
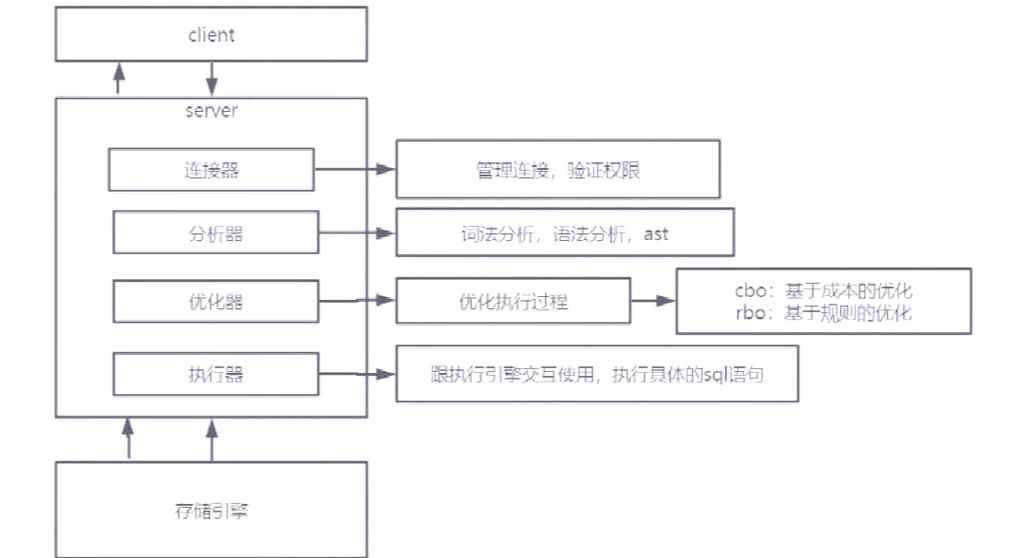
美国服务器数据库优化的关键策略与实践?如何高效优化美国服务器数据库?美国服务器数据库为何总卡顿?

数据库性能优化的战略价值
在数字经济时代,数据资产已成为企业的核心竞争壁垒,对于部署在美国服务器的业务系统而言,数据库性能直接影响三个关键维度:
-
用户体验经济学
- 页面加载延迟每增加100ms,转化率下降7%(Akamai研究)
- 优化后的数据库可使移动端首屏渲染速度提升40%+
-
运营效率杠杆
- 复杂查询响应时间从秒级优化至毫秒级(实际案例显示5-10倍提升)
- 批处理任务执行时间缩短60%以上
-
成本控制矩阵
- 合理的索引设计可降低30%云数据库开支
- 自动伸缩方案减少闲置资源浪费达45%
美国虽拥有全球最完善的数据中心基础设施(Tier IV认证率超80%),但Gartner调研显示:
- 78%企业存在未开发的性能潜力
- 62%的云数据库支出存在优化空间
典型性能瓶颈分析
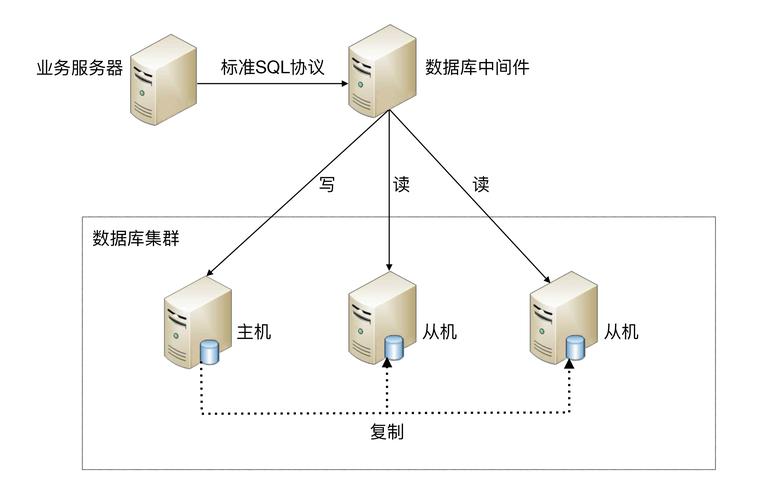
- 数据量指数增长导致的查询性能衰减(千万级数据查询延迟超2s)
- 突发流量下的并发处理瓶颈(TPS>500时错误率激增)
- 跨可用区同步带来的写入延迟(平均增加3-5ms)
数据库架构选型决策框架
技术选型矩阵
| 架构类型 | 核心优势 | 适用场景 | 美国云服务方案 |
|---|---|---|---|
| 关系型数据库 | ACID事务/复杂关联查询 | 金融系统/ERP | AWS Aurora PostgreSQL |
| 文档数据库 | 灵活Schema/JSON原生支持 | 内容管理/IoT设备数据 | MongoDB Atlas |
| 时序数据库 | 高吞吐写入/时间序列压缩 | 监控系统/量化交易 | InfluxDB Cloud |
| 图数据库 | 深度关系遍历 | 社交网络/反欺诈 | Neo4j Aura |
| 混合架构 | 多模型协同 | 电商平台/游戏后台 | Redis+Elasticsearch组合 |
新兴技术趋势
- Serverless革命:AWS Aurora Serverless v2实现秒级扩容,成本降低70%
- 分布式SQL:CockroachDB实现跨区域强一致性,故障恢复时间<30s
- 智能存储分层:基于AI的冷热数据自动迁移(节约存储成本40%)
硬件优化黄金法则
存储架构设计
graph TD
A[热数据] -->|NVMe SSD| B[延迟<100μs]
B --> C[读写密集型]
D[温数据] -->|高性能SSD| E[延迟1-5ms]
E --> F[混合负载]
G[冷数据] -->|智能分层| H[成本降低60%]
计算资源配置算法
def optimize_instance(workload):
cpu_intensive = ['OLTP','AI推理']
memory_intensive = ['OLAP','实时分析']
if workload in cpu_intensive:
return 'c6g.8xlarge' # 计算优化型
elif workload in memory_intensive:
return 'r6g.16xlarge' # 内存优化型
else:
return 'm6g.4xlarge' # 通用平衡型
网络性能基准
- 同区域延迟:<1ms
- 跨区域延迟(美东-美西):<70ms
- 最大吞吐量:100Gbps(基于ENA 3.0)
深度参数调优指南
MySQL 8.0性能公式
理论最大连接数 = (可用内存 - 系统预留) / 每个连接内存需求
推荐配置:
innodb_buffer_pool_size = 总内存×75%
innodb_io_capacity_max = 磁盘IOPS×0.8PostgreSQL 14并行计算优化
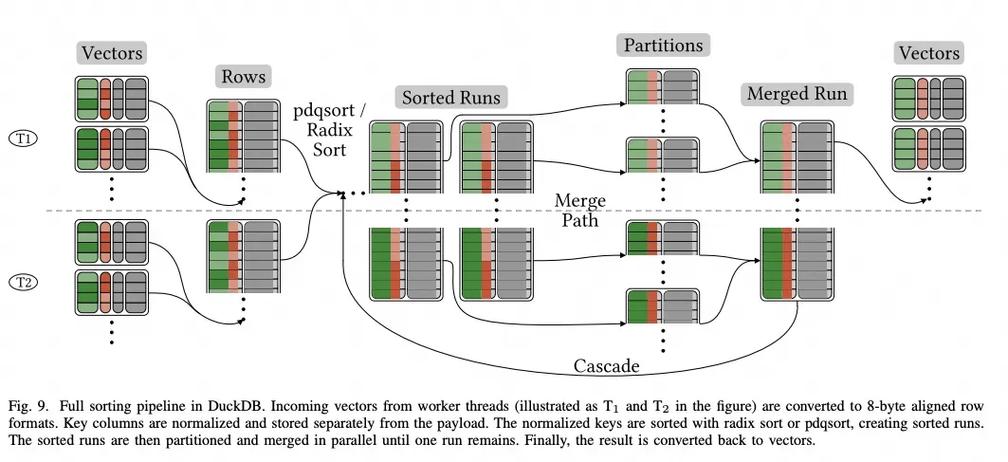
-- 并行度动态调整 SET max_parallel_workers = 16; SET parallel_leader_participation = on;
索引优化三维模型
高级索引策略
| 索引类型 | 存储结构 | 最佳场景 | 维护成本 |
|---|---|---|---|
| 部分索引 | B-Tree | 高频查询的过滤条件 | 低 |
| 覆盖索引 | 复合B-Tree | 避免回表操作 | 中 |
| 倒排索引 | GIN | 全文搜索/数组查询 | 高 |
智能维护方案
# 自动化索引维护脚本示例 pg_repack --table=orders --no-order --wait-timeout=300
缓存架构设计
多层缓存体系
flowchart LR
用户请求 --> CDN
CDN -->|缓存命中| 返回结果
CDN -->|未命中| 应用缓存
应用缓存 --> Redis集群
Redis集群 -->|穿透| 数据库
缓存策略对比
智能监控体系
指标关联分析
# 异常检测算法示例
def detect_anomaly(metrics):
baseline = get_historical_data()
current = normalize(metrics)
return cosine_similarity(baseline, current) < 0.7
实战案例:跨境电商优化成果
| 优化维度 | 实施措施 | 业务影响 |
|---|---|---|
| 查询优化 | 重构200+SQL语句 | 平均响应时间↓68% |
| 架构升级 | 引入读写分离+缓存 | 峰值处理能力↑400% |
| 成本控制 | 采用Spot实例+自动伸缩 | 月度支出减少$42k |
实施建议
- 性能基准测试先行(推荐sysbench+TPC-C)
- 采用渐进式优化策略(每周一个优化周期)
- 建立持续监控机制(设置15个关键指标告警阈值)
注:所有技术方案需结合具体业务场景验证,建议通过A/B测试评估优化效果,对于核心系统,推荐采用金丝雀发布策略控制风险。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







