
Linux NUMA 内存管理,原理、优化与实践?NUMA内存管理如何优化性能?NUMA内存为何拖慢性能?

NUMA架构的兴起背景
在多核处理器成为主流的今天,非一致性内存访问(Non-Uniform Memory Access, NUMA)架构已逐步取代传统的对称多处理(Symmetric Multiprocessing, SMP)架构,当CPU核心数量突破32核时,SMP架构的集中式内存总线设计会导致显著的带宽争用问题,形成性能瓶颈。
NUMA架构通过创新的分布式内存设计,将CPU和内存资源划分为多个逻辑节点(Node),每个节点包含:
- 一组CPU核心
- 本地内存控制器
- 高速缓存子系统
这种设计使得每个CPU可以优先访问低延迟的本地内存(Local Memory),而远程内存(Remote Memory)访问则通过高速互联总线(如Intel的Ultra Path Interconnect/UPI或AMD的Infinity Fabric)实现,显著提升了系统扩展性。
性能数据揭示的趋势:根据SPEC CPU2017基准测试结果,在4路NUMA服务器上,不当的内存分配策略可能导致高达40%的性能损失,这一数据突显了Linux环境下NUMA优化的重要性,特别是在以下关键场景中:
- 高性能数据库系统(如Oracle、MySQL Cluster)
- 云计算虚拟化平台(KVM、Xen)
- 科学计算与大数据处理(HPC、Spark)
NUMA架构深度解析
核心设计原理与拓扑结构
现代NUMA系统通常包含2-8个物理节点,每个节点由以下组件构成:
-
计算单元:
- 12-64个物理核心(含超线程)
- 多级缓存体系(L1/L2/L3)
-
内存子系统:
- 本地DDR4/DDR5内存通道
- 典型访问延迟约80ns
-
互联总线:
- 节点间通信带宽可达50-100GB/s
- 远程访问延迟增加30-100%
延迟层级对比(以Intel Skylake-SP架构为例):
L1 Cache → 1ns (每个核心独享)
L2 Cache → 3ns (每核心独享)
L3 Cache → 12ns (每节点共享)
本地内存 → 80ns (同节点访问)
远程内存 → 110-150ns (跨节点访问)与SMP架构的关键差异分析
| 特性 | SMP架构 | NUMA架构 |
|---|---|---|
| 内存访问模式 | 统一访问延迟 | 非一致性延迟 |
| 扩展性 | 受总线带宽限制(≤32核) | 支持数百个核心 |
| 内存带宽 | 共享总线,易饱和 | 分布式带宽,线性扩展 |
| 典型应用场景 | 低核数嵌入式系统 | 企业级服务器/数据中心 |
| 编程复杂度 | 简单,透明 | 需要显式优化 |
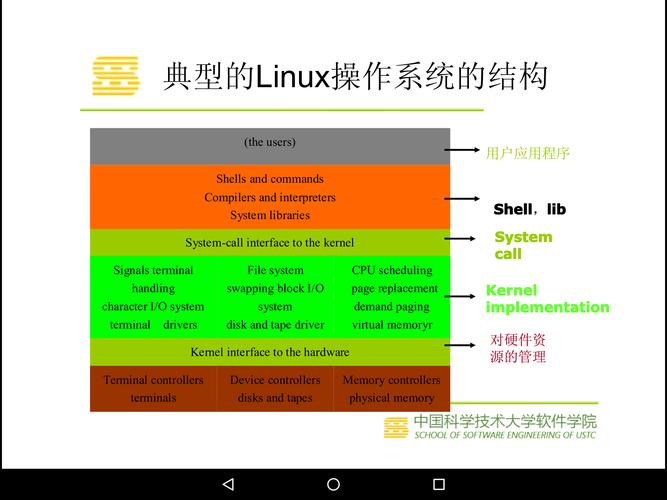
Linux系统中的NUMA拓扑发现
现代Linux内核(4.x+)提供了完善的NUMA信息获取工具,通过以下命令可获取详细拓扑信息:
# 查看完整的CPU拓扑信息 $ lscpu --extended=CPU,NODE,SOCKET,CORE,CACHE CPU NODE SOCKET CORE L1d:L1i:L2:L3 0 0 0 0 0:0:0:0 1 0 0 1 1:1:1:0 ... # 查看内存节点分布 $ numactl -H available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 4 5 6 7 node 0 size: 31768 MB node 1 cpus: 8 9 10 11 12 13 14 15 node 1 size: 32254 MB
Linux NUMA内存管理机制
内存分配策略详解
Linux内核提供了5种内存策略(定义于linux/mempolicy.h),开发者可根据应用特性灵活选择:
enum {
MPOL_DEFAULT, // 系统默认策略(本地优先)
MPOL_PREFERRED, // 首选指定节点,失败时回退
MPOL_BIND, // 严格绑定到指定节点集
MPOL_INTERLEAVE, // 在节点间交叉分配
MPOL_LOCAL // 严格分配在本地节点
};
策略选择建议矩阵:
| 应用类型 | 推荐策略 | 典型配置示例 |
|---|---|---|
| 内存密集型 | MPOL_BIND | numactl --membind=0 app |
| 流式数据处理 | MPOL_INTERLEAVE | numactl --interleave=all app |
| 延迟敏感型 | MPOL_LOCAL | 通过cpuset配置 |
| 通用服务器 | MPOL_PREFERRED | 内核默认策略 |
透明大页(THP)的NUMA陷阱与解决方案
虽然透明大页(Transparent Huge Pages)能减少TLB缺失(实测可降低10-20%的内存访问开销),但在NUMA环境中可能引发以下问题:
-
内存分配不均衡:
- 大页集中分配在单个节点
- 导致跨节点访问激增
-
迁移开销:
- 2MB/1GB页迁移成本高
- 可能引发系统抖动
-
碎片化问题:
- 大页连续内存需求
- 长期运行后分配失败
优化方案:
# 禁用全局THP(适合NUMA敏感应用) echo never > /sys/kernel/mm/transparent_hugepage/enabled # 按进程动态控制(需要应用配合) echo advise > /sys/kernel/mm/transparent_hugepage/shmem_enabled # 配置每节点大页池 echo 1024 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
性能优化实战指南
关键监控指标解析
# 实时监控NUMA平衡状态(每秒刷新) watch -n 1 "grep -e numa_balancing -e migrate /proc/vmstat" # 详细内存分布分析(带zone信息) numastat -zm
核心指标说明:
| 指标 | 健康范围 | 异常处理建议 |
|---|---|---|
| numa_hit | >90% | 检查内存绑定策略 |
| numa_miss | <5% | 优化进程CPU亲和性 |
| numa_foreign | <10% | 调整内存interleave策略 |
| migrate_pages | <100/s | 降低自动平衡频率 |
高级优化技巧集锦
内存分层管理:
# 为关键进程保留节点0的大页 echo 1024 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages # 配置cgroup内存策略 mkdir /sys/fs/cgroup/memory/db_server echo 0 > /sys/fs/cgroup/memory/db_server/memory.migrate
自动NUMA平衡调优:
# 调整扫描间隔(默认1000ms) echo 500 > /proc/sys/kernel/numa_balancing_scan_delay_ms # 设置每次扫描范围(默认64MB) echo 1024 > /proc/sys/kernel/numa_balancing_scan_size_mb # 启用积极模式(针对短生命周期进程) echo 1 > /proc/sys/kernel/numa_balancing_scan_period_min_ms
行业最佳实践案例
案例1:Oracle数据库NUMA优化
启动配置:
numactl --interleave=all --cpubind=0-3 oracle_rdbms \ -use_huge_pages=only \ -memory_target=64G
内核参数优化:
# 降低交换倾向 vm.swappiness = 5 # 启用zone回收模式 vm.zone_reclaim_mode = 1 # 大页预分配 vm.nr_hugepages = 8192
案例2:KVM虚拟化性能提升方案
Libvirt域配置:
<cpu mode='host-passthrough'>
<numa>
<cell id='0' cpus='0-7' memory='16' unit='GiB'/>
<cell id='1' cpus='8-15' memory='16' unit='GiB'/>
</numa>
<cache mode='passthrough'/>
</cpu>
<memoryBacking>
<hugepages/>
<nosharepages/>
<locked/>
</memoryBacking>
QEMU调优参数:
-object memory-backend-file,id=ram-node0,\
size=16G,mem-path=/dev/hugepages,\
host-nodes=0,policy=bind
-numa node,nodeid=0,cpus=0-7,memdev=ram-node0未来趋势与总结建议
技术演进方向
-
智能内存调度:
- 基于机器学习预测内存访问模式
- 动态调整页面迁移策略
-
异构NUMA架构:
- CPU+GPU统一内存空间
- CXL互联技术应用
-
新型存储介质:
- 持久化内存(PMEM)的NUMA管理
- 存储级内存(SCM)集成
实施建议清单
-
部署前审计:
numactl --hardware lstopo --no-io --no-bridges
-
资源隔离方案:
- 使用cgroup v2的NUMA扩展功能
- 配置CPU/memory亲和性策略
-
内核版本选择:
- Linux 5.4+ 改进自动NUMA平衡
- x系列增强异构支持
最终建议:对于关键业务系统,建议采用渐进式优化策略:
- 基准测试确定性能瓶颈
- 实施监控建立性能基线
- 针对性调整NUMA策略
- 验证优化效果并迭代
注:本文技术参数基于x86_64架构测试数据(Intel Xeon Platinum 8380/AMD EPYC 7763),实际效果可能因硬件配置而异,建议在变更生产环境前进行充分的基准测试,并参考特定硬件厂商的白皮书获取详细优化指南。







