
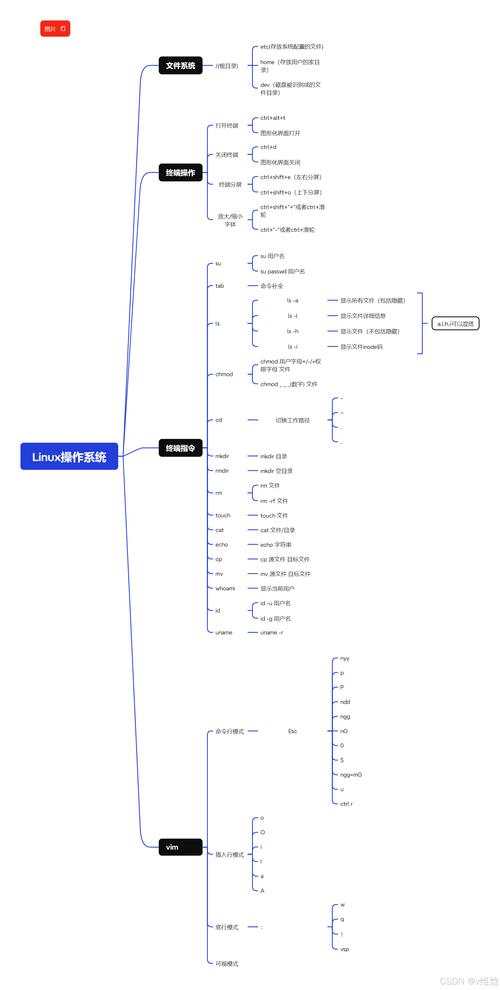
Linux PS 命令与死锁问题分析与解决?PS命令会导致死锁吗?PS命令会引发死锁吗?

Linux PS 命令工作机制解析
ps(Process Status)作为Linux/Unix系统中的核心进程监控工具,其实现机制与系统内核紧密耦合,该命令通过直接访问/proc虚拟文件系统获取实时进程信息,这种设计使其成为系统管理员不可或缺的故障排查利器。
核心技术特性
- 多维度信息采集:支持从
/proc/[pid]目录下的stat、status、io等虚拟文件中提取超过50种进程指标 - 零干扰设计:采用只读方式访问系统信息,不会对进程运行状态产生任何影响
- 灵活输出控制:可通过BSD/UNIX两种风格参数以及自定义列实现精准信息筛选
典型应用场景
# 显示完整进程树结构(包含线程) ps -eLf --forest # 监控高CPU消耗进程(按使用率排序) ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head -n 10 # 检查特定用户的进程资源占用 ps -U www-data -o pid,rss,vsz,cmd --sort=-rss
技术细节:现代Linux内核中,
ps命令执行时会遍历/proc目录下的数字子目录(每个对应一个进程PID),通过解析这些目录中的虚拟文件获取信息,当系统存在数千个进程时,这种遍历操作可能成为性能瓶颈。
系统死锁的形成机制
死锁四要素理论
- 资源互斥性:关键资源(如内核锁)同一时刻只能被单个进程持有
- 占有且等待:进程在保持现有资源的同时请求新资源
- 不可剥夺:已分配资源必须由持有进程主动释放
- 循环等待链:多个进程形成环形资源依赖关系
Linux特有的死锁场景
| 死锁类型 | 触发条件 | 典型症状 |
|---|---|---|
| 内核锁竞争 | 多个CPU核心争用自旋锁 | 系统完全无响应 |
| 内存死锁 | OOM killer未能及时触发 | 频繁磁盘交换,进程D状态 |
| 文件系统死锁 | NFS客户端服务端双向等待 | 挂载点操作超时 |
| 驱动级死锁 | 硬件设备响应异常 | 内核日志出现"task blocked" |
PS命令卡死的深层原因
/proc文件系统阻塞
当出现以下情况时,ps命令可能陷入永久等待:
- 不可中断进程(D状态):等待磁盘I/O或网络响应的进程会导致
ps在读取其状态文件时阻塞 - 内核锁争用:
proc_dir_entry锁竞争会使所有/proc访问操作串行化 - 内存压力:当系统内存严重不足时,内核可能无法为
ps分配必要的缓冲区
系统资源枯竭指标
# 快速检查系统资源状态
dmesg -T | grep -i 'oom\|kill' # 检查OOM事件
cat /proc/sys/fs/file-nr # 查看文件描述符使用量
free -m | awk '/Mem/{printf "%.1f%%\n", $3/$2*100}' # 内存使用率
专业级诊断方法
实时系统状态捕获
# 使用systemtap进行内核级追踪
stap -e 'probe kernel.function("proc_pid_readdir") {
printf("%s(%d) accessing %s\n", execname(), pid(), kernel_string($filp->f_path->dentry->d_name.name))
}'
高级死锁检测技术
-
锁依赖图分析:
cat /proc/lockdep_chains debugfs -R 'info locks' /sys/kernel/debug
-
内核软死锁检测:
# 配置内核检测参数 echo 30 > /proc/sys/kernel/watchdog_thresh sysctl -w kernel.softlockup_panic=1
系统化解决方案
紧急恢复操作流程
-
SysRq组合键应急方案:
Alt+SysRq+r : 切换键盘到原始模式 Alt+SysRq+s : 同步所有挂载的文件系统 Alt+SysRq+u : 重新挂载所有文件系统为只读 Alt+SysRq+b : 立即重启系统 -
无响应进程处理:
# 查找D状态进程 awk '$2=="D"{print $0}' /proc/[0-9]*/stat | cut -d' ' -f1,41- # 强制解除挂载可能卡住的文件系统 umount -l /mnt/nfs
长期优化策略
内核参数调优建议:
# 提升系统稳定性 echo 120 > /proc/sys/kernel/panic echo 1 > /proc/sys/vm/overcommit_memory sysctl -w kernel.panic_on_io_nmi=1
监控体系配置示例:
# Prometheus告警规则示例
groups:
- name: deadlock.rules
rules:
- alert: ProcessStuck
expr: sum(process_state{state="D"}) by (instance) > 5
for: 10m
labels:
severity: critical
annotations:
summary: "{{ $value }} processes in D state on {{ $labels.instance }}"
专业工具链推荐
-
动态追踪三件套:
# perf事件分析 perf stat -e 'sched:sched_process_*' -a sleep 10 # ebpf死锁检测 bpftrace -e 'kprobe:mutex_lock { @[kstack] = count(); }' -
高级调试工具:
# 使用crash分析内核转储 crash -i analysis.cmd /var/crash/vmcore /usr/lib/debug/vmlinux # 使用kgdb进行实时内核调试 echo g > /proc/sysrq-trigger
最佳实践指南
-
预防性维护:
- 每月执行一次内核压力测试:
stress-ng --all 4 --timeout 1h - 使用
cgroup隔离关键服务资源 - 定期更新内核获取死锁修复补丁
- 每月执行一次内核压力测试:
-
应急响应预案:
# 创建应急恢复脚本 cat > /usr/local/bin/emergency_recovery.sh <<'EOF' #!/bin/bash sync; sync; sync mount -o remount,ro / kill -9 $(ps -eo pid,state | awk '$2=="D"{print $1}') reboot EOF chmod +x /usr/local/bin/emergency_recovery.sh -
文档化记录:
- 维护系统变更日志
- 记录所有异常事件及解决方案
- 建立系统健康基线指标
版本说明:本文技术方案适用于Linux 4.15+内核版本,对于容器化环境需特别注意cgroup v2的兼容性问题,建议在生产环境实施前,使用相同内核版本进行充分测试。
通过系统性地应用这些技术方案,管理员可以显著降低ps命令死锁问题的发生概率,并在出现异常时快速定位问题根源,完善的监控体系比事后诊断更为重要,应当将资源监控作为系统运维的基础设施来建设。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







