
Linux线程进程,深入理解与比较?线程与进程究竟有何不同?线程和进程,区别在哪?

Linux中的进程和线程是操作系统资源调度的核心单元,二者既有联系又有显著差异。**进程是资源分配的基本单位**,拥有独立的地址空间、文件描述符等系统资源,进程间通信需依赖IPC机制(如管道、共享内存),而**线程是CPU调度的最小单位**,属于同一进程的多个线程共享进程资源(如内存、文件),仅保留独立的栈、寄存器等执行上下文,切换开销远低于进程。 ,关键区别在于: ,1. **资源隔离性**:进程间相互隔离,线程共享进程资源; ,2. **创建/切换成本**:线程创建和上下文切换更快; ,3. **通信机制**:线程可直接读写进程数据,进程通信需额外机制; ,4. **健壮性**:单个线程崩溃可能导致整个进程终止,而进程间互不影响。 ,多线程适合高并发任务(如Web服务器),多进程则更安全(如浏览器多标签),理解二者差异有助于优化程序性能与稳定性。
在Linux操作系统的并发编程领域,线程和进程是最基础也是最重要的两个概念,对于系统开发者、运维工程师和性能优化专家而言,深入理解它们的核心区别、底层工作原理以及适用场景,是构建高性能、稳定系统的关键,本文将从内核实现机制出发,结合性能指标和典型应用案例,为您提供一份系统性的技术指南。
进程与线程的本质解析
进程(Process)的体系架构
进程是操作系统进行资源分配和调度的基本单位,每个进程都拥有完全独立的虚拟地址空间(通常32位系统为4GB)、文件描述符表、信号处理机制等系统资源,在Linux中,通过fork()系统调用创建新进程时,子进程会继承父进程的大部分资源(采用写时复制/COW技术优化性能)。
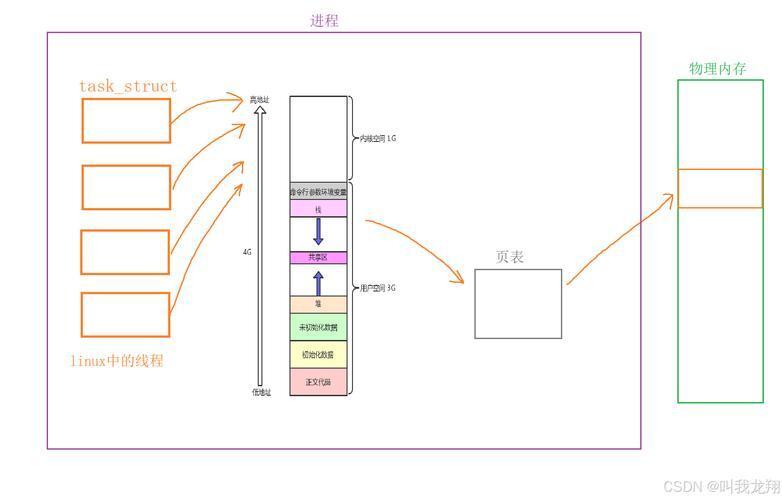
核心特征:
- 强隔离性:进程间内存空间严格隔离,一个进程的崩溃不会影响其他进程
- 完整资源上下文:每个进程包含独立的页表、文件描述符表、信号掩码等
- 安全边界:进程是Linux权限管理的基本单元,uid/gid权限基于进程控制
- 显式通信机制:进程间通信(IPC)必须通过管道、共享内存等特定机制
进程创建的系统调用链:
fork() -> clone() -> do_fork() -> copy_process()
内核通过写时复制技术延迟实际内存复制,仅复制进程描述符(task_struct)等元数据。
线程(Thread)的实现模型
线程是进程内的执行单元,是CPU调度的基本单位,同一进程内的多个线程共享:
- 相同的虚拟地址空间
- 文件描述符表
- 信号处理程序
- 进程凭证(uid/gid)
但各自拥有:
- 独立的线程ID(TID)
- 专用栈空间(默认2-10MB,可通过
pthread_attr_setstacksize调整) - 线程局部存储(TLS)
- 独立的信号掩码和调度优先级
POSIX线程创建流程:
pthread_create() -> clone() -> do_fork()
与进程创建使用相同内核机制,但通过clone()参数控制资源共享程度。

Linux调度器的实现细节
进程调度策略
Linux采用完全公平调度器(CFS)算法,关键参数包括:
nice值(-20到19,影响时间片权重)- 实时优先级(0-99,SCHED_FIFO/SCHED_RR策略)
- CPU亲和性(通过
taskset或sched_setaffinity设置)
进程上下文切换开销主要来自:
- TLB刷新(平均约100-200个时钟周期)
- 页表切换(x86通过CR3寄存器)
- 缓存失效(尤其L1/L2缓存)
线程调度优化
由于线程共享地址空间,其上下文切换开销显著降低:
- 无需TLB刷新(共享页表)
- 缓存利用率更高(共享相同的内存访问模式)
- 平均切换时间比进程快5-10倍
但需要注意:
- 大量线程会导致调度器开销增加(Linux线程与进程同等调度)
- 虚假共享(False Sharing)可能降低多核性能
- NUMA架构下需要显式绑定内存节点
同步机制的工程实践
高级同步原语对比
| 机制 | 最佳场景 | 性能特征 | 风险点 |
|---|---|---|---|
| 自旋锁 | 临界区极短(<100ns) | 无上下文切换 | 死锁、CPU空转 |
| 互斥锁 | 通用场景 | 约50ns获取时间 | 优先级反转 |
| 读写锁 | 读多写少(>90%读) | 读并行度高 | 写者饥饿 |
| RCU | 读极端频繁 | 读零开销 | 内存回收复杂 |
| 条件变量 | 事件等待 | 需配合互斥锁 | 虚假唤醒 |
无锁编程实践
现代多核系统推荐模式:
// C++11原子变量示例
std::atomic<int> counter(0);
void increment() {
counter.fetch_add(1, std::memory_order_relaxed);
}
// CAS(Compare-And-Swap)典型模式
void push(Node* new_node) {
Node* old_head = head.load();
do {
new_node->next = old_head;
} while (!head.compare_exchange_weak(old_head, new_node));
}
内存序选择原则:
memory_order_seq_cst:默认严格顺序(性能最低)memory_order_acquire/release:读写侧同步memory_order_relaxed:计数器等无依赖场景
性能调优实战案例
Nginx进程模型调优
典型配置优化项:

worker_processes auto; # 匹配CPU核心数
worker_cpu_affinity auto; # 自动绑定核心
worker_rlimit_nofile 100000; # 提高文件描述符限制
events {
worker_connections 10240; # 每个worker的连接数
use epoll; # 高性能I/O多路复用
multi_accept on; # 批量接受新连接
}
Java线程池最佳实践
// 自定义线程工厂示例
ThreadFactory factory = new ThreadFactoryBuilder()
.setNameFormat("worker-%d")
.setUncaughtExceptionHandler(logExceptionHandler)
.build();
// 适合CPU密集型任务的线程池
ExecutorService executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
Runtime.getRuntime().availableProcessors() * 2,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
factory,
new ThreadPoolExecutor.CallerRunsPolicy());
关键参数准则:
- 计算密集型:线程数 = CPU核心数 + 1
- I/O密集型:线程数 = CPU核心数 × (1 + 平均等待时间/计算时间)
- 队列容量需避免OOM,通常设置1000-10000
新兴并发模型展望
用户态调度技术
- io_uring:Linux 5.1+的异步I/O接口,减少系统调用开销
- eBPF:在内核实现安全的事件驱动逻辑
- Coroutine:微信/libco等实现千万级协程
异构计算架构
graph TD
A[Main Process] --> B[CPU Thread Pool]
A --> C[GPU Accelerator]
A --> D[FPGA Worker]
B --> E[Task Queue]
C --> E
D --> E
设计要点:
- 任务自动切分(OpenMP/TBB)
- 统一内存空间(CUDA Unified Memory)
- 流水线并行化
终极决策树
graph TD
Start[需要并发?] -->|Yes| Q1{需要强隔离?}
Q1 -->|Yes| Process[选择多进程]
Q1 -->|No| Q2{共享状态复杂?}
Q2 -->|Yes| Thread[选择多线程+同步]
Q2 -->|No| Q3{任务粒度细?}
Q3 -->|Yes| Coroutine[考虑协程]
Q3 -->|No| Hybrid[混合架构]
通过深入理解Linux线程与进程的底层机制,开发者可以:
- 精准诊断性能瓶颈(perf/ftrace)
- 合理设计并发架构(隔离vs性能权衡)
- 规避常见陷阱(死锁、竞态条件)
- 充分利用硬件资源(NUMA、CPU缓存)
这些知识构成了构建现代高性能系统的基石,无论是开发微服务、实时交易系统还是AI推理引擎,都离不开对这些基础概念的深刻把握。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







