
Ollama + Open WebUI 本地部署DeepSeek

文章目录
- 前言
- 一、环境准备
- 最低系统要求
- 必要软件
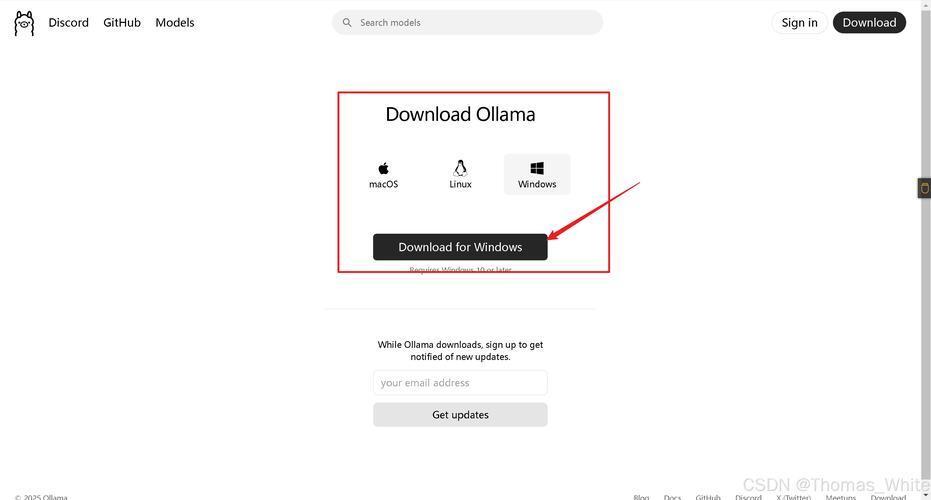
- 二、安装 Ollama
- 通过 Docker 部署
- 验证安装
- 三、部署 Open WebUI
- 快速启动
- 配置说明
- 四、加载 DeepSeek 模型
- 通过 Ollama 拉取模型
- 支持模型列表
- 五、使用 Web 界面交互
- 首次使用
- 功能特性
- 六、高级配置
- GPU 加速(NVIDIA)
- 多模型管理
- 七、常见问题
- 模型加载失败
- WebUI 无法连接 Ollama
- 八、安全建议
- 总结
前言
由于官网的deepseek经常问一个问题回答后经常处于繁忙状态,所以为了避免这种情况我们可以自己在本地部署个deepseek进行使用,我们可以本地使用Ollama和Open WebUI部署DeepSeek模型。deepseek模型有多个版本,相应对配置要求也不一样,要想获得最好的体验,这需要非常高的配置。
一、环境准备
最低系统要求
组件 要求 操作系统 Windows 10/11, macOS 12+, Ubuntu 20.04+ 处理器 支持 AVX2 的 x86_64 CPU(Intel/AMD) 内存 16GB(7B 模型) / 32GB+(更大模型) 存储 至少 50GB 可用空间 GPU(可选) NVIDIA GPU(需 CUDA 11+) 必要软件
-
Docker Desktop
官方下载地址
安装后需启用 Linux 容器(Windows)并分配至少 8GB 内存
-
Git(可选)
用于克隆 Open WebUI 仓库:
sudo apt install git # Ubuntu brew install git # macOS
二、安装 Ollama
通过 Docker 部署
# 创建持久化存储卷 docker volume create ollama_data # 启动 Ollama 容器 docker run -d \ --name ollama \ -p 11434:11434 \ -v ollama_data:/root/.ollama \ --restart unless-stopped \ ollama/ollama
验证安装
docker logs ollama | grep "Listening" # 应显示:Listening on [::]:11434
三、部署 Open WebUI
快速启动
docker run -d \ --name open-webui \ -p 3000:8080 \ -e OLLAMA_API_BASE_URL=http://host.docker.internal:11434 \ -v open-webui:/app/backend/data \ --restart unless-stopped \ ghcr.io/open-webui/open-webui:main
配置说明
- OLLAMA_API_BASE_URL: Ollama 服务的地址
- -v open-webui:/app/backend/data: 持久化聊天记录和用户数据
- 访问地址:http://localhost:3000
四、加载 DeepSeek 模型
通过 Ollama 拉取模型
# 查看可用模型 curl http://localhost:11434/api/tags # 拉取 DeepSeek 模型(示例) docker exec ollama ollama pull deepseek-ai/deepseek-math-7b-base
支持模型列表
模型名称 大小 推荐配置 deepseek-7b 13GB 16GB RAM deepseek-math-7b 13GB 16GB RAM deepseek-coder-7b 13GB 16GB RAM 五、使用 Web 界面交互
首次使用
- 访问 http://localhost:3000
- 创建账户(首次会自动注册管理员账户)
- 在模型选择栏选择已加载的 DeepSeek 模型
功能特性
- 对话模式:支持多轮上下文对话
- 参数调整:
temperature: 0.7 # 控制随机性 (0-1) top_p: 0.9 # 输出多样性 max_tokens: 2048 # 最大生成长度
- 文件上传:支持 PDF/TXT 文件分析
- 提示词库:内置常用提示模板
六、高级配置
GPU 加速(NVIDIA)
# 先安装 NVIDIA 容器工具包 distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # 重启容器时添加 GPU 支持 docker run --gpus all -d ... ollama/ollama多模型管理
# 查看已下载模型 docker exec ollama ollama list # 删除模型 docker exec ollama ollama rm deepseek-7b
七、常见问题
模型加载失败
现象:Error: insufficient memory
解决:
- 调整 Docker 内存限制至 16GB+
- 使用量化模型(添加 -q4 后缀):
ollama pull deepseek-7b-q4_0
WebUI 无法连接 Ollama
- 检查容器网络:
docker network inspect bridge
- 测试 API 连通性:
curl http://host.docker.internal:11434/api/tags
八、安全建议
-
身份验证
在 Open WebUI 的启动命令中添加:
-e WEBUI_SECRET_KEY=your_secure_key
-
网络隔离
使用自定义 Docker 网络:
docker network create ai-net docker run --network ai-net ... ollama/ollama docker run --network ai-net ... open-webui
-
防火墙规则
仅允许本地访问:
ufw allow from 127.0.0.1 to any port 3000
总结
通过本教程,您已经实现了:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 基于 Docker 的 Ollama 服务部署
- Open WebUI 可视化界面搭建
- DeepSeek 系列模型的加载与测试
扩展建议:
- 结合 LangChain 构建复杂 AI 应用
- 使用 NGINX 添加 HTTPS 支持
- 配置定时模型更新任务(需修改 Ollama 容器)
如需更新 Open WebUI,运行:
 (图片来源网络,侵删)
(图片来源网络,侵删)docker compose pull open-webui && docker compose up -d
官方文档参考 | Ollama 模型库
 (图片来源网络,侵删)
(图片来源网络,侵删)
-
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



