
Cangjie 并发模型解析:与 C++ 线程的对比实践

以下内容基于学习 Cangjie 语言时的观察与实践编写。欲深入了解,请参阅 Cangjie 开发指南 并发编程。
1. 调度机制
Cangjie 语言提供 抢占式 线程模型 —— 线程的执行时间由 OS 强制分配,通过 时间片轮转 或 优先级策略 决定何时切换线程。若某个线程占用 CPU 时间过长,OS 会强制挂起当前线程、并切换到其它线程,避免单个线程长期独占资源。
与协作式调度(需线程主动让出 CPU)不同,抢占式模型由运行时控制调度,开发者无需显式调用 yeild() 或 await,从而降低因线程长时间执行导致的资源争用问题。
2. 线程模型
线程可以细分为两个概念:语言线程 和 native 线程 —— 语言线程是 Cangjie 并发模型的基本执行单位;native 线程是语言线程实现的具体载体,一般是操作系统线程。
不同于 C++,每个语言线程对应一个 native 线程这种 1 : 1 线程模型;Cangjie 采用 M : N 线程模型,即 M 个语言线程在 N 个 native 线程上调度执行。
开发者仅需通过 spawn 关键字创建线程,通过 Future().get() 获取线程执行结果并等待其完成。
每个 Cangjie 线程拥有独立的执行上下文(如寄存器状态、栈空间),共享进程的内存空间;上下文切换完全在用户空间完成,无需进入内核态,避免了传统线程切换的高昂成本。
以下均在 Linux Ubuntu 20.04 环境下进行验证:
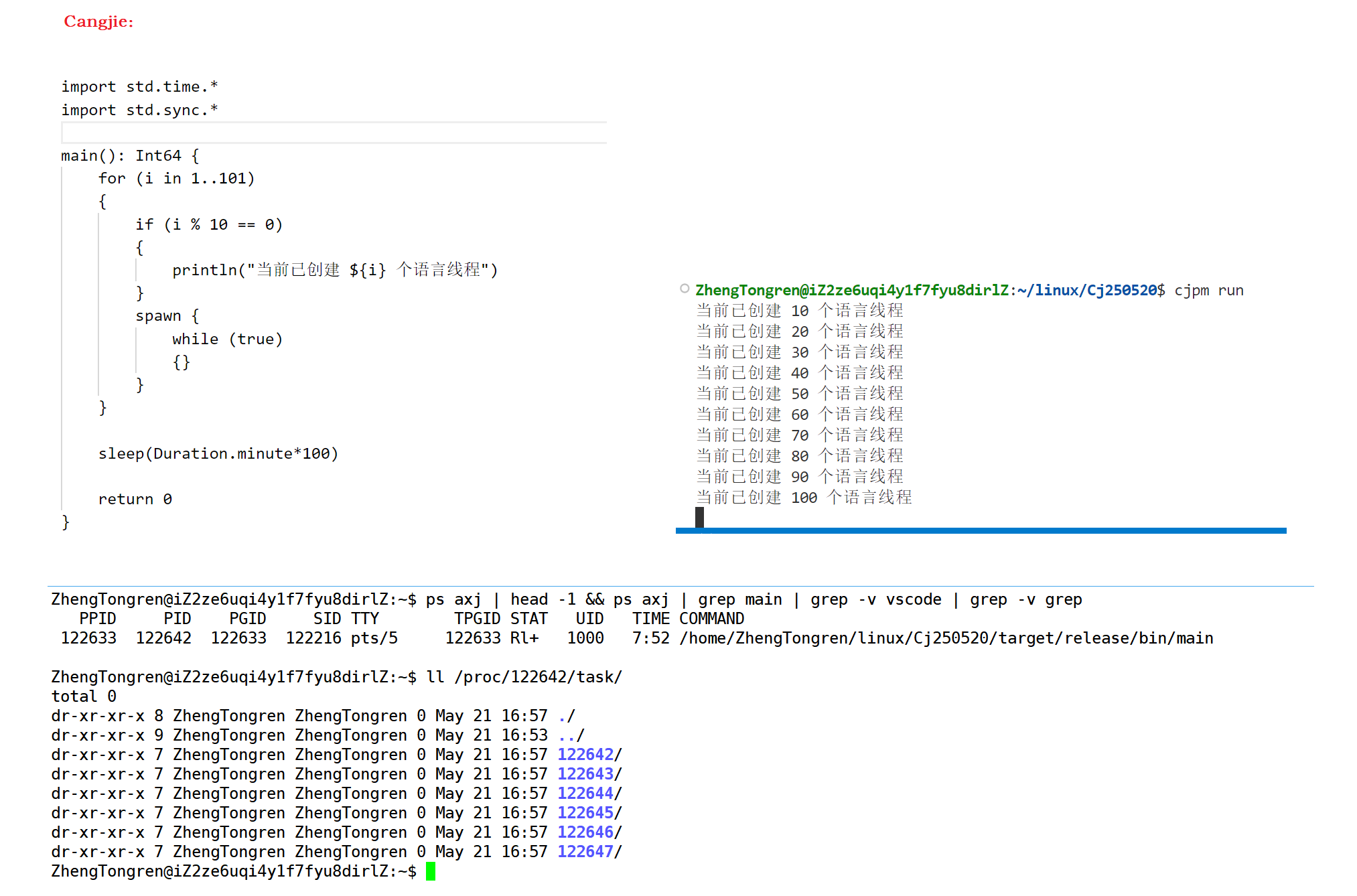
- 现象 1:Cangjie 创建 1 ~ 10000 个的用户态线程,在 /proc//task 中只看到 5 个线程(不含主线程)。
但无法验证 Cangjie 是否采用了固定大小的线程池模型,其中 M(即线程池中的内核线程数)恒定为 5。
根据 华为鸿蒙开发技术 中提到的内容,“针对发现的性能瓶颈,开发者可以采取以下优化措施:3. 调整线程池大小:根据系统负载调整线程池的大小,以平衡性能与资源消耗。”
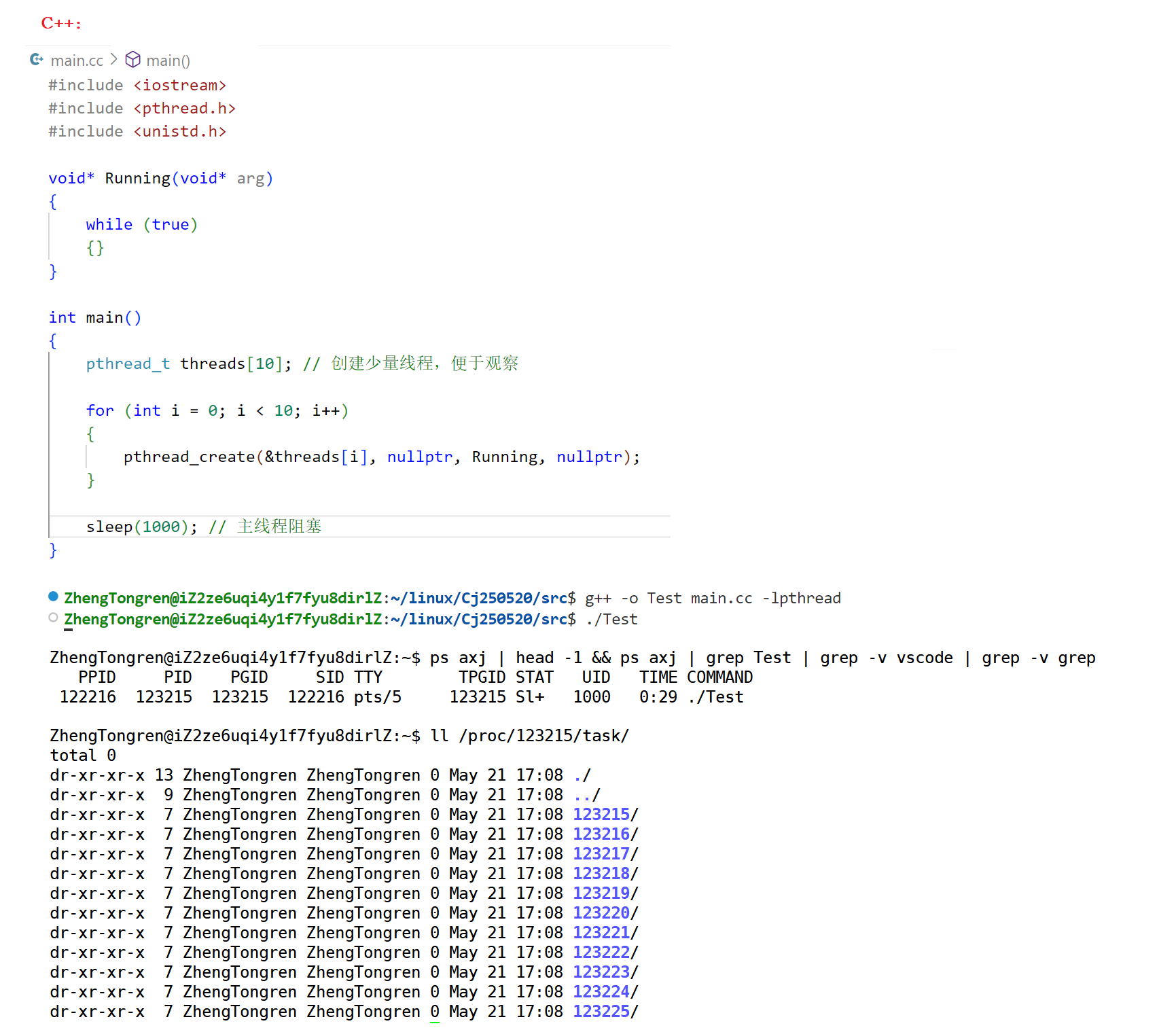
- 现象 2:C++ 使用 pthread_create 创建 n 个线程,在 /proc//task 中能看到 n 个线程。
3. 可重入锁 和 synchronized
3.1 ReentrantMutex
Cangjie 语言的可重入锁机制(Reentrant Mutex)是一种支持线程多次获取同一把锁的工具。
ReentrantMutex 与 std::mutex 相同点在于:
- 互斥性:任意时刻,最多只有一个线程能持有锁,其它线程需等待锁释放后才能获取。
- 临界区保护:通过锁的 加锁 / 解锁 操作,确保临界区代码的原子执行,避免数据竞争和状态不一致。
ReentrantMutex 还具备 锁重入性 —— 允许同一线程多次获取同一把锁而不会导致死锁;在此功能上,ReentrantMutex 与 std::Recursive_mutex 是等价的。
import std.collection.* import std.sync.* var count = 0 let mutex = ReentrantMutex() func recursiveAdd(times : Int64) : Unit { if (times > 0) { mutex.lock() // 加锁 count++ println("Thread-id: ${Thread.currentThread.id}, Count: ${count}") recursiveAdd(times-1) // 递归调用 mutex.unlock() // 释放锁 } } main() : Int64 { let threads = ArrayList() for (_ in 0..3) { let fut = spawn { recursiveAdd(2) // 每个线程递归加锁两次 } threads.append(fut) } // 等待所有线程完成 for (fut in threads) { fut.get() } return 0; }Thread.currentThread.id 为当前执行线程的标识,所有存活的线程都有不同的标识(通常 id 从 1 开始递增),但线程结束后其 id 并不保证会被复用。
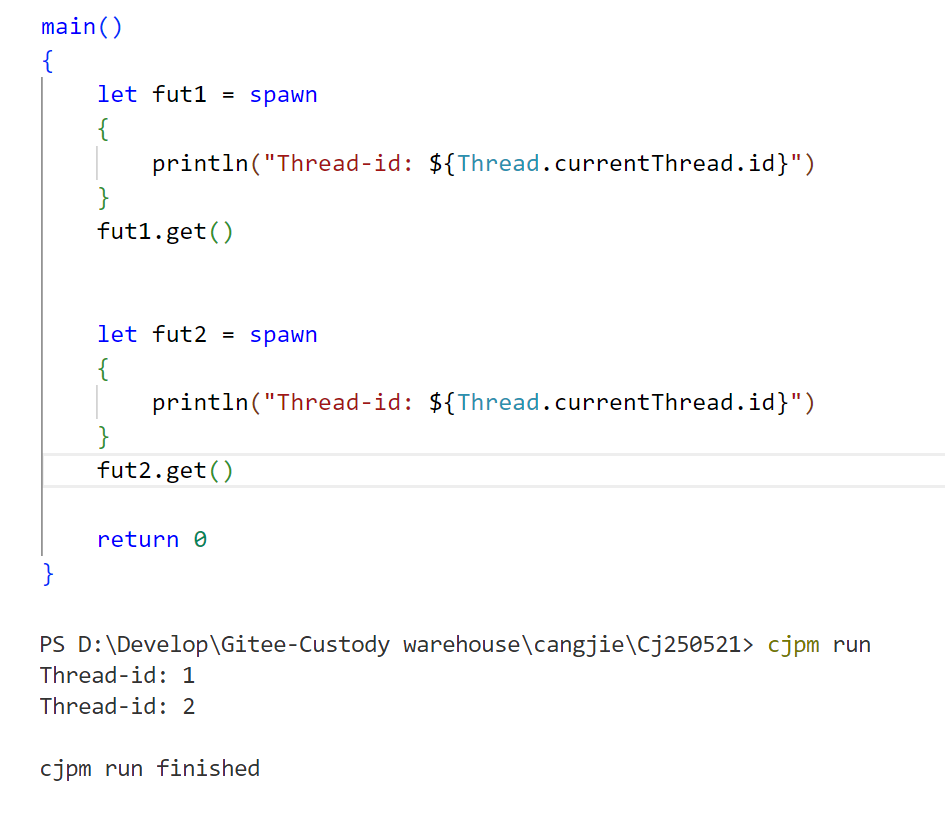
需要注意的是,Thread.currentThread.id 返回的是 Cangjie 线程逻辑的 id,并不等同于其背后关联的 native 线程的操作系统级标识(如 pthread_t 或 内核 tid – Thread-id )。

recursiveAdd 函数在每次调用时会递归嵌套自身,同一线程多次调用 mutex.lock() 而不会死锁,锁的持有计数自动递增;相应地,每次执行解锁操作 mutex.unlock() 时,该计数会递减。
仅当计数降至 0 时,锁才会被完全释放,从而允许其它等待的线程获取该锁;若 计数溢出 或 未匹配解锁,可能导致死锁或资源泄露。
因此,加锁 和 解锁 操作必须 成对出现 且 数量匹配。
3.2 synchronized 关键字
Cangjie 的 synchronized 关键字搭配 ReentrantMutex 使用,会在代码块或方法执行前自动获取锁,并在退出作用域时自动释放锁,类似于 C++ 中 std::unique_lock 的 RAII (资源获取即初始化)机制。
功能差异:
-
synchronized 是 Cangjie 的语言级关键字,与 ReentrantMutex 深度绑定;而 unique_lock 是 C++ 标准库的模版类。
-
unique_lock 提供 try_lock_for() 等高级操作,而 synchronized 关键字仅提供基础的自动锁管理。
synchronized(mutex) // 自动加锁 { // 访问共享资源 count++ println("Thread-id: ${Thread.currentThread.id}, Count: ${count}") recursiveAdd(times-1) } // 自动解锁
-
- 现象 2:C++ 使用 pthread_create 创建 n 个线程,在 /proc//task 中能看到 n 个线程。







