从而证实了系统的检索准确性和有效性。这表明RAG能够正确地从本地知识库中提取并生成相关响应。

8、RAG执行原理
RAG 通过结合检索技术和生成模型的强大能力,使智能体能够实时从外部数据源获取信息,并在生成过程中增强其知识深度和推理能力。
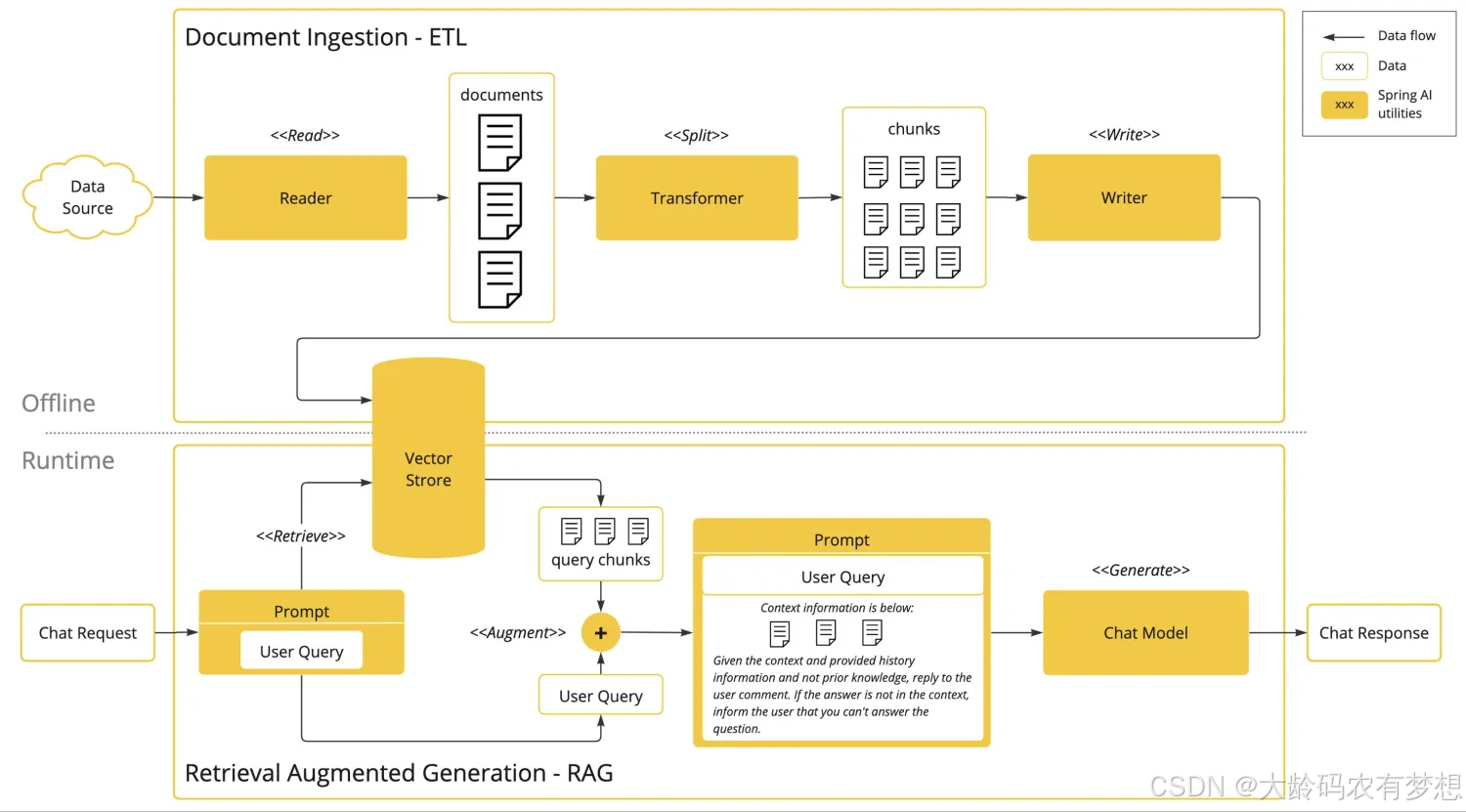
如上图所示,总体上 RAG 是分为离线和运行时两部分。离线部分是将一些领域特有数据进行向量化的过程,将向量化的数据存入向量数据库。图中后半部分体现的运行时流程,Spring AI 框架在组装 prompt 时,会额外检索向量数据库,最终生成一个比用户原始问题具有更多辅助上下文的 prompt,然后将这个具备上下文的 prompt 给到模型,模型根据用户问题、上下文以及自己的推理生成响应。
Spring AI 提供了从离线数据加载、分析到向量化存储的抽象,也提供了运行时检索、prompt 增强的抽象。
9、RAG执行过程源代码解读
以上示例是如何实现RAG的,通过断点调试,找到了com.alibaba.cloud.ai.advisor.RetrievalRerankAdvisor类,其中有两个关键方法before和doRerank,官方代码如下:
protected List doRerank(AdvisedRequest request, List documents) {
if (CollectionUtils.isEmpty(documents)) {
return documents;
}
var rerankRequest = new RerankRequest(request.userText(), documents);
RerankResponse response = rerankModel.call(rerankRequest);
logger.debug("reranked documents: {}", response);
if (response == null || response.getResults() == null) {
return documents;
}
return response.getResults()
.stream()
.filter(doc -> doc != null && doc.getScore() >= minScore)
.sorted(Comparator.comparingDouble(DocumentWithScore::getScore).reversed())
.map(DocumentWithScore::getOutput)
.collect(toList());
}
private AdvisedRequest before(AdvisedRequest request) {
var context = new HashMap(request.adviseContext());
// 1. Advise the system text.
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.query(request.userText())
.filterExpression(doGetFilterExpression(context))
.build();
// 2. Search for similar documents in the vector store.
logger.debug("searchRequestToUse: {}", searchRequestToUse);
List documents = this.vectorStore.similaritySearch(searchRequestToUse);
logger.debug("retrieved documents: {}", documents);
// 3. Rerank documents for query
documents = doRerank(request, documents);
context.put(RETRIEVED_DOCUMENTS, documents);
// 4. Create the context from the documents.
String documentContext = documents.stream()
.map(Document::getText)
.collect(Collectors.joining(System.lineSeparator()));
// 5. Advise the user parameters.
Map advisedUserParams = new HashMap(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
return AdvisedRequest.from(request)
.userText(advisedUserText)
.userParams(advisedUserParams)
.adviseContext(context)
.build();
}
以下我们解读一下这段代码,来理解RAG的执行过程。
这段代码定义了一个名为 `before` 的方法,该方法接收一个 `AdvisedRequest` 对象作为输入,并返回一个新的 `AdvisedRequest` 对象。该方法的主要目的是对用户输入的文本进行预处理、检索相关文档、重排序文档,并生成上下文信息,以便后续处理。以下是详细的步骤和功能说明:
1)方法签名
```java
private AdvisedRequest before(AdvisedRequest request) {
```
- **`before` 方法**:这是一个私有方法,接收一个 `AdvisedRequest` 对象作为参数,并返回一个新的 `AdvisedRequest` 对象。
2)初始化上下文
```java
var context = new HashMap(request.adviseContext());
```
- 创建一个新的 `HashMap` 对象 `context`,并从输入的 `request` 中复制现有的建议上下文(`adviseContext`)。
3)构建建议的用户文本
```java
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
```
- 将输入请求中的用户文本(`userText`)与预先定义的用户文本建议(`userTextAdvise`)拼接在一起,并使用系统换行符(`System.lineSeparator()`)分隔它们,形成新的建议用户文本(`advisedUserText`)。
4)构建搜索请求
```java
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.query(request.userText())
.filterExpression(doGetFilterExpression(context))
.build();
```
- 使用 `SearchRequest.from(this.searchRequest)` 方法从现有的搜索请求模板创建一个新的搜索请求对象。
- 设置查询文本为 `request.userText()`。
- 调用 `doGetFilterExpression(context)` 方法生成过滤表达式,并将其应用到搜索请求中。
- 最终构建并返回新的搜索请求对象 `searchRequestToUse`。
5)执行相似度搜索
```java
logger.debug("searchRequestToUse: {}", searchRequestToUse);
List documents = this.vectorStore.similaritySearch(searchRequestToUse);
logger.debug("retrieved documents: {}", documents);
```
- 记录调试信息,输出构建好的 `searchRequestToUse`。
- 使用向量存储(`vectorStore`)执行相似度搜索,获取与查询文本最相关的文档列表(`documents`)。
- 记录调试信息,输出检索到的文档列表。
6)文档重排序
```java
documents = doRerank(request, documents);
```
- 调用 `doRerank` 方法对检索到的文档进行重排序,以优化其相关性顺序,并更新文档列表 `documents`。
7)更新上下文
```java
context.put(RETRIEVED_DOCUMENTS, documents);
```
- 将重排序后的文档列表添加到上下文 `context` 中,键名为 `RETRIEVED_DOCUMENTS`。
8)生成文档上下文
```java
String documentContext = documents.stream()
.map(Document::getText)
.collect(Collectors.joining(System.lineSeparator()));
```
- 将文档列表中的每个文档的文本内容提取出来,并使用系统换行符连接成一个字符串 `documentContext`。
9)构建建议的用户参数
```java
Map advisedUserParams = new HashMap(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
```
- 创建一个新的 `HashMap` 对象 `advisedUserParams`,并从输入请求中复制现有的用户参数(`userParams`)。
- 将生成的文档上下文(`documentContext`)作为键值对 `"question_answer_context"` 添加到用户参数中。
10)返回新的 `AdvisedRequest` 对象
```java
return AdvisedRequest.from(request)
.userText(advisedUserText)
.userParams(advisedUserParams)
.adviseContext(context)
.build();
```
- 使用 `AdvisedRequest.from(request)` 方法从输入请求创建一个新的 `AdvisedRequest.Builder`。
- 设置新的用户文本(`advisedUserText`)、用户参数(`advisedUserParams`)和建议上下文(`context`)。
- 构建并返回新的 `AdvisedRequest` 对象。
总结
RetrievalRerankAdvisor.before() 方法主要完成以下任务:
1. **初始化上下文**:从输入请求中复制现有的建议上下文。
2. **构建建议的用户文本**:将用户输入的文本与预先定义的建议文本拼接在一起。
3. **构建搜索请求**:根据用户输入的文本和上下文生成搜索请求。
4. **执行相似度搜索**:在向量存储中查找与查询文本最相关的文档。
5. **文档重排序**:对检索到的文档进行重排序,优化其相关性顺序。
6. **更新上下文**:将重排序后的文档列表添加到上下文中。
7. **生成文档上下文**:将文档列表中的文本内容拼接成一个字符串。
8. **构建建议的用户参数**:将生成的文档上下文作为用户参数的一部分。
9. **返回新的请求对象**:构建并返回包含所有更新信息的新 `AdvisedRequest` 对象。
这段代码展示了如何通过一系列步骤对用户输入进行预处理,并生成优化后的请求对象,以便后续的检索增强生成(RAG)流程能够更准确地从本地知识库中检索相关信息。
10、结束语
通过本文的详细讲解和实践示例,我们成功展示了如何使用Spring AI、Milvus 和 Spring AI Alibaba 开源框架,搭建并验证一个基于AI大模型的本地知识库系统,并实现了完整的检索增强生成(RAG)流程。在这个过程中,我们深入探讨了多个关键技术点:
- 向量数据库:通过Milvus的强大向量存储和相似度搜索功能,我们能够高效地管理和检索大规模的Embedding数据。
- Embedding生成:利用预训练的语言模型生成高质量的文本嵌入,为后续的相似度搜索和重排序提供了坚实的基础。
- 大语言模型选型:根据具体需求选择合适的大语言模型,并评估其在不同场景下的表现,确保系统的高效性和准确性。
- 文档切片:通过对长文档进行合理切片,保证每个片段都能被有效处理,提升了整体系统的性能和灵活性。
- 重排序算法:设计并实现高效的重排序算法,进一步优化检索结果的相关性,提升用户体验。
- SpringAI框架使用:借助Spring AI提供的丰富工具和便捷接口,简化了整个开发流程,提高了代码的可维护性和扩展性。







