
webrtc pacer模块(一) 平滑处理的实现

Pacer起到平滑码率的作用,使发送到网络上的码率稳定。如下的这张创建Pacer的流程图,其中PacerSender就是Pacer,其中PacerSender就是Pacer。这篇文章介绍它的核心子类PacingController及Periodic模式下平滑处理的基本流程。平滑处理流程中还有与带宽探测所关联的流程,在本篇文章中并不涉及。

从上图中可以看到,在创建Call对象时,会创建一个RtpTransportControllerSend,它是Call对象中发送数据的大总管,而PacerSender也是属于它管理的对象。
一个Call对象中一个RtpTransportControllerSend,一个RtpTransportControllerSend中一个PacerSender,所以Pacer是作用于Call中所有的stream,这里并不是只处理音视频包,还有fec包,重传包,padding包,Call对象中也发送出去的数据都会经过Pacer。
这篇文章是介绍平滑实现的基本原理和Pacer中的Periodic模式的处理流程。Pacer的流程中还有与带宽探测所关联的流程,在本篇文章中并不涉及。
码率平滑的原理
在视频编码中,虽然编码器会将输出码流的码率控制在所设置的码率范围内。但是在编码器产生关键帧或在画面变化比较大时,码率可能超过设置的码率值。在有fec或重传包时,也可能造成实际发送的码率值超过目标值。这种突发的大码率的数据,可能就会造成网络链路拥塞。
所以引入的pacer就是平滑发送的码率值,在一段时间内,保证发送码率接近设置目标码率值。而避免突发的高码率造成网络链路拥塞。
平滑的基本原理就是**缓存队列+周期发送,将要发送的数据先缓存,在周期性的发送出去,起到平均码率的目的。那么这种周期有两种模式:**
- **kPeriodic**,周期模式,也是默认模式,以固定间隔时间发送数据。
- kDynamic,动态模式,根据数据的缓存时长及数据量来计算下一次发送数据的时间点。
组成
pacer的流程都实现在PacingController,包括两个核心类:RoundBoinPacketQueue,IntervalBudget。
- RoundBobinPacketQueue 缓存队列,对每条流都会缓存,以ssrc做为流的唯一标识,包括:重传包,fec,padding包。
- IntervalBudget 根据设置的目标码率值及时间间隔计算可发送的数据量。
PacingController类
所属文件为\modules\pacing\pacing_controller.h,如下类图:

两个核心的成员变量:
- RoundRobinPakcetQueue packet_queue_ packet的缓存队列。
- IntervalBudget media_buget_可发送数据量计算。
两个核心函数:
- NextSendTime,获取每次执行的时间(5毫秒,在kPeriodic模式下)。
- ProcessPackets,周期处理包的发送,确定要发送的数据量,从缓存队列中取包。
平滑逻辑的处理流程
整个pacer运行的机制就是靠PacingController的NextSendTime和ProcessPackets两个方法,它们被单独的放在一个ModuleThread线程中执行,周期性的被执行,两个方法调用的堆栈如下:
**NextSendTime**
peerconnection_client.exe!webrtc::PacingController::NextSendTime() 行 348 C++
peerconnection_client.exe!webrtc::PacedSender::TimeUntilNextProcess() 行 171 C++
peerconnection_client.exe!webrtc::PacedSender::ModuleProxy::TimeUntilNextProcess() 行 150 C++
peerconnection_client.exe!webrtc::`anonymous namespace’::GetNextCallbackTime(webrtc::Module * module, __int64 time_now) 行 30 C++
peerconnection_client.exe!webrtc::ProcessThreadImpl::Process() 行 231 C++
peerconnection_client.exe!webrtc::ProcessThreadImpl::Run(void * obj) 行 198 C++
peerconnection_client.exe!rtc::PlatformThread::Run() 行 130 C++
peerconnection_client.exe!rtc::PlatformThread::StartThread(void * param) 行 62 C++
**ProcessPackets**
peerconnection_client.exe!webrtc::PacingController::ProcessPackets() 行 408 C++
peerconnection_client.exe!webrtc::PacedSender::Process() 行 183 C++
peerconnection_client.exe!webrtc::PacedSender::ModuleProxy::Process() 行 152 C++
peerconnection_client.exe!webrtc::ProcessThreadImpl::Process() 行 226 C++
peerconnection_client.exe!webrtc::ProcessThreadImpl::Run(void * obj) 行 198 C++
peerconnection_client.exe!rtc::PlatformThread::Run() 行 130 C++
peerconnection_client.exe!rtc::PlatformThread::StartThread(void * param) 行 62 C++
核心骨架就是下面三个步骤:
- 设置目标码率,通过SetPacingRates(...)方法。
- 计算每个时间片可以发送的数据,在UpdateBudgetWithElapsedTime(TimeDelta delta)方法中。
- 用已发送的数据量来计算还剩多少数据量可以发送,在UpdateBudgetWithSentData(DataSize size)方法中。
详细流程:
(1). 如果媒体数据包处理模式是 kDynamic,则检查期望的发送时间和 前一次数据包处理时间 的对比,当前者大于后者时,则根据两者的差值更新预计仍在传输中的数据量,以及 前一次数据包处理时间;(Periodic模式是5ms执行一次)
(2). 从媒体数据包优先级队列中取一个数据包出来;
(3). 第 (2) 步中取出的数据包为空,但已经发送的媒体数据的量还没有达到码率探测器 webrtc::BitrateProber 建议发送的最小探测数据量,则创建一些填充数据包放入媒体数据包优先级队列,并继续下一轮处理;
(4). 发送取出的媒体数据包;
(5). 获取 FEC 数据包,并放入媒体数据包优先级队列;
(6). 根据发送的数据包的数据量,更新预计仍在传输中的数据量等信息;
(7). 如果是在码率探测期间,且发送的数据量超出码率探测器 webrtc::BitrateProber 建议发送的最小探测数据量,则结束发送过程;
(8). 如果媒体数据包处理模式是 kDynamic,则更新目标发送时间。
RoundBobinPacketQueue
RoundBobinPacketQueue是一个缓存队列, 用于缓存数据包(音视频包,fec,padding,重传包),它有两个特征:
- 根据优先级存储包(每种类型包都有优先级)。
- 记录缓存时长(记录每个包的入队时间,用于计算缓存的总时长,避免引入过多的延迟)。
类图

上图种的Stream类代表了一路流,QueuePacket类代表了数据包。
RoundBobinPacketQueue三个核心的数据结构:
- std::map streams_
key为ssrc。
- std::multimap **stream_priorities_**
**Stream**的优先级信息表,以**priority**和**DataSize**为比较的key,value是ssrc。通过优先级找Stream,方便优先级变化的实现。越靠前,优先级越高。
Stream类中的std::multimap::iterator priority_it;它指向 RoundBobinPacketQueue中的stream_priorities_中的某项,可以快速定位到自己的优先级。
- std::multiset enqueue_times_
The enqueue time of every packet currently in the queue. Used to figure out the age of the oldest packet in the queue.
记录每一个包的入队时间
QueuedPacket对象中的std::multiset::iterator enqueue_time_it_;指向enqueue_times_中的项,可以快速定位到自己的入队时间。
Stream,QueuePacket,RoundBobinPacketQueue关系图
如下是Stream对象,QueuePacket对象与RoundBobinPacketQueue对象的关系图。
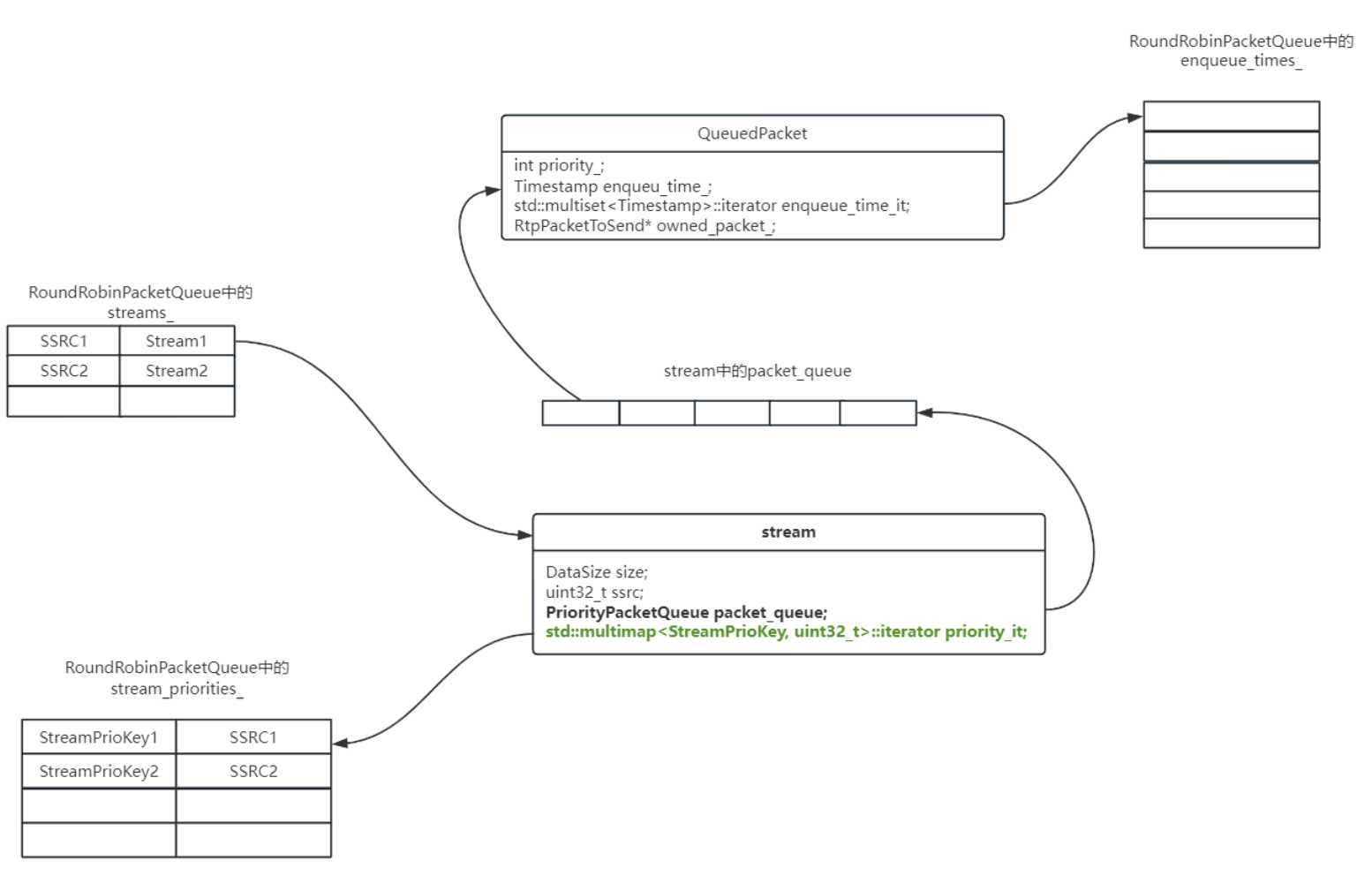
上图是以Stream为中心,描绘Stream,QueuePacket,RoundBobinPacketQueue的关系。
- 每个Stream都被记录在RoundRobinPacketQueue的streams_中,以ssrc为key。
- 每个Stream的优先级都被记录在RoundRobinPacketQueue的stream_priorites_中,以优先级为key,ssrc为value。
- 数据包都被封装成QueuePacket缓存在Stream对象的packet_queue中,它也是一个优先级队列,所以每个数据包都是有优先级的。
- RoundRobinPacketQueue的enqueue_times_记录着每个rtp packet的入队时间。
- stream中std::multimap::iterator priority_it迭代器指向该stream在stream_priorites_中的位置,便于快速检索。
- QueuedPacket中的std::multiset::iterator enqueue_time_it迭代器指向该packet在enqueue_times_中的位置,便于快速检索。
缓存队列中记录的信息有:
- 记录总的缓存包个数。
- 记录总的数据量。
- 记录包的优先级。
- 记录包的入队时间(计算包的缓存总时长,平均缓存时间,最大缓存时间)。
插入队列(push方法)的逻辑
- 从streams_中找pakcet所属的Ssrc的stream,如果没有,则在streams_中插入一项。
- 查看stream的priority_it是否等于stream_priorities_的end():如果相等,则在stream_priorities插入新的项; 否则,如果新包的优先级高,则更新其ssrc对应队列的优先级。
- 更新队列总时长。
- 入队时间减去暂停时间(一般不会有暂停)。
- 队列总包数+1。
- 队列总字节大小+包的负载大小+Padding大小(Packet的大小)。
- 插入到steam对象的packet_queue中。
push流程的注意点:
- stream的size指的是stream发送的size,在Pop中,会加上弹出的PacketSize。
- 一条stream的packet的priority值都是一样的。
- 在入队一个stream的新的packet时,并不确定优先级,触发优先级队列中没有记录或packet的优先级发生变化。
取数据(Pop方法)的逻辑
- 获得优先级最高的stream。
- 从stream的packet_queue中取出第一个Packet。
- 将stream在stream_priorites_中的项删除掉。
- 计算Packet入队后到现在的时间(不包括暂停时间)。
- 将这段时间从队列的总时间中减去。
- 从equeue_times_中将Packet的项删除。
- 总包数减一。
- 总字节数减去包的字节数。
- 将包从stream中的queue中弹出。
- 如果stream中的队列为空,则令stream的priority_it指向stream_priorities的end()。
- 否则,从stream队列头部取Packet,将该Packet的priority插入到stream_priorities_中。
缓存时间的计算
计算缓存时间的目的是控制延迟,包括如下几个方法:
- 获取缓存时间最长的包
Timestamp RoundRobinPacketQueue::OldestEnqueueTime() const { if (single_packet_queue_.has_value()) { return single_packet_queue_->EnqueueTime(); } if (Empty()) return Timestamp::MinusInfinity(); RTC_CHECK(!enqueue_times_.empty()); return *enqueue_times_.begin(); }这个方法是用于统计,最终会被call对象的GetStats()方法调用。
- 计算总延时,UpdateQueueTime每次被调用,总时长都会被计算,累加。
void RoundRobinPacketQueue::UpdateQueueTime(Timestamp now) { RTC_CHECK_GE(now, time_last_updated_); if (now == time_last_updated_) return; TimeDelta delta = now - time_last_updated_; if (paused_) { pause_time_sum_ += delta; } else { //有n个包,每调一次UpdateQueueTime就有一个delta值,总数为size of packet乘以delta queue_time_sum_ += TimeDelta::Micros(delta.us() * size_packets_); } time_last_updated_ = now; }- 计算平均缓存时间
平均缓存时间=queue的总时间数/包数,用于判断延时(缓存时间)是否过大。
TimeDelta RoundRobinPacketQueue::AverageQueueTime() const { if (Empty()) return TimeDelta::Zero(); return queue_time_sum_ / size_packets_; }控制延时
在PacingController::ProcessPackets()方法中,会计算包的缓存时间,如下if分支
if (drain_large_queues_) { //限制延时 TimeDelta avg_time_left = std::max(TimeDelta::Millis(1), queue_time_limit - packet_queue_.AverageQueueTime()); DataRate min_rate_needed = queue_size_data / avg_time_left; if (min_rate_needed > target_rate) { target_rate = min_rate_needed; RTC_LOG(LS_VERBOSE) single_packet_queue_.emplace( QueuedPacket(priority, enqueue_time, enqueue_order, enqueue_times_.end(), std::move(packet))); UpdateQueueTime(enqueue_time); single_packet_queue_-SubtractPauseTime(pause_time_sum_); size_packets_ = 1; size_ += PacketSize(*single_packet_queue_); } if (single_packet_queue_.has_value()) { if (single_packet_queue_-Type() == RtpPacketMediaType::kAudio) { return single_packet_queue_->EnqueueTime(); } return absl::nullopt; } if (stream_priorities_.empty()) { return absl::nullopt; } uint32_t ssrc = stream_priorities_.begin()->second; const auto& top_packet = streams_.find(ssrc)->second.packet_queue.top(); if (top_packet.Type() == RtpPacketMediaType::kAudio) { return top_packet.EnqueueTime(); } return absl::nullopt; }如果这个unpaced_audio_packet变量的值为true,这不会走media_buget_的机制,直接取出数据。
std::unique_ptr PacingController::GetPendingPacket( const PacedPacketInfo& pacing_info, Timestamp target_send_time, Timestamp now) { if (packet_queue_.Empty()) { return nullptr; } // First, check if there is any reason _not_ to send the next queued packet. // Unpaced audio packets and probes are exempted from send checks. bool unpaced_audio_packet = !pace_audio_ && packet_queue_.LeadingAudioPacketEnqueueTime().has_value(); bool is_probe = pacing_info.probe_cluster_id != PacedPacketInfo::kNotAProbe; //不pace audio if (!unpaced_audio_packet && !is_probe) { if (Congested()) { // Don't send anything if congested. return nullptr; } if (mode_ == ProcessMode::kPeriodic) { if (media_budget_.bytes_remaining() // Not enough budget. RTC_LOG(LS_INFO) // Dynamic processing mode. if (now // We allow sending slightly early if we think that we would actually // had been able to, had we been right on time - i.e. the current debt // is not more than would be reduced to zero at the target sent time. TimeDelta flush_time = media_debt_ / media_rate_; if (now + flush_time target_send_time) { return nullptr; } } } } //直接取出数据 return packet_queue_.Pop(); } //音频包走这个分支 RTC_DCHECK(stream_priorities_.empty()); std::unique_ptrRtpPacket()); single_packet_queue_.reset(); queue_time_sum_ = TimeDelta::Zero(); size_packets_ = 0; size_ = DataSize::Zero(); return rtp_packet; }在只有音频的情况下,音频包只会入single_packet_queue_,并且不会走media_buget_的机制,每次时间片内都会马上取出来发送出去,起到降低延迟的作用。
音视频流的处理
PacingController::ProcessPackets是每5ms跑一次(kPeriodic模式)。视频数据,一次会产生一批rtp包,在间隔周期内,会有多个包进入队列。在size_packets_为0时,包会进入single_packet_queue_,不为0时进入包缓存队列。在这个时候media_budget_就起作用了。
音视频流都存在的情况下,音频包也不止会进入single_pakcet_queue_了,这时音频的加速就体现在std::unique_ptr PacingController::GetPendingPacket上了,判断为音频包时,则不走media_buget_机制,直接取出数据。
对非音频包,则下面这个分支会起作用,限制包的发送。
if (mode_ == ProcessMode::kPeriodic) { if (media_budget_.bytes_remaining() // Not enough budget. RTC_LOG(LS_INFO) Process的调用时间间隔和当前目标码率target bitrate来计算出本次Process理应发送的字节数。比如当前码率是100 000bps,本次Process调用与上次调用间隔是20ms,则本次理应发送的字节数是100 bits per ms * 20 ms = 2000bits=250 bytes。
250bytes为本次发送理应发送的字节数,但实际上视频RTP包差不多是一个MTU大小。我们不可能真的发送250bytes的数据,因此可能会导致理应发送的数据量多或少的问题,如何解决这个问题呢?
IntervalBudget中引入一个bytes_remaining_的变量来记录上次发送后,与理应发送数据量相比,多或少发了多少。其值为负表示上轮我们实际发送的比理应发送的数据量多了,我们本轮应该停止发送。其值为正表示我们上轮实际发送比理应发送的要少,还有富余。
工作原理
void set_target_rate_kbps(int target_rate_kbps);设置总的可用量max_bytes_in_budget_。
void IntervalBudget::set_target_rate_kbps(int target_rate_kbps) { target_rate_kbps_ = target_rate_kbps; max_bytes_in_budget_ = (kWindowMs * target_rate_kbps_) / 8; bytes_remaining_ = std::min(std::max(-max_bytes_in_budget_, bytes_remaining_), max_bytes_in_budget_); }target_rate_kbps目标码率,max_bytes_in_budget_为半秒钟可发送的码率。
void IncreaseBudget(int64_t delta_time_ms);根据毫秒数增加预算(增加的量计入bytes_remaining),在kPeriodic模式下,这个delta_time_ms的值为5ms。
void IntervalBudget::IncreaseBudget(int64_t delta_time_ms) { int64_t bytes = target_rate_kbps_ * delta_time_ms / 8; if (bytes_remaining_void UseBudget(size_t bytes);使用预算(bytes_remaining_减去bytes)。
void IntervalBudget::UseBudget(size_t bytes) { bytes_remaining_ = std::max(bytes_remaining_ - static_cast(bytes), -max_bytes_in_budget_); }UseBudget(size_t bytes)更新用掉的数据量(就是已发送的数据量),如下调用堆栈

如果bytes_remaining_小于0,那么当然不能在发数据了。
**padding_budget_**的原理也一样,它是用于计算padding的数据量。
码率平滑的实现原理
发包的流程PacingController::ProcessPackets放在一个线程中,会被定时触发。被触发后,会计算当前时间和上次被调用时间的时间差,然后将时间差参数传入media_buget(**IntervalBudget**对象),media_buget_算出当前时间片可以发送多少数据,然后从缓存队列(**RoundBobinPacketQueue**对象)中取出数据进行发送。
**media_buget_**计算时间片发送多少字节的公式如下:
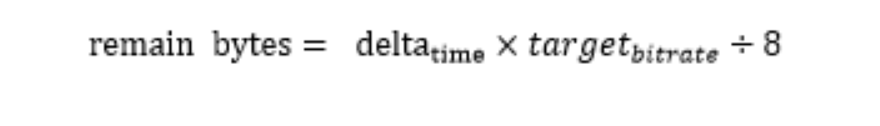
**delta time:**上次检查时间点和这次检查时间点的时间差。
target bitrate: pacer的参考码率,是由probe模块根据网络探测带宽评估出来。
remain_bytes: 每次触发包时会减去发送报文的长度size,如果remain_bytes>0,继续从缓存队列中取下一个报文进行发送,直到remain_bytes // Lower number takes priority over higher. switch (type) { case RtpPacketMediaType::kAudio: // Audio is always prioritized over other packet types. return kFirstPriority + 1; case RtpPacketMediaType::kRetransmission: // Send retransmissions before new media. return kFirstPriority + 2; case RtpPacketMediaType::kVideo: case RtpPacketMediaType::kForwardErrorCorrection: // Video has "normal" priority, in the old speak. // Send redundancy concurrently to video. If it is delayed it might have a // lower chance of being useful. return kFirstPriority + 3; case RtpPacketMediaType::kPadding: // Packets that are in themselves likely useless, only sent to keep the // BWE high. return kFirstPriority + 4; } RTC_CHECK_NOTREACHED(); } if (priority_ != other.priority_) return priority_ other.priority_; if (is_retransmission_ != other.is_retransmission_) return other.is_retransmission_; return enqueue_order_ other.enqueue_order_; }
- 计算平均缓存时间
- 计算总延时,UpdateQueueTime每次被调用,总时长都会被计算,累加。
- std::multiset enqueue_times_
- std::multimap **stream_priorities_**



