
爬虫实战:抖音视频搜索数据爬虫开发实战(附完整Python源码)

先看效果!支持:关键词搜索、支持视频日期筛选、支持页数筛选。可以获取全部字段!
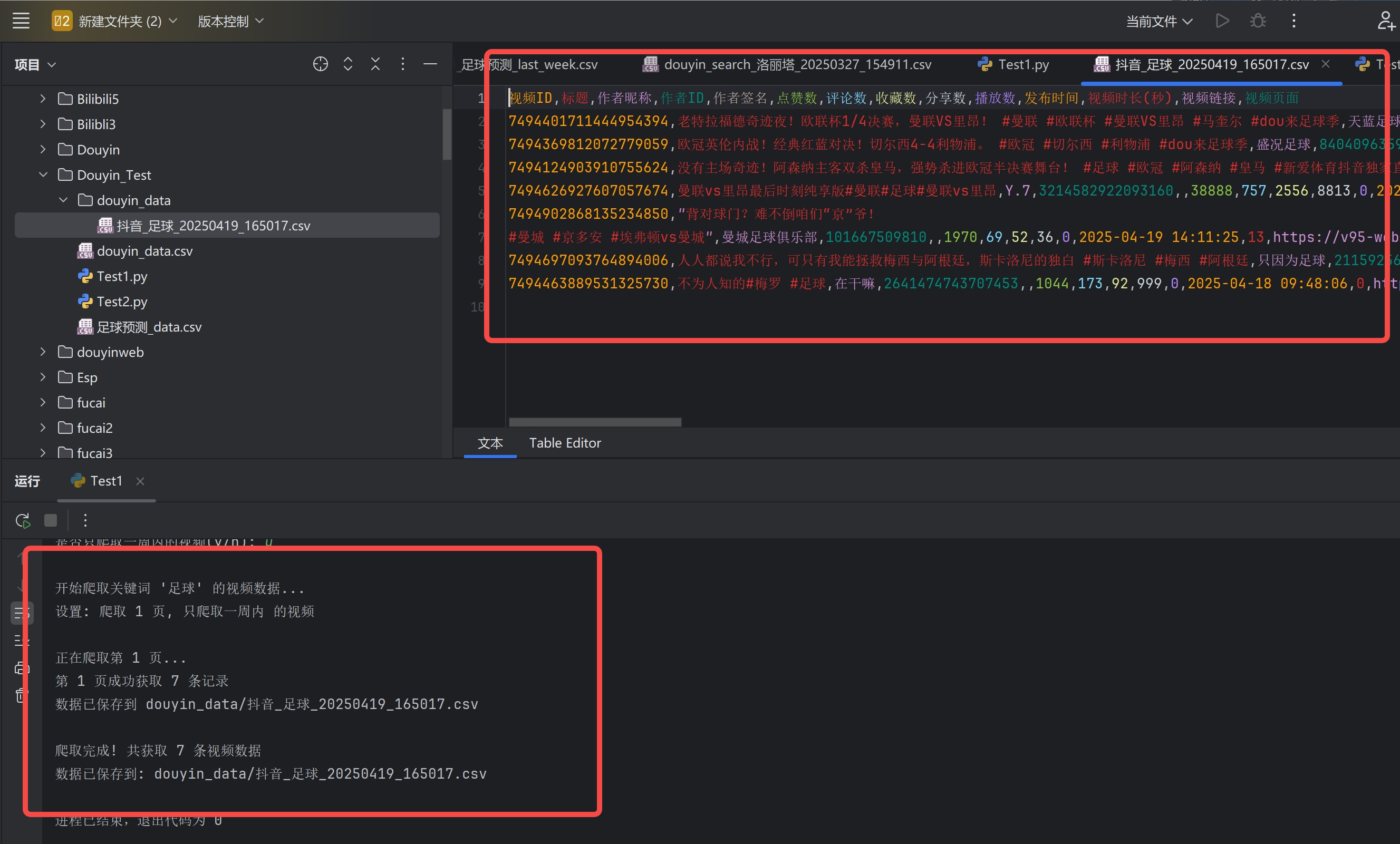
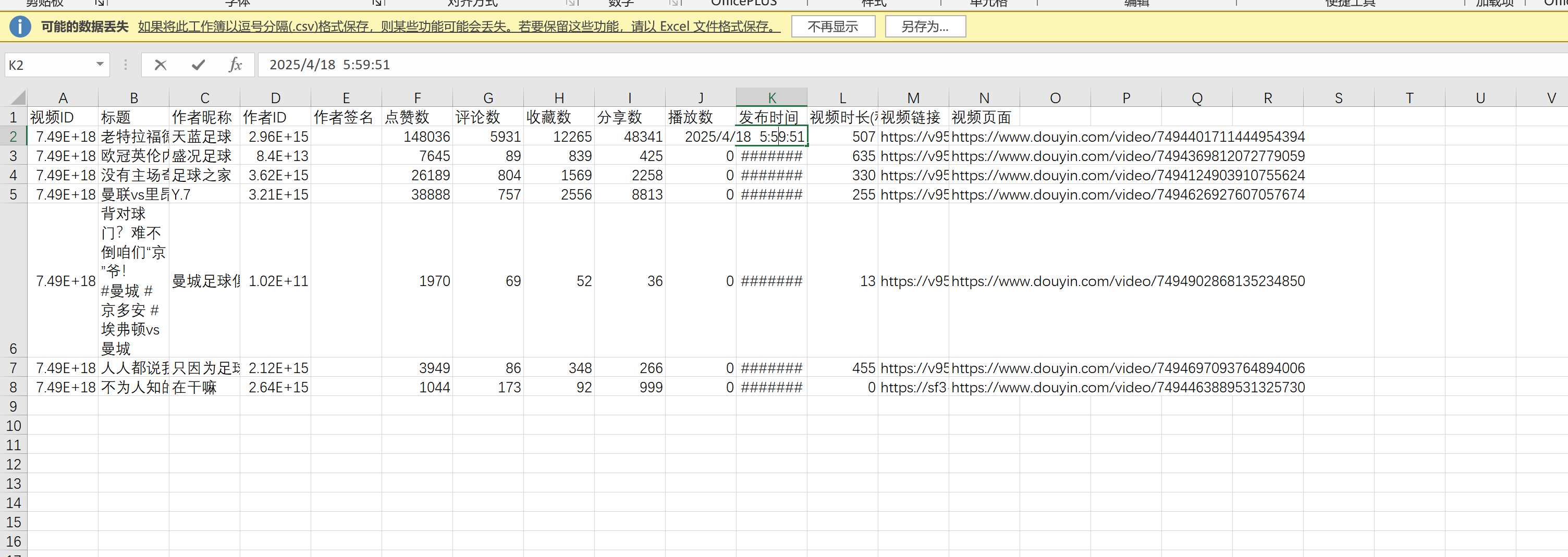
一、项目背景与功能特点
本文介绍一个基于Python开发的抖音视频搜索数据爬虫工具,具备以下技术特点:
-
核心功能:
- 支持自定义关键词搜索
- 可设定爬取页数(每页10条)
- 支持筛选最近一周发布的视频
- 自动保存结构化数据到CSV文件
-
技术亮点:
- 随机设备指纹生成
- 完善的请求重试机制
- 自动处理异常JSON数据
- 智能反爬策略应对
二、环境准备
开发环境要求:
- Python 3.7+
- 安装依赖库:
pip install requests pandas
三、核心代码解析
1. 参数生成模块
def generate_ms_token(self, length=128): """ """ characters = '' return ''.join(random.choice(characters) for _ in range(length)) def get_search_params(self, keyword, offset=0, only_last_week=False): """动态生成请求参数""" params = { 'aid': '', 'device_id': str(random.randint(7e18, 8e18)), 'webid': str(random.randint(7e18, 8e18)), 'msToken': self.generate_ms_token(), # 其他参数... } return params2. 数据清洗模块
def clean_json_response(self, response_text): """处理异常JSON数据""" json_start = response_text.find('{') if json_start == -1: return None possible_json = response_text[json_start:] try: return json.loads(possible_json) except: # 智能截取有效JSON部分 json_end = possible_json.rstrip().rfind('}') + 1 return json.loads(possible_json[:json_end]) if json_end > 0 else None3. 数据提取模块
def extract_video_data(self, aweme_info): """提取结构化视频数据""" return { '视频ID': aweme_info.get('aweme_id', ''), '标题': aweme_info.get('desc', '')[:50], # 截取前50字符 '作者昵称': author.get('nickname', ''), '视频链接': play_addr['url_list'][0] if play_addr else '', # 其他字段... }五、注意事项与优化建议
-
法律合规:
- 需遵守《数据安全法》和《个人信息保护法》
- 禁止商业用途和批量抓取
- 设置合理请求间隔(建议≥2秒)
-
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







