
Python:正则表达式

正则表达式的基础和应用
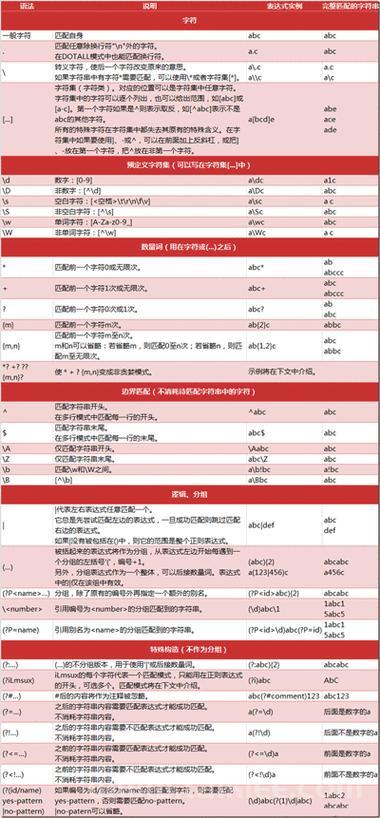
一、正则表达式核心语法(四大基石)
1. 元字符(特殊符号)
- 定位符
^:匹配字符串开始位置
$:匹配字符串结束位置
\b:匹配单词边界(如 \bword\b 匹配独立单词)
- 字符类
.:任意单个字符(默认不包括换行符)
\d:数字(等价 [0-9])
\w:字母、数字、下划线(等价 [a-zA-Z0-9_])
\s:空白符(空格、Tab、换行等)
- 转义符
\:将特殊字符转为普通字符(如 \. 匹配真正的点号)
2. 量词(重复次数)
- *:0次或多次
- +:1次或多次
- ?:0次或1次
- {n}:精确n次
- {n,}:至少n次
- {n,m}:n到m次
3. 字符集合与逻辑
- [abc]:匹配a、b、c中的任意一个
- [a-z]:匹配小写字母a到z
- [^abc]:否定集合(匹配不在abc中的字符)
- |:逻辑或(如 cat|dog 匹配"cat"或"dog")
4. 分组与引用
- ( ):捕获分组(可通过 \1 或 $1 反向引用)
- (?: ):非捕获分组(仅用于逻辑分组)
- (?P):命名分组(Python中可通过名称引用)
二、正则引擎工作原理(NFA vs DFA)
1. NFA引擎(主流实现)
- 特点:支持回溯、捕获组、零宽断言等高级功能,但存在性能风险
- 匹配流程:
- 从起始位置尝试匹配
- 记录所有可能的分支(回溯点)
- 失败时退回最近回溯点继续尝试
- 直到匹配成功或完全失败
2. DFA引擎
- 特点:无回溯,线性时间复杂度,但功能受限(不支持分组引用)
- 流程:一次性扫描文本,无状态回退
三、关键应用场景与解决方案
1. 数据验证(精准匹配)
-
邮箱验证
^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$- ^ 和 $ 确保整行匹配
- [\w\.-]+ 允许用户名包含字母、数字、点、减号
- ([\w-]+\.)+ 匹配多级域名(如 "mail." 或 "google.com.")
- [\w-]{2,4} 匹配顶级域名(如 com、org)
-
强密码规则
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,}$- (?=.*\d):正向预查确保包含数字
- (?=.*[a-z]):必须有小写字母
- (?=.*[A-Z]):必须有大写字母
- .{8,}:总长度至少8位
2. 数据提取(捕获关键信息)
-
从URL提取域名和路径
^https?://([^/?#]+)([^?#]*)
- 分组1 ([^/?#]+) 捕获域名(如 www.example.com)
- 分组2 ([^?#]*) 捕获路径(如 /path/to/page)
-
日志时间戳提取
\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}- 精确匹配 YYYY-MM-DD HH:MM:SS 格式
3. 文本清洗与替换
-
删除HTML标签
]+>
- 匹配所有以 结尾的内容
- 使用 re.sub(r']+>', '', html) 替换为空
-
格式化电话号码
输入:1234567890 → 输出:(123) 456-7890
 (图片来源网络,侵删)
(图片来源网络,侵删)re.sub(r'(\d{3})(\d{3})(\d{4})', r'(\1) \2-\3', phone)四、性能优化与避坑指南
1. 避免灾难性回溯
- 危险模式:(a+)+ 或 .*.*(嵌套量词导致指数级复杂度)
- 优化方法:
- 用具体字符代替 .*(如 \d+ 代替 .*)
- 使用原子分组 (?>...)(部分引擎支持)
- 添加锚点限制范围(如 ^...$)
2. 贪婪与非贪婪选择
- 贪婪模式(默认):.* 匹配尽可能多内容
.* → 可能跨多个标签错误匹配
- 非贪婪模式:.*? 匹配最短结果
.*? → 精确匹配单个标签内容
3. 预编译与复用
# 预编译提升性能(适用于频繁调用场景) pattern = re.compile(r'\d{3}-\d{4}') pattern.findall('Tel: 123-4567')五、进阶技巧
1. 零宽断言(Lookaround)
- (?=...):正向先行断言(右侧必须满足条件)
\d+(?=px) → 匹配 "100px" 中的 "100"
- (?
- (?=...):正向先行断言(右侧必须满足条件)
- 贪婪模式(默认):.* 匹配尽可能多内容
-
- 精确匹配 YYYY-MM-DD HH:MM:SS 格式
-
-
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



