
Qwen-3 微调实战:用 Python 和 Unsloth 打造专属 AI 模型

虽然大家都忙着在 DeepSeek 上构建应用,但那些聪明的开发者们却悄悄发现了 Qwen-3 的微调功能,这可是一个隐藏的宝藏,能把通用型 AI 变成你的专属数字专家。
通过这篇文章,你将学到如何针对特定用途微调最新的 Qwen-3 模型。无论是刚刚踏入 AI 领域的初学者,还是经验丰富的 AI 工程师,这篇文章都有适合你的内容。

Qwen3 很快就成为了大多数开发者的首选。它之所以如此受欢迎,是因为它在编码、数学、通用能力等竞争性评估中获得的基准分数。
这些基准分数超过了主要的 LLM,包括 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等模型。此外,小 MoE 模型 Qwen3–30B-A3B 在激活参数数量上是 Qwen-32B 的 10 倍,甚至一个像 Qwen3–4B 这样的小模型也能与 Qwen2.5–72B-Instruct 的性能相媲美。
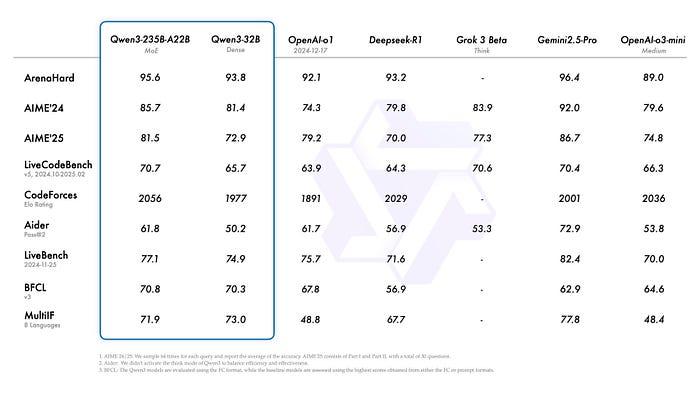
Qwen-3 模型基准
你可以从 这里 了解更多关于基准及其在特定任务中的表现。
在这篇文章中,你将深入了解如何使用 Python 和 Unsloth 对 Qwen-3 模型进行微调。
尽管微调是一个计算成本高昂的任务,但这篇文章通过使用 Google 的 Colab Notebook,尽量使其变得易于访问。
条件和设置
让我们先了解微调 Qwen-3 需要什么。这包括技术要求和设置要求的简要介绍。
Python库和框架
以下是微调 Qwen-3 模型所需的 Python 库和框架:
- unsloth,这个包能让像 Llama-3、Mistral、Gemma 和 Qwen 这样的大型语言模型的微调速度翻倍,内存使用减少 70%,而且不会降低准确性!你可以在这里了解更多 详情。
- torch,这个包是使用 PyTorch 进行深度学习的基础。它提供了一个强大的张量库,类似于 NumPy,但增加了 GPU 加速的优势,这对于处理 LLM 来说至关重要。
- transformers 是一个强大且流行的开源自然语言处理(NLP)库。它为各种最先进的预训练模型提供了易于使用的接口。由于预训练模型是任何微调任务的基础,这个包有助于轻松访问训练好的模型。
- trl 包是一个专门用于 强化学习(Reinforcement Learning, RL) 与变换器模型的 Python 库。它基于 Hugging Face 的 transformers 库构建,利用其优势,使变换器的强化学习更加易于访问和高效。
计算需求
微调大型语言模型(LLM)是一种技术,可以在不进行完整(参数)训练的情况下,使模型的响应更加结构化和特定于领域。
然而,对于大多数普通计算机硬件来说,微调大型 LLM 仍然不可行,因为所有的可训练参数以及实际的 LLM 都存储在 GPU 的 vRAM(虚拟 RAM)中,而 LLM 的巨大尺寸是实现这一目标的主要障碍。
因此,为了这篇文章,我们将微调 Qwen-3 的量化版本,该版本有 80 亿参数。这个 LLM 需要大约 8-12 GB 的 vRAM,为了使所有学习者都能访问,我们将使用 Google Colab 的免费 T4 GPU,它有 15 GB 的 vRAM。
数据准备策略
对于微调 LLM,我们需要结构化和特定于任务的数据。有许多数据准备策略,无论是从社交媒体平台、网站、书籍还是研究论文中抓取数据。
对于微调我们的 Qwen-3 模型,我们将使用推理数据集和通用聊天交互数据集。这样,我们将为我们的 LLM 赋予增强的推理能力和改进的提示理解能力。
这两个数据集将从开源的 Hugging Face Hub 加载。我们将使用 unsloth/OpenMathReasoning-mini 和 mlabonne/FineTome-100k 数据集。
在这里,unsloth/OpenMathReasoning-mini 将增强我们模型的推理和解决问题的能力,而 mlabonne/FineTome-100k 将提高通用对话能力。
Python实现
安装包
你需要在你的内核中运行以下命令:
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl==0.15.2 triton cut_cross_entropy unsloth_zoo !pip install sentencepiece protobuf datasets huggingface_hub hf_transfer !pip install --no-deps unsloth
如果你有一个强大的 GPU 并且愿意在本地机器上进行微调任务,那么这个过程相当简单。要安装这个包,只需在你的终端中运行以下命令:
!pip install unsloth
初始化 LLM 模型及其分词器
我们将使用 unsloth 包来加载预训练模型。除了更快的下载速度外,它还提供了有助于微调 LLM 的有用技术。
初始化模型和分词器的代码如下:
from unsloth import FastLanguageModel import torch model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Qwen3-8B-unsloth-bnb-4bit", max_seq_length = 2048, # 上下文长度 load_in_4bit = True, # 4bit 使用更少的内存 load_in_8bit = False, # 稍微更准确,但内存使用量翻倍 full_finetuning = False, # 现在我们已经可以进行全微调了! # token = "", # 如果使用受限制的模型 )- 我们正在从 Hugging Face Hub 使用 FastModel.from_pretrained() 方法加载预训练的 Qwen3–8B 模型。
- 第一个参数是 model_name,即 unsloth/Qwen3–8B-unsloth-bnb-4bit,这是 Qwen-3 模型的 80 亿参数 版本,非常适合我们的需求。
- 通过设置 max_seq_length,我们可以处理模型的 序列长度,允许模型处理 2048 个标记的输入序列。它也会影响模型的性能、内存使用和准确性。
- load_in_4bit 参数用于将模型量化为 4 位精度,以减少内存使用量,而你可以将 load_in_8bit 设置为 True(如果你的 GPU 支持),因为它会提高准确性,但内存成本会增加一倍。
- full_finetuning 标志设置为 False,这使得我们能够进行 参数高效的微调(PEFT),而不是更新所有模型参数。
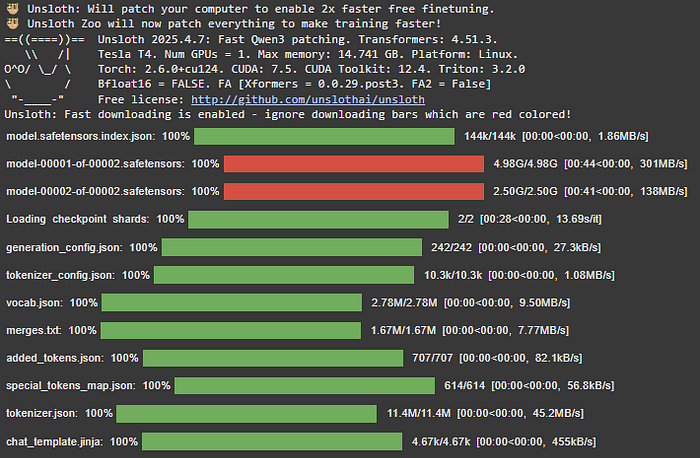
初始化 Qwen-3 模型和分词器
添加 LoRA 适配器
我们将为预训练的 Qwen-3 模型添加 LoRA 矩阵,这将有助于微调模型的响应。使用 unsloth,整个过程只需要几行代码。
代码如下:
model = FastLanguageModel.get_peft_model( model, r = 32, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 64, lora_dropout = 0, bias = "none", use_gradient_checkpointing = "unsloth", # True 或 "unsloth" 用于非常长的上下文 random_state = 3433, )代码解释:
- FastModel.get_peft_model() 方法将 参数高效的微调(PEFT) 应用于我们刚刚初始化的 Qwen-3 基础模型,以实现高效的适应。
- r 参数(秩)控制 LoRA 适应矩阵 的大小,值越高可以提高准确性,但可能会导致过拟合。lora_alpha 作为缩放因子,通常设置为 r 的相等或两倍。
- 我们将 lora_dropout 设置为 0,表示不应用 dropout,bias="none" 表示我们不微调偏置。
- 设置 random_state=3433 就像给新模型留下了一个指纹,确保在微调过程中结果的一致性和可重复性。
数据准备
现在,我们已经在预训练的 Qwen-3 模型上设置了 LoRA 适配器。接下来,我们可以开始准备用于训练模型的数据。
我们将使用 unsloth/OpenMathReasoning-mini 和 mlabonne/FineTome-100k 数据集来微调模型,并从 Hugging Face 加载数据集。
加载数据集的代码如下:
from datasets import load_dataset reasoning_dataset = load_dataset("unsloth/OpenMathReasoning-mini", split = "cot") non_reasoning_dataset = load_dataset("mlabonne/FineTome-100k", split = "train")在这里,数据集 unsloth/OpenMathReasoning-mini 将用于增强 LLM 的推理能力,为此,我们只需要数据的 COT(Chain-Of-Thought,思维链)部分。
现在,我们需要将数据结构标准化,以匹配聊天式微调的预期格式,例如处理“用户”和“助手”的角色。这一步也可以用于生成对话式的输入,以便将查询传递给数据集中的问题。这样,我们就可以对齐实际传递给 LLM 的查询方式。
标准化数据集的代码如下:
def generate_conversation(examples): problems = examples["problem"] solutions = examples["generated_solution"] conversations = [] for problem, solution in zip(problems, solutions): conversations.append([ {"role" : "user", "content" : problem}, {"role" : "assistant", "content" : solution}, ]) return { "conversations": conversations, }这个函数 generate_conversation 将单独的查询及其各自的解决方案转换为对话,包含用户和助手的响应。
现在,我们需要将这个函数映射到实际的数据集上,代码如下:
reasoning_conversations = tokenizer.apply_chat_template( reasoning_dataset.map(generate_conversation, batched = True)["conversations"], tokenize = False, )现在,我们还需要处理我们加载的非推理数据集。为此,我们将使用 UnSloth 聊天模板库中的 standardize_sharegpt 函数来修正数据集的格式。
from unsloth.chat_templates import standardize_sharegpt dataset = standardize_sharegpt(non_reasoning_dataset) non_reasoning_conversations = tokenizer.apply_chat_template( dataset["conversations"], tokenize = False, )数据比例
现在我们已经准备好了两个数据集,通常这个时候就可以开始训练模型了。但我们还应该考虑模型的 聊天与推理比例。
较高的聊天比例会优先考虑对话的流畅性和一般知识,而较高的推理比例则强调逻辑推理和解决问题的能力。在这两者之间取得平衡对于创建一个既能进行有趣对话又能解决复杂任务的多功能模型至关重要。
在本文中,我们假设我们想要一个聊天模型,因此我们将聊天部分设置为 70%,推理部分设置为 30%。实现方法如下:
import pandas as pd # 定义聊天部分的比例 chat_percentage = 0.7 # 按照比例对非推理数据集进行采样 non_reasoning_subset = pd.Series(non_reasoning_conversations) non_reasoning_subset = non_reasoning_subset.sample( int(len(reasoning_conversations) * (1.0 - chat_percentage)), random_state = 2407, )现在,我们在数据准备过程中的最后一步是将两个数据集合并,代码如下:
data = pd.concat([ pd.Series(reasoning_conversations), pd.Series(non_reasoning_subset) ]) data.name = "text" from datasets import Dataset combined_dataset = Dataset.from_pandas(pd.DataFrame(data)) combined_dataset = combined_dataset.shuffle(seed = 3407)训练
现在我们已经准备好了结构化的数据和带有 LoRA 适配器或矩阵的模型,我们可以开始训练模型了。
为了训练模型,我们需要初始化一些超参数,这些参数将有助于训练过程,并且会在一定程度上影响模型的准确性。
我们将使用 SFTTrainer 初始化一个 trainer,并设置超参数。
from trl import SFTTrainer, SFTConfig trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = combined_dataset, # 结构化的数据集 eval_dataset = None, args = SFTConfig( dataset_text_field = "text", # 数据集中用于训练的结构化字段 per_device_train_batch_size = 2, # 每个设备每个批次处理的样本数量 gradient_accumulation_steps = 4, # 在执行反向传播之前累积梯度的步数 warmup_steps = 5, # 训练开始时逐步增加学习率的步数 # num_train_epochs = 1, # 设置为 1 以进行完整的训练运行 max_steps = 30, # 要执行的总训练步数 learning_rate = 2e-4, # 训练期间更新权重的学习率 logging_steps = 1, # 训练指标记录的频率(以步数为单位) optim = "adamw_8bit", # 优化器 weight_decay = 0.01, # 用于防止过拟合的正则化 lr_scheduler_type = "linear", # 用于控制学习率衰减 seed = 3407, report_to = "none", # 用于记录指标的平台,也可以是 'wandb' ), )代码解释:
- SFTTrainer 是 trl 库中用于在自定义数据集上微调大型语言模型的工具。它提供了诸如梯度累积、混合精度优化等技术,非常适合指令微调、对话生成以及特定领域的 LLM 适应等任务。
- 在 SFTTrainer 中,我们传入了模型、分词器和我们刚刚准备好的训练数据集,并将评估数据集设置为 None,以满足我们的用例。
现在,我们已经完成了所有设置,模型已经准备好开始训练。开始训练的代码如下:
trainer_stats = trainer.train()
这将在每个训练步骤中在内核中打印训练损失,如下所示:
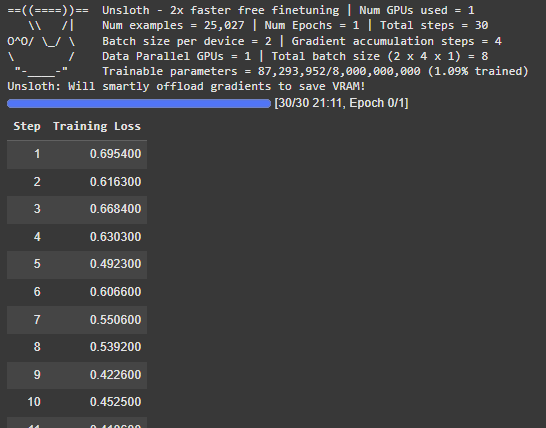
训练带有 LoRA 适配器的 Qwen3 模型
推理
现在我们已经完成了模型的训练,接下来只需要对微调后的模型进行推理,以评估其响应。
有两种方法可以对模型进行推理,一种是启用思考,另一种是禁用思考。
不思考模式
禁用思考时对模型进行推理的代码如下:
messages = [ {"role" : "user", "content" : "Solve (x + 2)^2 = 0."} ] text = tokenizer.apply_chat_template( messages, tokenize = False, add_generation_prompt = True, # 必须添加以进行生成 enable_thinking = False, # 禁用思考 ) from transformers import TextStreamer _ = model.generate( **tokenizer(text, return_tensors = "pt").to("cuda"), max_new_tokens = 256, # 增加此值以获得更长的输出 temperature = 0.7, top_p = 0.8, top_k = 20, streamer = TextStreamer(tokenizer, skip_prompt = True), )- 在这里,为了对模型进行推理,我们初始化分词器以处理 Qwen3 聊天格式/模板中的对话。
- 在将 chat_template 应用于消息(输入)时,我们明确指定了模型在响应时不进行思考。
- max_new_token 设置为 256,你可以根据需要调整此值以获得更长的输出。
此推理的输出如下:

禁用思考时微调后的 Qwen-3 模型的推理输出。
如果图片不太清晰,以下是文字版的输出内容:
To solve the equation (x + 2)² =0, we can take the square root of the both sides. This gives us x+2 = 0. Then, we can subtract 2 from both sides to get x = -2.
思考模式
我们刚刚看到,当告诉模型不进行思考时,模型直接给出了答案,这正是我们所期望的!
禁用思考的方法既有优点也有缺点,因为它虽然减少了计算需求并加快了输出生成速度,但对于解决复杂问题来说并不可靠——在那种情况下,我们需要模型进行思考。
要启用思考以进行响应,我们需要按照以下方式操作:
messages = [ {"role" : "user", "content" : "Solve (x + 2)^2 = 0."} ] text = tokenizer.apply_chat_template( messages, tokenize = False, add_generation_prompt = True, # 必须添加以进行生成 enable_thinking = True, # 启用思考 ) from transformers import TextStreamer _ = model.generate( **tokenizer(text, return_tensors = "pt").to("cuda"), max_new_tokens = 1024, # 增加此值以获得更长的输出 temperature = 0.6, top_p = 0.95, top_k = 20, streamer = TextStreamer(tokenizer, skip_prompt = True), )- 在这里,我们修改了 enable_thinking 标志。
- 我们将 max_new_token 的数量增加到了 1024,你可以根据对问题的思考来调整这个值。
上述推理的输出如下:
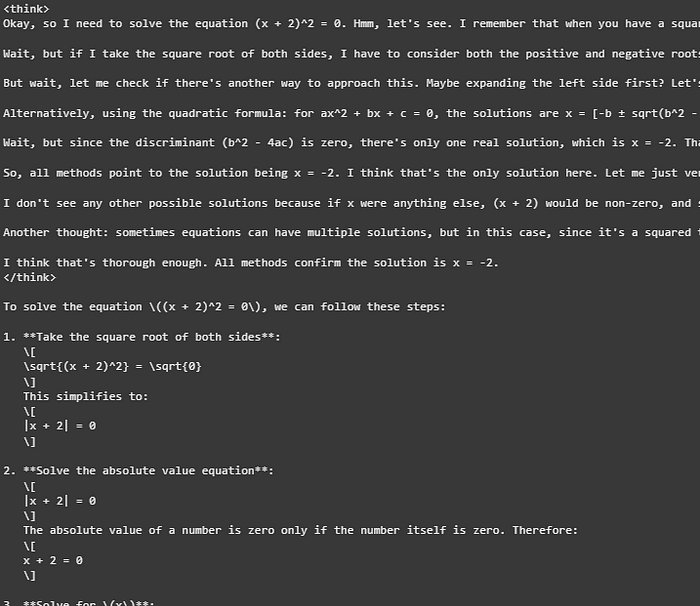
启用思考时微调后的 Qwen-3 模型的推理输出。
在这里,我们可以看到模型为了回答这样一个简单的问题所达到的深度。而且,那些 标签也可见。
保存模型
这一步完成了整个微调模型的过程,现在我们可以保存微调后的模型,以便进行推理或在未来使用。
我们还需要将分词器与模型一起保存。以下是将完整的(合并后的)微调模型保存到本地系统的方法:
model.save_pretrained_merged("Qwen3-16bit-OpenMathReasoning-Finetuned-Merged", tokenizer, save_method = "merged_16bit")- 在这里,我们将微调后的模型命名为 Qwen3–16bit-OpenMathReasoning-Finetuned-Merged,但你可以选择自己的名称。
总结
- 大型语言模型,简单来说,就是深度学习架构(如 Transformer)的一个漂亮实现,它被大量语言文本数据喂养或训练。
- Qwen3 通过在许多现有的最佳大型语言模型中脱颖而出,包括 DeepSeek-R1、o1、Gemini-2.5-pro 等,占据了竞争地位。
- 微调 LLM 是一个过程,即向模型提供一些特定于任务的数据,以量身定制其响应,从而提高其准确性,并使其响应更加专门化和特定于领域。
- chat_template 表示用于标记多轮对话的骨架,以确保模型正确区分系统、用户和助手消息。
- 我们使用的主要 Python 库和框架是 unsloth、torch、transformers 和 trl。此外,我们还讨论了微调 LLM 的计算要求。
- 我们对数据集进行了结构化,以便有效地微调模型,然后使用 SFTTrainer 进行了训练。
- 我们还将 LoRA 适配器或矩阵与预训练模型合并
Today’s Inspiration
“有人今天坐在树荫下,是因为很久以前有人种下了一棵树。” —— 沃伦·巴菲特
- 在这里,我们将微调后的模型命名为 Qwen3–16bit-OpenMathReasoning-Finetuned-Merged,但你可以选择自己的名称。



