
Spring AI——从入门到应用(持续更新)

介绍
Spring AI 是 Spring 项目中一个面向 AI 应用的模块,旨在通过集成开源框架、提供标准化的工具和便捷的开发体验,加速 AI 应用程序的构建和部署。
依赖
org.springframework.ai spring-ai-mcp-client-webflux-spring-boot-starter org.springframework.ai spring-ai-mcp-client-spring-boot-starter org.springframework.ai spring-ai-openai-spring-boot-starter org.springframework.boot spring-boot-starter-web
配置文件
在 yml 中配置大模型的 API Key 和模型类型:
spring:
ai:
openai:
base-url: ${AI_BASE_URL}
api-key: ${AI_API_KEY} # 通过环境变量文件 .env 获取
chat:
options:
model: ${AI_MODEL}
temperature: 0.8
在 yml 配置文件的同目录下创建一个 .env 文件,配置以下内容。这里使用的是 DeepSeek 的 API,可以去官网查看:https://platform.deepseek.com/
# AI URL AI_BASE_URL=https://api.deepseek.com # AI 密钥 AI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxx # AI 模型 AI_MODEL=deepseek-chat
配置类
概念
首先,简单介绍一些概念
- ChatClient
ChatClient 提供了与 AI 模型通信的 Fluent API,它支持同步和反应式(Reactive)编程模型。
ChatClient 类似于应用程序开发中的服务层,它为应用程序直接提供 AI 服务,开发者可以使用 ChatClient Fluent API 快速完成一整套 AI 交互流程的组装
- ChatModel
ChatModel 即对话模型,它接收一系列消息(Message)作为输入,与模型 LLM 服务进行交互,并接收返回的聊天消息(ChatMessage)作为输出。目前,它有 3 种类型:
-
ChatModel:文本聊天交互模型,支持纯文本格式作为输入,并将模型的输出以格式化文本形式返回
-
ImageModel:接收用户文本输入,并将模型生成的图片作为输出返回(文生图)
-
AudioModel:接收用户文本输入,并将模型合成的语音作为输出返回
ChatModel 的工作原理是接收 Prompt 或部分对话作为输入,将输入发送给后端大模型,模型根据其训练数据和对自然语言的理解生成对话响应,应用程序可以将响应呈现给用户或用于进一步处理。
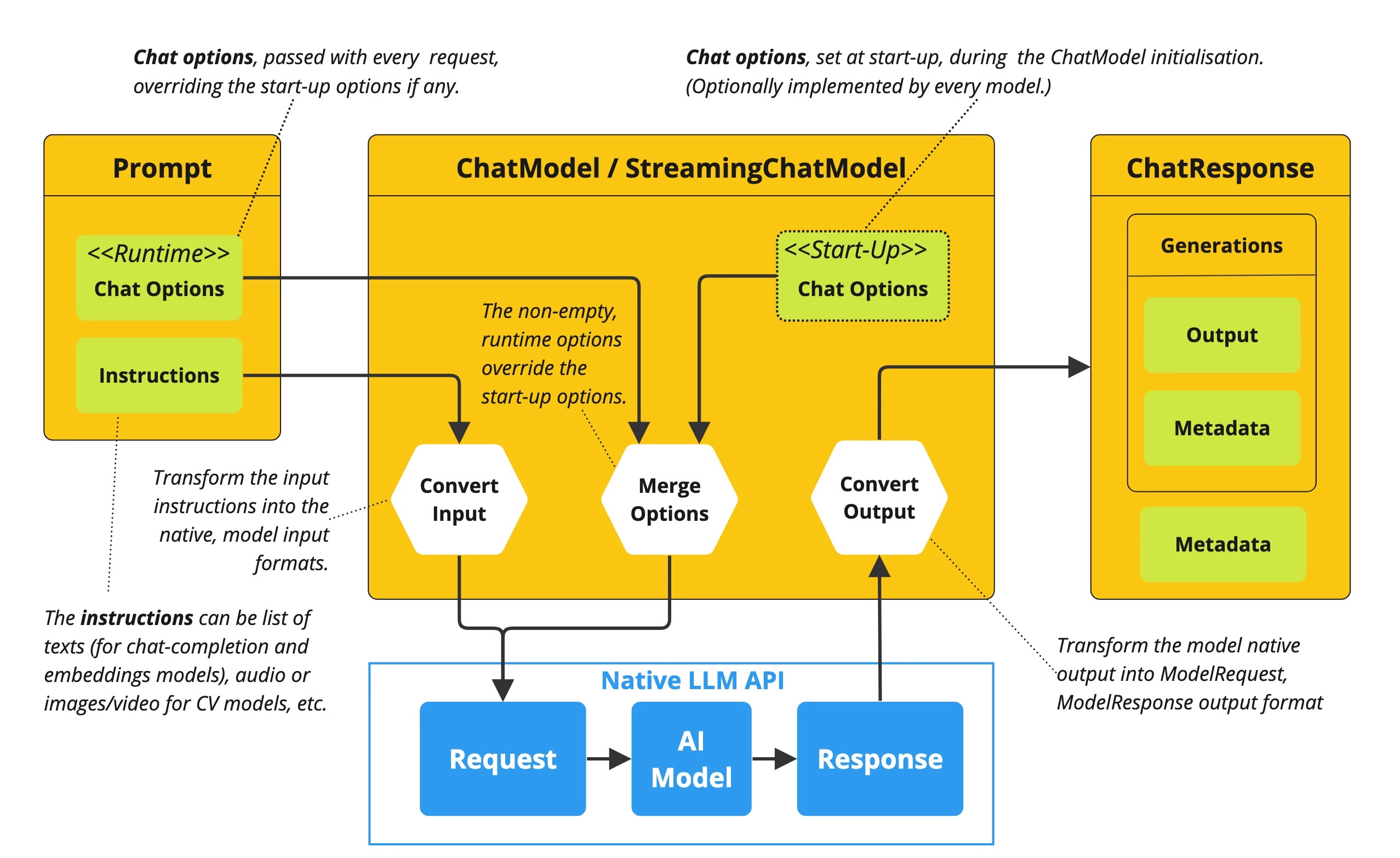
问题
一个项目中可能会存在多个大模型的调用实例,例如 ZhiPuAiChatModel(智谱)、OllamaChatModel(Ollama本地模型)、OpenAiChatModel(OpenAi),这些实例都实现了ChatModel 接口,当然,我们可以直接使用这些模型实例来实现需求,但我们通常通过 ChatModel 来构建 ChatClient,因为这更通用。
可以通过在 yml 配置文件中设置 spring.ai.chat.client.enabled=false 来禁用 ChatClient bean 的自动配置,然后为每个聊天模型 build 出一个 ChatClient。
spring: ai: chat: client: enabled: false配置类
package cn.onism.mcp.config; import jakarta.annotation.Resource; import org.springframework.ai.chat.client.ChatClient; import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor; import org.springframework.ai.chat.memory.InMemoryChatMemory; import org.springframework.ai.ollama.OllamaChatModel; import org.springframework.ai.openai.OpenAiChatModel; import org.springframework.ai.tool.ToolCallbackProvider; import org.springframework.ai.zhipuai.ZhiPuAiChatModel; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * ChatClient 配置 * * @author wxw * @date 2025-03-25 */ @Configuration public class ChatClientConfig { @Resource private OpenAiChatModel openAiChatModel; @Resource private ZhiPuAiChatModel zhiPuAiChatModel; @Resource private OllamaChatModel ollamaChatModel; @Resource private ToolCallbackProvider toolCallbackProvider; @Bean("openAiChatClient") public ChatClient openAiChatClient() { return ChatClient.builder(openAiChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) .defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory())) .build(); } @Bean("zhiPuAiChatClient") public ChatClient zhiPuAiChatClient() { return ChatClient.builder(zhiPuAiChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) .defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory())) .build(); } @Bean("ollamaChatClient") public ChatClient ollamaChatClient() { return ChatClient.builder(ollamaChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) .defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory())) .build(); } }使用 ChatClient 的时候,@Resource 注解会按 Bean 的名称注入
@Resource private ChatClient openAiChatClient; @Resource private ChatClient ollamaChatClient; @Resource private ChatClient zhiPuAiChatClient;
基础对话
普通响应
使用 call 方法来调用大模型
private ChatClient openAiChatModel; @GetMapping("/chat") public String chat(){ Prompt prompt = new Prompt("你好,请介绍下你自己"); String response = openAiChatModel.prompt(prompt) .call() .content(); return response; }流式响应
call 方法修改为 stream,最终返回一个 Flux 对象
@GetMapping(value = "/chat/stream", produces = "text/html;charset=UTF-8") public Flux stream() { Prompt prompt = new Prompt("你好,请介绍下你自己"); String response = openAiChatModel.prompt(prompt) .stream() .content(); return response; }tips:我们可以通过缓存减少重复请求,提高性能。可以使用 Spring Cache 的 @Cacheable 注解实现:
@Cacheable("getChatResponse") public String getChatResponse(String message){ String response = openAiChatModel.prompt() .user(message) .call() .content(); return response; }tips: 适用于批量处理场景。可以使用 Spring 的 @Async 注解实现:
@Async public CompletableFuture getAsyncChatResponse(String message) { return CompletableFuture.supplyAsync(() -> openAiChatModel.prompt() .user(message) .call() .content()); }3 种组织提示词的方式
Prompt
通过 Prompt 来封装提示词实体,适用于简单场景
Prompt prompt = new Prompt("介绍下你自己");PromptTemplate
使用提示词模板 PromptTemplate 来复用提示词,即将提示词的大体框架构建好,用户仅输入关键信息完善提示词
其中,{ } 作为占位符,promptTemplate.render 方法来填充
@GetMapping("/chat/formatPrompt") public String formatPrompt( @RequestParam(value = "money") String money, @RequestParam(value = "number") String number, @RequestParam(value = "brand") String brand ) { PromptTemplate promptTemplate = new PromptTemplate(""" 根据我目前的经济情况{money},只推荐{number}部{brand}品牌的手机。 """); Prompt prompt = new Prompt(promptTemplate.render( Map.of("money",money,"number", number, "brand", brand))); return openAiChatModel.prompt(prompt) .call() .content(); }Message
使用 Message ,提前约定好大模型的功能或角色
消息类型:
系统消息(SystemMessage):设定对话的背景、规则或指令,引导 AI 的行为 用户消息(UserMessage):表示用户的输入,即用户向 AI 提出的问题或请求 助手消息(AssistantMessage):表示 AI 的回复,即模型生成的回答 工具响应消息(ToolResponseMessage):当 AI 调用外部工具(如 API)后,返回 工具的执行结果,供 AI 进一步处理
@GetMapping("/chat/messagePrompt") public String messagePrompt(@RequestParam(value = "book", defaultValue = "《白夜行》") String book) { // 用户输入 UserMessage userMessage = new UserMessage(book); log.info("userMessage: {}", userMessage); // 对系统的指令 SystemMessage systemMessage = new SystemMessage("你是一个专业的评书人,给出你的评价吧!"); log.info("systemMessage: {}", systemMessage); // 组合成完整的提示词,注意,只能是系统指令在前,用户消息在后,否则会报错 Prompt prompt = new Prompt(List.of(systemMessage, userMessage)); return openAiChatModel.prompt(prompt) .call() .content(); }保存 prompt
prompt 不宜嵌入到代码中,可以将作为一个 .txt 文件 其保存到 src/main/resources/prompt 目录下,使用读取文件的工具类就可以读取到 prompt
package cn.onism.mcp.utils; import org.springframework.core.io.ClassPathResource; import org.springframework.stereotype.Component; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.nio.charset.StandardCharsets; /** * @description: 读取文件内容的工具类 * @date: 2025/5/8 */ @Component public class FileContentReader { public String readFileContent(String filePath) { StringBuilder content = new StringBuilder(); try { // 创建 ClassPathResource 对象以获取类路径下的资源 ClassPathResource resource = new ClassPathResource(filePath); // 打开文件输入流 InputStream inputStream = resource.getInputStream(); // 创建 BufferedReader 用于读取文件内容 BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, StandardCharsets.UTF_8)); String line; // 逐行读取文件内容 while ((line = reader.readLine()) != null) { content.append(line).append("\n"); } // 关闭输入流 reader.close(); } catch (IOException e) { // 若读取文件时出现异常,打印异常信息 e.printStackTrace(); } return content.toString(); } }PromptTemplate promptTemplate = new PromptTemplate( fileContentReader.readFileContent("prompt/formatPrompt.txt") );解析模型输出(结构化)
模型输出的格式是不固定的,无法直接解析或映射到 Java 对象,因此,Spring AI 通过在提示词中添加格式化指令要求大模型按特定格式返回内容,在拿到大模型输出数据后通过转换器做结构化输出。
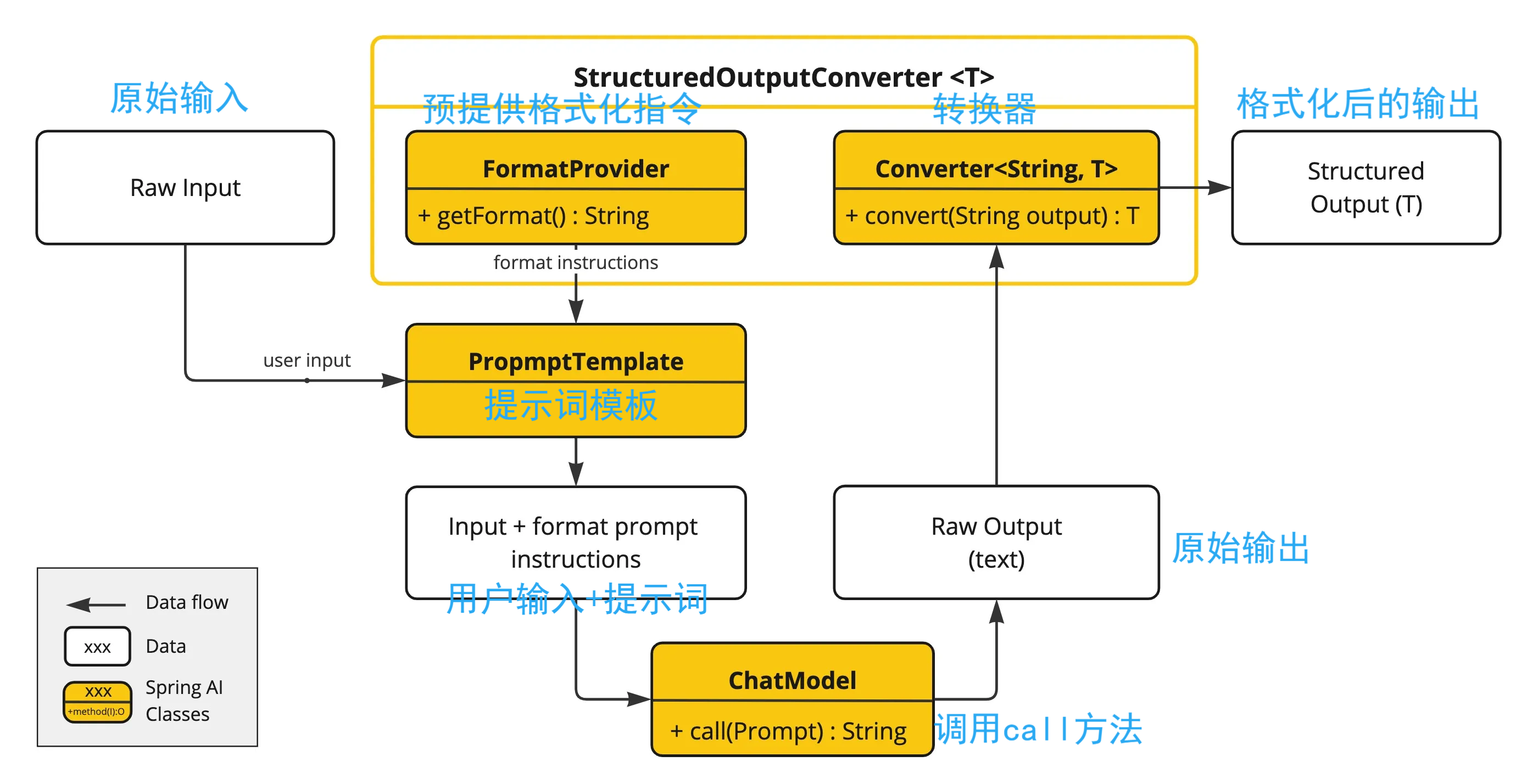
实体类 Json 格式
首先我们定义一个实体类 ActorInfo
@Data @Description("演员信息") public class ActorInfo { @JsonPropertyDescription("演员姓名") private String name; @JsonPropertyDescription("演员年龄") private Integer age; @JsonPropertyDescription("演员性别") private String gender; @JsonPropertyDescription("演员出生日期") private String birthday; @JsonPropertyDescription("演员国籍") private String nationality; }在 call 方法后面调用 entity 方法,把对应实体类的 class 传递进去即能做到结构化输出
@GetMapping("/chat/actor") public ActorInfo queryActorInfo(@RequestParam(value = "actorName") String actorName) { PromptTemplate promptTemplate = new PromptTemplate("查询{actorName}演员的详细信息"); Prompt prompt = new Prompt(promptTemplate.render(Map.of("actorName", actorName))); ActorInfo response = openAiChatModel.prompt(prompt) .call() .entity(ActorInfo.class); return response; }结果符合要求

List 列表格式
在 entity 方法中传入 new ListOutputConverter(new DefaultConversionService())
@GetMapping("/chat/actorMovieList") public List queryActorMovieList(@RequestParam(value = "actorName") String actorName) { PromptTemplate promptTemplate = new PromptTemplate("查询{actorName}主演的电影"); Prompt prompt = new Prompt(promptTemplate.render(Map.of("actorName", actorName))); List response = openAiChatModel.prompt(prompt) .call() .entity(new ListOutputConverter(new DefaultConversionService())); return response; }Map 格式
tips: 目前在 Map 中暂不支持嵌套复杂类型,因此 Map 中不能返回实体类,而只能是 Object。
在 entity 方法中传入 new ParameterizedTypeReference() {}
@GetMapping("/chat/actor") public Map queryActorInfo(@RequestParam(value = "actorName") String actorName) { PromptTemplate promptTemplate = new PromptTemplate("查询{actorName}演员及另外4名相关演员的详细信息"); Prompt prompt = new Prompt(promptTemplate.render(Map.of("actorName", actorName))); Map response = openAiChatModel.prompt(prompt) .call() .entity(new ParameterizedTypeReference() {}); return response; }多模态
deepseek 暂时不支持多模态,因此这里选用 智谱:https://bigmodel.cn/
依赖与配置
org.springframework.ai spring-ai-zhipuai 1.0.0-M6spring: ai: zhipuai: api-key: ${ZHIPUAI_API_KEY} chat: options: model: ${ZHIPUAI_MODEL} temperature: 0.8# api-key ZHIPUAI_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxx.xxxxxxxxxxxxxxx # 所选模型 ZHIPUAI_MODEL=glm-4v-plus-0111
理解图片
在 src/main/resources/images 目录下保存图片
创建一个 ZhiPuAiChatModel,将用户输入和图片封装成一个 UserMessage,然后使用 call 方法传入一个 prompt,最后获得输出
@Resource private ZhiPuAiChatModel zhiPuAiChatModel; @GetMapping("/chat/pic") public String pic() { Resource imageResource = new ClassPathResource("images/mcp.png"); // 构造用户消息 var userMessage = new UserMessage("解释一下你在这幅图中看到了什么?", new Media(MimeTypeUtils.IMAGE_PNG, imageResource)); ChatResponse chatResponse = zhiPuAiChatModel.call(new Prompt(userMessage)); return chatResponse.getResult().getOutput().getText(); }文生图
这里需要使用 zhiPuAiImageModel,我们调用它的 call 方法,传入一个 ImagePrompt,ImagePrompt 由**用户图片描述输入 ImageMessage **和 **图片描述信息 OpenAiImageOptions **所构成,
其中,
- model 要选择适用于图像生成任务的模型,这里我们选择了 cogview-4-250304
- quality 为图像生成图像的质量,默认为 standard
- hd : 生成更精细、细节更丰富的图像,整体一致性更高,耗时约20 秒
- standard :快速生成图像,适合对生成速度有较高要求的场景,耗时约 5-10 秒
@Autowired ZhiPuAiImageModel ziPuAiImageModel; @Autowired private FileUtils fileUtils; @GetMapping("/outputImg") public void outputImg() throws IOException { ImageMessage userMessage = new ImageMessage("一个仙人掌大象"); OpenAiImageOptions chatOptions = OpenAiImageOptions.builder() .model("cogview-4-250304").quality("hd").N(1).height(1024).width(1024).build(); ImagePrompt prompt = new ImagePrompt(userMessage, chatOptions); // 调用 ImageResponse imageResponse = ziPuAiImageModel.call(prompt); // 输出的图片 Image image = imageResponse.getResult().getOutput(); // 保存到本地 InputStream in = new URL(image.getUrl()).openStream(); fileUtils.saveStreamToFile(in, "src/main/resources/images", "pic"+RandomUtils.insecure().randomInt(0, 100)+".png" ); }@Component public class FileUtils { public String saveStreamToFile(InputStream inputStream, String filePath, String fileName) throws IOException { // 创建目录(如果不存在) Path dirPath = Paths.get(filePath); if (!Files.exists(dirPath)) { Files.createDirectories(dirPath); } // 构建完整路径 Path targetPath = dirPath.resolve(fileName); // 使用 try-with-resources 确保流关闭 try (inputStream) { Files.copy(inputStream, targetPath, StandardCopyOption.REPLACE_EXISTING); } return targetPath.toAbsolutePath().toString(); } }调用本地模型
_**tips: **_若想零成本调用大模型,并且保障隐私,可以阅读本章节
下载安装 Ollama
下载安装 Ollama:https://ollama.com/ [Ollama 是一个开源的大型语言模型服务工具,旨在帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以通过一条命令轻松启动和运行开源的大型语言模型。Ollama 是 LLM 领域的 Docker],安装完成后执行 ollama 得到如下输出则表明安装成功
选择一个模型下载到本地:https://ollama.com/search,我这里选择了 qwen3:8b

引入 ollama 依赖
org.springframework.ai spring-ai-ollama-spring-boot-starter
配置
spring: ai: ollama: chat: model: ${OLLAMA_MODEL} base-url: ${OLLAMA_BASE_URL}# 本地模型 OLLAMA_MODEL=qwen3:8b # URL OLLAMA_BASE_URL=http://localhost:11434
实际调用
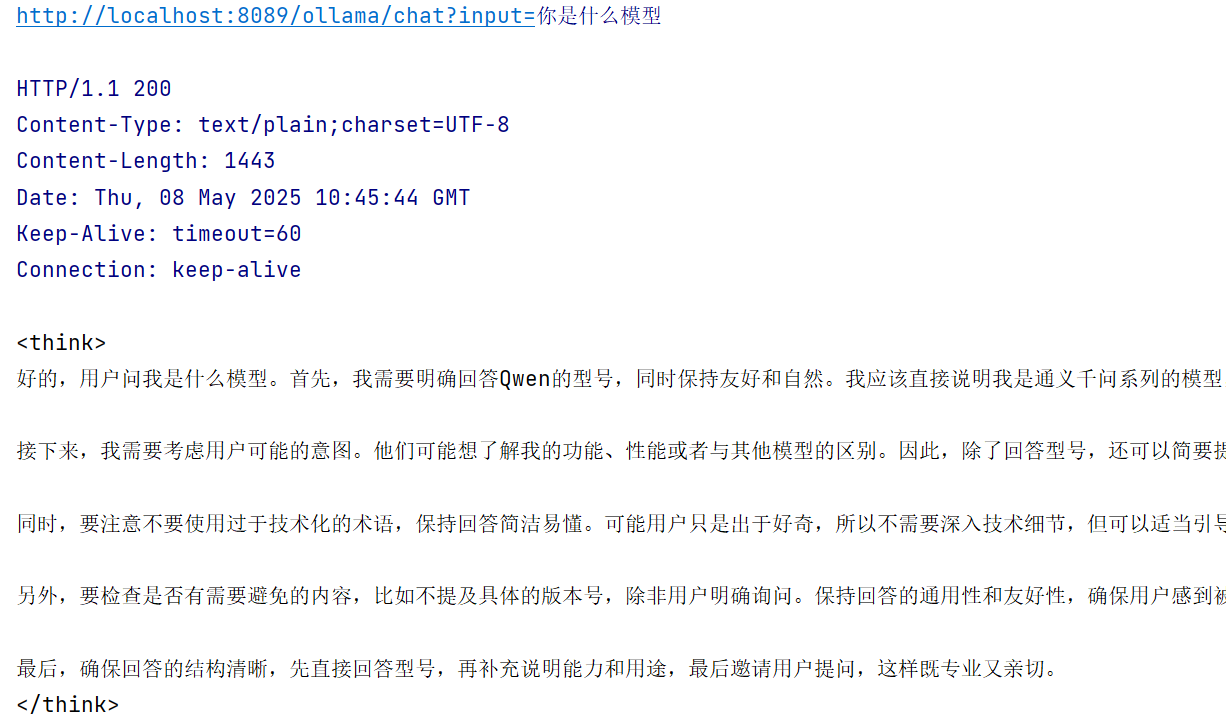
/** * ollama本地模型测试 * @param input * @return */ @GetMapping("/ollama/chat") public String ollamaChat(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); return ollamaChatModel.call(prompt).getResult().getOutput().getText(); }结果
对话记忆
内存记忆(短期)
MessageChatMemoryAdvisor 可以用来提供聊天记忆功能,这需要传递一个基于内存记忆的 ChatMemory
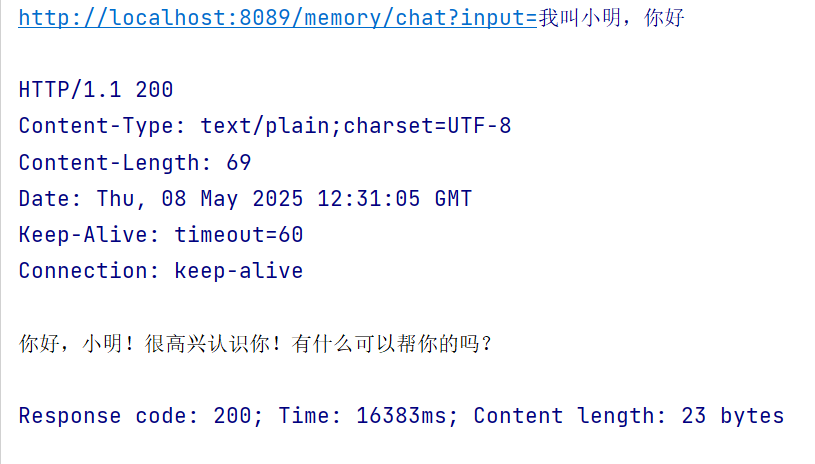
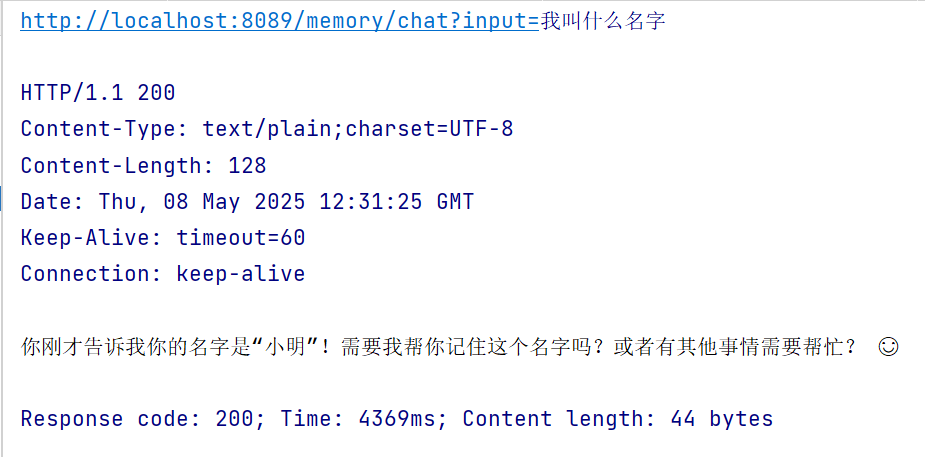
/** * 内存记忆/短期记忆 * @param input * @return */ @GetMapping("/memory/chat") public String chat(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); // 内存记忆的 ChatMemory InMemoryChatMemory inMemoryChatMemory = new InMemoryChatMemory(); return openAiChatClient.prompt(prompt) .advisors(new MessageChatMemoryAdvisor(inMemoryChatMemory)) .call() .content(); }测试
隔离
多用户参与 AI 对话,每个用户的对话记录要做到互不干扰,因此要对不同用户的记忆按一定规则做好隔离。
由于在配置类中已经设置好了默认的 Advisors 为基于内存的聊天记忆 InMemoryChatMemory,因此,我们只需调用 openAiChatClient 的 advisors 方法,并设置好相应的参数即可
其中,
chat_memory_conversation_id 表示 会话 ID,用于区分不同用户的对话历史 chat_memory_response_size 表示每次最多检索 x 条对话历史
@Bean("openAiChatClient") public ChatClient openAiChatClient() { return ChatClient.builder(openAiChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) // 设置记忆 .defaultAdvisors(new MessageChatMemoryAdvisor(new InMemoryChatMemory())) .build(); }/** * 短期记忆,按用户 ID 隔离 * @param input * @param userId * @return */ @GetMapping("/memory/chat/user") public String chatByUser(@RequestParam(value = "input") String input, @RequestParam(value = "userId") String userId) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) // 设置记忆的参数 .advisors(advisor -> advisor.param("chat_memory_conversation_id", userId) .param("chat_memory_response_size", 100)) .call() .content(); }测试
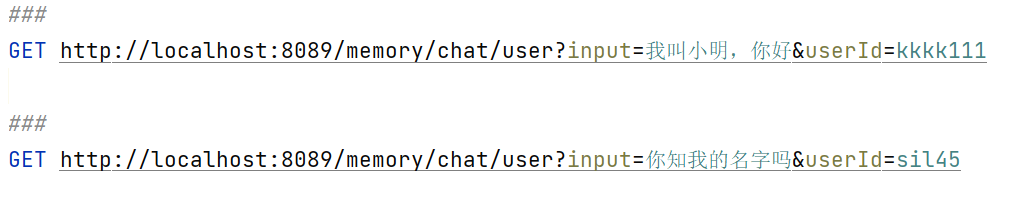
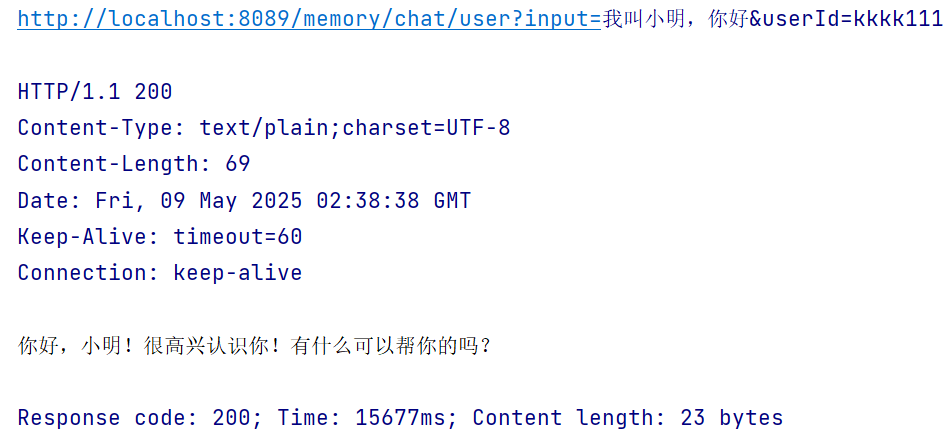
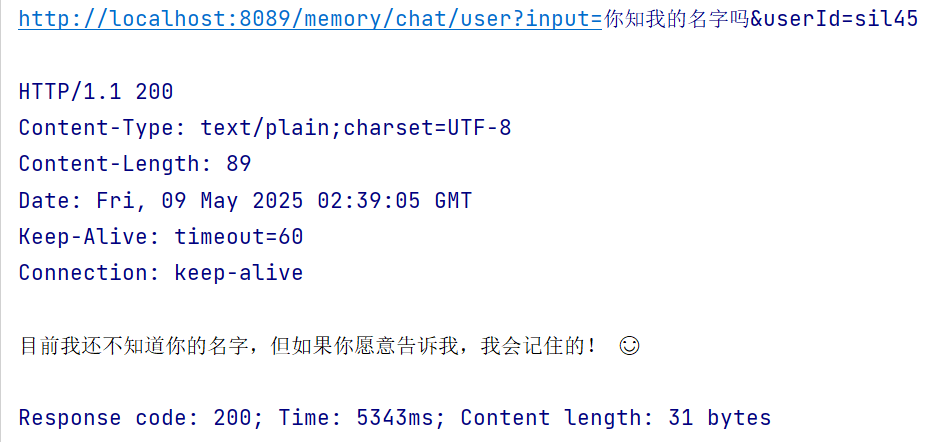
集成 Redis
基于内存的聊天记忆可能无法满足开发者的需求,因此,我们可以构建一个基于 Redis 的长期记忆 RedisChatMemory
引入 Redis 依赖
org.springframework.boot spring-boot-starter-data-redisyml 配置
spring: data: redis: host: localhost port: 6379 password: xxxxxRedis 配置类
创建了一个 RedisTemplate 实例
package cn.onism.mcp.config; import org.springframework.context.annotation.Bean; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.StringRedisSerializer; /** * @description: Redis配置类 * @date: 2025/5/9 */ public class RedisConfig { @Bean public RedisTemplate redisTemplate(RedisConnectionFactory factory) { RedisTemplate redisTemplate = new RedisTemplate(); redisTemplate.setConnectionFactory(factory); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer(Object.class)); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); redisTemplate.setHashValueSerializer(new Jackson2JsonRedisSerializer(Object.class)); redisTemplate.afterPropertiesSet(); return redisTemplate; } }定义消息实体类
用于存储对话的 ID、类型和内容,同时实现了序列化接口以便在 Redis 中存储
/** * @description: 聊天消息实体类 * @date: 2025/5/9 */ @NoArgsConstructor @AllArgsConstructor @Data public class ChatEntity implements Serializable { private static final long serialVersionUID = 1555L; /** * 聊天ID */ private String chatId; /** * 聊天类型 */ private String type; /** * 聊天内容 */ private String content; }构造 RedisChatMemory
创建一个 RedisChatMemory 并实现 ChatMemory 接口,重写该接口的 3 个方法
其中,
add表示添加聊天记录,conversationId 为会话 ID,messages 为消息列表 get表示获取聊天记录,lastN 表示获取最后 lastN 条聊天记录 clear表示清除聊天记录
package cn.onism.mcp.memory; import cn.onism.mcp.model.entity.ChatEntity; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.ai.chat.memory.ChatMemory; import org.springframework.ai.chat.messages.*; import org.springframework.data.redis.core.RedisTemplate; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.concurrent.TimeUnit; /** * @description: 基于Redis的聊天记忆 * @date: 2025/5/9 */ public class ChatRedisMemory implements ChatMemory { /** * 聊天记录的Redis key前缀 */ private static final String KEY_PREFIX = "chat:history:"; private final RedisTemplate redisTemplate; public ChatRedisMemory(RedisTemplate redisTemplate) { this.redisTemplate = redisTemplate; } /** * 添加聊天记录 * @param conversationId * @param messages */ @Override public void add(String conversationId, List messages) { String key = KEY_PREFIX + conversationId; List chatEntityList = new ArrayList(); for (Message message : messages) { // 解析消息内容 String[] strings = message.getText().split(""); String text = strings.length == 2 ? strings[1] : strings[0]; // 构造聊天记录实体 ChatEntity chatEntity = new ChatEntity(); chatEntity.setChatId(conversationId); chatEntity.setType(message.getMessageType().getValue()); chatEntity.setContent(text); chatEntityList.add(chatEntity); } // 保存聊天记录到Redis, 并设置过期时间为60分钟 redisTemplate.opsForList().rightPushAll(key, chatEntityList.toArray()); redisTemplate.expire(key, 60, TimeUnit.MINUTES); } /** * 获取聊天记录 * @param conversationId * @param lastN * @return List */ @Override public List get(String conversationId, int lastN) { String key = KEY_PREFIX + conversationId; Long size = redisTemplate.opsForList().size(key); if (size == null || size == 0) { return Collections.emptyList(); } // 取最后lastN条聊天记录,如果聊天记录数量少于lastN,则取全部 int start = Math.max(0, size.intValue() - lastN); List objectList = redisTemplate.opsForList().range(key, start, -1); List outputList = new ArrayList(); // 解析聊天记录实体,并构造消息对象 ObjectMapper mapper = new ObjectMapper(); for (Object object : objectList){ ChatEntity chatEntity = mapper.convertValue(object, ChatEntity.class); if(MessageType.USER.getValue().equals(chatEntity.getType())){ outputList.add(new UserMessage(chatEntity.getContent())); }else if (MessageType.SYSTEM.getValue().equals(chatEntity.getType())){ outputList.add(new SystemMessage(chatEntity.getContent())); }else if (MessageType.ASSISTANT.getValue().equals(chatEntity.getType())){ outputList.add(new AssistantMessage(chatEntity.getContent())); } } return outputList; } /** * 清除聊天记录 * @param conversationId */ @Override public void clear(String conversationId) { String key = KEY_PREFIX + conversationId; redisTemplate.delete(key); } }更改 ChatClient 配置
将 MessageChatMemoryAdvisor 中的参数替换为我们实现的 ChatRedisMemory
@Resource private RedisTemplate redisTemplate; @Bean("openAiChatClient") public ChatClient openAiChatClient() { return ChatClient.builder(openAiChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) .defaultAdvisors(new MessageChatMemoryAdvisor(new ChatRedisMemory(redisTemplate))) .build(); }测试
/** * RedisChatMemory * @param input * @param userId * @return String */ @GetMapping("/memory/chat/user") public String chatByUser(@RequestParam(value = "input") String input, @RequestParam(value = "userId") String userId) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) .advisors(advisor -> advisor.param("chat_memory_conversation_id", userId) .param("chat_memory_response_size", 100)) .call() .content(); }
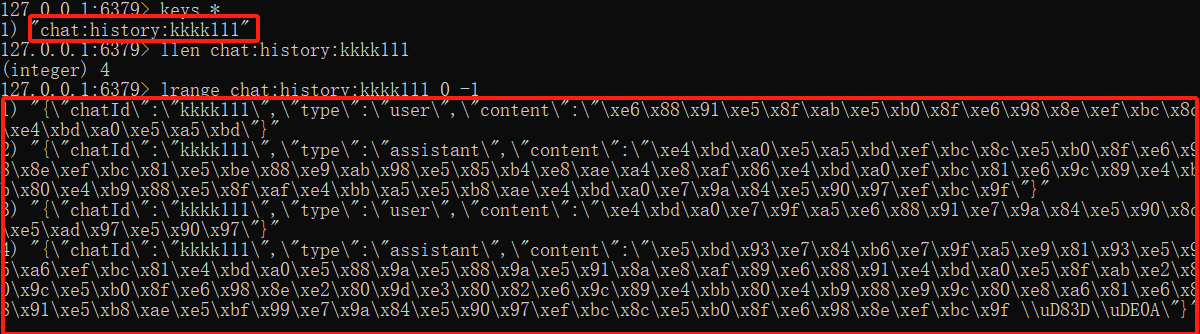
执行结果

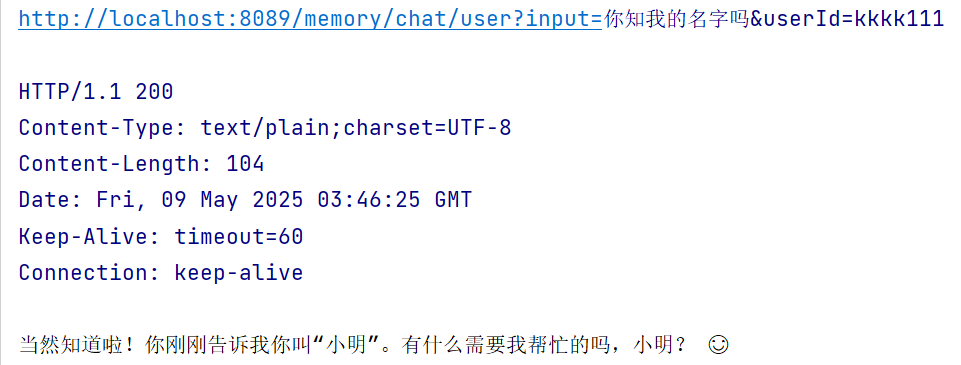
可以看到,Redis 中有对应的记录,我们可以通过 lrange key start end 命令获取列表中的数据,其中 content 为 UTF-8 编码
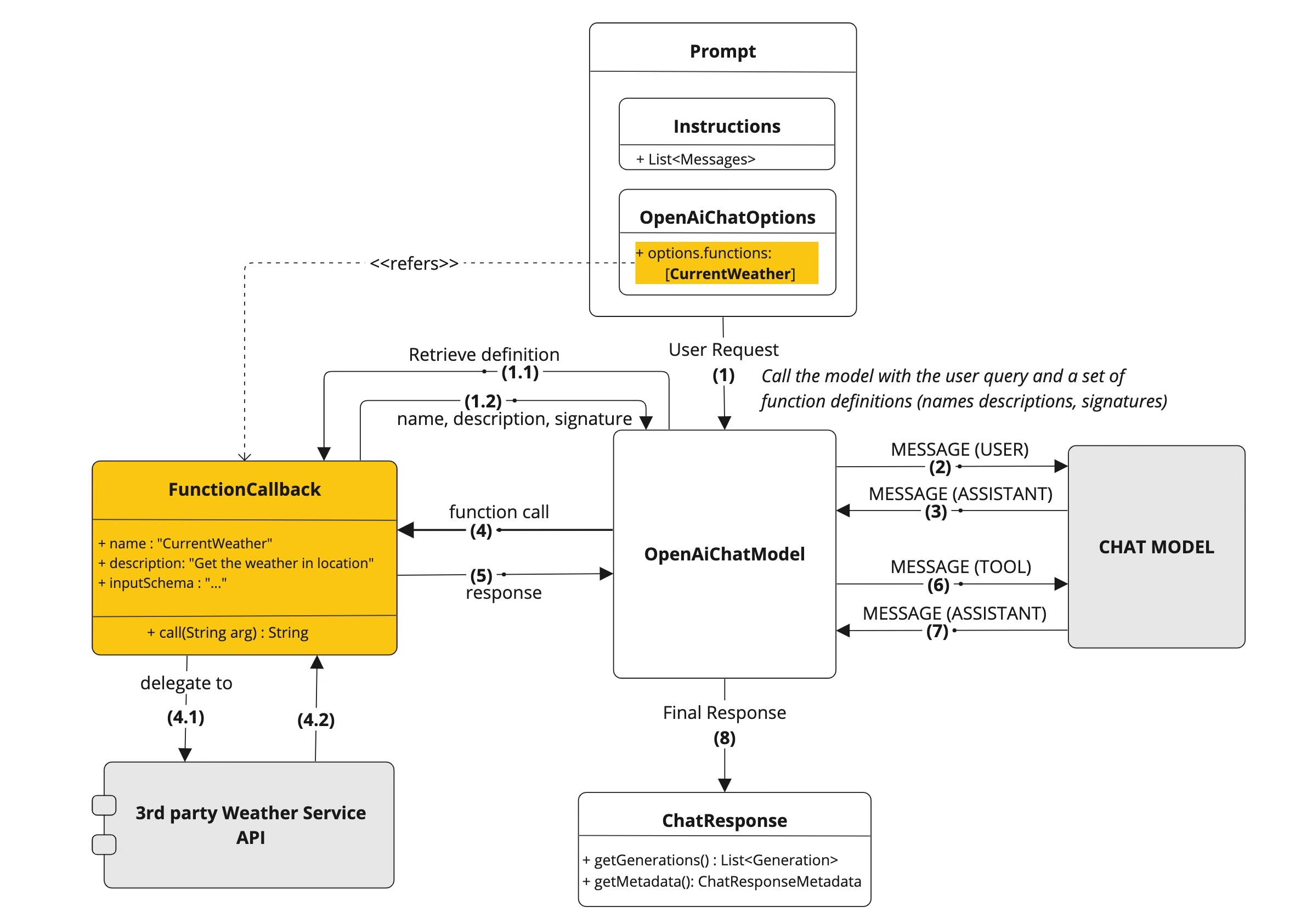
Tool/Function Calling
工具(Tool)或功能调用(Function Calling)允许大型语言模型在必要时调用一个或多个可用的工具,这些工具通常由开发者定义。工具可以是任何东西:网页搜索、对外部 API 的调用,或特定代码的执行等。
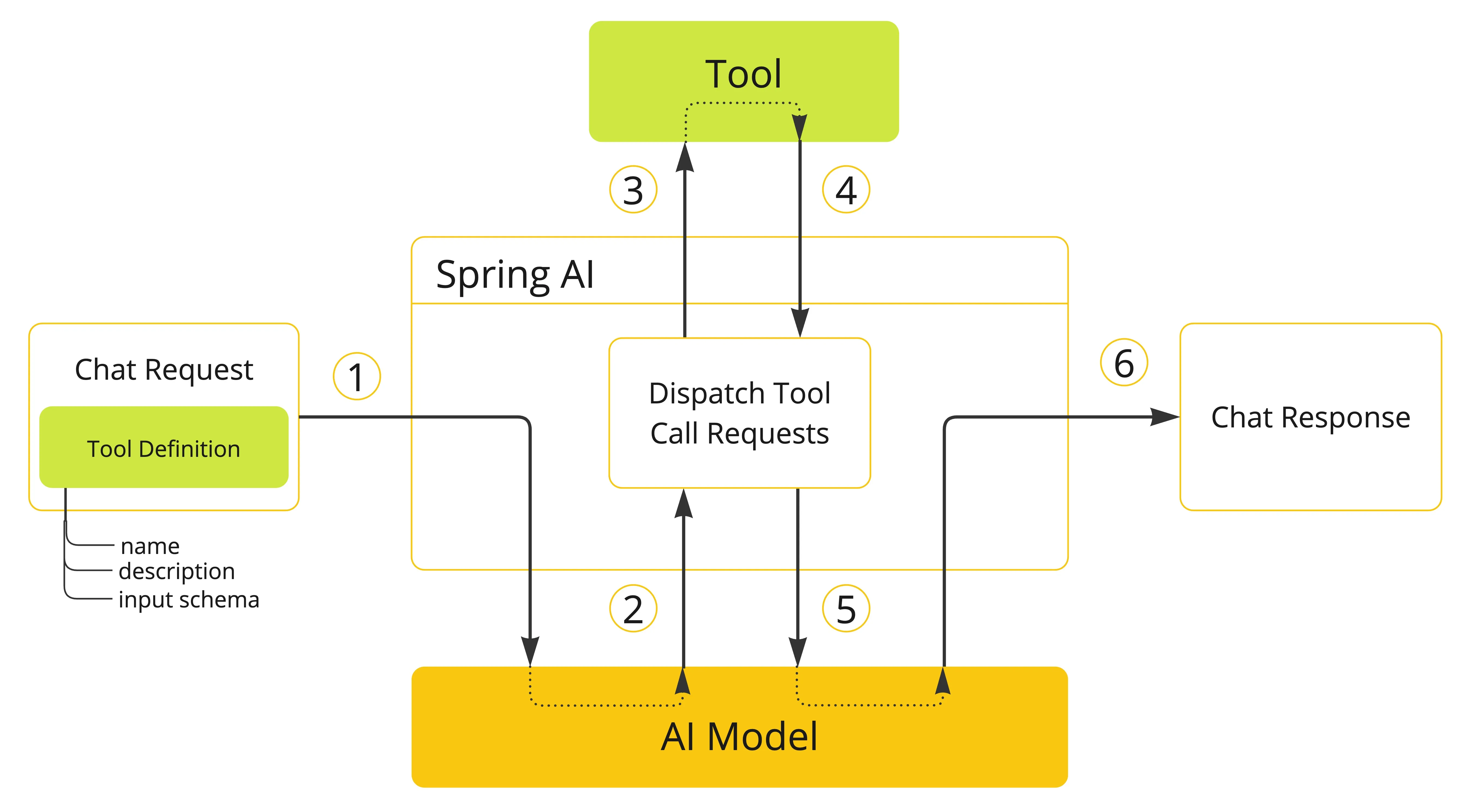
下面是工具调用的流程图:
更加简洁的流程图:
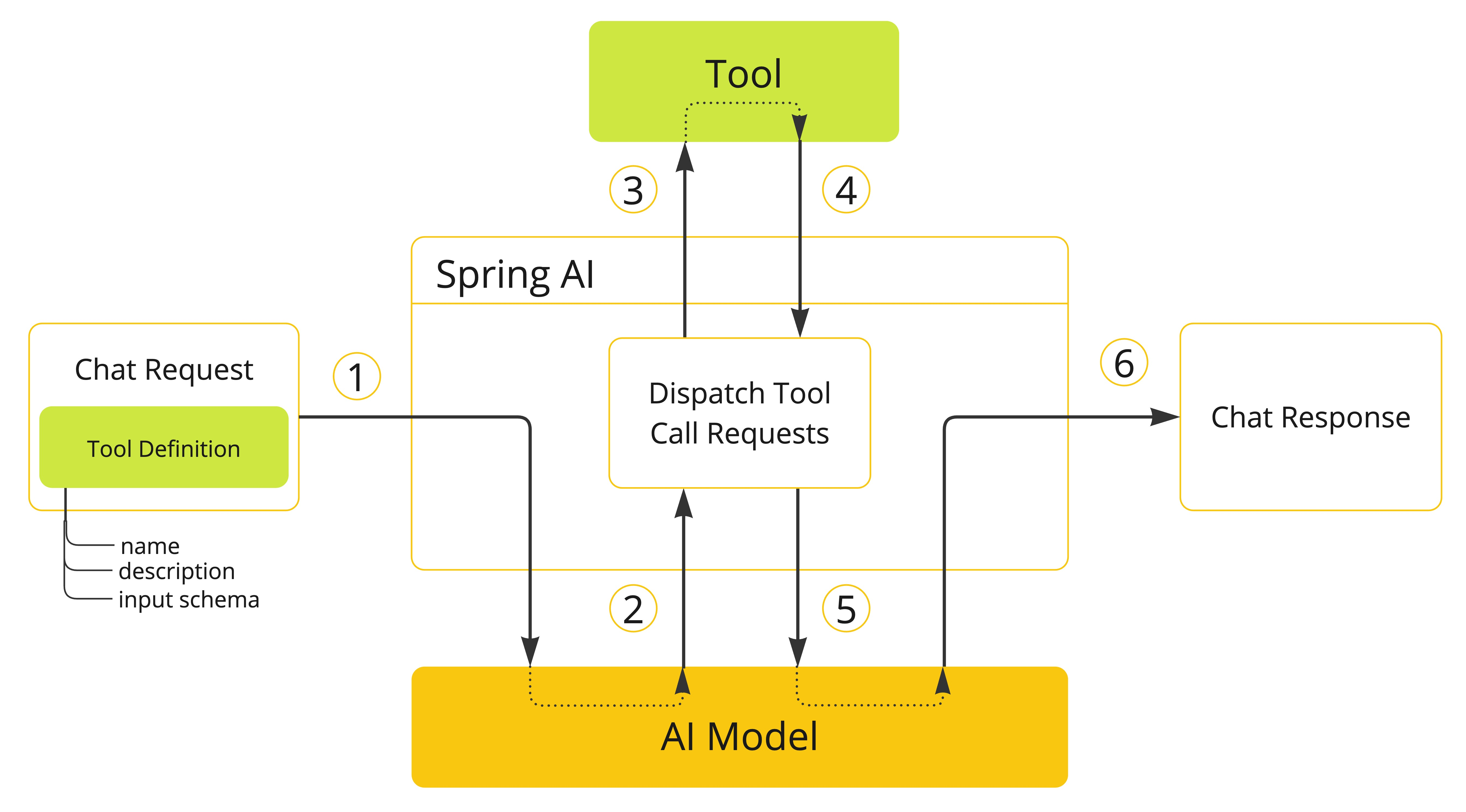
- 工具注册阶段,当需要为模型提供工具支持时,需在聊天请求中声明工具定义。每个工具定义包含三个核心要素:工具名称(唯一标识符)、功能描述(自然语言说明)、输入参数结构(JSON Schema格式)
- 模型决策阶段,模型分析请求后,若决定调用工具,将返回结构化响应,包含:目标工具名称、符合预定义Schema的格式化参数
- 工具执行阶段,客户端应用负责根据工具名称定位具体实现,使用验证后的参数执行目标工具
- 工具响应阶段,工具执行结果返回给应用程序
- 重新组装阶段,应用将标准化处理后的执行结果返回给模型再次处理
- 结果响应阶段,模型结合用户初始输入以及工具执行结果再次加工返回给用户
工具定义与使用
Methods as Tools
- 注解式定义
创建一个 DateTimeTool 工具类,在 getCurrentDateTime 方法上使用 @Tool 注解,表示将该方法标记为一个 Tool,description 表示对工具的描述,大模型会根据这个描述来理解该工具的作用
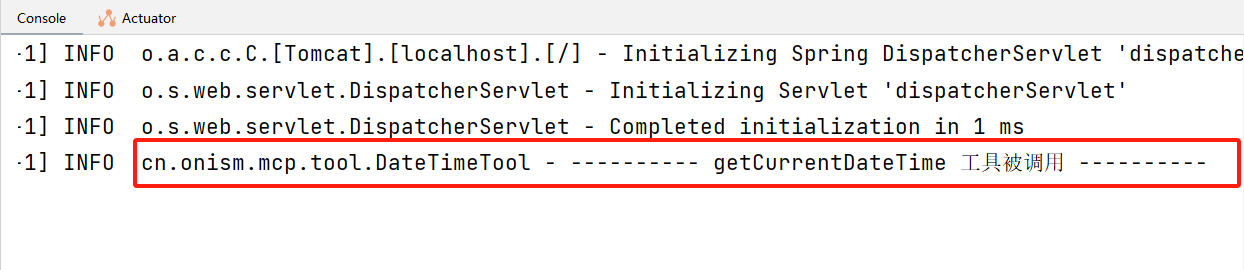
@Component public class DateTimeTool { private static final Logger LOGGER = LoggerFactory.getLogger(DateTimeTool.class); @Tool(description = "获取当前用户的日期和时间") public String getCurrentDateTime() { LOGGER.info("---------- getCurrentDateTime 工具被调用 ----------"); return LocalDateTime.now() .atZone(LocaleContextHolder.getTimeZone().toZoneId()) .toString(); } }在使用时,可以在 ChatClient 配置类中将所有工具都提前加载到 ChatClient 中
@Configuration public class ChatClientConfig { @Resource private OpenAiChatModel openAiChatModel; @Resource private ToolCallbackProvider toolCallbackProvider; @Resource private RedisTemplate redisTemplate; @Bean("openAiChatClient") public ChatClient openAiChatClient() { return ChatClient.builder(openAiChatModel) // 默认加载所有的工具,避免重复 new .defaultTools(toolCallbackProvider.getToolCallbacks()) .defaultAdvisors(new MessageChatMemoryAdvisor(new ChatRedisMemory(redisTemplate))) .build(); } }或者是不在配置类中加载所有工具,而是在调用 ChatClient 时将需要用到的工具传递进去,即使用 tools 方法,传入工具类
@GetMapping("/tool/chat") public String toolChat(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) .tools(new DateTimeTool()) .call() .content(); }测试后发现大模型的确调用了 DateTimeTool
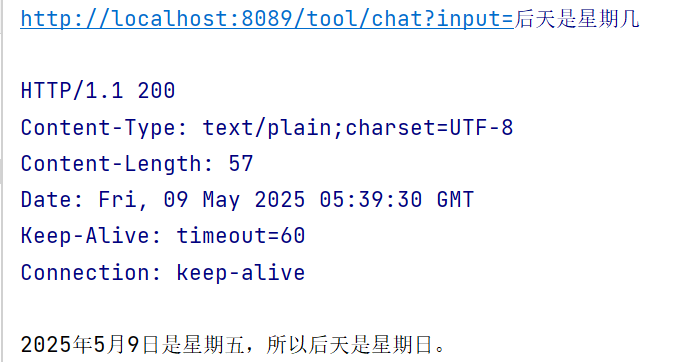
- 编程式定义
我们可以不使用 @Tool 注解,而是采用编程式的方式构造一个 Tool
@Component public class DateTimeTool { private static final Logger LOGGER = LoggerFactory.getLogger(DateTimeTool.class); // no annotation public String getCurrentDateTime() { LOGGER.info("---------- getCurrentDateTime 工具被调用 ----------"); return LocalDateTime.now() .atZone(LocaleContextHolder.getTimeZone().toZoneId()) .toString(); } }首先通过反射获取方法,然后定义一个 ToolDefinition,最后创建一个 MethodToolCallback,将其传入到 tools 方法中即可
@GetMapping("/tool/chat") public String toolChat(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); // 通过反射获取方法 Method method = ReflectionUtils.findMethod(DateTimeTool.class, "getCurrentDateTime"); // 工具定义 ToolDefinition toolDefinition = ToolDefinition.builder(method) .description("获取当前用户的日期和时间") .build(); // 创建一个 MethodToolCallback MethodToolCallback methodToolCallback = MethodToolCallback.builder() .toolDefinition(toolDefinition) .toolMethod(method) .toolObject(new DateTimeTool()) .build(); return openAiChatClient.prompt(prompt) .tools(methodToolCallback) .call() .content(); }Fuctions as Tools
除方法外,Function、Supplier、Consumer 等函数式接口也可以定义为 Tool
下面**模拟一个查询天气的服务,首先定义 WeatherRequest 和 WeatherResponse**
其中,@ToolParam 注解用于定义工具所需参数, description 为工具参数的描述,模型通过描述可以更好的理解参数的作用
/** * 天气查询请求参数 */ @Data public class WeatherRequest { /** * 坐标 */ @ToolParam(description = "经纬度,精确到小数点后4位,格式为:经度,纬度") String location; }@Data @AllArgsConstructor @NoArgsConstructor public class WeatherResponse { /** * 温度 */ private double temp; /** * 单位 */ private Unit unit; }/** * 温度单位 */ public enum Unit { C, F }接下来创建一个 WeatherService,实现 Function 接口,编写具体逻辑。这里获取天气使用的是彩云科技开放平台提供的免费的 API 接口:https://docs.caiyunapp.com/weather-api/,构造好请求后使用 HttpURLConnection 发送请求,读取响应后使用 Jackson 解析 JSON,获取天气数据。
package cn.onism.mcp.tool.service; import cn.onism.mcp.tool.Unit; import cn.onism.mcp.tool.WeatherRequest; import cn.onism.mcp.tool.WeatherResponse; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import lombok.extern.slf4j.Slf4j; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Component; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.net.URLEncoder; import java.nio.charset.StandardCharsets; import java.util.function.Function; /** * @description: 天气服务 * @date: 2025/5/9 */ @Slf4j @Component public class WeatherService implements Function { private static final Logger LOGGER = LoggerFactory.getLogger(WeatherService.class); private static final String TOEKN = "xxxxxxxxxxxxxxxxxx"; /** * 实时天气接口 */ private static final String API_URL = "https://api.caiyunapp.com/v2.6/%s/%s/realtime"; private double temp; private String skycon; @Override public WeatherResponse apply(WeatherRequest weatherRequest) { LOGGER.info("Using caiyun api, getting weather information..."); try { // 构造API请求 String location = weatherRequest.getLocation(); String encodedLocation = URLEncoder.encode(location, StandardCharsets.UTF_8); String apiUrl = String.format( API_URL, TOEKN, encodedLocation ); URL url = new URL(apiUrl); // 发送请求 HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setRequestMethod("GET"); // 读取响应 int responseCode = connection.getResponseCode(); if (responseCode == HttpURLConnection.HTTP_OK) { BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream())); String inputLine; StringBuilder response = new StringBuilder(); while ((inputLine = in.readLine()) != null) { response.append(inputLine); } in.close(); // 使用Jackson解析JSON ObjectMapper objectMapper = new ObjectMapper(); JsonNode rootNode = objectMapper.readTree(response.toString()); // 获取天气数据 JsonNode resultNode = rootNode.get("result"); LOGGER.info("获取到天气信息: " + resultNode.toString()); temp = resultNode.get("realtime").get("temperature").asDouble(); skycon = resultNode.get("realtime").get("skycon").asText(); } else { System.out.println("请求失败,响应码为: " + responseCode); } } catch (IOException e) { e.printStackTrace(); } return new WeatherResponse(temp, skycon, Unit.C); } }创建一个 WeatherTool 工具类,定义一个 Bean,Bean 名称为工具名称,@Description 中描述工具作用,该 Bean 调用了 WeatherService 中的方法
package cn.onism.mcp.tool; import cn.onism.mcp.tool.service.WeatherService; import lombok.extern.slf4j.Slf4j; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.ai.tool.annotation.Tool; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Description; import org.springframework.stereotype.Component; import java.util.function.Function; /** * @description: 天气工具类 * @date: 2025/5/9 */ @Slf4j @Component public class WeatherTool { private final WeatherService weatherService = new WeatherService(); @Bean(name = "currentWeather") @Description("依据位置获取天气信息") public Function currentWeather() { return weatherService::apply; } }将天气工具和日期工具传入 tools 方法中
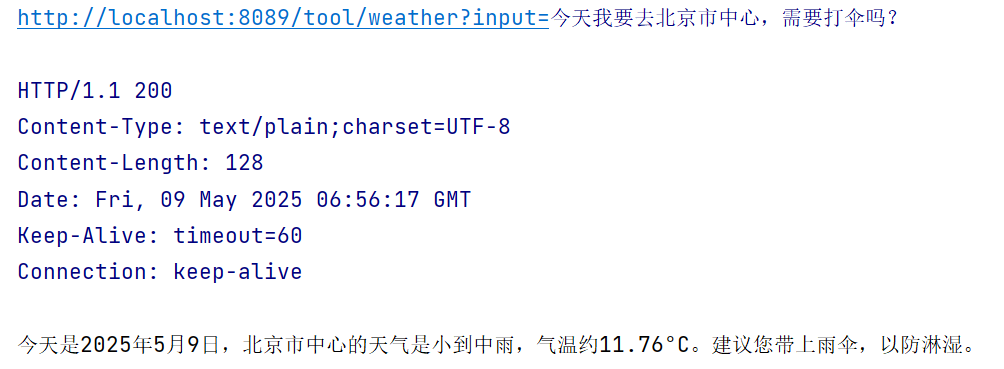
@GetMapping("/tool/weather") public String toolFunctionAnnotation(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) .tools("currentWeather","getCurrentDateTime") .call() .content(); }测试
可以看到,大模型首先会调用日期工具获取时间,同时,我们向大模型询问的地点会被自动解析为 location 经纬度参数,接着调用天气工具获取天气信息
在之前的流程图中,工具的调用会与大模型进行 2 次交互,第一次为发起请求,第二次在工具执行完成后带着工具执行的结果再次调用大模型,而某些情况下,我们想在工具执行完成后直接返回,而不去调用大模型。在 @Tool 注解中令 returnDirect = true 即可
MCP
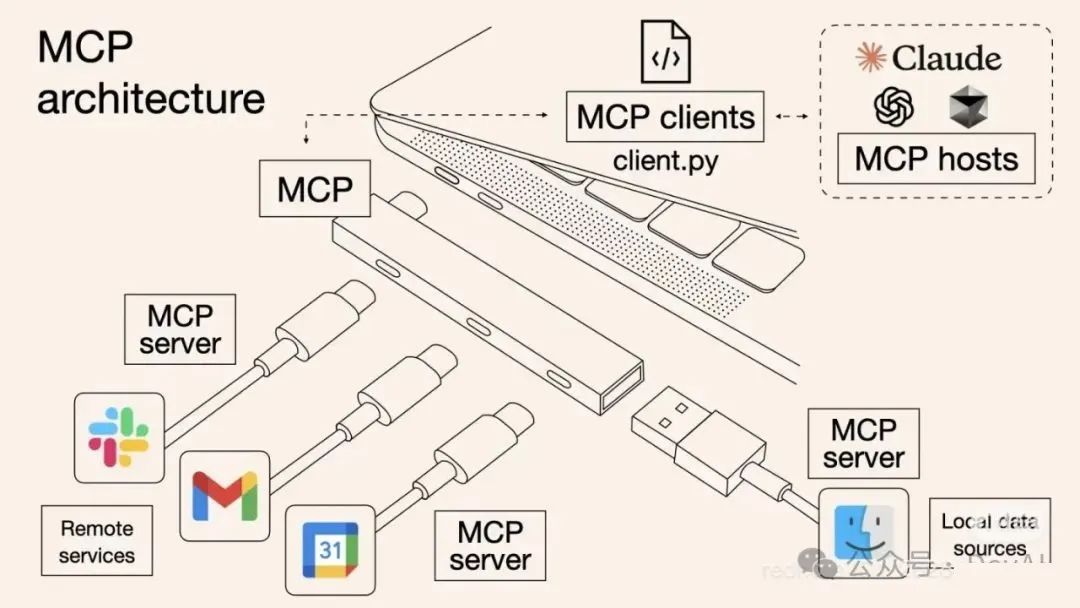
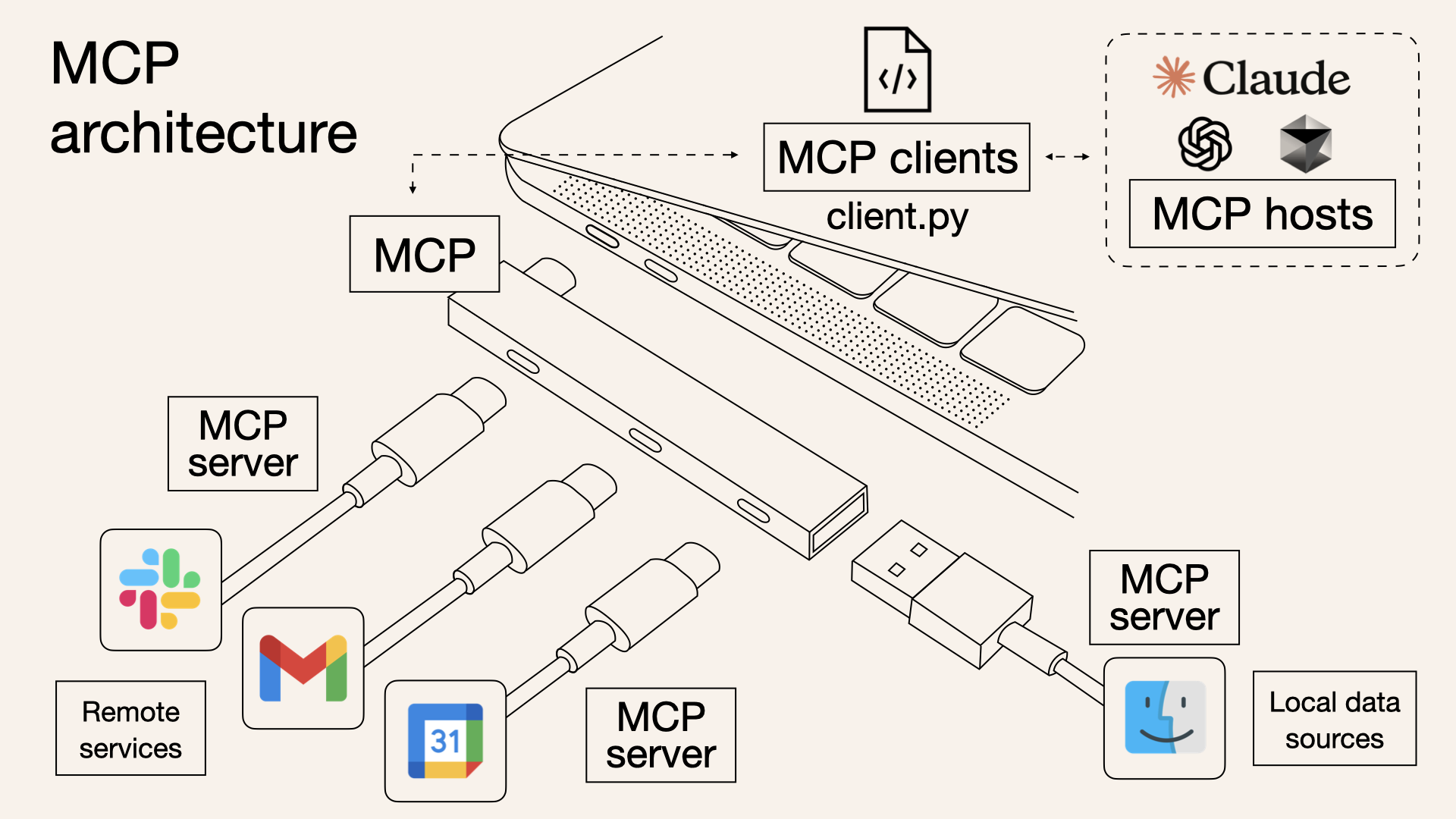
首先来看这张经典的图,MCP(Model Context Protocol 模型上下文协议)可以被视为 AI 应用的 USB-C 端口,它为 AI 模型/应用与不同数据源/工具建立了统一对接规范,旨在标准化应用程序向大语言模型提供上下文的交互方式。
MCP 采用客户端-服务器架构,
其中,
- MCP Hosts(宿主程序):如 Claude Desktop、IDE 等,通过 MCP 访问数据
- MCP Clients(客户端):与服务器建立 1:1 连接,处理通信
- MCP Servers(服务端):轻量级程序,提供标准化的数据或工具访问能力
- Local Data Sources(本地数据源):如文件、数据库等,由 MCP 服务端安全访问
- Remote Services(远程服务):如API、云服务等,MCP 服务端可代理访问
好的,你已经知道了 MCP Servers 就是展示和调用工具的地方,而 MCP Clients 就是用户与各种大模型/AI应用对话的地方
假设,我们的 MCP Servers 提供了 2 个简单的工具,分别是获取日期、获取天气。那么 MCP Servers 启动成功之后,MCP Clients 就可以获取到这两个工具。
我们在 MCP Clients 向 AI 询问 今天是星期几? 接下来, MCP Clients 会首先使用模型的 Function call 能力,由大模型决定是否使用工具,以及使用哪个工具。随后,MCP Clients 把确定要使用的工具和参数发送回 MCP Servers,由 MCP Servers 实现工具调用并返回结果。最后,MCP Clients 根据返回结果,再次调用大模型,由大模型进行回答。
你可能会问,这和工具调用有什么区别?这个流程和 Function/Tool call 不是一样嘛……
确实,MCP 只是一个协议,就像后端开发中的 RESTful API ,基本上就是一组接口约定,通过固定的模式来理解每个工具的作用和参数,实际上并没有新的技术。 而且实际使用过程中,会产生巨量的token 消耗。
并且,在真实的生产环境中,工具数量可能会非常多,一些工具之间的界限可能并没有那么清晰,模型也会出现调用错误的情况。此外,若一个工具需要传入多个参数,那么模型提取参数可能不是那么准确。
但是,作为一个协议,它的出发点是好的。
了解更多,请阅读 MCP 中文文档:https://mcplab.cc/zh/docs/getstarted
MCP Client/Server
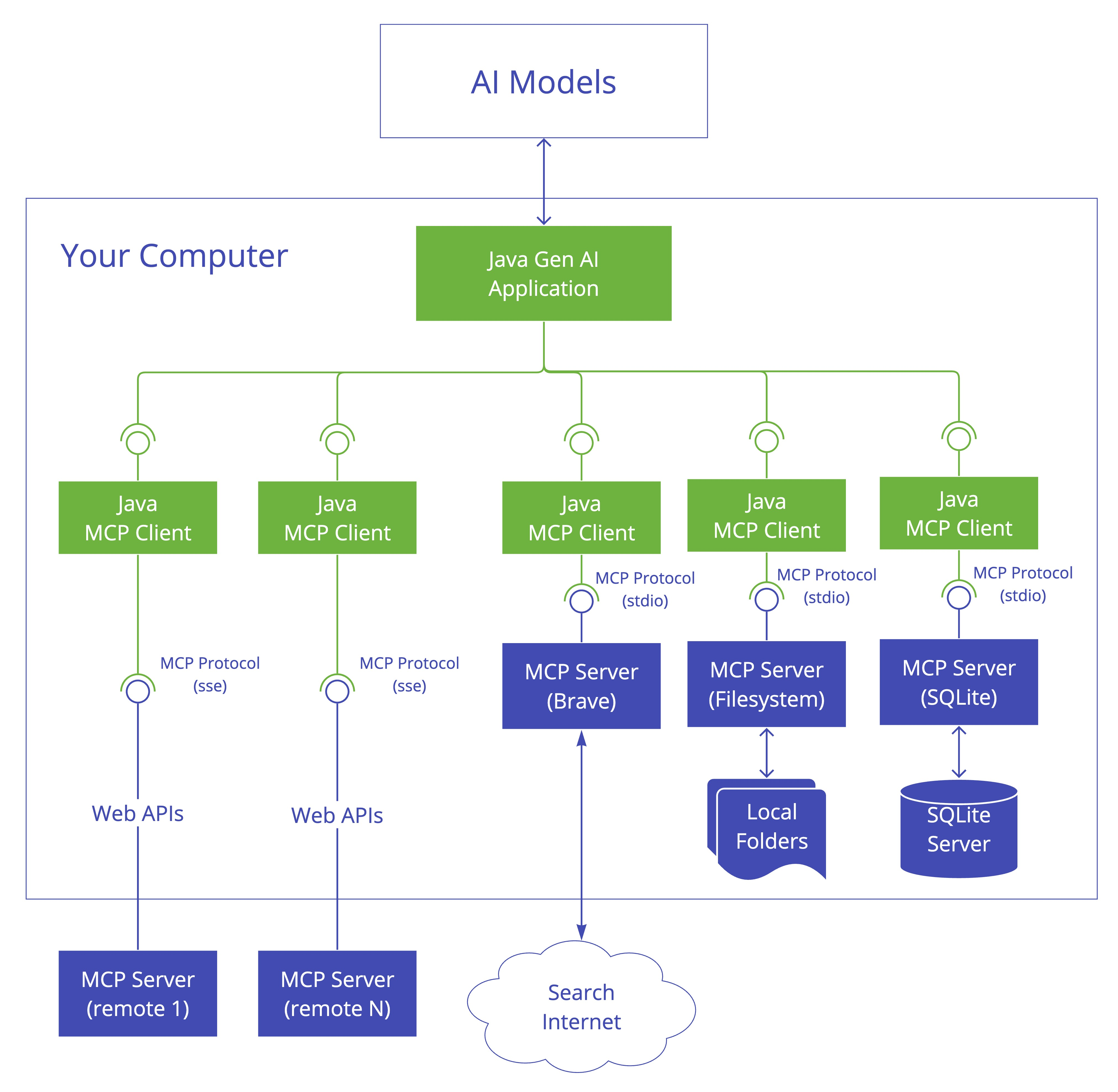
从下面这幅图可以看到,通过 Spring AI,我们可以自己实现一个 MCP Client 和 MCP Server,并通过 MCP 来连接 MCP Server。
MCP 有两种通信模式:stdio、sse。
stdio(标准输入/输出)通过本地进程间通信实现,客户端以子进程形式启动服务器,双方通过stdin/stdout 交换 JSON-RPC 消息,每条消息以换行符分隔。适用场景:本地工具集成、隐私数据处理、快速原型开发。
SSE 又分为 Spring MVC (Server-Sent Events) 和 Spring WebFlux (Reactive SSE) 。
1. Spring MVC 的 SSE 适合传统的基于 Servlet 的 Web 应用程序,能够与现有的 Spring MVC 项目无缝集成,支持**同步模式**,适合传统的请求-响应模式。 2. Spring WebFlux 的 SSE 适合需要高性能、非阻塞 I/O 的现代响应式应用,特别是在处理大量并发连接时表现出色,支持异步模式,适合需要高并发和低延迟的应用。
MCP Server 开发
基于 stdio 形式是将 MCP Server 当做一个本地的子进程,基于 sse 可将 MCP Server 部署在远端,各有千秋
stdio
引入 **mcp-server **依赖
org.springframework.ai spring-ai-starter-mcp-server 1.0.0-M7定义一个工具,这里模拟获取某地区新闻头条
/** * @description: * @date: 2025/5/10 */ @Service public class NewsService { @Tool(description = "获取某地区新闻头条") public String getNewsTop(String location) { return "今日" + location + "地区的新闻头条是: " + location + "申奥成功"; } }在配置类中将工具加载到 ToolCallbackProvider 中
/** * @description: * @date: 2025/5/10 */ @Configuration public class ToolConfiguration { @Bean public ToolCallbackProvider weatherTools(NewsService newsService) { return MethodToolCallbackProvider .builder() .toolObjects(newsService) .build(); } }接下来在 yml 文件中配置如下内容,含义见注释:
spring: main: # 禁用 web 应用类型 web-application-type: none # 禁用 banner banner-mode: off ai: mcp: server: # mcp 服务名称 name: mcp-stdio-news # mcp 服务版本 version: 1.0.0 # mcp 通信模式为 stdio stdio: true application: name: mcp-stdio-demo # 日志 logging: file: name: mcp-stdio-demo.log接下来打包,在 target 目录中获取 jar 包路径
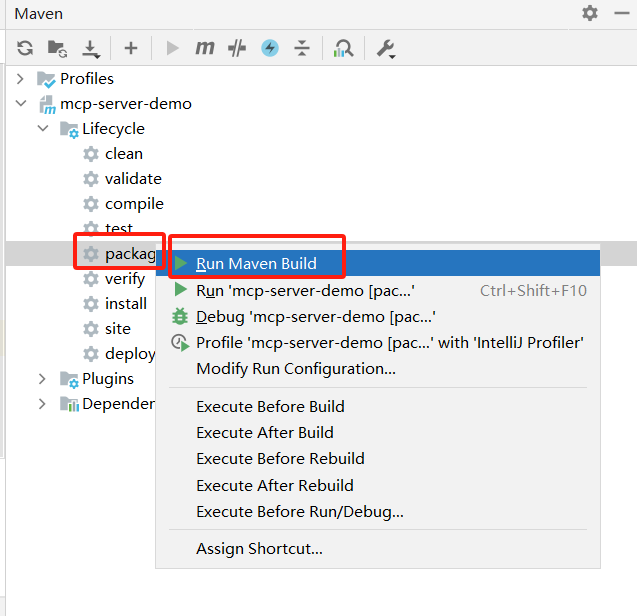
编写 mcp-servers-config.json 文件,该文件可以在任何 MCP Client 平台中导入
其中:
“mcpServers” 中可以有多个 MCP Server 配置,这里只写了一个
“mcp-stdio-news” 表示 MCP Server 的名称,随便取
“command” 表示命令
“args” 表示命令中的参数
“E:/Java-Projects/mcp-server-demo/target/mcp-server-demo-0.0.1-SNAPSHOT.jar” 表示 jar 包的路径
{ "mcpServers": { "mcp-stdio-news": { "command": "java", "args": [ "-Dspring.ai.mcp.server.stdio=true", "-Dspring.main.web-application-type=none", "-Dlogging.pattern.console=", "-jar", "E:/Java-Projects/mcp-server-demo/target/mcp-server-demo-0.0.1-SNAPSHOT.jar" ] } } }为了测试,我们使用 Spring AI 来实现一个 MCP Client,具体见 MCP Client 开发的 stdio 章节
sse
相较于 stdio 方式,sse 更适用于远程部署的 MCP 服务器,客户端可以通过标准 HTTP 协议与服务器建立连接,实现单向的实时数据推送。
引入依赖
org.springframework.boot spring-boot-starter-web org.springframework.ai spring-ai-starter-mcp-server-webmvc 1.0.0-M7
接下来在 yml 文件中配置如下内容
spring: ai: mcp: server: name: mcp-sse-server version: 1.0.0 application: name: mcp-server server: port: 8090增加配置类
@Configuration public class McpConfig implements WebMvcConfigurer { @Bean public WebMvcSseServerTransportProvider transportProvider(ObjectMapper mapper) { return new WebMvcSseServerTransportProvider(mapper, "/mcp"); // 基础路径设为/mcp } @Bean public RouterFunction mcpRouterFunction( WebMvcSseServerTransportProvider transportProvider) { return transportProvider.getRouterFunction(); } }下面的步骤和 stdio 一样
定义一个工具,这里模拟获取某地区新闻头条
/** * @description: * @date: 2025/5/10 */ @Service public class NewsService { @Tool(description = "获取某地区新闻头条") public String getNewsTop(String location) { return "今日" + location + "地区的新闻头条是: " + location + "申奥成功"; } }在配置类中将工具加载到 ToolCallbackProvider 中
/** * @description: * @date: 2025/5/10 */ @Configuration public class ToolConfiguration { @Bean public ToolCallbackProvider weatherTools(NewsService newsService) { return MethodToolCallbackProvider .builder() .toolObjects(newsService) .build(); } }最后直接运行,不用打包和编写 json 文件,为了测试,我们使用 Spring AI 来实现一个 MCP Client,具体见 MCP Client 开发的 sse 章节
MCP Client 开发
stdio
引入以下依赖
org.springframework.ai spring-ai-starter-mcp-client 1.0.0-M7 org.springframework.ai spring-ai-openai-spring-boot-starter 1.0.0-M6 org.springframework.boot spring-boot-starter-web
编写 yml 配置文件,这里还是使用 deepseek 的 API,其中的 servers-configuration 为 MCP Server 提供的 json 文件,我们将其放在 resources 目录下即可,toolcallback 设置为 true 表示启用工具回调功能
spring: ai: openai: base-url: xxxxxxxxxxxx api-key: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx chat: options: model: deepseek-chat temperature: 0.8 mcp: client: stdio: servers-configuration: classpath:/mcp-servers-config.json toolcallback: enabled: true request-timeout: 60000 server: port: 8085编写配置类
/** * @description: * @date: 2025/5/10 */ @Configuration public class ChatClientConfig { @Resource private OpenAiChatModel openAiChatModel; @Bean("openAiChatClient") public ChatClient openAiChatClient(ToolCallbackProvider toolCallbackProvider) { return ChatClient.builder(openAiChatModel) .defaultTools(toolCallbackProvider) .build(); } }进行测试,可以看到,Client 端的确调用到了 Server 端的工具
/** * @description: * @date: 2025/5/10 */ @RestController public class MCPController { @Resource private ChatClient openAiChatClient; @GetMapping(value = "/chat") public String generate(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) .call() .content(); } }
sse
引入依赖
org.springframework.ai spring-ai-mcp-client-webflux-spring-boot-starter 1.0.0-M6 org.springframework.ai spring-ai-openai-spring-boot-starter 1.0.0-M6
在 yml 文件中配置 MCP 服务器,其中,sse.connections.server1.url 填写 MCP 服务器的地址;news-server 为自定义的服务名
spring: ai: openai: base-url: https://api.deepseek.com api-key: sk-0e48a66aef34434489ce9710ba45f8e2 chat: options: model: deepseek-chat temperature: 0.8 mcp: client: toolcallback: enabled: true name: mcp-sse-client version: 1.0.0 request-timeout: 20s type: ASYNC sse: connections: news-server: url: http://localhost:8090 server: port: 8087编写配置类
/** * @description: * @date: 2025/5/10 */ @Configuration public class ChatClientConfig { @Resource private OpenAiChatModel openAiChatModel; @Bean("openAiChatClient") public ChatClient openAiChatClient(ToolCallbackProvider toolCallbackProvider) { return ChatClient.builder(openAiChatModel) .defaultTools(toolCallbackProvider) .build(); } }进行测试,可以看到,Client 端的确调用到了 Server 端的工具
/** * @description: * @date: 2025/5/10 */ @RestController public class MCPController { @Resource private ChatClient openAiChatClient; @GetMapping(value = "/chat/sse") public String generate(@RequestParam(value = "input") String input) { Prompt prompt = new Prompt(input); return openAiChatClient.prompt(prompt) .call() .content(); } }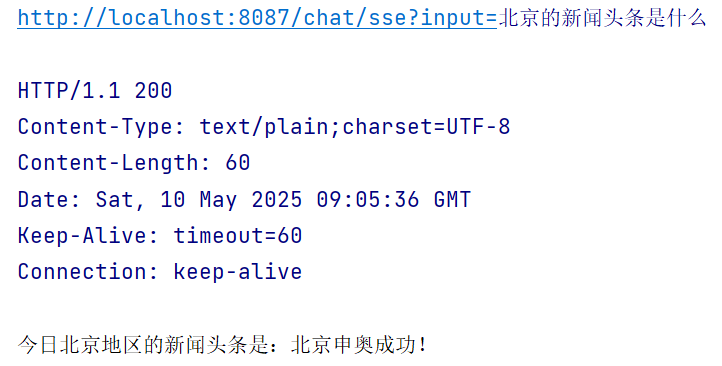
MCP 操作文件系统
MCP 操作数据库
Dify 结合 MCP
进入 Dify 工作室:https://cloud.dify.ai/apps,创建一个 Chatflow
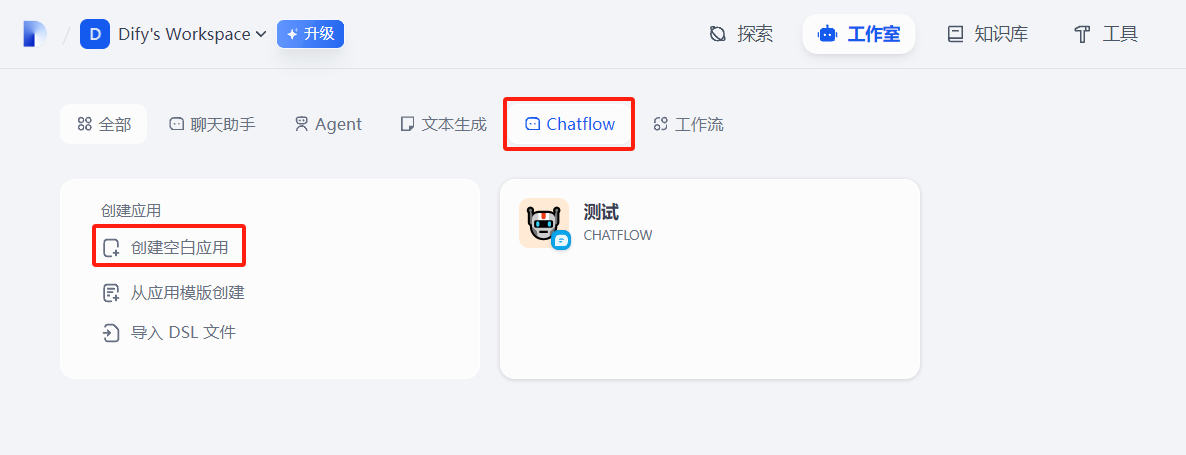
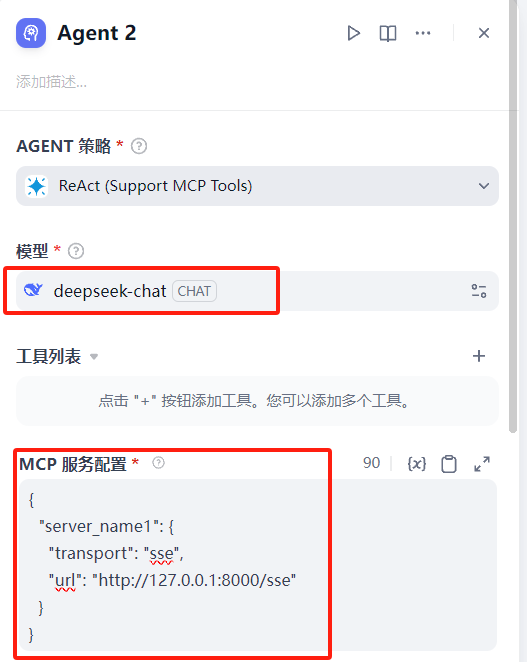
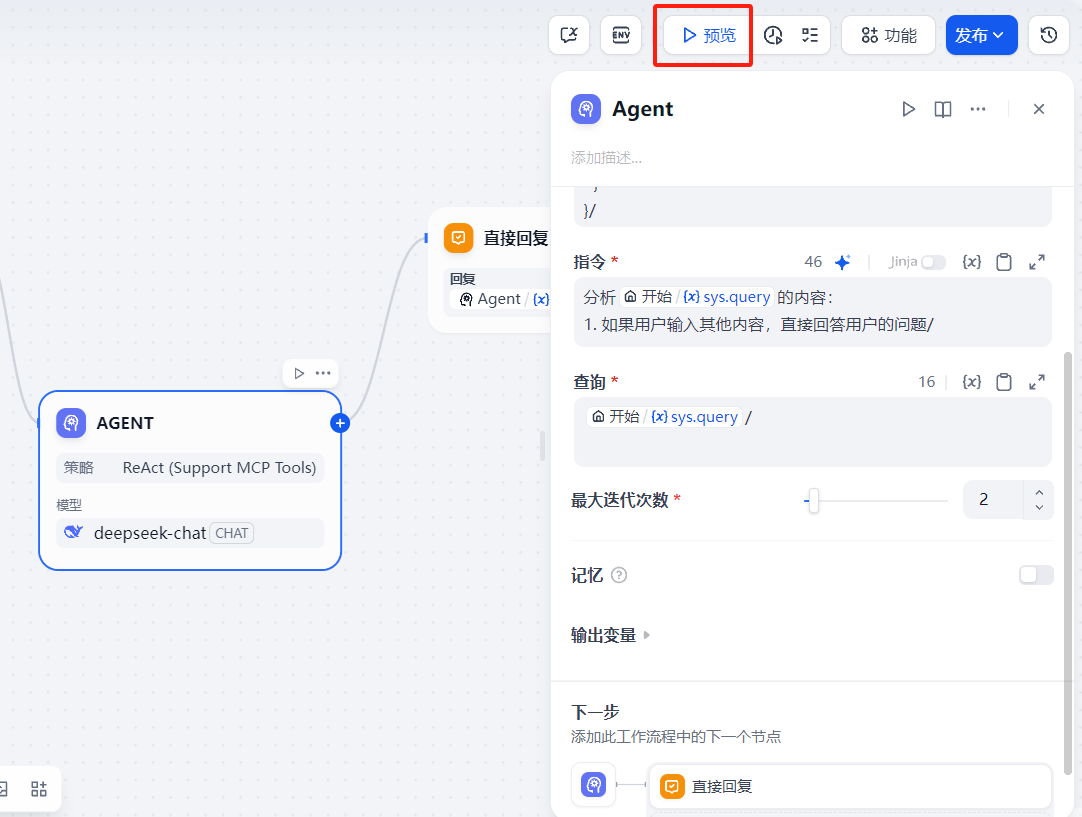
添加 Agent 节点
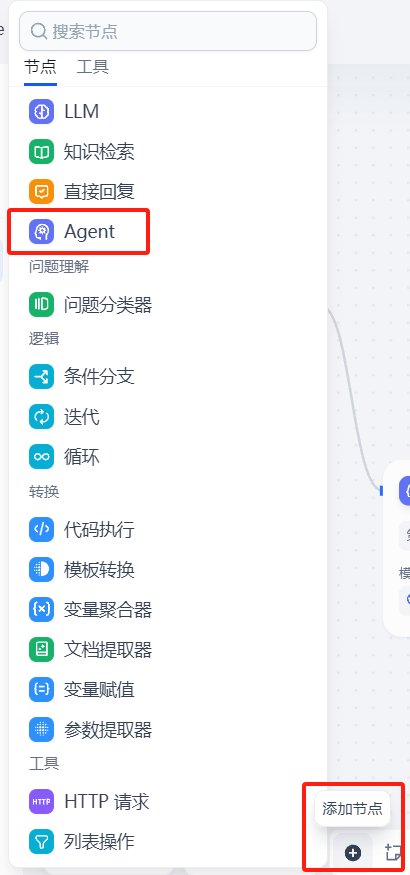
选择支持 MCP工具的 Agent 策略,若没有该选项,请前往 https://marketplace.dify.ai/ 中安装 MCP 插件
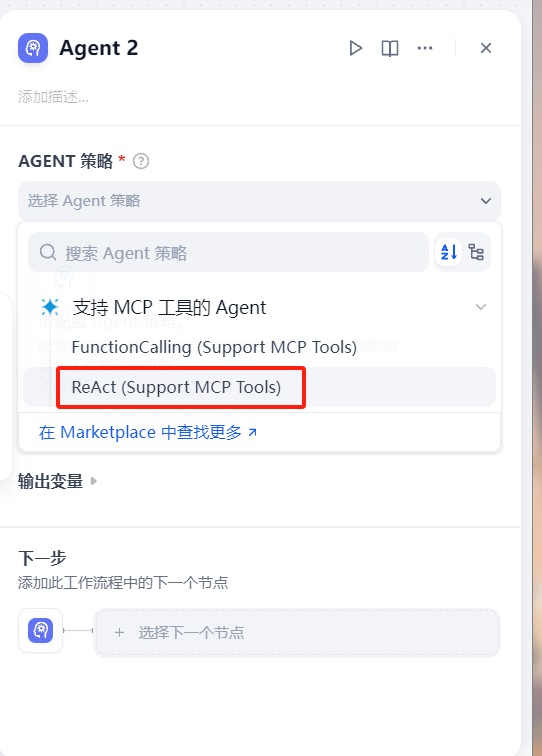
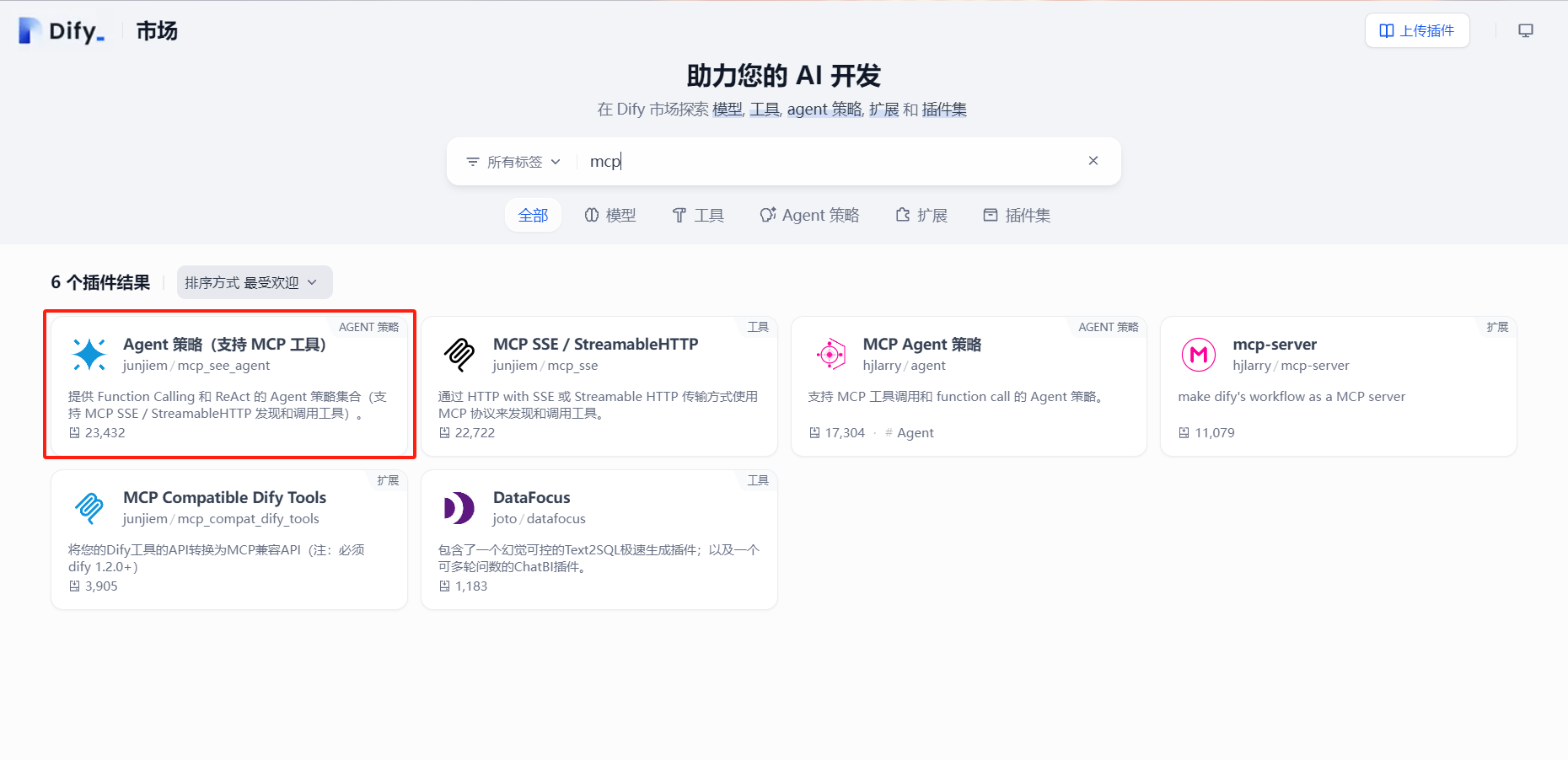
选择模型,进行 MCP 服务配置,注意,本地启动的 MCP Server 无法进行被访问到,需要在云服务器上部署好 MCP Server,详情请见 简易部署 MCP Server 章节
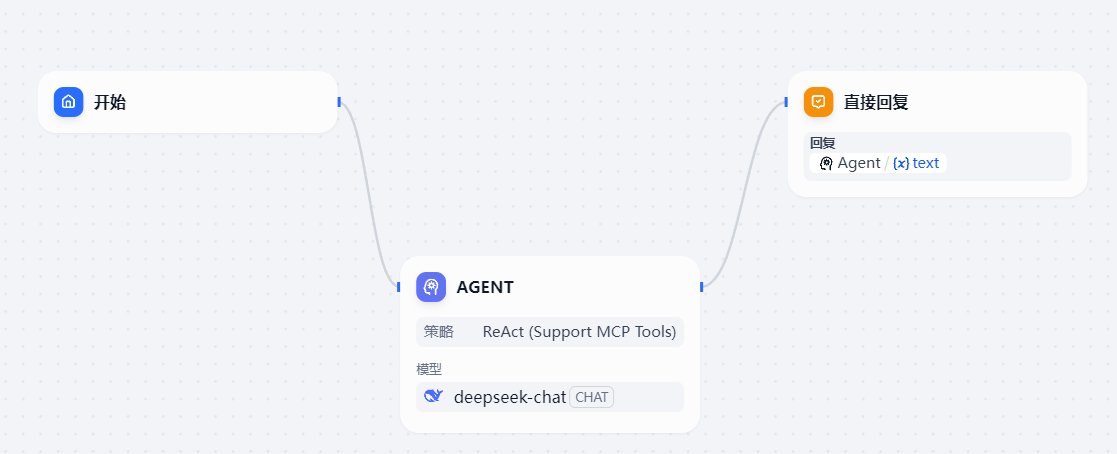
将开始节点和直接回复节点与 Agent 节点相连
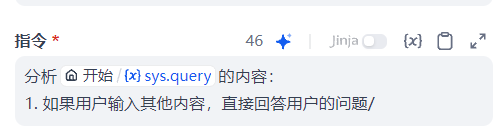
为了提高 Agent 调用工具的准确性,可以编写指令,当然 1. 若包含地区,则提取地区,调用工具”getNewsTop“ 删掉也能成功地调用相应工具。
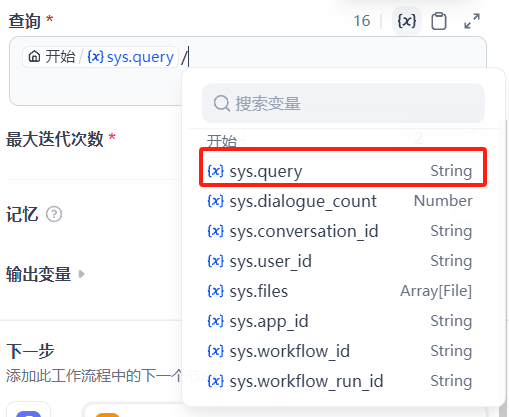
在查询中,添加开始节点中的 sys.query,最大迭代次数可以设置为 2
点击预览,进行聊天,发现的确调用了相关工具
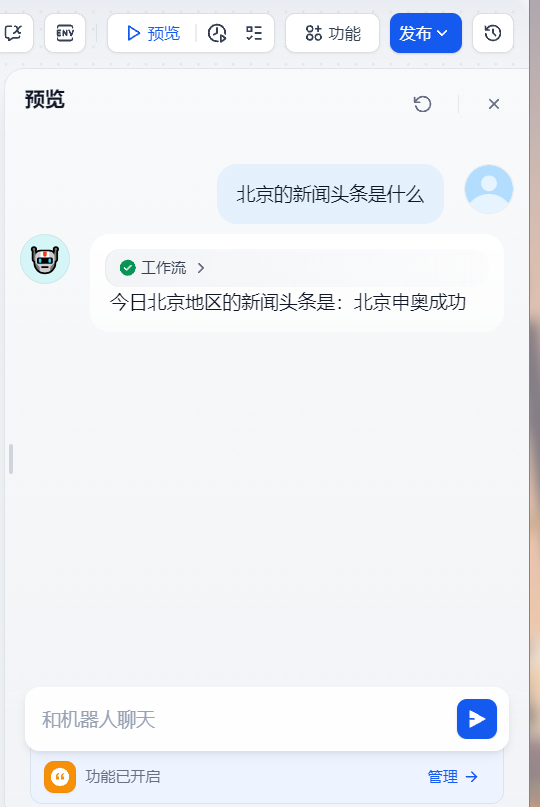
简易部署 MCP Server
RAG
检索增强生成(Retrieval-Augmented Generation, RAG),是一种结合了语言模型和信息检索的技术,其大致流程如下:
- 文档预处理与向量化存储:将生产数据处理为文档 Documents,用嵌入模型(如 OpenAI text-embedding、BERT 等)转为向量并存入向量数据库(如 Milvus、Faiss),保留语义。
- 用户查询向量化:用与文档处理相同的嵌入模型,将用户自然语言查询转为向量,确保向量空间一致。
- 语义检索:计算用户查询向量与库中文档向量的余弦相似度,返回相似度最高的 Top K 文档。
- 生成 LLM 输入:将用户查询和检索到的文档按模板合并,形成 LLM 的输入提示。
- 大模型输出与后处理:LLM 基于输入生成回答,减少幻觉 API 对输出格式化后返回结构化响应给用户。
下面我们按流程进行演示
文档预处理与向量化存储
文档提取
首先,我们要将生产数据(文本TXT、JSON、PDF、DOCX、Markdown、HTML、数据库等)处理为 Document
Spring AI 提供了 DocumentReader 来将生产数据转换为 Document,它的实现类有:
- **JsonReader**:读取 JSON 格式的文件 - **TextReader**:读取 txt 文件 - **PagePdfDocumentReader**:使用 Apache PdfBox 读取 PDF 文件 - **TikaDocumentReader**:使用 Apache Tika 来读取 PDF、DOC/DOCX、PPT/PPTX、HTML等文件
我们进行逐个演示:
txt
使用 TextReader 来读取违规行为管理规范.txt 文件内容:
@Component public class DocumentService { @Value("classpath:违规行为管理规范.txt") private Resource txtResource; public List loadText() { TextReader textReader = new TextReader(txtResource); textReader.getCustomMetadata().put("title", "违规行为管理规范.txt"); List documentList = textReader.get(); return documentList; } }@RestController public class RAGController { @Resource private DocumentService documentService; @GetMapping("/document/text") public List txtDocument() { return documentService.loadText(); } }
可以看到,Document 的格式由 id 文档的唯一标识符、text 文档主要内容、media 与文档相关的媒体内容、metadata 元数据和 score 用于排序和过滤的分数组成
JSON
使用 JsonReader 来读取 weather.json 文件内容:
@Component public class DocumentService { @Value("classpath:weather.json") private Resource jsonResource; public List loadJson() { JsonReader jsonReader = new JsonReader(jsonResource); List documents = jsonReader.get(); return documents; } }@RestController public class RAGController { @Resource private DocumentService documentService; @GetMapping("/document/json") public List jsonDocument() { return documentService.loadJson(); } }
PDF
引入 spring-ai-pdf-document-reader 依赖
org.springframework.ai spring-ai-pdf-document-reader 1.0.0-M6使用 PagePdfDocumentReader 来读取 raft.pdf 文件内容:
@Component public class DocumentService { @Value("classpath:raft.pdf") private Resource pdfResource; public List loadPdf() { PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource, PdfDocumentReaderConfig.builder() .withPageTopMargin(0) .withPageExtractedTextFormatter(ExtractedTextFormatter.builder() .withNumberOfTopTextLinesToDelete(0) .build()) .withPagesPerDocument(1) .build()); List read = pdfReader.read(); return read; } }@RestController public class RAGController { @Resource private DocumentService documentService; @GetMapping("/document/pdf") public List pdfDocument() { return documentService.loadPdf(); } }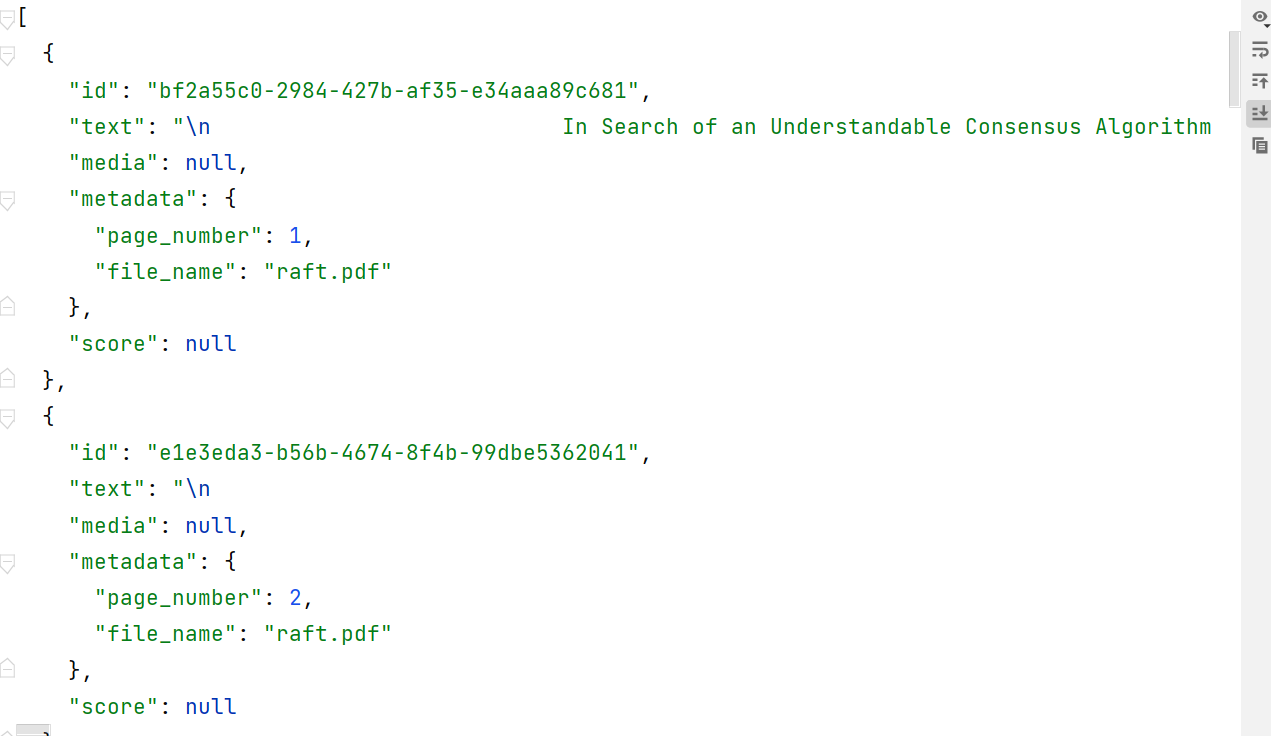
DOCX
引入 spring-ai-tika-document-reader 依赖
org.springframework.ai spring-ai-tika-document-reader 1.0.0-M6使用 TikaDocumentReader 来读取 test.docx 文件内容:
@Component public class DocumentService { @Value("classpath:test.docx") private Resource docxResource; public List loadDocx() { TikaDocumentReader docxReader = new TikaDocumentReader(docxResource); List documents = docxReader.read(); return documents; } }@RestController public class RAGController { @Resource private DocumentService documentService; @GetMapping("/document/docx") public List docxDocument() { return documentService.loadDocx(); } }
HTML
使用 TikaDocumentReader 来读取 =email.html 文件内容:
@Component public class DocumentService { @Value("classpath:email.html") private Resource htmlResource; public List loadHtml(){ TikaDocumentReader htmlReader = new TikaDocumentReader(htmlResource); List documents = htmlReader.read(); return documents; } }@RestController public class RAGController { @Resource private DocumentService documentService; @GetMapping("/document/html") public List htmlDocument() { return documentService.loadHtml(); } }
文档转换
接下来,我们要将文档 Document 分割成适合 AI 模型上下文窗口的片段,这里要使用的是
TokenTextSplitter,它基于 CL100K_BASE 编码,按 Token 数量分割文本,默认按 800Tokens/块 来分块
我们创建一个 TokenTextSplitter 对象
其中:
- defaultChunkSize 表示目标 Token 数,即每个块的 Token 数
- minChunkSizeChars 表示最小字符数,当某块因分隔符导致不足 defaultChunkSize 时,会至少保留minChunkSize 的内容
- minChunkLengthToEmbed 表示最小有效分块长度,避免过滤短句
- maxNumChunks 表示最大分块数
- keepSeparator 表示是否保留分隔符(如换行符)在文本块中,中文无需保留
调用 TokenTextSplitter 的 split 方法就可以对 Document 进行分块了
@Component public class DocumentService { @Value("classpath:test.docx") private Resource docxResource; public List loadDocx() { TikaDocumentReader docxReader = new TikaDocumentReader(docxResource); List documents = docxReader.read(); TokenTextSplitter splitter = new TokenTextSplitter( 30, // defaultChunkSize 目标Token数,即每个块的Token数 20, // minChunkSizeChars 最小字符数,当某块因分隔符导致不足chunkSize时,会至少保留minChunkSize的内容 1, // minChunkLengthToEmbed 最小有效分块长度,避免过滤短句 20, // maxNumChunks 最大分块数 false // keepSeparator 是否保留分隔符(如换行符)在文本块中,中文无需保留 ); List documentList = splitter.split(documents); LOGGER.info("分块后文档数: {}", documentList.size()); documentList.stream() .forEach(document -> LOGGER.info("Processing document: {}", document)); return documents; } }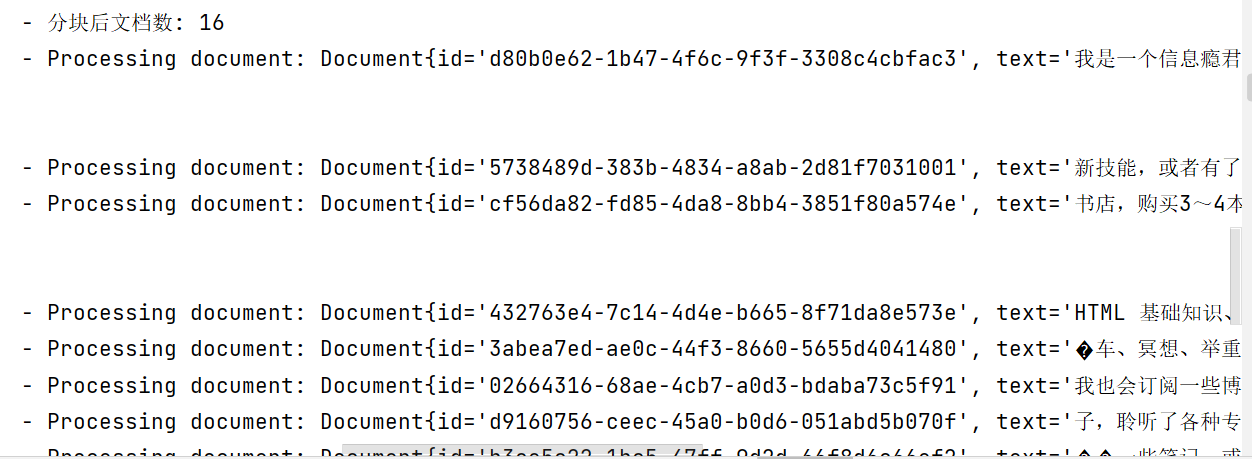
当然,我们还可以对 Document 的格式进行处理,使用 ContentFormatTransformer 并结合特定规则处理文档内容
其中,DefaultContentFormatter 定义了格式规则
public class ContentFormatTransformerTest { public static void main(String[] args) { Document doc = new Document( "北京今日天气:晴朗,气温 25°C,空气质量优", Map.of( "city", "北京", "date", "2024-03-20", "temperature", "25°C", "weather", "晴朗", "air_quality", "优", "humidity", "45%", "wind_speed", "3级" ) ); DefaultContentFormatter formatter = DefaultContentFormatter.builder() .withMetadataTemplate("{key}---{value}") // 元数据显示格式 .withMetadataSeparator("\n") // 元数据分隔符 .withTextTemplate("METADATA:\n{metadata_string}\nCONTENT:\n{content}") // 内容模板 .withExcludedInferenceMetadataKeys("air_quality") // 推理时排除的元数据 .withExcludedEmbedMetadataKeys("wind_speed") // 嵌入时排除的元数据 .build(); String content = formatter.format(doc, MetadataMode.EMBED); System.out.println(content); ContentFormatTransformer transformer = new ContentFormatTransformer(formatter, false); List documentList = transformer.apply(List.of(doc)); documentList.forEach(System.out::println); } }此外,我们还可以使用 KeywordMetadataEnricher,它会使用大模型提取文档关键词,并添加在元数据中
其中,KeywordMetadataEnricher 中的第一个参数为 ChatModel 模型,第二个参数为所提取的最大关键词数量
@Service public class KeywordMetadataEnricherTest { @Resource private OpenAiChatModel openAiChatModel; public String getKeywords() { Document doc = new Document(""" 今日北京,碧空如洗,澄澈的蓝天如同被反复擦拭过的蓝宝石,不见一丝云彩。 温暖的阳光毫无保留地倾洒在这座古老又现代的城市,气温稳定维持在 25°C, 体感舒适宜人,微风轻拂,带着些许春日的惬意。 空气质量达到了优的级别,清新的空气沁人心脾,无论是漫步在故宫的红墙黄瓦间, 还是穿梭于国贸的高楼大厦中,都能尽情享受每一口呼吸。 这样的好天气,引得市民纷纷走出家门,公园里孩童嬉笑玩耍,护城河旁老人悠闲垂钓, 街头巷尾满是活力与生机,处处洋溢着幸福的气息。 """, Map.of( "city", "北京", "date", "2024-03-20", "temperature", "25°C", "weather", "晴朗", "air_quality", "优", "humidity", "45%", "wind_speed", "3级" )); // 构造 KeywordMetadataEnricher,传入 OpenAiChatModel,并设置最大关键词数量为 5 KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(openAiChatModel,5); List documentList = enricher.apply(List.of(doc)); // 输出生成的关键词 String keywords = (String) documentList.get(0).getMetadata().get("excerpt_keywords"); return keywords; } }测试
@RestController public class RAGController { @Resource private KeywordMetadataEnricherTest keywordMetadataEnricherTest; @GetMapping("/document/keywords") public String xmlDocument() { return keywordMetadataEnricherTest.getKeywords(); } }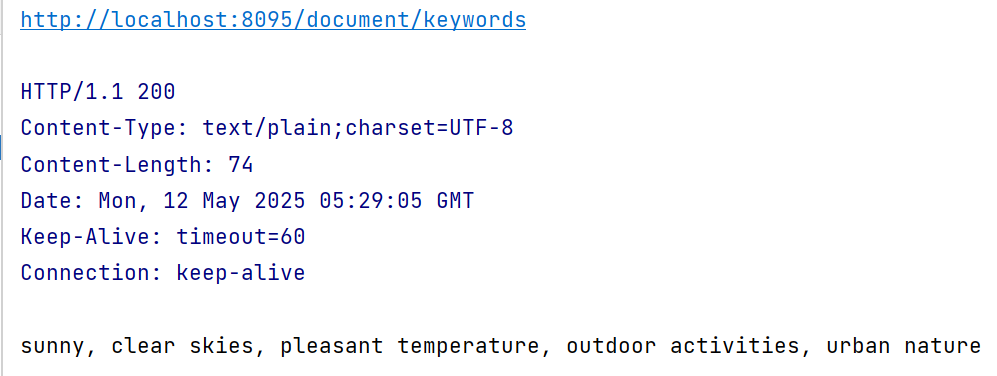
接下来,演示 SummaryMetadataEnricher(它使用大模型提取文档摘要,在元数据中添加一个 section_summary/prev_section_summary/next_section_summary 字段),它不仅可以生成当前文档的摘要,还能生成相邻文档(前一篇和后一篇)的摘要
SummaryMetadataEnricher 中的参数如下:
* chatModel:用于生成摘要的 AI 模型
* summaryTypes:指定生成哪些类型的摘要(PREVIOUS、CURRENT、NEXT)
* summaryTemplate(可选):自定义摘要生成模板(默认是英文,可以改写成中文的)
* metadataMode(可选):控制生成摘要时如何处理文档的元数据
@Service public class SummaryMetadataEnricherTest { @Resource private OpenAiChatModel openAiChatModel; public List getSummary() { Document doc1 = new Document(""" 今日北京,碧空如洗,澄澈的蓝天如同被反复擦拭过的蓝宝石,不见一丝云彩。 温暖的阳光毫无保留地倾洒在这座古老又现代的城市,气温稳定维持在 25°C, 体感舒适宜人,微风轻拂,带着些许春日的惬意。 空气质量达到了优的级别,清新的空气沁人心脾,无论是漫步在故宫的红墙黄瓦间, 还是穿梭于国贸的高楼大厦中,都能尽情享受每一口呼吸。 这样的好天气,引得市民纷纷走出家门,公园里孩童嬉笑玩耍,护城河旁老人悠闲垂钓, 街头巷尾满是活力与生机,处处洋溢着幸福的气息。 """, Map.of( "city", "北京", "date", "2024-03-20", "temperature", "25°C", "weather", "晴朗", "air_quality", "优", "humidity", "45%", "wind_speed", "3级" ) ); Document doc2 = new Document(""" 今日上海,全球瞩目的2024世界人工智能大会在浦东世博中心盛大开幕。 来自40多个国家的2000余位科技精英齐聚一堂,展示了最新的AI研究成果。 开幕式上,由中国科学院研发的"启明-9000"超级计算机首次公开亮相, 其算力达到每秒10^18次浮点运算,较前代提升300%,能耗却降低40%。 现场还展示了AI驱动的医疗诊断系统,能在10秒内完成肺部CT影像分析, 准确率高达99.7%。各大科技巨头纷纷发布智能机器人、自动驾驶等前沿产品, 彰显了AI技术在赋能实体经济、改善民生等领域的巨大潜力。 """, Map.of( "city", "上海", "date", "2024-05-15", "event", "世界人工智能大会", "location", "浦东世博中心", "key_technology", "超级计算机、AI医疗、智能机器人", "organizer", "中国科学院、科技部" ) ); Document doc3 = new Document(""" 西安城墙下,第十四届"长安国际艺术节"在春日的暖阳中拉开帷幕。 来自全球15个国家的80余个艺术团体带来了为期20天的文化盛宴。 开幕式上,敦煌研究院与法国卢浮宫联合打造的"丝路文明对话"光影秀惊艳全场, 3D投影技术将莫高窟壁画与卢浮宫馆藏完美融合,呈现出跨越时空的艺术对话。 日本能剧、西班牙弗拉门戈等世界非遗表演轮番登场, 更有陕派秦腔与现代交响乐的创新融合演出,吸引了3万余名观众到场欣赏。 艺术节期间,还将举办20余场学术研讨会和50多场艺术工作坊, 为不同文化背景的艺术家和观众搭建起交流互鉴的桥梁。 """, Map.of( "city", "西安", "date", "2024-04-08", "event", "长安国际艺术节", "duration", "20天", "participants", "15国80余个艺术团体", "highlight", "丝路文明对话光影秀、非遗表演" ) ); // 构造 SummaryMetadataEnricher,传入 OpenAiChatModel,指定要生成的摘要类型 String template = """ 请基于以下文本提取核心信息: {context_str} 要求: 1. 使用简体中文 2. 包含关键实体 3. 不超过50字 摘要: """; SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher( openAiChatModel, List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS, SummaryMetadataEnricher.SummaryType.CURRENT, SummaryMetadataEnricher.SummaryType.NEXT), template, MetadataMode.ALL ); List documentList = summaryMetadataEnricher.apply(List.of(doc1, doc2, doc3)); String summary1 = (String) documentList.get(0).getMetadata().get("section_summary"); String summary2 = (String) documentList.get(1).getMetadata().get("prev_section_summary"); String summary3 = (String) documentList.get(2).getMetadata().get("next_section_summary"); return Arrays.asList(summary1, summary2, summary3); } }@RestController public class RAGController { @Resource private SummaryMetadataEnricherTest summaryMetadataEnricherTest; @GetMapping("/document/summary") public List summaryDocument() { return summaryMetadataEnricherTest.getSummary(); } }
文档写入到文件
使用 FileDocumentWriter 来将 Document 写入到文件中
其中:
- fileName 表示目标文件名
- withDocumentMarkers 表示是否在输出中包含文档标记(默认false)
- metadataMode 表示指定写入文件的文档内容格式(默认MetadataMode.NONE)
- append 表示是否追加写入文件(默认false)
调用 accept 方法,传入 List
@Service public class DocumentWriterTest { public static void main(String[] args) { Document doc1 = new Document("今日北京,碧空如洗,澄澈的蓝天如同被反复擦拭过的蓝宝石,不见一丝云彩。"); Document doc2 = new Document("温暖的阳光毫无保留地倾洒在这座古老又现代的城市,气温稳定维持在 25°C"); Document doc3 = new Document("体感舒适宜人,微风轻拂,带着些许春日的惬意。"); FileDocumentWriter fileDocumentWriter = new FileDocumentWriter( "output.txt", true, MetadataMode.ALL, false ); fileDocumentWriter.accept(List.of(doc1, doc2, doc3)); } }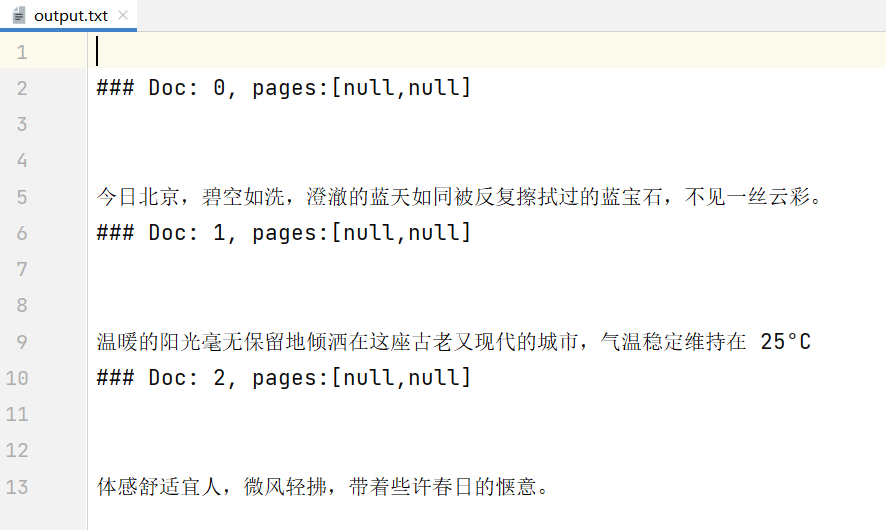
向量化存储
Spring AI 通过 VectorStore 接口为向量数据库交互提供了抽象化的 API,这里的向量数据库我选择了 Milvus
安装 Milvus 及 Attu
在 Docker 中安装 Milvus,输入以下命令:
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh bash standalone_embed.sh start
可以访问 Milvus WebUI,网址是 http://your_host:9091/webui/
Attu 是 Milvus 的官方 GUI 客户端,提供更直观的操作体验
在 Docker 中安装运行 Attu,输入以下命令:
docker run -d --name attu -p 8000:3000 -e MILVUS_URL=your_host:19530 zilliz/attu:v2.5.6
访问 Attu 的地址:http://your_host:8000
使用 Milvus
引入 spring-ai-milvus-store 依赖
org.springframework.ai spring-ai-milvus-store-spring-boot-starter 1.0.0-M6这里我使用的文本向量模型是阿里的 text-embedding 系列,阿里云百炼:https://help.aliyun.com/zh/model-studio/get-api-key,可能是不兼容的原因,我们不再使用 spring-ai-openai-spring-boot-starter 依赖,而是使用 spring-ai-alibaba-starter 依赖
com.alibaba.cloud.ai spring-ai-alibaba-starter 1.0.0-M5.1修改 yml 文件中的配置,在 .env 中填写 api-key
spring: # ai 配置 ai: dashscope: api-key: ${AI_API_KEY}首先将数据存入到 Milvus 中,使用 vectorStore 的 add 方法,传入 List
@Service public class MilvusService { @Value("classpath:违规行为管理规范.txt") private Resource textResource; @jakarta.annotation.Resource private MilvusVectorStore vectorStore; public void initMilvus() { TextReader textReader = new TextReader(textResource); textReader.getCustomMetadata().put("title", "违规行为管理规范.txt"); TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(); List documentList = tokenTextSplitter.apply(textReader.get()); vectorStore.add(documentList); LOGGER.info("Vector data initialized"); } }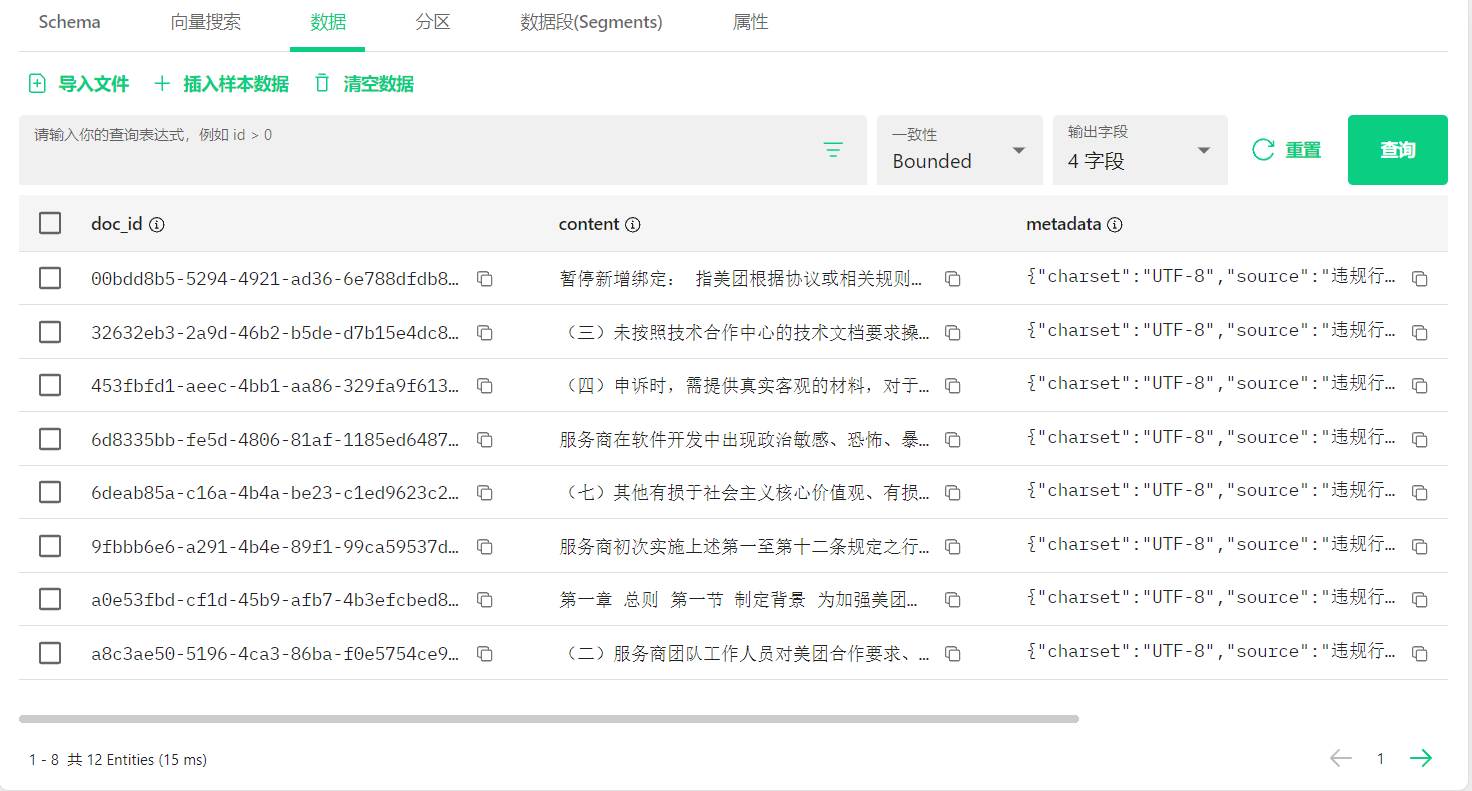
LLM + Milvus
首先测试一下向量搜索,根据用户输入搜索最相似的文本
在 advisors 方法中 new 一个 QuestionAnswerAdvisor,传入 milvusVectorStore 和SearchRequest,其中,.query(userInput) 表示搜索的文本,.topK(5) 表示要搜索的数量
@RestController public class RAGController { private static final Logger LOGGER = LoggerFactory.getLogger(RAGController.class); @Resource private ChatClient chatClient; @Resource private MilvusVectorStore milvusVectorStore; @GetMapping("/chat/rag") public String initChat(@RequestParam(value = "userInput") String userInput) { return chatClient.prompt() .user(userInput) .advisors(new QuestionAnswerAdvisor(milvusVectorStore, SearchRequest.builder() .query(userInput) .topK(5) .build() ) ) .call() .content(); } }对比文档可以看到确实进行了向量搜索

当然,我们可以将用户输入和检索到的文档进行合并,形成 LLM 的输入提示
@GetMapping("/rag") public String milvusRag(@RequestParam(value = "input") String input) { PromptTemplate promptTemplate = new PromptTemplate(""" 你是一个违规行为管理规范答疑助手,请结合文档提供的内容回答用户的问题,如果不知道请直接回答不知道 用户输入的问题: {input} 文档: {documents} """); // 构造 SearchRequest SearchRequest searchRequest = SearchRequest.builder() .query(input) .topK(5).build(); // 从向量数据库中搜索到的最相似的 Document List documentList = milvusVectorStore.similaritySearch(searchRequest); // 转换为 String List stringList = documentList.stream() .map(Document::getText) .collect(Collectors.toList()); // 拼接 String relevantDocs = String.join("\n", stringList); LOGGER.info("用户问题={},查询结果={}", input, relevantDocs); // 构造 PromptTemplate 参数 Map params = new HashMap(); params.put("input", input); params.put("documents", relevantDocs); return chatClient.prompt(new Prompt(promptTemplate.render(params))) .call() .content(); }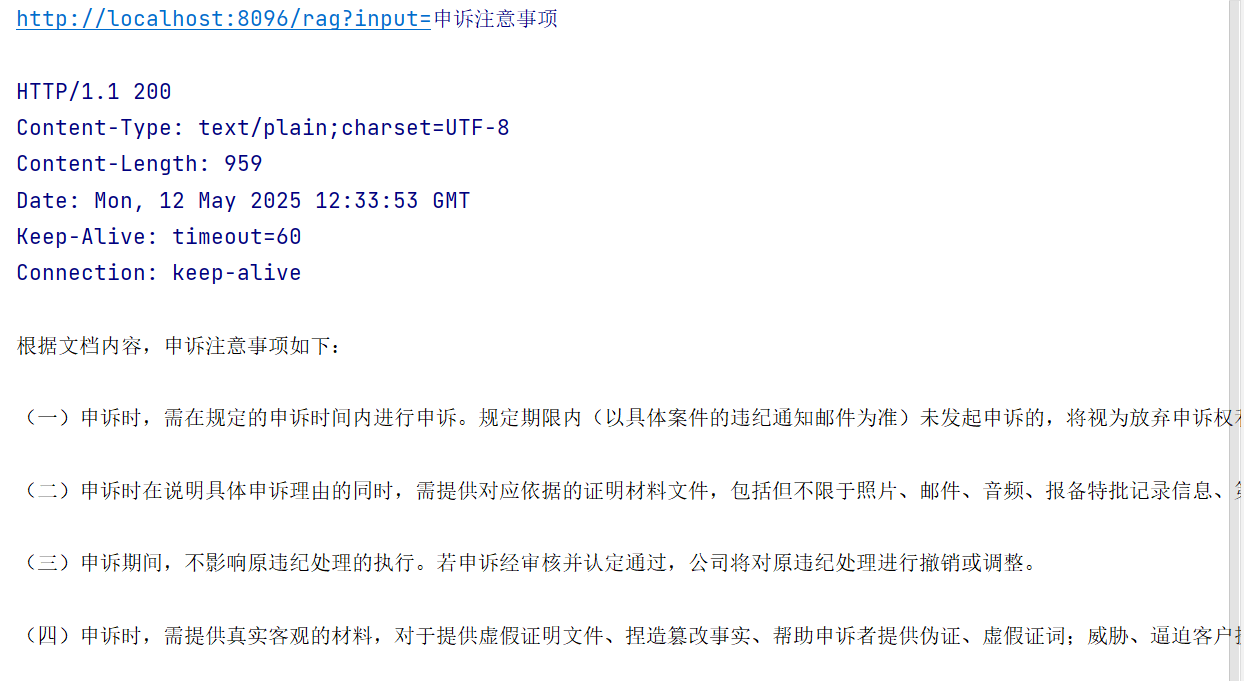
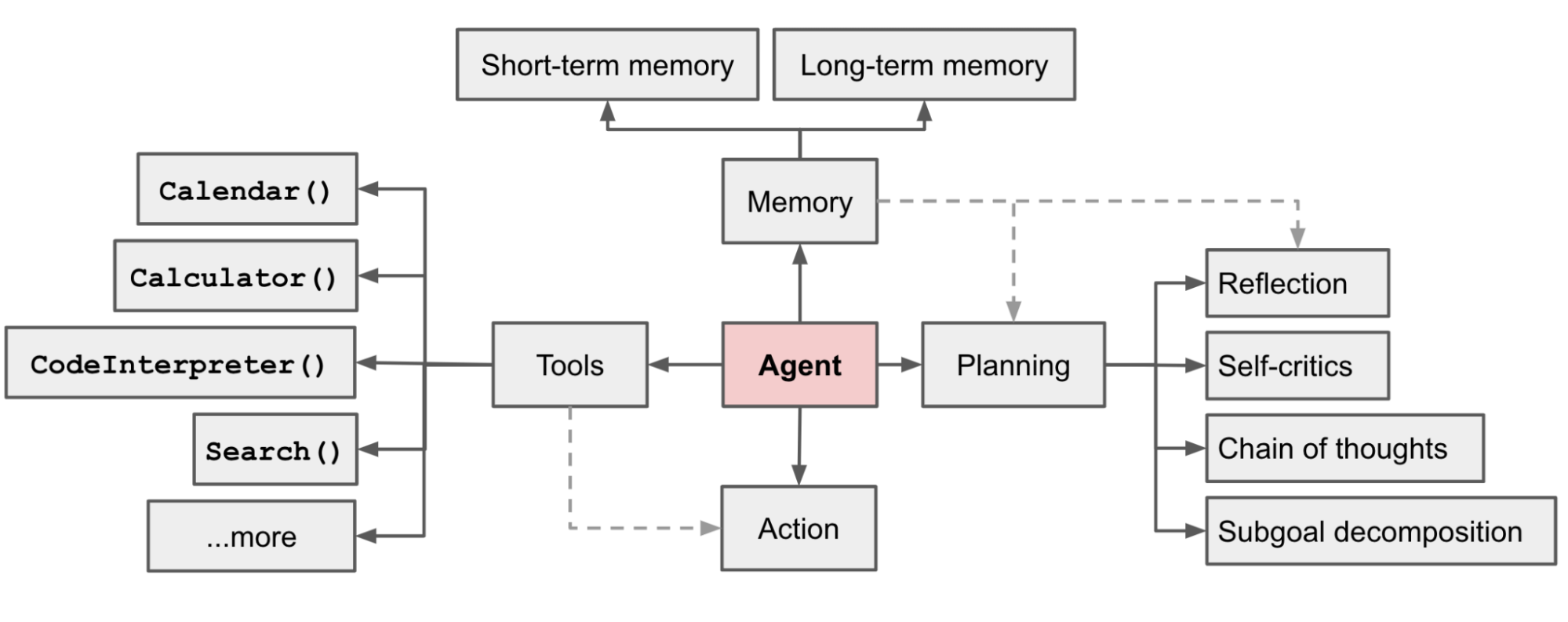
Aegnt
Agent 并非一个标准概念,它可以是完全自主的系统,也可以是遵循预定工作流的系统。Anthropic 将这些变体统称为 Agent 系统,并将其在实现架构上划分为两类:
- 工作流 Workflow:通过预定义的代码路径去编排 LLM 和工具
- 智能体 Agent:LLM 动态指导自身流程和工具使用,保持对任务完成方式的控制
Agent 框架通常以 LLM 为核心,以工具 Tool、规划 Planning、记忆 Memory 和行动 Action 等多个模块共同组成
Workflow Agent(Workflow)
Workflow Agent 是通过预定义代码路径协调 LLM 和工具的系统,我们在构建 Workflow Agent 时需要针对业务进行步骤分解和流程设计
提示链(Prompt chaining)
提示链将任务分解为一系列步骤,其中每个 LLM 调用都会处理前一个步骤的输出。我们可以在任何中间步骤上添加程序化检查(Gate),以确保流程仍在正常进行。
此工作流程非常适合任务可以轻松清晰地分解为固定子任务的情况。其主要目标是通过简化每次 LLM 调用,以降低延迟并提高准确率。

为此,我们需要对业务步骤进行拆解,构建出一个 Prompt 列表,通过循环串行化执行 LLM Call
示例:使用提示链将电商平台商品信息格式化输出
首先编写一个 WorkflowService 接口,定义 startPromptChainingWorkflow 方法
public interface WorkflowService { String startPromptChainingWorkflow(String userInput); }在其实现类中,我们将该示例业务拆解成 4 个步骤,对每个步骤编写对应的 Prompt
在 chain 方法中,我们在 for 循环中链式执行 Prompt 数组
@Service public class WorkflowServiceImpl implements WorkflowService { private static final String [] DEFAULT_SYSTEM_PROMPTS = { // 步骤1 """ 从文本中提取商品名称、价格、库存数量、销量或其他重要信息。 每条数据格式为 "信息类别:具体内容",各占一行。 示例格式: 商品名称:智能蓝牙耳机 价格: 199 元 库存数量: 50 销量: 1200 """, // 步骤2 """ 将价格统一保留两位小数,并去除货币单位(元)。 将库存数量和销量转换为整数形式(每隔3位用逗号分隔)。 保持每行一个信息。 示例格式: 商品名称:智能蓝牙耳机 价格: 199.00 库存数量: 5,000,000 销量: 1,200 """, // 步骤3 """ 仅保留销量大于 1000 的商品信息,并按销量降序排列。 保持每行 "信息类别:具体内容" 的格式。 示例: 商品名称:智能蓝牙耳机 价格: 199.00 库存数量: 5,000,000 销量: 1,200 """, // 步骤4 """ 将排序后的数据格式化为Markdown表格,包含商品名称、价格、库存数量、销量或其他信息列 要求仅输出Markdown表格,不要包含任何其他文本: | 商品名称 | 价格 | ... | |:--|--:||--:| | 智能蓝牙耳机 | 199.00 || ... | """ }; @Resource(name = "openAiChatClient") private ChatClient openAiChatClient; public String chain(String Input) { int step = 0; String response = Input; // 初始用户输入 System.out.println(String.format("\nSTEP %s:\n %s", step++, response)); // 串行化调用 LLM for (String prompt : DEFAULT_SYSTEM_PROMPTS) { String input = String.format("{%s}\n {%s}", prompt, response); response = openAiChatClient.prompt(input) .call() .content(); System.out.println(String.format("\nSTEP %s:\n %s", step++, response)); } return response; } @Override public String startPromptChainingWorkflow(String userInput) { return chain(userInput); } }测试效果,可以看到,控制台中输出的每个步骤的执行结果,最终返回了一个 Markdown 表格,符合预期要求
@RestController public class AgentController { @Resource private WorkflowService workflowService; @GetMapping("/agent/chain") public String chain(@RequestParam("userInput") String userInput) { return workflowService.startPromptChainingWorkflow(userInput); } }STEP 0: 我们新上架了一批商品,智能蓝牙耳机,价格 199.8 元,库存 50 件,销量 120000;复古机械键盘,价格 299 元,库存 30 件,销量 800;无线鼠标,价格 89.9 元,库存 100 件,销量 15000。 STEP 1: 商品名称:智能蓝牙耳机 价格:199.8 元 库存数量:50 销量:120000 商品名称:复古机械键盘 价格:299 元 库存数量:30 销量:800 商品名称:无线鼠标 价格:89.9 元 库存数量:100 销量:15000 STEP 2: 商品名称:智能蓝牙耳机 价格:199.80 库存数量:50 销量:120,000 商品名称:复古机械键盘 价格:299.00 库存数量:30 销量:800 商品名称:无线鼠标 价格:89.90 库存数量:100 销量:15,000 STEP 3: 商品名称:智能蓝牙耳机 价格:199.80 库存数量:50 销量:120,000 商品名称:无线鼠标 价格:89.90 库存数量:100 销量:15,000 STEP 4: | 商品名称 | 价格 | 库存数量 | 销量 | |:---------------|------:|---------:|--------:| | 智能蓝牙耳机 | 199.80| 50 | 120,000 | | 无线鼠标 | 89.90 | 100 | 15,000 |

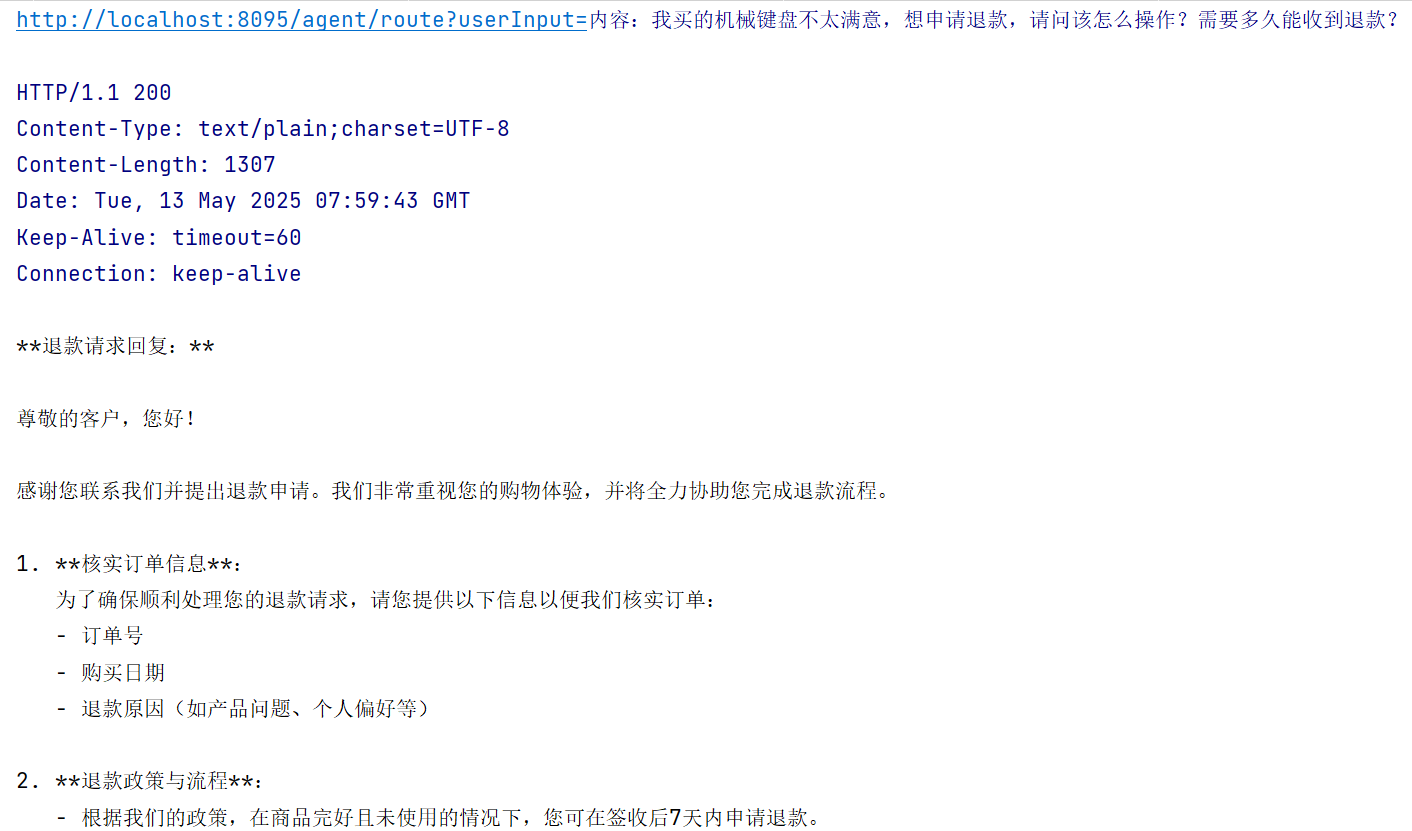
路由(Routing)
路由会对输入进行分类,并将其定向到专门的后续任务。此工作流程允许分离关注点,并构建更专业的提示。如果没有此工作流程,针对一种输入进行优化可能会损害其他输入的性能。

路由非常适合复杂任务,其中存在不同的类别,最好分别处理
示例:将不同类型的客户服务查询(一般问题、退款请求、技术支持、合作沟通)引导到不同的下游流程中
在接口中添加 startRoutingWorkflow 方法
String startRoutingWorkflow(String userInput);
我们将 Prompt 全部放到一个常量类中,方便管理
public class PromptConstant { public static final String [] DEFAULT_SYSTEM_PROMPTS = { // 步骤1 """ 从文本中提取商品名称、价格、库存数量、销量或其他重要信息。 每条数据格式为 "信息类别:具体内容",各占一行。 示例格式: 商品名称:智能蓝牙耳机 价格: 199 元 库存数量: 50 销量: 1200 """, // 步骤2 """ 将价格统一保留两位小数,并去除货币单位(元)。 将库存数量和销量转换为整数形式(每隔3位用逗号分隔)。 保持每行一个信息。 示例格式: 商品名称:智能蓝牙耳机 价格: 199.00 库存数量: 5,000,000 销量: 1,200 """, // 步骤3 """ 仅保留销量大于 1000 的商品信息,并按销量降序排列。 保持每行 "信息类别:具体内容" 的格式。 示例: 商品名称:智能蓝牙耳机 价格: 199.00 库存数量: 5,000,000 销量: 1,200 """, // 步骤4 """ 将排序后的数据格式化为Markdown表格,包含商品名称、价格、库存数量、销量或其他信息列 要求仅输出Markdown表格,不要包含任何其他文本: | 商品名称 | 价格 | ... | |:--|--:||--:| | 智能蓝牙耳机 | 199.00 || ... | """ }; public static final Map ROUTE_MAP = Map.of ( "general", """ 您是一位客户服务专员。请遵循以下准则: 1.始终以 "通用问题回复:" 开头 2.全面理解客户提出的一般问题,先表达共情与理解 3.用简洁易懂的语言解答问题,若涉及复杂政策,进行通俗解释 4.对于无法直接回答的问题,告知客户后续跟进方式及预计时间 5.保持友好、耐心的沟通语气 输入: """, "refund", """ 您是一位退款处理专员。请遵循以下准则: 1.始终以 "退款请求回复:" 开头 2.优先核实客户订单及退款原因,安抚客户情绪 3.详细说明退款政策、流程及预计到账时间 4.指导客户提交必要的退款材料,提供提交方式和地址 5.定期告知客户退款进度查询方式 6.保持专业且负责的态度 输入: """, "technical_support", """ 1.您是一位技术支持人员。请遵循以下准则: 2.始终以 "技术支持回复:" 开头 3.询问客户具体的技术问题表现,收集系统环境信息 4.列出分步骤的排查和解决方法,附上操作截图示例 5.提供临时替代方案以保障客户紧急使用需求 6.若问题复杂,说明升级至高级技术团队的流程和预计响应时间 7.使用清晰的技术术语,表述严谨 输入: """, "cooperation", """ 1.您是一位合作对接专员。请遵循以下准则: 2.始终以 "合作沟通回复:" 开头 3.热情回应客户的合作意向,询问合作需求和期望 4.介绍公司合作政策、优势资源及成功案例 5.安排专人与客户进行后续详细对接,告知对接人信息和时间 6.提供合作相关资料的获取方式 7.保持积极主动、开放合作的态度 输入: """ ); }使用到的实体类
@Data @AllArgsConstructor @NoArgsConstructor public class RoutingResponse { private String reason; private String selection; }在接口实现类中,**route 方法负责进行路由操作,并根据路由到的提示词调用 LLM 返回结果 **
public String route(String input, Map routeMap){ Set stringSet = routeMap.keySet(); // 路由操作提示词 String routePrompt = String.format(""" 分析输入内容并从以下选项中选择最合适的查询类型:%s 首先解释你的判断依据,然后按照以下JSON格式提供选择: \\{ "reasoning": "简要说明为何该客户服务查询应选择该查询类型。 需考虑关键词、用户意图和紧急程度。", "selection": "所选查询类型名称" \\} 输入:%s""", stringSet, input); // 调用 LLM,获取路由结果响应 RoutingResponse routeResponse = openAiChatClient.prompt(new Prompt(routePrompt)) .call() .entity(RoutingResponse.class); LOGGER.info("RouteResponse: " + "Reason---" + routeResponse.getReason() + "\n" + "Selection---" + routeResponse.getSelection()); // 获取路由结果响应中的提示词 String callPrompt = routeMap.get(routeResponse.getSelection()); // 调用 LLM String content = openAiChatClient.prompt(new Prompt(callPrompt + "\n" + input)) .call() .content(); // 返回结果 return content; } @Override public String startRoutingWorkflow(String userInput) { return route(userInput, PromptConstant.ROUTE_MAP); }测试效果,从控制台中可以看到,用户输入被路由到了 refund,符合预期要求
@GetMapping("/agent/route") public String route(@RequestParam("userInput") String userInput) { return workflowService.startRoutingWorkflow(userInput); }

并行化(Parallelization)
LLM 有时可以同时处理一项任务,并以编程方式聚合其输出
何时使用:拆分后的子任务可以并行化以提高速度、需要多个视角或尝试以获得更高置信度的结果
对于涉及多个考量的复杂任务,当每个考量都由单独的 LLM 调用处理时,LLM 通常表现更好,从而能够专注于每个特定方面。

示例:分析气候变化趋势对各个行业的系统性风险和机遇
由于可以对每个行业的分析单独执行,因此可以并行化
在接口中新增 startParallelWorkflow 方法
List startParallelWorkflow(String userInput);
在常量中增加一个 PARALLEL_PROMPT
public static final String PARALLEL_PROMPT = """ 分析气候变化趋势对该行业的系统性风险和机遇, 构建包含短期(1-3年)、中期(3-5年)、长期(5-10年)的战略应对框架。 使用清晰的分区和优先级进行格式化。 """;用户可以输入多个行业,startParallelWorkflow 方法可以将其拆分为多个子任务并行执行,其中核心线程数为子任务数(行业数)
@Override public List startParallelWorkflow(String userInput) { String regex = "[,。!?;、,.!?;]+"; String[] userInputArr = userInput.split(regex); List userInputList = Arrays.asList(userInputArr); // 核心线程数 int nWorkers = userInputArr.length; String prompt = PromptConstant.PARALLEL_PROMPT; ExecutorService executorService = Executors.newFixedThreadPool(nWorkers); try{ List completableFutureList = userInputList.stream().map(input -> CompletableFuture.supplyAsync(() -> { try { return openAiChatClient.prompt(prompt + "\nInput: " + input) .call() .content(); } catch (Exception e) { throw new RuntimeException(e); } }, executorService) ).collect(Collectors.toList()); // 并行等待所有任务完成 CompletableFuture voidCompletableFuture = CompletableFuture.allOf( completableFutureList.toArray(CompletableFuture[]::new) ); voidCompletableFuture.join(); List collect = completableFutureList.stream().map(CompletableFuture::join) .collect(Collectors.toList()); LOGGER.info("ParallelWorkflow: " + collect); return collect; } finally { executorService.shutdown(); } }测试
@GetMapping("/agent/parallel") public List parallel(@RequestParam("userInput") String userInput) { return workflowService.startParallelWorkflow(userInput); }
#### **一、系统性风险分析** --- 1. **物理风险** - **极端天气事件**:干旱、洪水、热浪等频率增加,影响作物产量和质量。 - **水资源短缺**:降水模式变化导致灌溉用水不足。 - **土壤退化**:高温和侵蚀加剧土壤肥力下降。 2. **转型风险** - **政策压力**:碳排放税、环保法规趋严增加生产成本。 - **市场需求变化**:消费者偏好转向低碳农产品,传统产品需求下降。 - **技术滞后**:未能适应气候智能型农业技术可能被淘汰。 3. **供应链风险** - **物流中断**:极端天气破坏运输和仓储设施。 - **投入成本上升**:化肥、农药等因能源价格波动或短缺而涨价。 --- ### 农业行业的气候变化趋势分析及战略应对框架 #### **二、机遇分析** 1. **气候适应型农业** - 耐旱/耐涝作物品种、精准灌溉技术等需求增长。 2. **碳汇经济** - 通过再生农业、森林碳汇项目获取额外收益。 3. **政策与市场激励** - 政府对绿色农业的补贴和碳交易机制支持。 4. **技术创新** - 垂直农业、AI病虫害预测等提升效率。 --- ### **三、战略应对框架** #### **短期(1-3年):风险缓解与基础能力建设** **优先级:高(生存与合规)** 1. **风险应对** - 引入天气指数保险,对冲极端气候损失。 - 建立应急水源储备和多元化供应链。 2. **技术试点** - 试点耐候作物品种和小规模精准灌溉系统。 3. **政策响应** - 跟踪碳减排政策,优化现有生产流程以符合法规。 --- #### **中期(3-5年):转型与效率提升** **优先级:中高(竞争力提升)** 1. **技术规模化** - 推广气候智能农业技术(如土壤湿度传感器、滴灌)。 - 投资可再生能源(太阳能水泵、生物质能)。 2. **市场调整** - 开发低碳认证农产品,抢占细分市场。 3. **合作网络** - 与科研机构合作育种,参与碳汇项目试点。 --- #### **长期(5-10年):可持续领导力构建** **优先级:中(战略重塑)** 1. **系统变革** - 全面转向再生农业(轮作、免耕、有机肥料)。 - 布局垂直农业或气候适应性强的区域生产基地。 2. **价值链整合** - 构建从生产到销售的低碳闭环供应链。 3. **政策与资本利用** - 利用碳交易市场实现盈利,争取长期政策红利。 --- ### **四、优先级矩阵** | 时间框架 | 关键行动领域 | 优先级 | 资源投入建议 | |----------|----------------------------|--------|--------------| | 短期 | 应急风险管理、合规 | 高 | 20%-30% | | 中期 | 技术升级、市场差异化 | 中高 | 40%-50% | | 长期 | 模式创新、生态整合 | 中 | 20%-30% | --- **注**:农业企业需根据自身规模(如小农户 vs 大型农企)调整策略重点,小农户可优先依赖政策支持与合作社协作,大企业则需引领技术创新和标准制定。, ### 气候变化对保险业的系统性风险与机遇分析及战略应对框架 #### **一、系统性风险** 1. **物理风险** - **短期(1-3年)**:极端天气事件(如飓风、洪水、野火)频发,导致财产险赔付激增,再保险成本上升。 - **中期(3-5年)**:海平面上升和慢性气候灾害(如干旱)影响长期保单定价,部分高风险地区承保能力下降。 - **长期(5-10年)**:气候移民和基础设施损毁导致系统性风险累积,传统精算模型失效。 2. **转型风险** - **短期(1-3年)**:碳密集型行业(如化石燃料)投保需求下降,责任险面临环保诉讼风险。 - **中期(3-5年)**:监管趋严(如碳税、绿色金融政策)倒逼产品结构调整,资本配置压力增大。 - **长期(5-10年)**:低碳技术普及导致传统业务萎缩,需重构风险评估逻辑。 3. **声誉与合规风险** - **短期(1-3年)**:客户对“绿色washing”敏感,ESG评级影响融资成本。 - **中期(3-5年)**:强制披露气候相关财务信息(如TCFD),合规成本上升。 --- #### **二、机遇** 1. **新产品开发** - **短期(1-3年)**:推出 parametric insurance(参数化保险)应对极端天气,覆盖快速理赔场景。 - **中期(3-5年)**:定制可再生能源项目保险(如风电、光伏设备险)。 - **长期(5-10年)**:气候适应型保险(如生态修复保险、碳捕获技术险)。 2. **数据与技术革新** - **短期(1-3年)**:利用AI和卫星数据优化灾害预测与动态定价。 - **中期(3-5年)**:区块链提升气候风险共担机制(如P2P保险)。 3. **政策与市场协同** - **短期(1-3年)**:参与政府气候韧性项目(如洪水防御基金),获取补贴。 - **长期(5-10年)**:成为绿色债券和碳交易市场的风险中介。 --- ### **三、战略应对框架** | **时间维度** | **优先级措施** | **关键行动** | |--------------|----------------------------------------|-----------------------------------------------------------------------------| | **短期(1-3年)** | 1. 风险建模升级
2. 应急产品创新 | - 整合气候数据到精算模型
- 试点参数化保险产品
- 剥离高碳资产承保 | | **中期(3-5年)** | 1. 业务结构转型
2. 合规能力建设 | - 设立绿色保险专项基金
- 开发ESG投资组合
- 培训气候风险评估团队 | | **长期(5-10年)**| 1. 生态协同
2. 系统性风险对冲 | - 与政府合作建立巨灾风险池
- 投资气候适应技术(如海绵城市保险解决方案) | **优先级排序**:短期聚焦风险对冲与监管适应,中期转向绿色产品线,长期构建气候韧性生态。 --- **注**:战略需动态调整,建议每年评估气候情景分析(如RCP 2.6 vs RCP 8.5)对业务的影响。, ### 旅游业应对气候变化的战略框架 (按风险/机遇优先级排序,★数量代表紧迫性) --- #### **一、系统性风险分析** **1. 物理风险** - **短期(1-3年)★★★**:极端天气事件(如飓风、野火)导致景区关闭、基础设施损坏。 - **中期(3-5年)★★☆**:海平面上升威胁沿海度假区(如马尔代夫、加勒比地区)。 - **长期(5-10年)★☆☆**:生态系统退化(珊瑚白化、冰川消失)降低目的地吸引力。 **2. 转型风险** - **短期★★☆**:碳税政策增加航空及酒店运营成本。 - **中期★★★**:消费者偏好转向低碳旅行,高排放业务(如邮轮)面临需求下降。 - **长期★★☆**:全球“净零”目标倒逼全产业链脱碳改革。 --- #### **二、核心机遇分析** **1. 需求转型** - **短期★★★**:低碳旅游产品(如本地游、生态民宿)需求激增。 - **中期★★☆**:气候适应性旅游(如极地旅游替代消失的冰川游)兴起。 - **长期★☆☆**:虚拟旅游(VR+碳中和)成为新增长点。 **2. 政策与投资** - **短期★★☆**:绿色补贴(如欧盟可持续旅游基金)支持企业转型。 - **中期★★★**:碳交易市场为低碳景区创造额外收益。 - **长期★★☆**:气候韧性基建(如防波堤、智能电网)提升目的地竞争力。 --- #### **三、战略应对框架** **短期(1-3年)** ★★★ - **优先级1**:建立气候风险监测系统,针对高频灾害(如洪水)制定应急方案。 - **优先级2**:推出低碳认证(如酒店能源改造、短途旅游套餐),抢占市场先机。 - **优先级3**:与航空公司合作开发碳抵消计划,缓解政策压力。 **中期(3-5年)** ★★☆ - **优先级1**:投资气候适应性项目(如人工珊瑚礁、高海拔滑雪场)。 - **优先级2**:供应链脱碳(切换可再生能源交通、零碳供应链)。 - **优先级3**:培训员工掌握可持续旅游服务技能(如生态导游)。 **长期(5-10年)** ★☆☆ - **优先级1**:参与目的地气候韧性规划(如马尔代夫“漂浮城市”)。 - **优先级2**:开发“气候友好型”旅游IP(如碳中和主题公园)。 - **优先级3**:布局虚拟旅游技术,减少实体资源依赖。 --- #### **四、关键指标(KPI)** - 短期:应急响应时间缩短30%,低碳产品收入占比达20%。 - 中期:供应链碳排放下降50%,10个目的地获气候韧性认证。 - 长期:虚拟旅游收入占比超15%,全产业链实现净零排放。 --- **注**:框架需结合区域特性调整(如海岛vs内陆),并定期评估气候模型更新影响。, ### 能源行业气候变化战略应对框架 (按风险/机遇优先级排序,★为关键程度) --- #### **一、系统性风险分析** **1. 政策与监管风险** - **短期(1-3年)**:碳税、排放标准趋严(★★★) - **中期(3-5年)**:化石燃料补贴取消、可再生能源配额制(★★★) - **长期(5-10年)**:全球碳边境税(如CBAM)扩大化(★★☆) **2. 物理风险** - **短期**:极端天气导致能源基础设施损坏(如电网、炼油厂)(★★☆) - **中期**:水资源短缺影响火电/核电运营(★☆☆) - **长期**:海平面上升威胁沿海能源设施(★★☆) **3. 市场与转型风险** - **短期**:可再生能源成本下降挤压传统能源利润(★★★) - **中期**:投资者撤资化石燃料资产(★★☆) - **长期**:能源需求结构颠覆(如电动汽车普及)(★★★) --- #### **二、战略机遇分析** **1. 清洁能源转型** - **短期**:分布式光伏、储能技术商业化(★★★) - **中期**:绿氢产业链突破(★★☆) - **长期**:碳捕集与封存(CCUS)规模化应用(★☆☆) **2. 能效与创新** - **短期**:智能电网与需求响应技术(★★☆) - **中期**:工业流程电气化(如绿电制钢)(★★★) - **长期**:核聚变等颠覆性能源技术(★☆☆) **3. 新商业模式** - **短期**:能源即服务(EaaS)订阅模式(★☆☆) - **中期**:碳信用交易与绿证金融化(★★☆) - **长期**:全球可再生能源电力贸易(★★★) --- #### **三、战略应对框架** **优先级排序**:政策响应 > 技术投资 > 资产重组 > 市场重塑 | **时间维度** | **核心措施** | **关键行动示例** | |--------------|---------------------------------------|-------------------------------------------| | **短期** | 合规与灵活性提升 | - 加速煤电资产剥离或改造
- 布局储能+可再生能源混合项目 | | **中期** | 技术突破与产业链重构 | - 投资绿氢试点项目
- 建立碳资产管理团队 | | **长期** | 系统性转型与生态构建 | - 参与国际能源标准制定
- 打造零碳工业园 | --- #### **四、监控指标** - **短期**:政策变动频率、可再生能源装机增速 - **中期**:CCUS成本下降曲线、绿氢产能占比 - **长期**:全球温升目标进展、颠覆性技术专利数 --- **注**:★☆表示优先级,需结合企业具体业务板块调整权重(如油气企业需更高权重关注转型风险)。协调者-工作者(Orchestrator-Workers)
在协调器-工作者工作流中,中央 LLM 动态分解任务,将其委托给工作者 LLM,并综合其结果。
此工作流程非常适合无法预测所需子任务的复杂任务。虽然它在拓扑结构上与并行化类似,但其与并行化的关键区别在于灵活性——子任务并非预先定义,而是由编排器根据具体输入确定。

示例:我要到访秘鲁,为我写一篇旅游规划书
首先明确一点,任务(用户输入)要先被 Orchestrator 动态分解,然后 Workers 再执行这些子任务,最后汇总结果
下面定义 Orchestrator 和 Workers 的 Prompt,添加到常量类中
public static final String ORCHESTRATOR_PROMPT = """ 分析此任务并分解为3-4种不同的处理方式: 任务:{task} 请按以下JSON格式返回响应: \\{ "analysis": "说明你对任务的理解以及哪些变化会很有价值。 重点关注每种方式如何服务于任务的不同方面。", "tasks": [ \\{ "type": "adventure", "description": "规划充满冒险元素的行程,包括徒步、露营等活动" \\}, \\{ "type": "luxury", "description": "设计高端奢华的行程,包含精品酒店和私人定制体验" \\} ] \\} """; public static final String WORKER_PROMPT = """ 根据以下要求生成内容: 任务:{original_task} 风格:{task_type} 指南:{task_description} """;定义 OrchestratorResponse 实体类
@Data @AllArgsConstructor @NoArgsConstructor public class OrchestratorResponse { private String analysis; private List tasks; @Data @AllArgsConstructor @NoArgsConstructor public static class Task { private String type; private String description; } }在接口中定义 startOrchestratorWorkerWorkflow 方法
List startOrchestratorWorkerWorkflow(String userInput);
在实现类中,首先使用协调者动态分解任务,返回一个 orchestratorResponse,然后工作者会执行多个子任务,最后返回一个列表
@Override public List startOrchestratorWorkerWorkflow(String userInput) { // 协调者动态分解任务 OrchestratorResponse orchestratorResponse = openAiChatClient.prompt() .user(u -> u.text(PromptConstant.ORCHESTRATOR_PROMPT) .param("task", userInput)) .call() .entity(OrchestratorResponse.class); LOGGER.info("\n" + "OrchestratorResponse: " + "Analysis---" + orchestratorResponse.getAnalysis() + "\n" + "Tasks---" + orchestratorResponse.getTasks()); // 工作者执行多个子任务 List stringList = orchestratorResponse.getTasks().stream().map( task -> openAiChatClient.prompt() .user(u -> u.text(PromptConstant.WORKER_PROMPT) .param("original_task", userInput) .param("task_type", task.getType()) .param("task_description", task.getDescription())) .call() .content() ).toList(); LOGGER.info("Worker Output: " + stringList); return stringList; }测试,可以看到,Orchestrator 将任务分解成了 4 个子任务(adventure、luxury、cultural、family)
2025-05-13 18:03:32 [http-nio-8095-exec-1] INFO c.o.m.s.impl.WorkflowServiceImpl - OrchestratorResponse: Analysis---理解任务为根据用户需求定制秘鲁旅游规划书,重点在于满足不同旅行偏好。 有价值的变体包括行程强度、预算水平、文化深度和活动类型,以覆盖冒险、奢华、文化和家庭等不同需求。 Tasks---[ OrchestratorResponse.Task(type=adventure, description=规划充满冒险元素的行程,包括徒步、露营等活动), OrchestratorResponse.Task(type=luxury, description=设计高端奢华的行程,包含精品酒店和私人定制体验), OrchestratorResponse.Task(type=cultural, description=聚焦秘鲁历史与文化的深度探索,涵盖博物馆、遗址和当地社区互动), OrchestratorResponse.Task(type=family, description=设计适合家庭出游的行程,包含亲子友好活动和舒适住宿) ]
Worker Output: [# **秘鲁冒险之旅规划书** **目的地:秘鲁** **旅行风格:探险 & 户外** **时长:10天** ## **行程概览** 秘鲁是冒险者的天堂,拥有安第斯山脉、亚马逊雨林和古老的印加遗迹。本行程专注于徒步、露营、户外探险和文化体验,适合热爱挑战的旅行者。 --- ## **📅 详细行程** ### **Day 1-2: 利马(Lima)→ 库斯科(Cuzco)** - **抵达利马**,短暂休整,适应时差。 - **飞往库斯科**(海拔3,400米),适应高原环境。 - **库斯科探险准备**: - 租借徒步装备(背包、登山杖、睡袋等)。 - 短途徒步至**Sacsayhuamán**(印加军事要塞),欣赏库斯科全景。 ### **Day 3-5: 圣谷(Sacred Valley)→ 奥扬泰坦博(Ollantaytambo)** - **圣谷探险**: - 骑行或徒步探索**Moray**(印加农业实验梯田)和**Maras盐田**。 - **白水漂流**(Urubamba河,Class III-IV级急流)。 - **奥扬泰坦博过夜**,体验传统印加小镇风情。 ### **Day 6-9: 印加古道徒步(Inca Trail)→ 马丘比丘(Machu Picchu)** - **4天3夜印加古道徒步**(经典路线): - **Day 1**: 从**Km 82**出发,徒步至**Wayllabamba**营地(12km)。 - **Day 2**: 挑战**Dead Woman’s Pass**(海拔4,215米),露营于**Pacaymayo**。 - **Day 3**: 探索**Runkurakay**和**Sayacmarca**遗址,夜宿**Wiñay Wayna**营地。 - **Day 4**: 黎明抵达**太阳门(Inti Punku)**,俯瞰**马丘比丘**,全天深度探索。 - **可选**:下山后泡**Aguas Calientes**温泉放松。 ### **Day 10: 返回库斯科 → 利马 → 返程** - **乘火车返回库斯科**,短暂休整。 - **飞回利马**,结束冒险之旅。 --- ## **🏕️ 住宿推荐** - **库斯科**:Wild Rover Hostel(背包客氛围) - **圣谷**:Pisac Inn(生态旅馆) - **印加古道**:露营(需向导安排) - **马丘比丘**:Belmond Sanctuary Lodge(唯一山巅酒店,可选奢侈体验) --- ## **⚠️ 冒险贴士** ✅ **高原适应**:提前2天到库斯科适应海拔,多喝水,避免剧烈运动。 ✅ **装备清单**:登山鞋、防水外套、头灯、防晒霜、水袋。 ✅ **向导要求**:印加古道必须跟持证向导团队进入,提前6个月预订许可。 ✅ **安全提示**:避免独自徒步偏远路线,随身携带急救包。 --- ## **🌿 可选扩展冒险** - **彩虹山(Vinicunca)**:1日徒步(海拔5,200米)。 - **亚马逊雨林(Puerto Maldonado)**:3天丛林探险,观察野生动物。 **📌 结语** 秘鲁的冒险之旅将挑战你的体能,同时带来无与伦比的自然与文化震撼。准备好征服高山、穿越雨林,揭开印加帝国的神秘面纱吧! **🚀 出发吧,探险者!**, # **秘鲁奢华之旅规划书** **目的地:秘鲁** **旅行风格:高端定制 & 奢华体验** **时长:10天** ## **✨ 行程亮点** - **私人向导全程陪同**,VIP通道免排队 - **顶级精品酒店 & 豪华列车** - **独家文化体验 & 美食盛宴** - **直升机游览 & 私人游艇** --- ## **📅 尊享行程** ### **Day 1-2: 利马(Lima)—— 美食之都的奢华初体验** - **抵达利马**,专车接送至**Belmond Miraflores Park**(海景套房)。 - **私人城市导览**: - 参观**Larco Museum**(秘鲁黄金与文物珍藏)。 - **VIP品酒会**,品尝秘鲁国酒Pisco Sour。 - **米其林星级晚餐**: - **Central**(世界50佳餐厅)或**Maido**(日秘融合料理)。 ### **Day 3-4: 库斯科(Cuzco)—— 印加帝国的贵族之旅** - **私人飞机前往库斯科**,入住**Palacio del Inka, a Luxury Collection Hotel**(16世纪宫殿改建)。 - **圣谷(Sacred Valley)尊享体验**: - **私人导游**陪同游览**Pisac市场**和**Ollantaytambo遗址**。 - **Belmond Hiram Bingham豪华列车**前往马丘比丘(含香槟午餐)。 - **安第斯山野餐**:厨师现场烹饪,搭配本地葡萄酒。 ### **Day 5-6: 马丘比丘(Machu Picchu)—— 云端奇迹的私密探索** - **入住Belmond Sanctuary Lodge**(马丘比丘山巅唯一酒店)。 - **VIP日出游览**:清晨私人开放,避开人群。 - **直升机返程**(俯瞰安第斯山脉)。 ### **Day 7-8: 的的喀喀湖(Lake Titicaca)—— 水上漂浮宫殿** - **私人飞机前往普诺(Puno)**,入住**Titilaka Lodge**(全包式湖畔别墅)。 - **私人游艇游览**乌鲁斯浮岛(Uros Islands)。 - **星空晚宴**:湖边私人厨师定制菜单。 ### **Day 9-10: 利马—— 完美收官** - **返回利马**,入住**Country Club Lima Hotel**(高尔夫度假风)。 - **最后狂欢**: - **私人购物导览**(秘鲁羊驼毛精品店)。 - **海滨直升机巡游**(俯瞰太平洋海岸线)。 - **专车送机**,结束尊贵之旅。 --- ## **🏨 顶奢住宿推荐** | 城市 | 酒店 | 特色 | |---------------|-----------------------------------|-------------------------------| | **利马** | Belmond Miraflores Park | 无边泳池+太平洋全景 | | **库斯科** | Palacio del Inka | 殖民时期宫殿改建 | | **马丘比丘** | Belmond Sanctuary Lodge | 遗址旁唯一五星级 | | **的的喀喀湖**| Titilaka Lodge | 全包式私人湖畔别墅 | --- ## **🎁 独家增值服务** - **24小时管家** & 英语/中文私人导游 - **行李无忧**:全程专人运送 - **摄影跟拍**:专业摄影师记录旅程 - **健康护航**:随行高原反应医护团队 --- ## **🍾 不可错过的奢华体验** 1. **马丘比丘私人日出仪式**(萨满祈福) 2. **库斯科私人庄园晚宴**(印加后裔家族接待) 3. **亚马逊河私人游艇巡游**(需延长行程) **💎 设计说明** 本行程通过航空接驳最大化节约时间,每个节点都注入秘鲁最顶级的资源。从世界级餐厅到只有2间客房的野奢营地,彻底重新定义奢华旅行。 **🛎️ 定制提醒** 所有服务均可按需调整,包括延长亚马逊行程、增加珠宝采购等个性化需求。我们的旅行设计师将为您1v1优化方案。 **🌺 您值得拥有最完美的秘鲁!**, # **秘鲁文化深度之旅规划书** **目的地:秘鲁** **旅行风格:历史文化沉浸式体验** **时长:12天** --- ## **🌄 行程核心理念** 本行程专为文化爱好者设计,通过博物馆、考古遗址、传统工艺作坊和原住民社区互动,深入探索秘鲁5000年文明史。重点呈现: ✔ **前哥伦布时期文明**(莫切、纳斯卡、印加) ✔ **西班牙殖民艺术与建筑** ✔ **活态安第斯传统文化** --- ## **📜 文化行程路线** ### **Day 1-3: 利马——殖民瑰宝与秘鲁文明之源** #### **文化焦点**:混血文化(Mestizo)的形成 - **国家博物馆(MALI)**:秘鲁艺术史通览 - **圣弗朗西斯科修道院**:地下墓穴与殖民时期宗教艺术 - **帕查卡马克遗址**:前印加神圣之城 - **巴兰科区(Barranco)**:街头艺术与文学咖啡馆 - **特别体验**: - **秘鲁国菜烹饪课**(学习Ceviche和Pisco Sour制作) - **私人收藏家宅邸参观**(预览未公开的莫切文物) ### **Day 4-6: 特鲁希略与昌昌古城——莫切文明深度行** #### **文化焦点**:沙漠中的古老帝国 - **太阳神庙与月亮神庙**:莫切文明政治宗教中心 - **昌昌古城**:世界最大土坯城(UNESCO) - **西潘王墓博物馆**:堪比图坦卡蒙的黄金宝藏 - **特别体验**: - **传统芦苇船出海**(与当代渔民交流古老航海技术) - **陶艺大师工作坊**(学习莫切浮雕陶器制作) ### **Day 7-9: 库斯科与圣谷——活着的印加帝国** #### **文化焦点**:印加智慧与当代克丘亚文化 - **科里坎查(太阳神殿)**:印加建筑与殖民教堂的层叠 - **圣谷(Pisac+Chinchero)**:梯田系统与纺织合作社 - **奥扬泰坦博**:仍在使用的印加城市规划范本 - **特别体验**: - **克丘亚家族共进午餐**(参与传统Pachamanca地灶烹饪) - **安第斯星象解读**(原住民天文学家讲解) ### **Day 10-12: 普诺与的的喀喀湖——浮岛上的乌罗斯人** #### **文化焦点**:高原湖泊文明 - **乌鲁斯浮岛**:用芦苇再造生活的智慧 - **塔基列岛**:世界非遗纺织社区 - **西卢斯塔尼墓塔**:前印加生死观实证 - **特别体验**: - **夜宿浮岛民宿**(参与芦苇船制作) - **Capachica半岛仪式**(与萨满共同祈福) --- ## **🏛️ 核心文化站点解析** | **遗址/博物馆** | **文明归属** | **不可错过亮点** | |-----------------------|--------------|-----------------------------------| | 西潘王墓博物馆 | 莫切文明 | 孔雀羽头饰/黄金葬礼面具 | | 奥扬泰坦bo水利系统 | 印加文明 | 至今运作的灌溉网络 | | 塔基列纺织合作社 | 当代克丘亚 | 用编织记录历史的密码文字 | --- ## **🎭 文化互动日历** ▸ **Day3傍晚**:利马传统Marinera舞蹈私教课 ▸ **Day6全天**:参与北海岸圣佩德罗仙人掌仪式(需提前精神准备) ▸ **Day9夜间**:库斯科Q'eswachaka节(如逢6月,见证草绳桥重建仪式) --- ## **🛌 文化住宿推荐** - **利马**:Casa Republica(19世纪共和时期豪宅改建) - **特鲁希略**:Hotel Libertador(殖民时期总督府旧址) - **库斯科**:El Mercado Tunqui(前印加市场改造的设计酒店) --- ## **📚 行前文化准备建议** 1. **阅读清单**: - 《印加帝国的末日》(Kim MacQuarrie) - 《莫切文明的暴力与仪式》(Steve Bourget) 2. **影视推荐**:纪录片《秘鲁:隐藏的王国》(BBC) 3. **语言基础**:学习10个克丘亚语问候语 --- ## **💡 专业贴士** - **摄影伦理**:拍摄原住民前务必征得同意(建议携带宝丽来即时赠送) - **纪念品采购**:库斯科Centro Qosqo认证的公平贸易商店 - **学术支持**:可预约随行考古学家(需提前2月预定) **🌾 这不仅仅是一次旅行,而是一场文明对话。** 从沙漠金字塔到漂浮岛屿,让我们沿着时间的纤维,触摸秘鲁文明的温度。, # **秘鲁家庭欢乐之旅规划书** **目的地:秘鲁** **旅行风格:亲子友好 & 家庭休闲** **时长:10天** --- ## **👨👩👧👦 行程特色** ✔ **轻松节奏**:每天1个主要景点+充足休息时间 ✔ **趣味学习**:互动式文化体验激发孩子好奇心 ✔ **安全舒适**:家庭房住宿+专业儿童餐食 ✔ **交通优化**:包车服务+短途内陆航班 --- ## **📅 亲子行程安排** ### **Day 1-2: 利马(Lima)—— 海滨初体验** - **住宿**:**Sheraton Lima Hotel & Convention Center**(家庭连通房,儿童泳池) - **活动**: - **魔法水公园(Parque de la Reserva)**:世界最大喷泉综合体夜间灯光秀 - **拉尔科博物馆(Larco Museum)**:儿童专用讲解器+巧克力制作工坊 - **米拉弗洛雷斯海滨步道**:骑四轮协力车+品尝儿童友好版酸橘汁腌鱼 ### **Day 3-4: 帕拉卡斯(Paracas)—— 海洋奇遇** - **交通**:私人包车(3小时,配备儿童安全座椅) - **住宿**:**DoubleTree Resort by Hilton Paracas**(私人沙滩+儿童俱乐部) - **活动**: - **鸟岛游船(Ballestas Islands)**:看海狮/企鹅/海鸟(提供儿童望远镜) - **沙漠越野车**:小型沙丘滑沙体验(5岁以上可参与) - **生态手工课**:用贝壳制作纪念品 ### **Day 5-7: 库斯科(Cuzco)—— 印加探险** - **交通**:1小时航班(选择上午班次减少疲劳) - **住宿**:**Novotel Cusco**(高原供氧系统+家庭游戏室) - **活动**: - **圣谷小火车**:乘坐全景列车前往皮萨克(Pisac)集市 - **羊驼农场**:喂食+学习传统纺织(提供儿童尺寸纺织工具) - **巧克力博物馆**:从可可豆到成品的互动体验(可制作专属巧克力) - **儿童版印加古道**:2小时轻松徒步到Moray圆形梯田 ### **Day 8-9: 马丘比丘(Machu Picchu)—— 奇幻之旅** - **交通**:Vistadome景观列车(车厢魔术表演+儿童餐) - **住宿**:**Tierra Viva Machu Picchu**(家庭套房+热水浴缸) - **活动**: - **马丘比丘寻宝游戏**:定制儿童探险手册完成打卡任务 - **温泉镇手工坊**:用天然粘土制作迷你印加文物 - **夜间故事会**:酒店安排克丘亚语童话讲述 ### **Day 10: 返回利马 —— 回忆封存** - **活动**: - **家庭旅行相册DIY**:市区专业工作室1小时快制 - **拉尔科博物馆儿童证书**:完成所有文化挑战可获得 --- ## **🍽️ 亲子餐饮推荐** | **城市** | **餐厅** | **特色** | |------------|---------------------------|-------------------------------| | 利马 | Panchita | 儿童餐含可食用乐高积木 | | 库斯科 | Papacho's | 印加主题汉堡+自制柠檬水站 | | 马丘比丘 | Tree House | 树屋座位+动物造型甜点 | --- ## **🎒 行前准备清单** - **健康**: - 儿科医生开具高原反应预防建议(库斯科海拔3400米) - 准备儿童常用药+便携式血氧仪 - **装备**: - 可折叠婴儿车(鹅卵石路面适用) - 亲子装(当地节日拍照更出片) - **教育**: - 下载《印加文明儿童绘本》电子版 - 准备空白旅行日记本收集印章 --- ## **🌟 特别关怀服务** - **机场快速通道**:利马/库斯科机场VIP通关(避免排队) - **灵活调整权**:每天可免费取消1项活动(根据孩子状态) - **应急支持**:24小时中文保姆服务(需提前48小时预约) --- ## **📌 家长须知** 1. **最佳季节**:5-9月(旱季,适合户外活动) 2. **年龄建议**:5岁以上儿童体验更完整 3. **文化礼仪**:提前教孩子用克丘亚语说"谢谢"(Sulpayki) **🦙 让羊驼见证家庭的成长之旅!** 从海岸到高山,从古代文明到自然奇观,这将是孩子们终身难忘的南美课堂。]
评估者-优化器(Evaluator-Optimizer)
在评估者-优化器工作流中,一个 LLM 调用生成响应,而另一个调用在循环中提供评估和反馈
该模式对于翻译、代码生成等场景十分适用

示例: 通过评估优化实现一个 Java 队列代码生成
下面定义 Generator 和 的 Evaluator 的 Prompt,添加到常量类中
public static final String GENERATOR_PROMPT = """ 你的目标是根据输入完成任务。如果存在之前生成的反馈, 你应该反思这些反馈以改进你的解决方案。 关键要求:响应必须是单行有效的JSON,除明确使用\\n转义外,不得包含换行符。 以下是必须严格遵守的格式(包括所有引号和花括号): {"thoughts":"此处填写简要说明","code":"public class Example {\\n // 代码写在这里\\n}"} 响应字段的规则: 1. 所有换行必须使用\\n 2. 所有引号必须使用\\" 3. 所有反斜杠必须双写:\\ 4. 不允许实际换行或格式化 - 所有内容必须在一行 5. 不允许制表符或特殊字符 6. Java代码必须完整且正确转义 正确格式的响应示例: {"thoughts":"实现计数器","code":"public class Counter {\\n private int count;\\n public Counter() {\\n count = 0;\\n }\\n public void increment() {\\n count++;\\n }\\n}"} 必须严格遵循此格式 - 你的响应必须是单行有效的JSON。 """; public static final String EVALUATOR_PROMPT = """ 评估这段代码实现的正确性、时间复杂度和最佳实践。 确保代码有完整的javadoc文档。 用单行JSON格式精确响应: {"evaluation":"PASS,NEEDS_IMPROVEMENT,FAIL", "feedback":"你的反馈意见"} evaluation字段必须是以下之一: "PASS", "NEEDS_IMPROVEMENT", "FAIL" 仅当所有标准都满足且无需改进时才使用"PASS"。 """;在接口中定义 startEvaluatorOptimizerWorkflow 方法
String startEvaluatorOptimizerWorkflow(String userInput);
在实现类中,定义 loop 方法,在该方法通过 generate 生成代码,evaluate 评估生成的代码,若评估不通过,则进行优化(再次执行loop)
@Override public String startEvaluatorOptimizerWorkflow(String userInput) { List memory = new ArrayList(); List chainOfThought = new ArrayList(); return loop(userInput, "", memory, chainOfThought).toString(); } public RefinedResponse loop(String userInput, String context, List memory, List chainOfThought) { // Generator生成代码 GenerationResponse generationResponse = generate(userInput, context); chainOfThought.add(generationResponse); memory.add(generationResponse.getCode()); // Evaluator评估代码 EvaluationResponse evaluationResponse = evaluate(userInput, generationResponse.getCode()); // 若评估通过,则返回RefinedResponse if (Evaluation.PASS.equals(evaluationResponse.getEvaluation())){ return new RefinedResponse(generationResponse.getCode(), chainOfThought); } // 若评估不通过,则进行优化(再次执行loop) StringBuilder newContext = new StringBuilder(); newContext.append("之前的尝试:"); for (String m : memory) { newContext.append("\n- ").append(m); } newContext.append("\nFeedback: ").append(evaluationResponse.getFeedback()); return loop(userInput, newContext.toString(), memory, chainOfThought); } public GenerationResponse generate(String userInput, String context) { GenerationResponse generationResponse = openAiChatClient.prompt() .user(u -> u.text("{prompt}\n{context}\nTask: {task}") .param("prompt", PromptConstant.GENERATOR_PROMPT) .param("context", context) .param("task", userInput)) .call() .entity(GenerationResponse.class); System.out.println(String.format("\n=== 输出 ===\n思考: %s\n\n代码:\n %s\n", generationResponse.getThoughts(), generationResponse.getCode())); return generationResponse; } public EvaluationResponse evaluate(String userInput, String code) { EvaluationResponse evaluationResponse = openAiChatClient.prompt() .user(u -> u.text("{prompt}\nOriginal task: {task}\nContent to evaluate: {content}") .param("prompt", PromptConstant.EVALUATOR_PROMPT) .param("task", userInput) .param("content",code)) .call() .entity(EvaluationResponse.class); System.out.println(String.format("\n=== 评价输出 ===\n评价: %s\n\n反馈: %s\n", evaluationResponse.getEvaluation(), evaluationResponse.getFeedback())); return evaluationResponse; }测试
@GetMapping("/agent/generator_evaluator") public String generatorEvaluator() { String userInput = """ 实现一个具有以下功能的Java队列: 1. enqueue(x) - 将元素x添加到队列尾部 2. dequeue() - 移除并返回队列头部元素 3. getMin() - 获取队列中的最小值 所有操作的时间复杂度应为O(1)。 所有内部字段必须声明为private,使用时需加"this."前缀。 """; return workflowService.startEvaluatorOptimizerWorkflow(userInput); }=== 输出 === 思考: 使用双端队列维护最小值实现O(1)操作 代码: public class MinQueue { private java.util.Queue mainQueue; private java.util.Deque minDeque; public MinQueue() { this.mainQueue = new java.util.LinkedList(); this.minDeque = new java.util.LinkedList(); } public void enqueue(int x) { this.mainQueue.add(x); while (!this.minDeque.isEmpty() && this.minDeque.getLast() > x) { this.minDeque.removeLast(); } this.minDeque.addLast(x); } public int dequeue() { if (this.mainQueue.isEmpty()) throw new RuntimeException("Queue is empty"); int val = this.mainQueue.remove(); if (val == this.minDeque.getFirst()) { this.minDeque.removeFirst(); } return val; } public int getMin() { if (this.minDeque.isEmpty()) throw new RuntimeException("Queue is empty"); return this.minDeque.getFirst(); } } === 评价输出 === 评价: NEEDS_IMPROVEMENT 反馈: 实现正确且满足时间复杂度要求,但缺少Javadoc文档和更具体的异常处理。建议添加完整的类和方法文档,并使用更具体的异常类型如NoSuchElementException。 === 输出 === 思考: 改进后的实现添加了Javadoc文档和使用NoSuchElementException 代码: public class MinQueue { private java.util.Queue mainQueue; private java.util.Deque minDeque; /** * 构造一个新的MinQueue */ public MinQueue() { this.mainQueue = new java.util.LinkedList(); this.minDeque = new java.util.LinkedList(); } /** * 将元素添加到队列尾部 * @param x 要添加的元素 */ public void enqueue(int x) { this.mainQueue.add(x); while (!this.minDeque.isEmpty() && this.minDeque.getLast() > x) { this.minDeque.removeLast(); } this.minDeque.addLast(x); } /** * 移除并返回队列头部元素 * @return 队列头部元素 * @throws java.util.NoSuchElementException 如果队列为空 */ public int dequeue() { if (this.mainQueue.isEmpty()) throw new java.util.NoSuchElementException("Queue is empty"); int val = this.mainQueue.remove(); if (val == this.minDeque.getFirst()) { this.minDeque.removeFirst(); } return val; } /** * 获取队列中的最小值 * @return 队列中的最小值 * @throws java.util.NoSuchElementException 如果队列为空 */ public int getMin() { if (this.minDeque.isEmpty()) throw new java.util.NoSuchElementException("Queue is empty"); return this.minDeque.getFirst(); } } === 评价输出 === 评价: PASS 反馈: 实现完全符合要求,包括正确的时间复杂度、私有字段访问、完善的Javadoc文档和适当的异常处理。Autonomous Agent(Agent)
TODO







