
用了都说好!Vanna,助力高速实现Text2SQL技术

目录
一、认识Vanna
1、Vanna简介
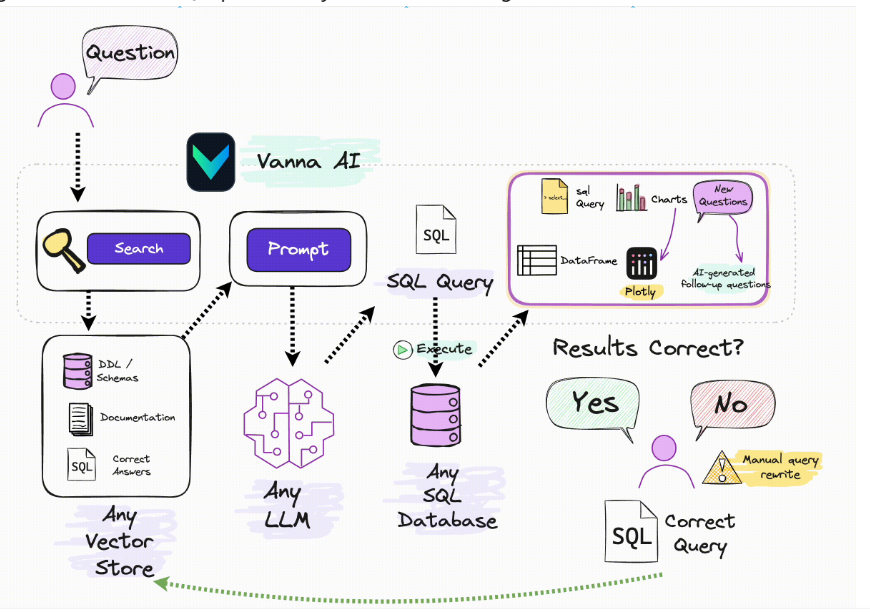
2、工作流程:
训练阶段
推理阶段
二、实操案例
documentations.json:
vanna_demo.py :
导入包与初始化配置
定义语言模型交互类
定义集成类
创建实例与连接数据库
存储 DDL 与业务术语定义
文件监听与自动重新加载
启动 Flask 应用
一、认识Vanna
1、Vanna简介
首先我们得先来认识下什么是Vanna:
Vanna 是一个基于 MIT 许可的开源 Python RAG(检索增强生成)框架,专注于 SQL 生成和相关功能。它允许用户在自己的数据上训练一个 RAG“模型”,然后通过自然语言提问,生成在数据库上运行的 SQL 查询语句,并将查询结果以表格和图表的方式展示给用户。其核心优势在于用户友好性和学习能力,即使非技术专家也能通过自然语言与之交流业务问题,且它能从交互中学习自我完善。
网站:https://vanna.ai/
2、工作流程:
训练阶段
首先需要在用户的数据上 “训练” 一个 RAG “模型”,这一步实际上是将数据结构构建向量库。用户可以使用多种方式来训练 Vanna,包括但不限于以下几种:
- 使用 DDL 语句:DDL 语句包含数据库表名、列名、数据类型和关系等信息。Vanna 使用这些信息构建数据库的 schema 表示,并将其存储到向量数据库中。例如,通过 vn.train(ddl="CREATE TABLE sales (id INT, product_id INT, amount FLOAT, date TIMESTAMP)") 这样的代码,将表结构信息输入给 Vanna。
-
使用文档:用户可提供业务术语或定义等文档信息,帮助 LLM 更好地理解自然语言问题中的业务概念,这些文档信息也会被存储到向量数据库中。
-
使用 SQL 查询:用户可以提供已有的 SQL 查询及其对应的自然语言描述作为训练数据,Vanna 将这些查询及其对应的自然语言描述存储到向量数据库中。如 vn.train(sql="SELECT p.id, p.name FROM products p WHERE p.category = 'kitchen'"),同时可以指定 optional_question 参数来指定提示问题。
此外,还可以通过指定 directory 参数来批量加载目录中的 SQL 文件,或指定 patterns 参数来过滤特定模式的文件,如 vn.train(directory="/path/to/sql/files", patterns=["*.sql"])。
推理阶段
当用户输入自然语言问题后,Vanna 会执行以下步骤来生成并执行 SQL 查询:
-
嵌入(Embedding):将用户的问题转换成向量表示,以便能够在向量数据库中进行相似性搜索。
-
检索(Retrieval):在向量数据库中检索与用户问题语义最相似的 DDL 语句、文档和 SQL 查询等信息。这些检索到的相关上下文信息将作为 LLM 的输入,帮助其更好地理解和生成符合用户意图的 SQL 查询。
-
生成(Generation):将检索到的信息和用户的问题一起提供给 LLM,由 LLM 生成对应的 SQL 查询。在生成 SQL 查询时,Vanna 会根据检索到的相关上下文信息以及用户的自然语言问题,利用 LLM 的语言理解和生成能力,构建出准确的 SQL 查询语句。
-
执行(Execution):将生成的 SQL 查询在数据库中执行,获取查询结果。Vanna 支持自动在用户的数据库上执行生成的 SQL 查询,也可以选择人工审核后执行。
-
结果返回和可视化:将查询结果以表格和 Plotly 图表的形式返回给用户,方便用户直观地查看和分析数据。如果用户反馈 LLM 生成的结果是正确的,Vanna 可以将这一问答对存储到向量数据库中,以便以后的生成结果更准确。
如果用户对生成的 SQL 查询不满意,可以使用 gpt4 参数指定使用 GPT-4 模型来提升结果质量,或者使用 temperature 参数来调整生成的随机性,如 vn.sql("How many products are in the kitchen category?", temperature=0.7)。此外,还可以通过 vn.table_names 属性查看 Vanna 已知的所有表名,确保问题中使用的表名正确。如果生成的 SQL 语句仍然不符合预期,用户可以手动修正后再使用 vn.run 方法执行,如 vn.run("SELECT p.id, p.name FROM products p WHERE p.category = 'kitchen';")。
二、实操案例
Q:我有一个员工信息表,想要基于Vanna和千问大模型实现自然语言查询,该如何操作?
A:
一、需求理解
-
目标 :实现通过自然语言对员工信息表进行查询,使非技术人员也能方便地获取员工信息表中的数据,提高数据查询的便捷性和效率。
-
核心功能 :将用户的自然语言问题准确地转换为能够查询员工信息表的 SQL 语句,并执行查询返回结果。
二、技术选型
-
Vanna :作为一个基于 Python 的 RAG 框架,其专注于 SQL 生成和相关功能,能够将自然语言问题转换为 SQL 查询语句,并且提供与数据库连接和执行查询的功能,为实现自然语言查询员工信息表提供了核心的 SQL 生成和执行能力。
-
千问大模型 :作为语言模型,能够理解和处理自然语言问题,将其转化为合适的表示形式,为 Vanna 生成准确的 SQL 查询提供语言理解支持。
三、实现步骤
-
环境搭建与依赖安装
-
确保 Python 开发环境已安装。
-
安装 Vanna 及其相关依赖库,如通过 pip install vanna 等命令。
-
安装千问大模型的 Python SDK 或相关的调用接口库,以便在代码中能够调用千问大模型。
-
数据准备
-
确定员工信息表的结构,包括表名、字段名、字段类型、主键等信息,例如员工信息表可能有员工 ID、姓名、职位、部门、入职日期等字段。
-
如果有现成的员工信息表,确保其数据的完整性和一致性;如果没有,需要根据实际需求创建员工信息表并填充数据。
-
代码实现
-
导入必要的模块和类 :从 vanna 模块中导入 VannaBase、ChromaDB_VectorStore 等类,用于构建 RAG 系统的基础功能和向量存储;从千问大模型的 SDK 中导入相关的类和方法,用于调用千问大模型。
-
定义语言模型类 :继承自 VannaBase,用于封装与千问大模型相关的操作,如初始化模型配置(包括模型名称、API 密钥等)、创建系统消息、用户消息和助手消息的格式、以及将提示提交给千问大模型并获取响应的方法。
-
定义自定义 Vanna 类 :继承自 ChromaDB_VectorStore 和之前定义的语言模型类,结合向量存储和语言模型的功能,在初始化时分别初始化向量存储和语言模型,重写 generate_sql 方法,在每次提问前清空对话历史,然后调用父类的 generate_sql 方法生成 SQL。
-
创建自定义 Vanna 实例并连接数据库 :传入千问大模型的 API 密钥和模型名称等配置信息创建自定义 Vanna 实例,然后调用 connect_to_mysql 等方法连接到员工信息表所在的 MySQL 等数据库,传入数据库的相关信息(如主机、名称、用户名、密码和端口等)。
-
存储数据库结构信息和业务术语定义 :定义员工信息表的 DDL 语句,调用自定义 Vanna 实例的 train 方法将 DDL 存储到向量库,使模型了解数据库结构;如果有业务术语定义(如对某些职位、部门的特定称呼等),从 JSON 文件加载业务术语定义并存储到向量库中。
-
实现文件监听和自动重新加载(可选) :如果业务术语定义等可能会频繁更新,可以实现文件监听功能,当检测到相关文件(如存储业务术语定义的 JSON 文件)被修改时,自动重新加载并更新向量库中的信息。
-
启动 Flask 应用提供交互界面 :从 vanna.flask 模块导入 VannaFlaskApp 类,创建 Flask 应用实例,传入自定义 Vanna 实例并设置相关参数(如 allow_llm_to_see_data 等),然后调用 app.run() 方法启动 Flask 应用,提供网页界面供用户输入自然语言问题并展示查询结果。
-
-
-
四、测试与优化
-
测试 :准备各种自然语言查询测试用例,如 “查找所有销售部门的员工”、“查询入职日期在 2024 年的员工姓名和职位” 等,通过自定义 Vanna 实例的 generate_sql 方法生成对应的 SQL 语句,并在数据库中执行查询,检查返回结果是否准确。
-
优化 :根据测试结果,对生成的 SQL 语句进行分析,如果发现某些查询生成的 SQL 语句不准确或效率低下,可以对语言模型的提示模板、向量存储的配置等进行调整和优化,以提高查询的准确性和性能。
五、安全与隐私考虑
-
数据安全 :确保员工信息表中的数据安全,对数据库连接进行加密,限制对数据库的访问权限,只允许授权的用户和应用程序访问数据。
-
隐私保护 :员工信息可能包含个人隐私数据,如姓名、联系方式等,在处理和存储这些数据时,需要遵循相关的隐私法律法规,对敏感数据进行加密或脱敏处理,防止隐私泄露。
Project:
需要的软件版本如下:
python vanna Mysql 3.11 0.7.9 8.0 接着我们开始构建应用,因为我用的pycharm,需要提前连接数据库
需要生成两个文件,文件结构如下:
vanna/
├── .venv/
│ ├── etc/
│ ├── include/
│ ├── lib/
│ ├── Scripts/
│ └── share/
├── .gitignore
├── pyvenv.cfg
├── 663c7487-e2c6-4de9-995a-a465107c4a1e/
├── c771f56a-5baf-4bf1-b9c8-b1e274b5babd/
├── fc9f1301-865c-452c-b7f7-7dd3451e6cbc/
├── chroma.sqlite3
├── documentations.json # documentations配置文件
└── vanna_demo.py # 运行文件
documentations.json:
{ "福报": "CustomerID >=3,也就是可以向社会输送的人才", "核心员工": "CustomerID between 1 and 10 的员工", "新员工": "CustomerID > 50 的员工", "老员工": "CustomerID between 1 and 5 的员工", }vanna_demo.py :
导入包与初始化配置
from vanna.base import VannaBase from vanna.chromadb import ChromaDB_VectorStore from dashscope import Generation import random import json import time from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler import threading DEBUG_INFO = None # 用于存储调试信息的全局变量,初始化为 None,后续在语言模型的提示提交过程中会更新其值,方便调试时查看输入输出情况。
-
导入包的解释 :
-
vanna.base :提供了 VannaBase 基类,为自定义类提供基础功能和接口。
-
vanna.chromadb :包含 ChromaDB_VectorStore 类,用于实现基于 ChromaDB 的向量存储功能,以便进行高效的向量检索和存储。
-
dashscope :提供了 Generation 类,用于调用语言模型进行文本生成等任务,通过其 call 方法可以方便地提交提示并获取模型的响应。
-
random :用于生成随机种子,增加生成结果的多样性。
-
json :用于处理 JSON 文件,方便加载和解析业务术语定义等数据。
-
time :提供了时间相关的函数,在文件监听过程中用于让线程暂停一段时间,避免过度占用 CPU 资源。
-
watchdog.observers 和 watchdog.events :用于实现文件监听功能,通过 Observer 观察文件系统的变化,当特定文件(如 documentations.json)被修改时,触发相应的处理事件。
-
threading :用于创建和管理线程,在后台启动文件监听线程,使主程序可以继续执行其他任务而不被阻塞。
定义语言模型交互类
class QwenLLM(VannaBase): def __init__(self, config=None): self.model = config['model'] self.api_key = config['api_key'] def system_message(self, message: str): return {'role': 'system', 'content': message} def user_message(self, message: str): return {'role': 'user', 'content': message} def assistant_message(self, message: str): return {'role': 'assistant', 'content': message} def submit_prompt(self, prompt, **kwargs): resp = Generation.call( model=self.model, messages=prompt, seed=random.randint(1, 10000), result_format='message', api_key=self.api_key) answer = resp.output.choices[0].message.content global DEBUG_INFO DEBUG_INFO = (prompt, answer) return answer-
函数解释 :
-
__init__ :初始化模型配置,从传入的配置字典中获取模型名称(model)和 API 密钥(api_key),分别存储到实例变量中,以便后续调用语言模型时使用。
-
system_message :创建系统消息格式,根据传入的消息内容,返回一个包含 role(系统角色)和 content(消息内容)键值对的字典,用于表示系统角色的消息,在与语言模型交互过程中标识消息来源为系统。
-
user_message :创建用户消息格式,与 system_message 类似,只不过 role 值为 user,用于表示用户角色的消息,在交互中传递用户的输入内容。
-
assistant_message :创建助手消息格式,role 值为 assistant,表示助手角色的消息,可用于后续构造完整的对话轮次或处理模型返回的回复内容。
-
submit_prompt :提交提示到语言模型并获取响应。通过调用 Generation.call 方法,传入模型名称、消息内容(prompt)、随机种子(用于生成不同结果)、结果格式以及 API 密钥,从模型返回的响应中提取答案内容,并更新全局的 DEBUG_INFO 变量记录输入提示和生成的答案,最后将答案返回,实现与语言模型的交互功能,是整个语言模型调用的核心方法。
定义集成类
class MyVanna(ChromaDB_VectorStore, QwenLLM): def __init__(self, config=None): ChromaDB_VectorStore.__init__(self, config=config) QwenLLM.__init__(self, config=config) def generate_sql(self, question, allow_llm_to_see_data=False): self.submit_prompt([self.system_message("清空之前的对话历史")]) return super().generate_sql(question, allow_llm_to_see_data=allow_llm_to_see_data)-
函数解释 :
-
__init__ :继承自 ChromaDB_VectorStore 和 QwenLLM 类,在初始化时分别调用父类的 __init__ 方法,传入配置参数,完成向量存储和语言模型的初始化工作,使得该类的实例同时具备向量存储操作和语言模型交互的功能。
-
generate_sql :在每次提问前清空对话历史,避免之前的对话内容对当前问题的干扰。通过调用 submit_prompt 方法,传入包含系统消息(清空对话历史指令)的提示,然后调用父类的 generate_sql 方法(来自 ChromaDB_VectorStore),传入问题和是否允许语言模型查看数据的标志,生成对应的 SQL 语句并返回,实现了结合向量存储和语言模型生成 SQL 的功能。
创建实例与连接数据库
vn = MyVanna({'api_key': '填写你的阿里云API', 'model': 'qwen-max'}) vn.connect_to_mysql(host='yourhost', dbname='your dbname', user='your username', password='your sql password', port=your port)-
代码解释 :
-
创建 MyVanna 实例 vn,传入包含 API 密钥和模型名称的配置字典,完成语言模型和向量存储的初始化配置,使得后续可以通过该实例进行模型交互和向量存储操作。
-
调用实例的 connect_to_mysql 方法,传入数据库的主机地址、名称、用户名、密码和端口,将向量存储与指定的 MySQL 数据库进行连接,为后续的数据库相关操作(如存储 DDL、训练等)建立基础,使得向量存储能够与数据库交互,利用数据库中的数据进行向量化的处理和存储。
存储 DDL 与业务术语定义
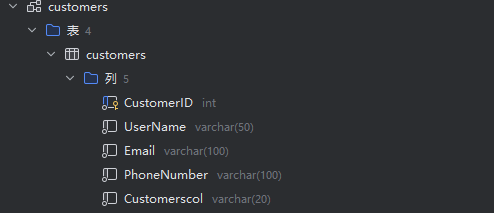
DDL = '''CREATE TABLE IF NOT EXISTS customers ( CustomerID INT PRIMARY KEY COMMENT '用户ID', UserName VARCHAR(50) COMMENT '用户名', Email VARCHAR(100) COMMENT '电子邮件', PhoneNumber VARCHAR(100) COMMENT '电话号码', Customerscol VARCHAR(20) COMMENT '附加信息' ) COMMENT '客户信息表'; ''' vn.train(ddl=DDL) def load_documentations(file_path): with open(file_path, 'r', encoding='utf-8') as f: return json.load(f) documentations = load_documentations('documentations.json') for term, definition in documentations.items(): vn.train(documentation=f'"{term}"是指 {definition}')-
代码解释 :
-
定义 DDL(数据定义语言)语句,用于创建一个名为 customers 的数据库表,指定了表的字段(如 CustomerID、UserName 等)、数据类型、约束条件(如主键)以及字段和表的注释信息,描述了数据库中客户信息表的结构。
-
调用 vn 实例的 train 方法,并传入 ddl=DDL 参数,将 DDL 存储到向量库中,使语言模型能够了解数据库的结构信息,为后续生成与数据库相关的 SQL 语句等操作提供基础数据支持,让模型知道数据库表的组成和各字段的含义。
-
定义 load_documentations 函数,传入文件路径参数,打开并读取指定的 JSON 文件(documentations.json),使用 json.load 方法将文件内容解析为 Python 字典对象并返回,该字典存储了业务术语及其对应的定义,方便后续加载业务相关的术语知识。
-
调用 load_documentations 函数,加载 documentations.json 文件中的业务术语定义数据,存储到 documentations 变量中。
-
遍历 documentations 字典中的每个业务术语(term)及其定义(definition),循环调用 vn 实例的 train 方法,将每个术语的定义以特定格式("{term}"是指 {definition})传入,存储到向量库中,使语言模型能够学习和理解这些业务术语的含义,从而在后续回答问题或生成内容时能够准确地运用这些术语,确保回答符合业务背景和需求。
文件监听与自动重新加载
class FileChangeHandler(FileSystemEventHandler): def on_modified(self, event): if event.src_path == 'documentations.json': print("documentations.json文件已修改,正在重新加载...") global documentations documentations = load_documentations('documentations.json') vn.train(documentation="清空之前的业务术语定义") for term, definition in documentations.items(): vn.train(documentation=f'"{term}"是指 {definition}') print("业务术语定义已更新") def start_file_observer(): observer = Observer() event_handler = FileChangeHandler() observer.schedule(event_handler, path='.', recursive=False) observer.start() try: while True: time.sleep(1) except KeyboardInterrupt: observer.stop() observer.join() file_observer_thread = threading.Thread(target=start_file_observer) file_observer_thread.daemon = True file_observer_thread.start()-
代码解释 :
-
定义 FileChangeHandler 类,继承自 FileSystemEventHandler,用于处理文件系统事件。重写 on_modified 方法,当监测到文件被修改时触发。在方法内部,判断被修改的文件路径是否为 documentations.json,如果是,则打印提示信息,重新加载该 JSON 文件更新 documentations 字典内容,并调用 vn 的 train 方法先清空之前存储的业务术语定义,再循环将新的术语定义存储到向量库中,最后打印更新完成的提示信息,实现了当业务术语定义文件被修改时,自动更新向量库中的相应内容,确保模型使用的是最新的业务知识。
-
定义 start_file_observer 函数,创建 Observer 对象和 FileChangeHandler 实例,将事件处理器绑定到观察者上,并指定监控的路径为当前目录('.'),启动观察者开始监听文件变化。通过一个无限循环(while True)结合 time.sleep(1) 使线程保持运行并定期检查文件变化,直到收到键盘中断信号(KeyboardInterrupt)才停止观察者并将其线程加入到主线程等待结束,实现了对文件修改的持续监听功能。
-
创建一个线程 file_observer_thread,将 start_file_observer 函数作为线程目标启动,设置为守护线程(daemon = True),使得该线程在主程序退出时自动结束。启动该线程后,程序可以在后台持续监听文件变化,而不影响其他任务的执行,实现了自动更新业务术语定义的自动化机制,提高了系统的维护性和实时性。
启动 Flask 应用
from vanna.flask import VannaFlaskApp app = VannaFlaskApp(vn, allow_llm_to_see_data=True) app.run()
-
代码解释 :
-
从 vanna.flask 模块导入 VannaFlaskApp 类,该类基于 Flask 框架创建 Web 应用,提供了与语言模型交互的网页界面。
-
创建 VannaFlaskApp 实例 app,传入之前初始化好的 vn 实例(包含语言模型和向量存储功能)以及参数 allow_llm_to_see_data=True,表示允许语言模型查看数据,使得在 Web 界面中用户与模型交互时,模型可以基于已有的数据(如数据库结构、业务术语等)生成更准确、相关的回复。
-
调用 app 实例的 run 方法启动 Flask 应用,使得程序可以通过网络提供服务,用户可以通过浏览器等客户端访问该 Web 应用,与语言模型进行交互,输入问题并获取模型生成的回答或 SQL 等结果,将模型功能通过 Web 界面的形式暴露给用户,方便用户使用和操作。
三、执行结果
以上工作完成后,可以执行运行,出现一个网页界面:
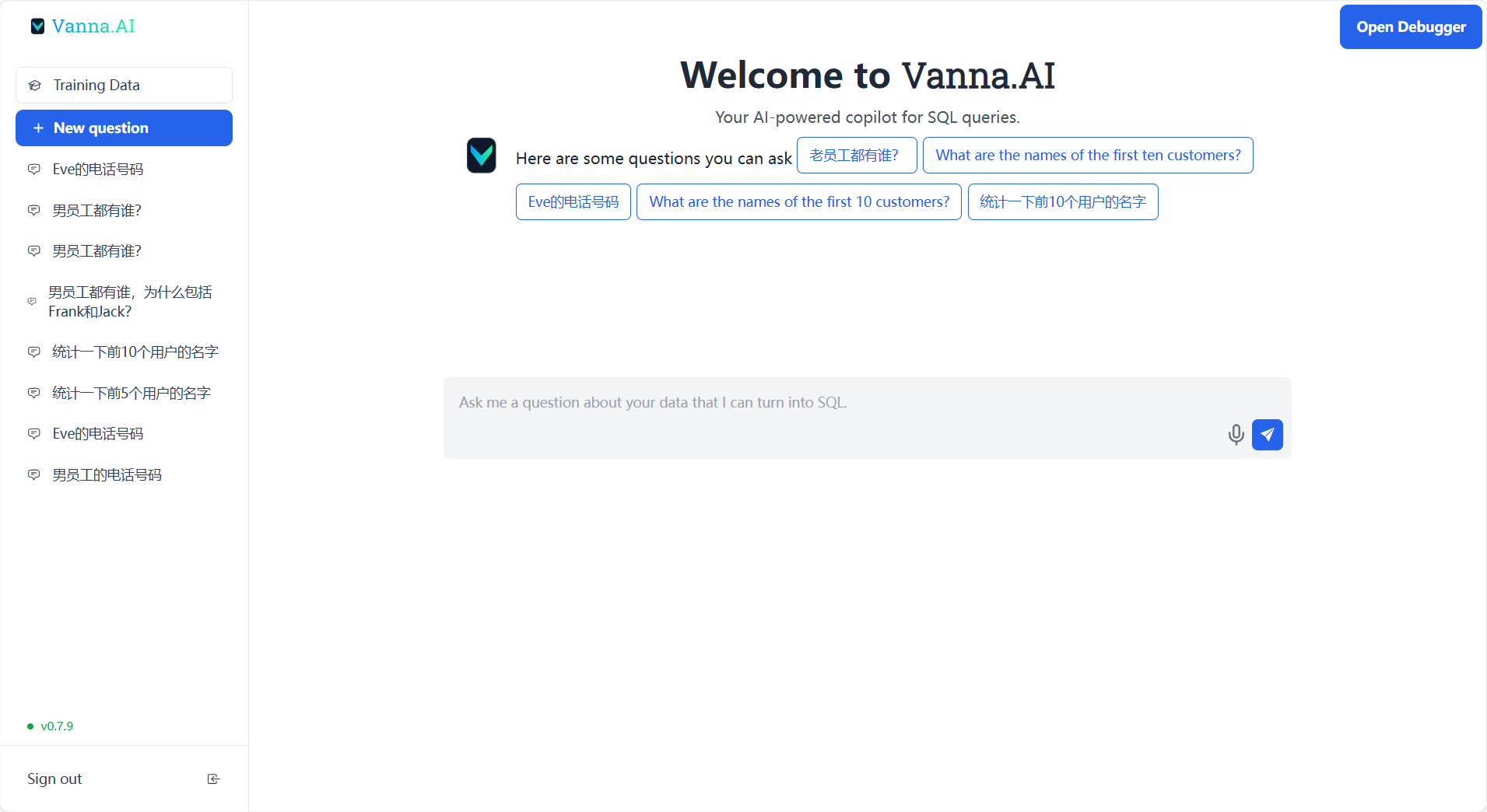
就可以基于数据库内容进行提问啦 !
如:
Q:Eva的电话号码?
A:999888777
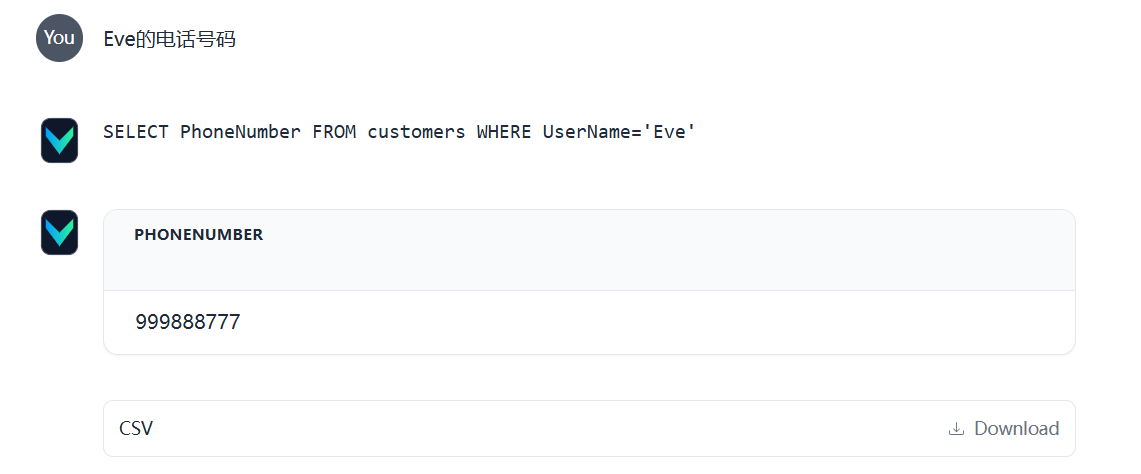
很方便,还可以下载CSV
在VannaFlaskApp中如果将allow_llm_to_see_data=True,那么还会产生自然语言回答
如:
Q:Eva的电话号码?
A:SELECT PhoneNumber FROM customers WHERE UserName='Eve'
Eve的电话号码是999888777。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-







