
爬虫之爬取-猫眼电影数据 手把手教学 干货满满

网站:影院热映大片_热映电影票房_高清电影影视大全-猫眼电影
温馨提示: 本案例仅供学习交流使用 此网站需要登陆 才能获取数据 cookie
| requests(发送HTTP请求) | parsel(解析HTML内容) |
| pandas(数据保存模块) | re(用于字符串匹配和处理) |
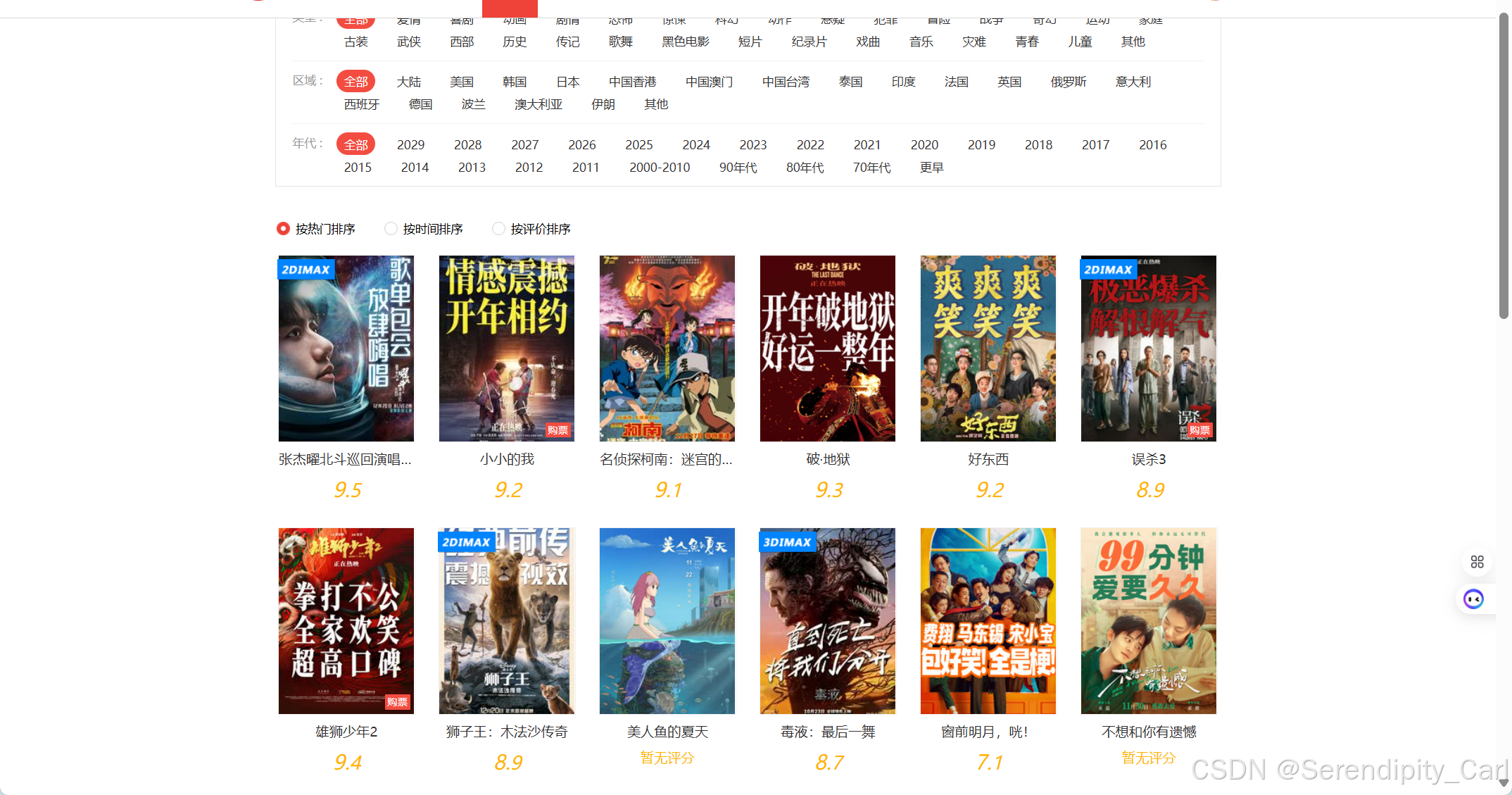
首先 明确爬取的数据
- 电影名称
- 电影评分
- 电影的上映时间
- 电影类型
- 电影海报封面
步骤:
- 简单分析界面 对前端的html结构有个结构
- 构建请求 模拟浏览器向服务器发送请求
- 解析数据 提取我们所需要的数据
- 保存数据 对数据进行持久化保存 如csv excel mysql
一.发送请求
查看源代码 查看是否为静态数据
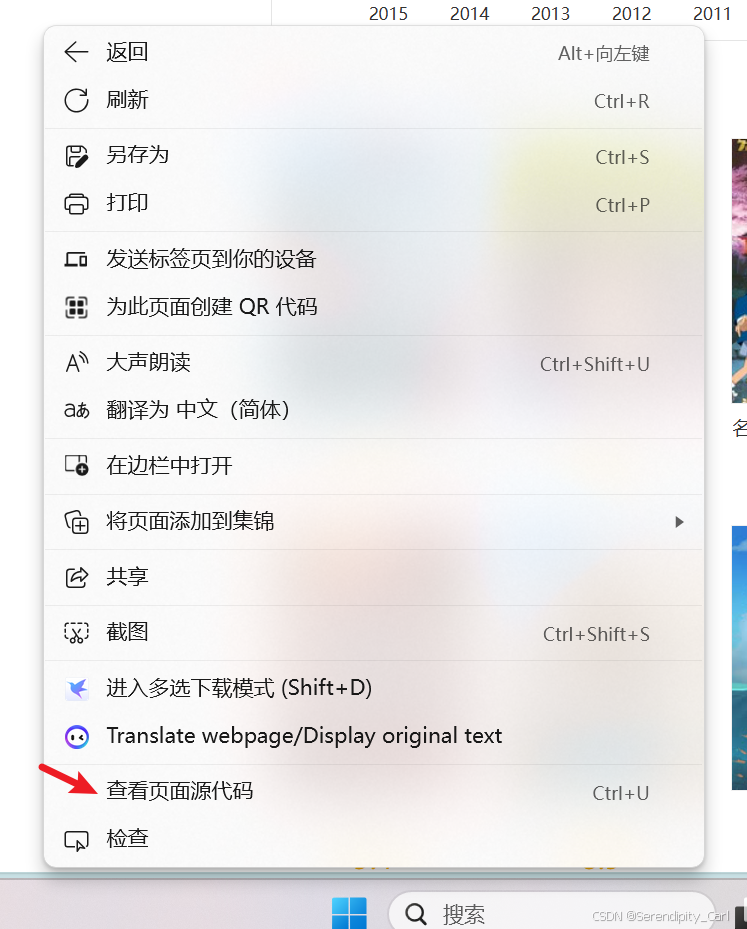
Ctrl+F 打开搜索框 查看是否包含我们爬取的数据
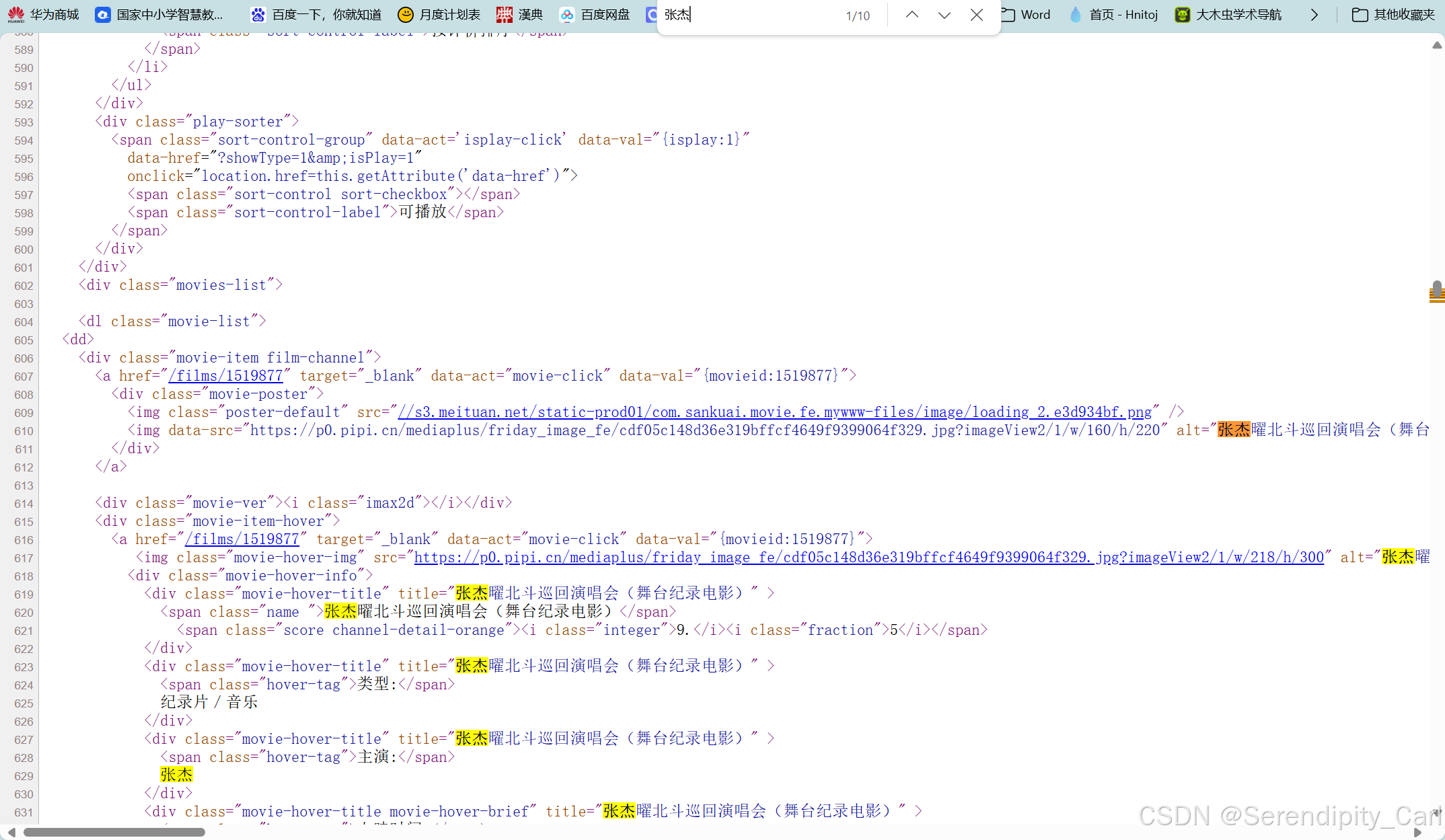
打开页面 F12 or 右击检查 打开开发者工具
点击左上角的这个像鼠标的 然后去页面中去选要爬取的数据 查看分析节点
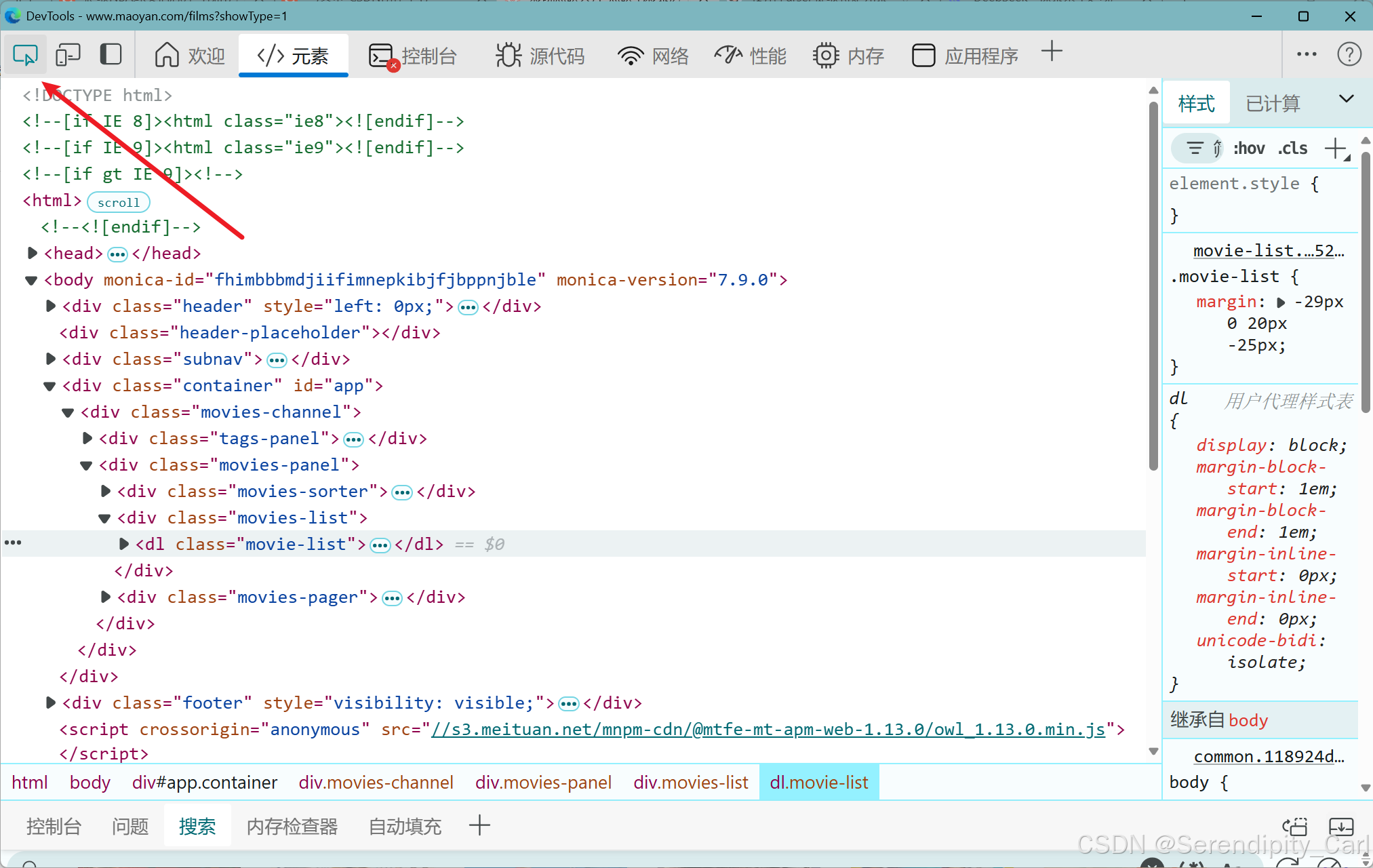
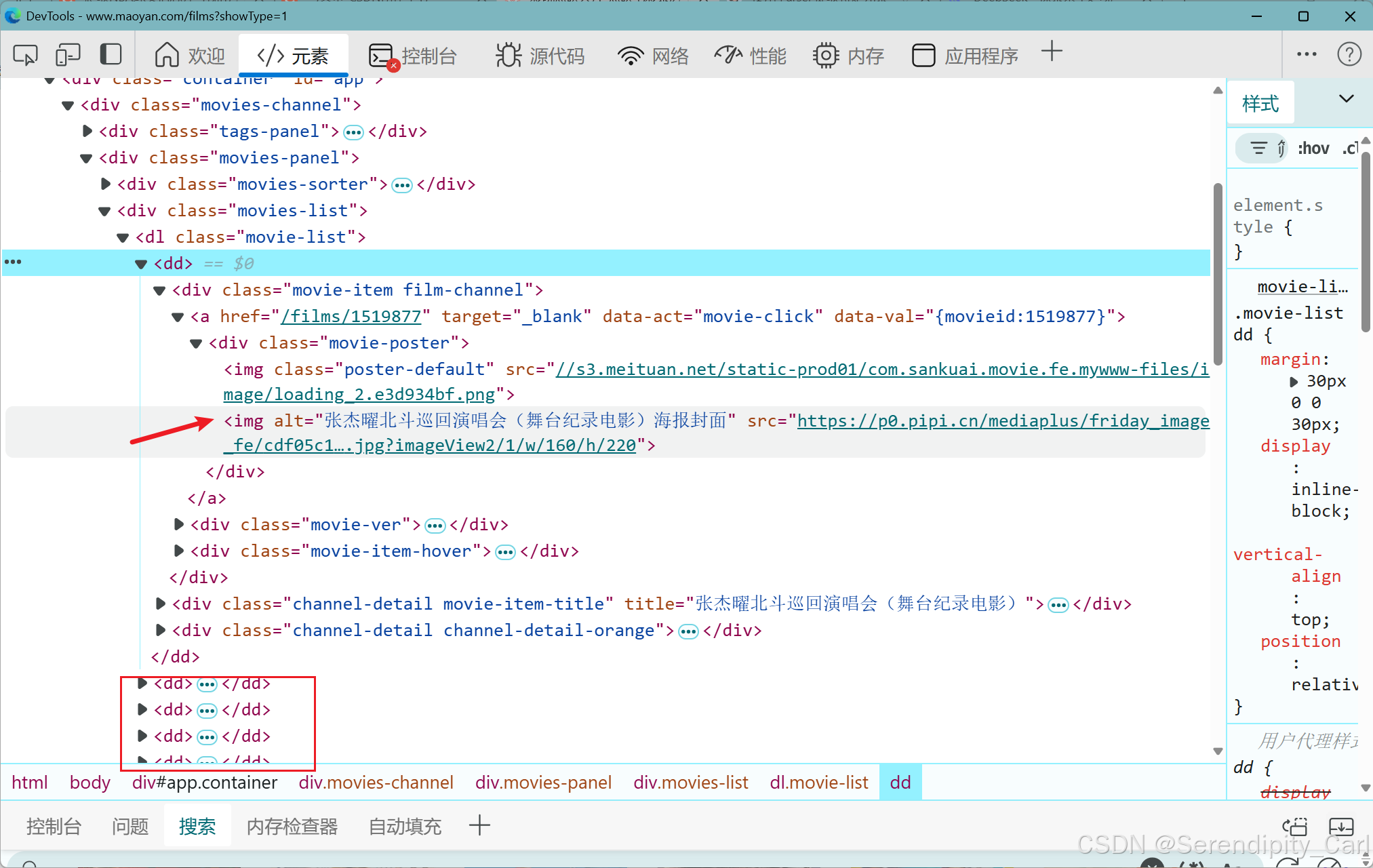
通过分析可得 每个电影的所有信息都在class属性为movie-list dl标签中的dd标签中
OK 简单地分析了结构之后 我们开始写代码
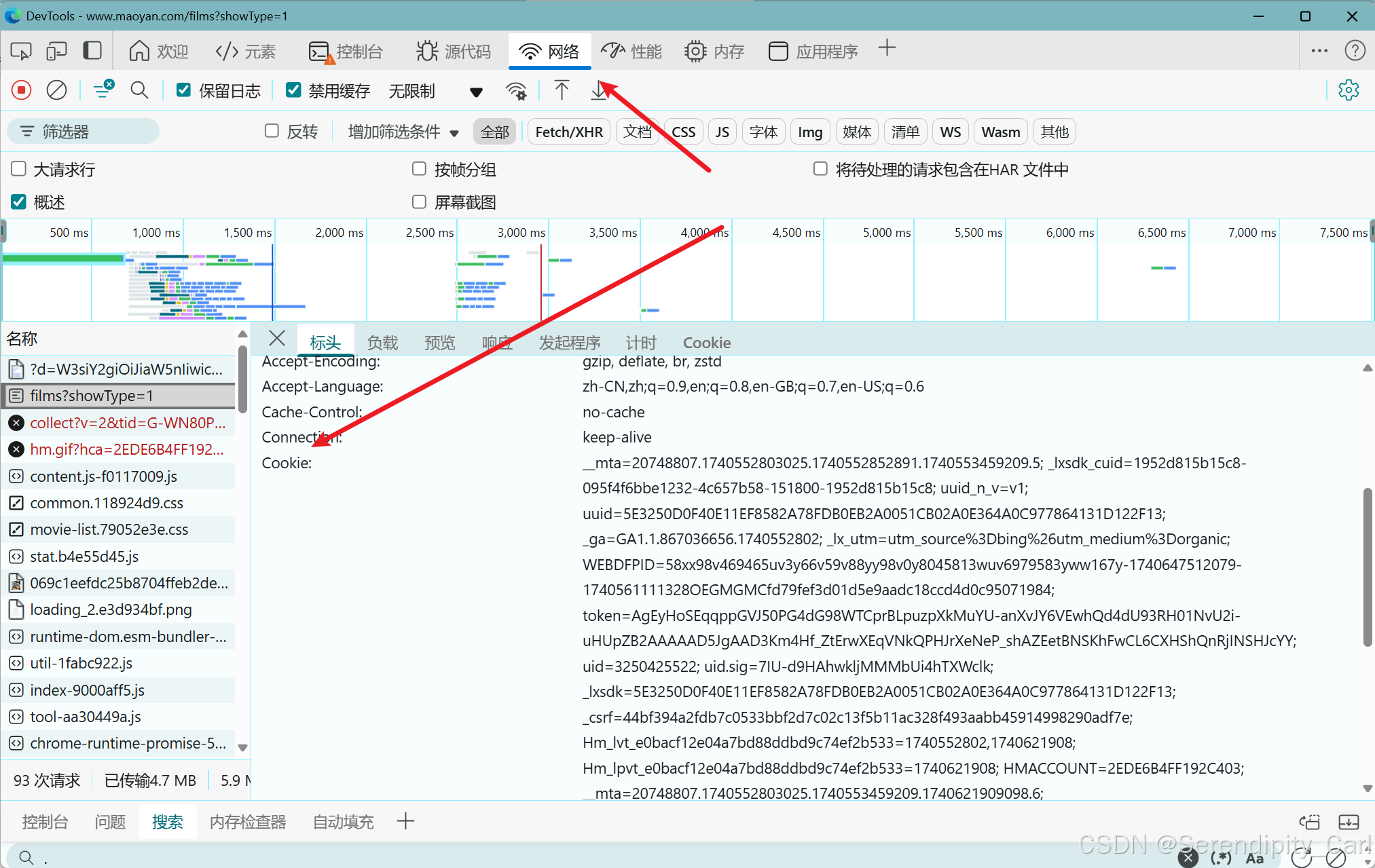
首先复制 浏览器中的地址 接着构建请求体 UserAgent(包含浏览器的基本信息 载荷 浏览器类型等) Referen(防盗链 简单来说就是你目前这个页面是从哪里跳转过来的) Cookie(包含了用户的一些登陆基本信息 ) 在浏览器复制就可以了
点击网络 接着 按快捷键Ctrl+R 刷新 加载数据包 手动刷新也行 点击标头下滑 复制即可
headers 通过键值对的形式构建 字典类型的
# 导包 import requests # 明确需求 爬取猫眼电影的名称 评分 上映时间 类型 海报封面 url = 'https://www.maoyan.com/films?showType=1' # 构建请求头 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0', 'referer': 'https://www.maoyan.com/', 'cookie':'复制自己的cookie' } # 模拟浏览器向服务器发送请求 resp = requests.get(url, headers=headers)二. 解析数据 提取数据
数据解析模块是用的parsel 需要pip 安装 pip install parsel
知识补充:
- 查看自己所有安装的库 在终端 输入指令 pip install freeze
- 将自己所有的库 保存为txt文件 pip install freeze > requirements.txt 名字固定叫这个 内行人一看就明白 也可以把自己的库快速地安装
- 批量安装的指令 pip install -r requirements.txt 读取这个文件并安装 前提是要在该项目的目录下面
import parsel # parsel模块解析 数据 # 实例化一个selector对象 selector = parsel.Selector(resp.text) # 提取电影名称 name_lis = selector.css('.movie-list dd') for i in name_lis: # 获取电影的名字 name = i.css('.channel-detail.movie-item-title::attr(title)').get()Explain:selector中内置了 三个方法 css xpath re 集成了三种 可以任意使用 方便很多
找到包含电影名称的父级标签 class属性为movie-list的dl 下面的dd标签
将根标签作为节点 通过for循环提起子标签中的内容
接着在div class属性为channel-detail &movie-item-title 中提取它的src属性 语法如上
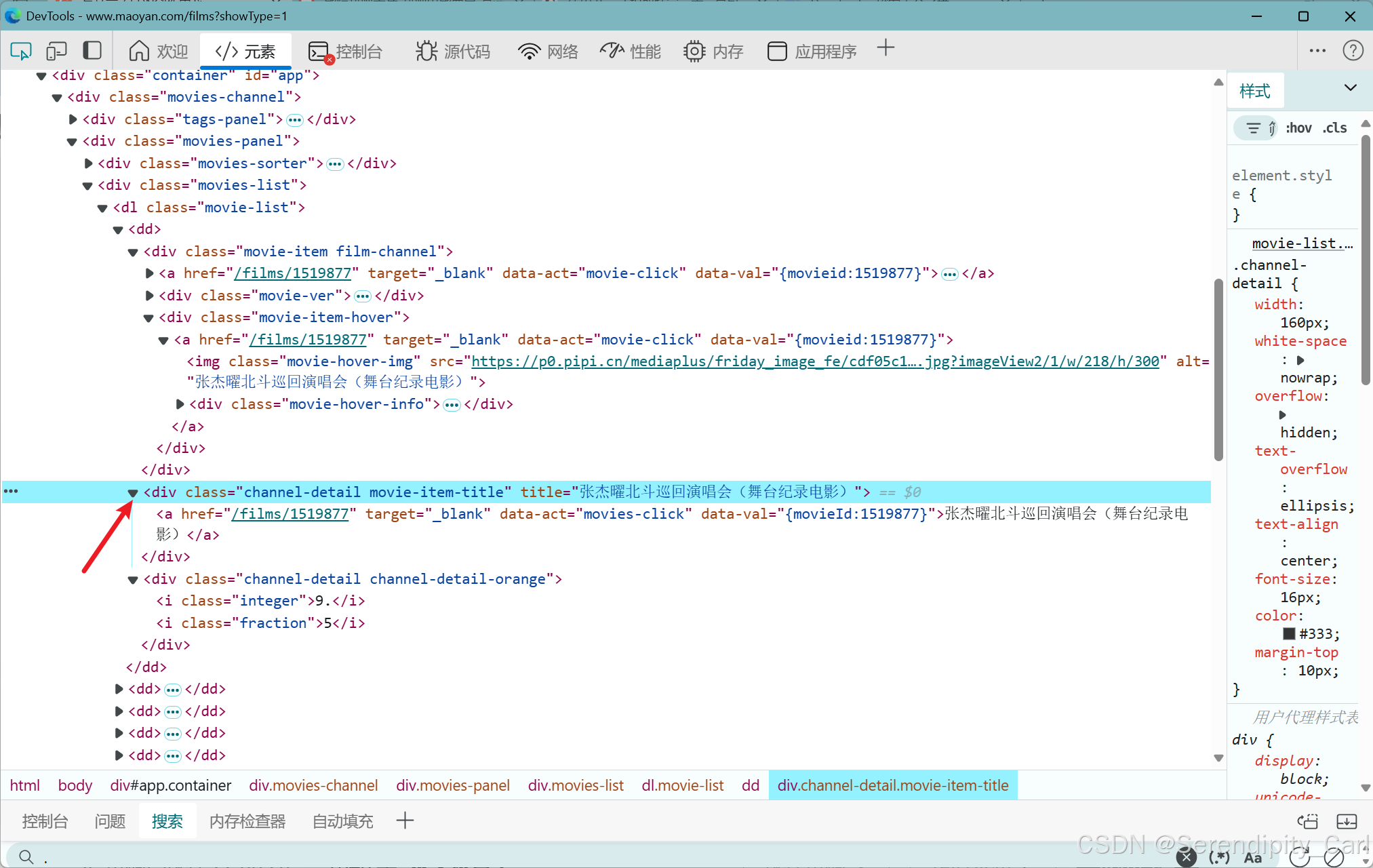
然后我们接着提取
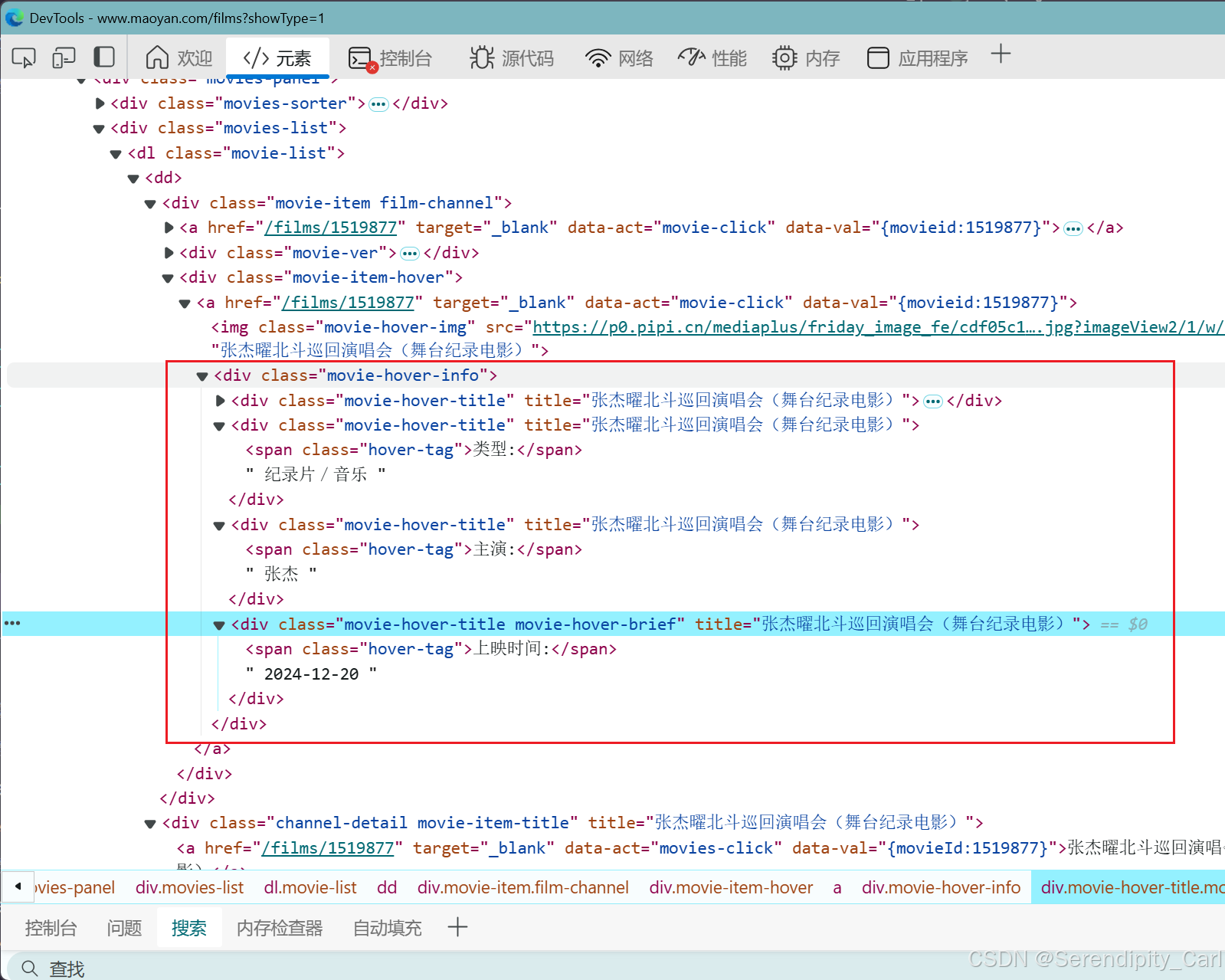
找到包含数据的根标签 根据标签层次结合css语法提取数据
拿到class属性为movie-item-hover的div标签 for循环遍历子节点 接着取class属性为movie-hover-title div (语法与css相同 .取class属性 #取id属性) 提取里面的文本 getall 顾名思义拿到所有

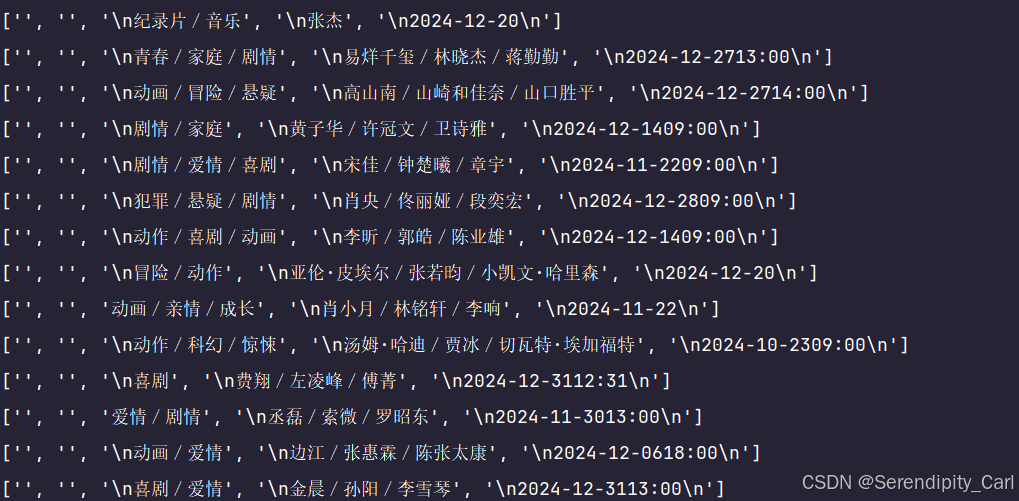

接着我们需要对得到的结果做一系列的处理
- 先转换成字符串
- 去除字符串中的空格
- 按双换行符分割字符串 分别进行取值
- 去除该元素的首尾空白字符
lis = selector.css('.movie-item-hover') for j in lis: # 处理得到的数据 # 电影的类型 movie_type = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-3].strip() # 电影的演员 movie_actor = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-2].strip() # 电影上映的日期 movie_date = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-1].strip()继续提取评分 分析可得 评分是分开的 还有的暂无评分
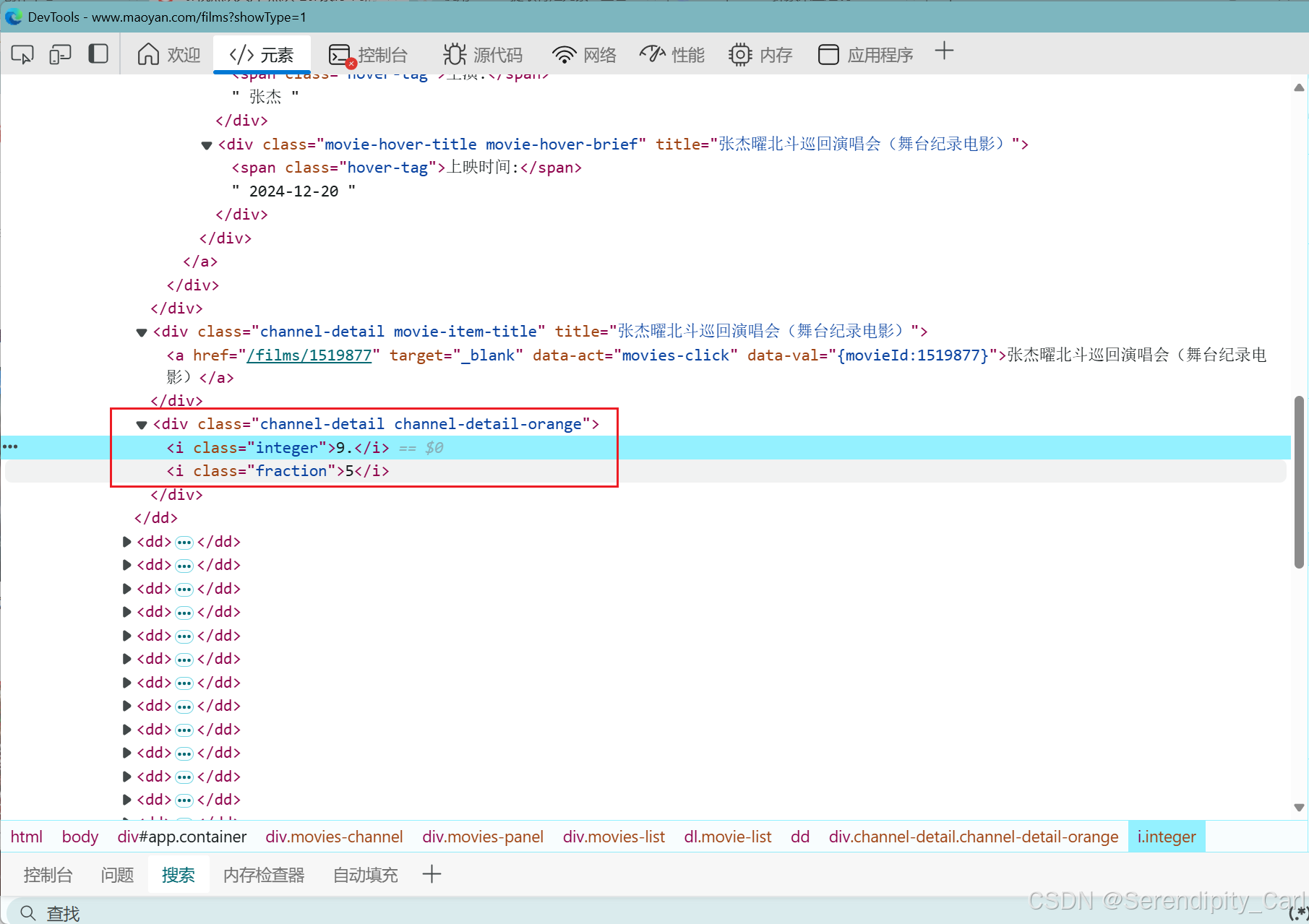
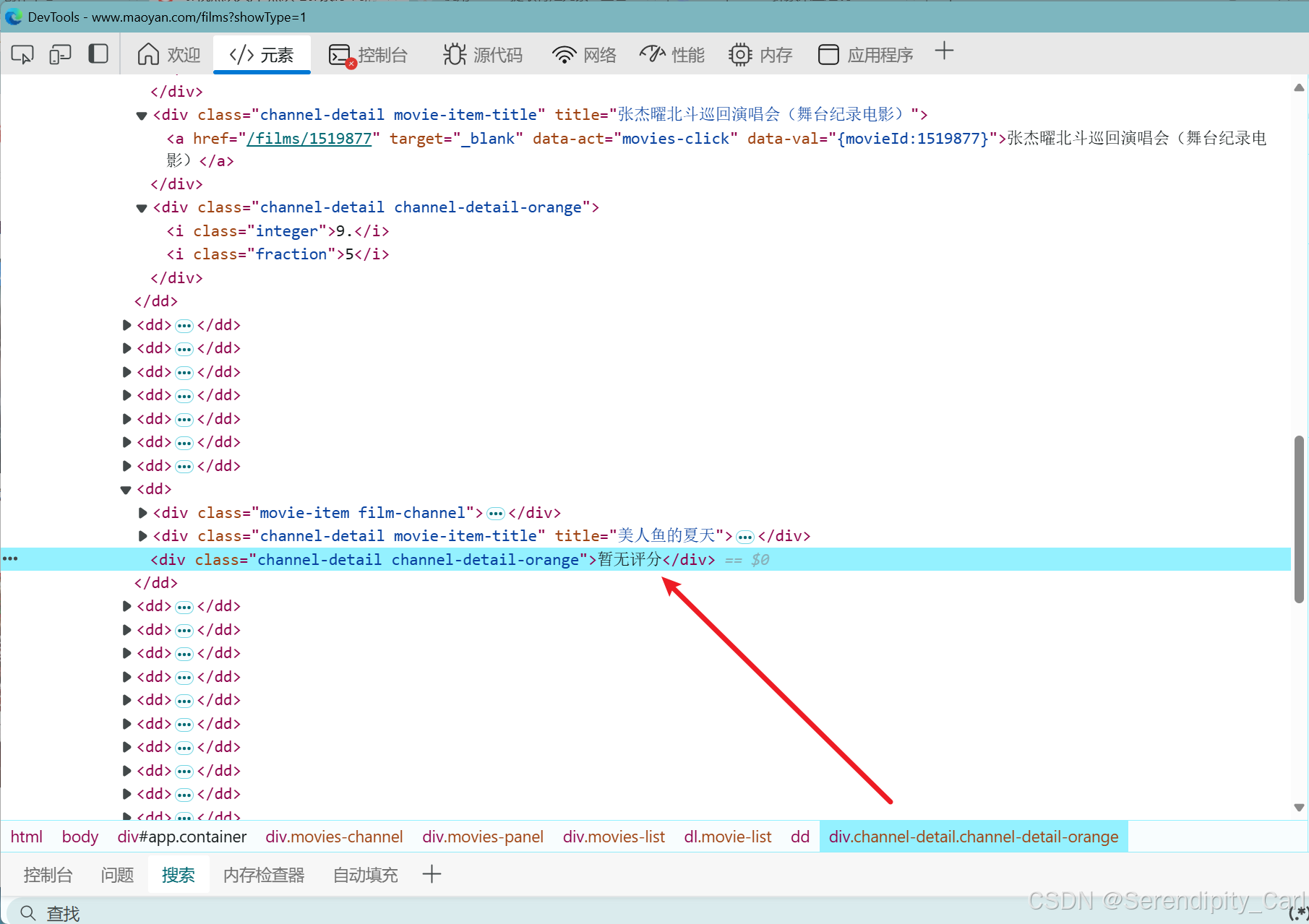
分析可得 区别就是这个div 下面是否有i标签 有的话则提取 i标签中的文本 没有则提取父级里面的文本
通过class属性找到根标签 就是这个div 进行判断
num_lis = selector.css('.channel-detail.channel-detail-orange') # 单独处理 评分 判断div标签下面有i标签时则提取 没有则提取父级里面的文本 for k in num_lis: if k.css('i'): judge = k.css('::text').get() judge2 = k.css('i:nth-of-type(2)::text').get() # 合并评分 judge_fi = judge + judge2 else: judge_fi = k.css('::text').get() judges.append(judge_fi)最后就是提取海报的url地址了
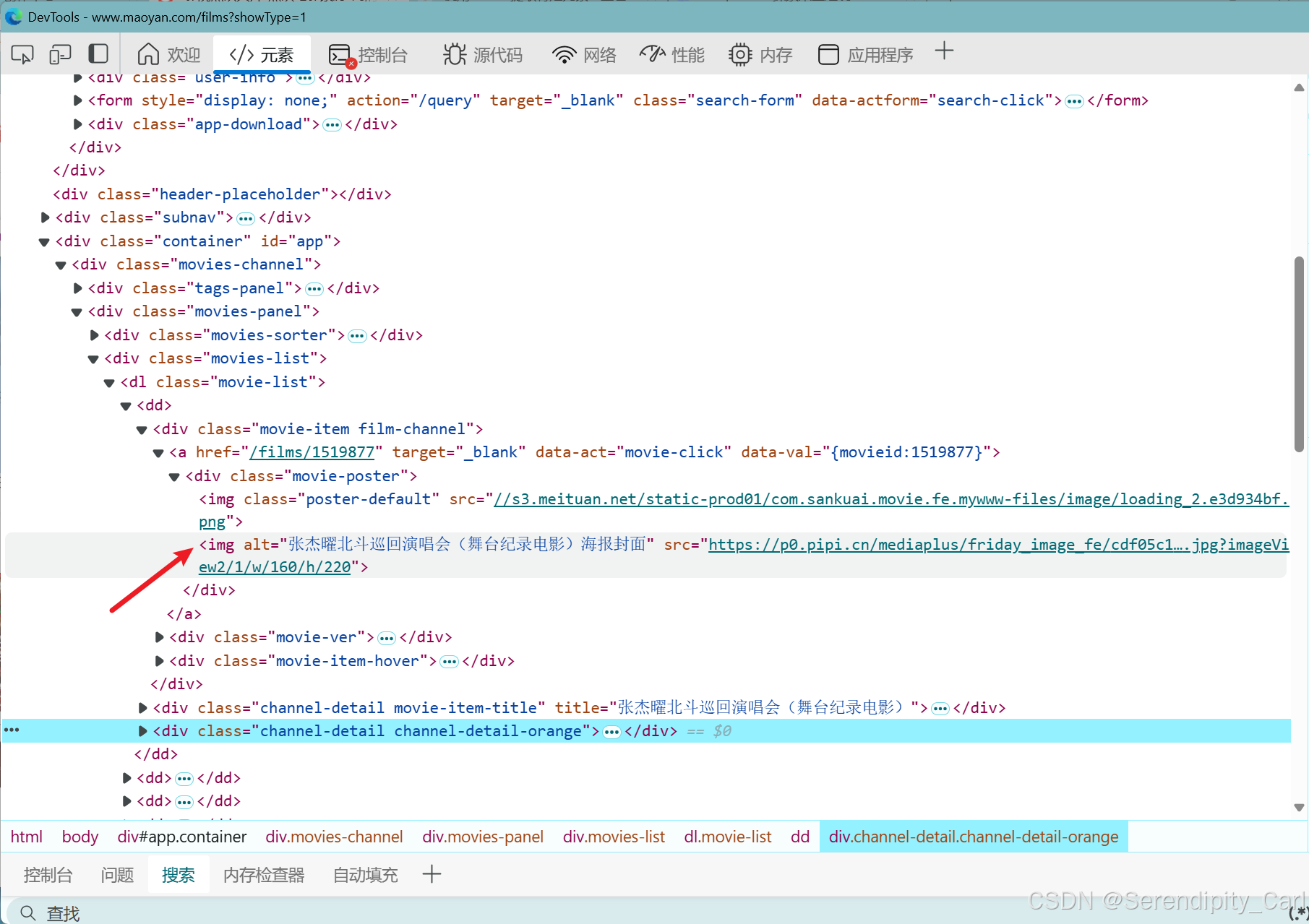
我试了 xpath css语法都提取不到 只能定位到第一个img标签 定位到第二个标签返回的值是None 大家也可以试试
这里我采用的是正则来提取
import re # 正则的基本用法这里就不讲了 obj = re.compile(r']*alt=".*?"[^>]*src="([^"]+)"', re.S) result = obj.findall(resp.text) # ]*:再次匹配
以外的任意字符零次或多次。 # src="([^"]+)":匹配 src 属性,并将属性值(双引号内的内容)捕获到一个分组中
OK 所有的数据提取完毕 我们开始存储数据
在外面定义多个列表 将后面拿到的数据添加进去
# 存储数据 names = [] types = [] judges = [] actor = [] date = [] img = [] dit = {} #通过字典保存 dit = { 'movie_name': names, 'movie_type': types, 'movie_judge': judges, 'movie_actor': actor, 'movie_date': date, 'movie_img': result, }保存到excel 文件
import pandas as pd pd.DataFrame(dit).to_excel('maoyan.xlsx', index=False)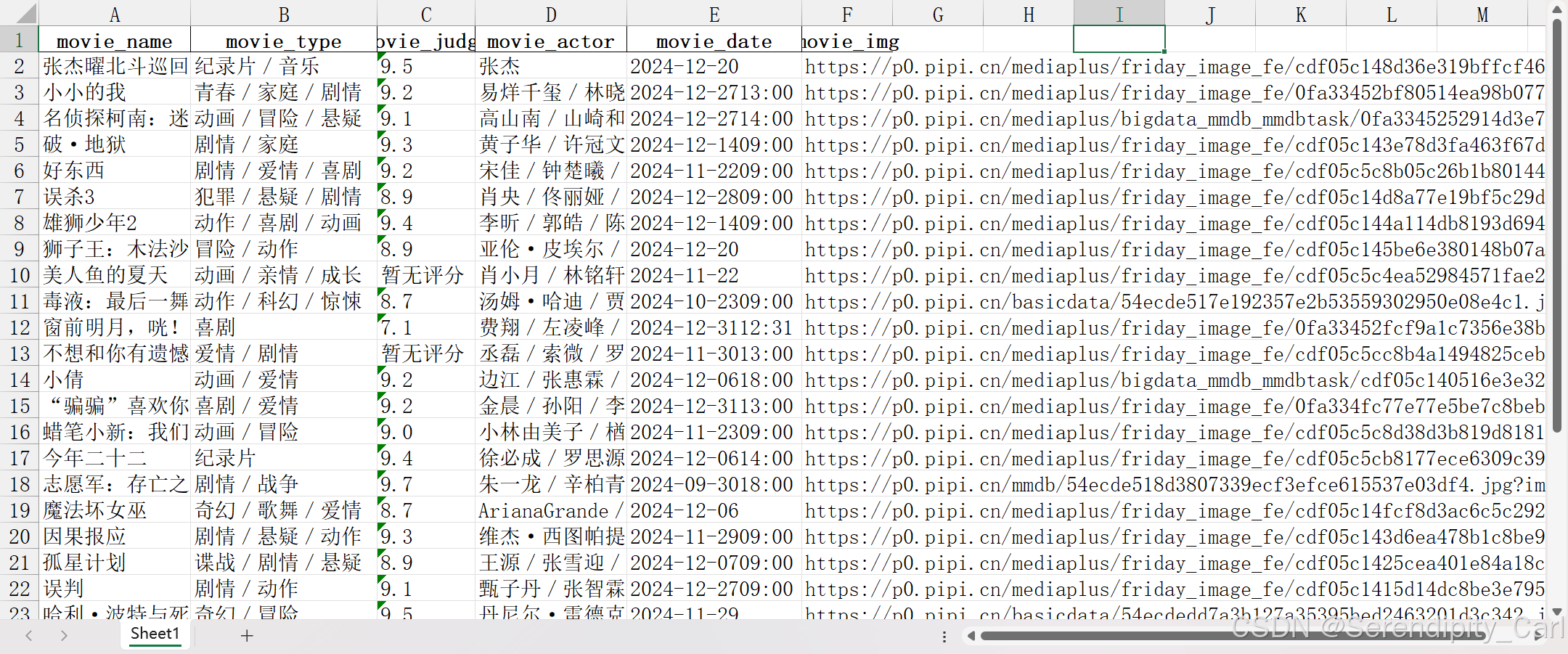
以下是本次案例的源代码 供大家学习交流使用
import requests import re import parsel import pandas as pd # 多线程 from concurrent.futures import ThreadPoolExecutor # lore: \s* 匹配换行符/空格 # 明确需求 爬取猫眼电影的名称 评分 上映时间 类型 海报封面 url = 'https://www.maoyan.com/films?showType=1' # 构建请求头 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0', 'referer': 'https://www.maoyan.com/', 'cookie': '__mta=20748807.1740552803025.1740552852891.1740553459209.5; _lxsdk_cuid=1952d815b15c8-095f4f6bbe1232-4c657b58-151800-1952d815b15c8; uuid_n_v=v1; uuid=5E3250D0F40E11EF8582A78FDB0EB2A0051CB02A0E364A0C977864131D122F13; _csrf=a68383b2e6e434edea900c20c6c5d6ad645d41c772092915f290fe259e55e398; Hm_lvt_e0bacf12e04a7bd88ddbd9c74ef2b533=1740552802; HMACCOUNT=2EDE6B4FF192C403; _ga=GA1.1.867036656.1740552802; _lx_utm=utm_source%3Dbing%26utm_medium%3Dorganic; WEBDFPID=58xx98v469465uv3y66v59v88yy98v0y8045813wuv6979583yww167y-1740647512079-1740561111328OEGMGMCfd79fef3d01d5e9aadc18ccd4d0c95071984; token=AgEyHoSEqqppGVJ50PG4dG98WTCprBLpuzpXkMuYU-anXvJY6VEwhQd4dU93RH01NvU2i-uHUpZB2AAAAAD5JgAAD3Km4Hf_ZtErwXEqVNkQPHJrXeNeP_shAZEetBNSKhFwCL6CXHShQnRjINSHJcYY; uid=3250425522; uid.sig=7IU-d9HAhwkljMMMbUi4hTXWclk; _lxsdk=5E3250D0F40E11EF8582A78FDB0EB2A0051CB02A0E364A0C977864131D122F13; Hm_lpvt_e0bacf12e04a7bd88ddbd9c74ef2b533=1740573120; _ga_WN80P4PSY7=GS1.1.1740573119.4.1.1740573119.0.0.0; __mta=20748807.1740552803025.1740553459209.1740573120838.6; _lxsdk_s=195423e118c-e0a-f42-8d7%7C3250425522%7C3' } # 模拟浏览器向服务器发送请求 resp = requests.get(url, headers=headers) # 解析数据 均采用re模块采取 目的是练习 提取的语法 即提高熟练度 # 提取电影评分的时候 整数和小数是分开的 拿到数据之后需要做一个字符串的合并 obj = re.compile(r'.*?)">.*?' r'.*?(?P.*?).*?' r'(?P.*?).*?' , re.S) # ?P # \s*\s*(.*?)\s* result = obj.finditer(resp.text) pattern = r'\s*\s*(.*?)\s*' result2 = re.compile(pattern).findall(resp.text) # \s*\s*(.*?)\s* # 存储到字典里面 # for i in result: # dit = i.groupdict() # all_dit = { # 'name': dit.get('name') or '', # 'judg': dit.get('judg') or '0', # 'e': dit.get('e') or '0', # } # judge = all_dit['judg'] + all_dit['e'] # parsel模块解析 数据 selector = parsel.Selector(resp.text) lis = selector.css('.movie-item-hover') name_lis = selector.css('.movie-list dd') num_lis = selector.css('.channel-detail.channel-detail-orange') # 存储数据 names = [] types = [] judges = [] actor = [] date = [] img = [] dit = {} # movie-list for j in lis: # 处理得到的数据 # 电影的类型 movie_type = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-3].strip() # 电影的演员 movie_actor = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-2].strip() # 电影上映的日期 movie_date = ''.join(j.css('.movie-hover-title::text').getall()).replace(' ', '').split('\n\n')[-1].strip() types.append(movie_type) actor.append(movie_actor) date.append(movie_date) for i in name_lis: # 获取电影的名字 name = i.css('.channel-detail.movie-item-title::attr(title)').get() names.append(name) # 获取海报的标签 src属性 div 下面的第二个img标签提取不出来 换别的解析方法 # 采用re模块 提取海报的url地址 # ]*:再次匹配以外的任意字符零次或多次。 # src="([^"]+)":匹配 src 属性,并将属性值(双引号内的内容)捕获到一个分组中。 obj = re.compile(r']*alt=".*?"[^>]*src="([^"]+)"', re.S) result = obj.findall(resp.text) img.append(result) # 单独处理 评分 判断div标签下面有i标签时则提取 没有则 for k in num_lis: if k.css('i'): judge = k.css('::text').get() judge2 = k.css('i:nth-of-type(2)::text').get() # 合并评分 judge_fi = judge + judge2 else: judge_fi = k.css('::text').get() judges.append(judge_fi) dit = { 'movie_name': names, 'movie_type': types, 'movie_judge': judges, 'movie_actor': actor, 'movie_date': date, 'movie_img': result, } pd.DataFrame(dit).to_excel('maoyan.xlsx', index=False)
本次的案例分析就到此结束啦 谢谢大家的观看 你的点赞和关注是我更新的最大动力
如果感兴趣的话可以看看我之前的博客







