
前端将html导出pdf文件解决分页问题

文章目录
- 1.安装依赖
- 2.使用方法
- 3.使用说明
- 导出效果对比:
- 截断
- 自动分页
- 具体代码 :
- 这是借鉴了qq_251025116大佬的解决方案并优化升级完成的,原文链接
1.安装依赖
npm install jspdf html2canvas
2.使用方法
import htmlToPdffrom './index.js' const suc = () => { message.success('success'); }; //记得在需要打印的div上面添加 id let dom = document.querySelector('#testPdf'); let pdf = new htmlToPdf(dom, '测试', 'splitPages', ',', suc, 2); pdf.outPutPdfFn('测试');3.使用说明
//splitPages 是需要添加的类名,需要再那个地方分页就在那个地方添加类名 splitPages //如:导出效果对比:
截断
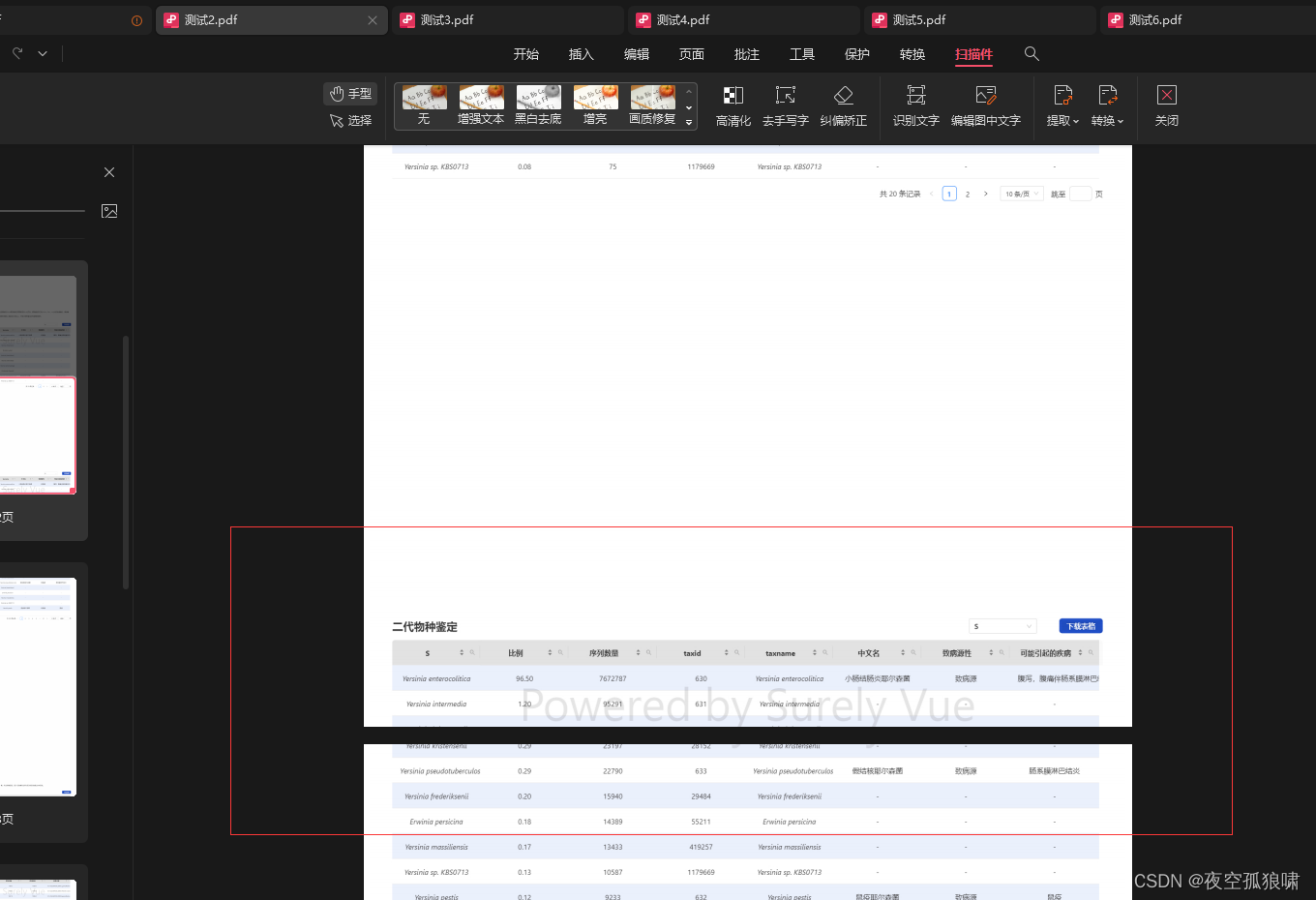
自动分页
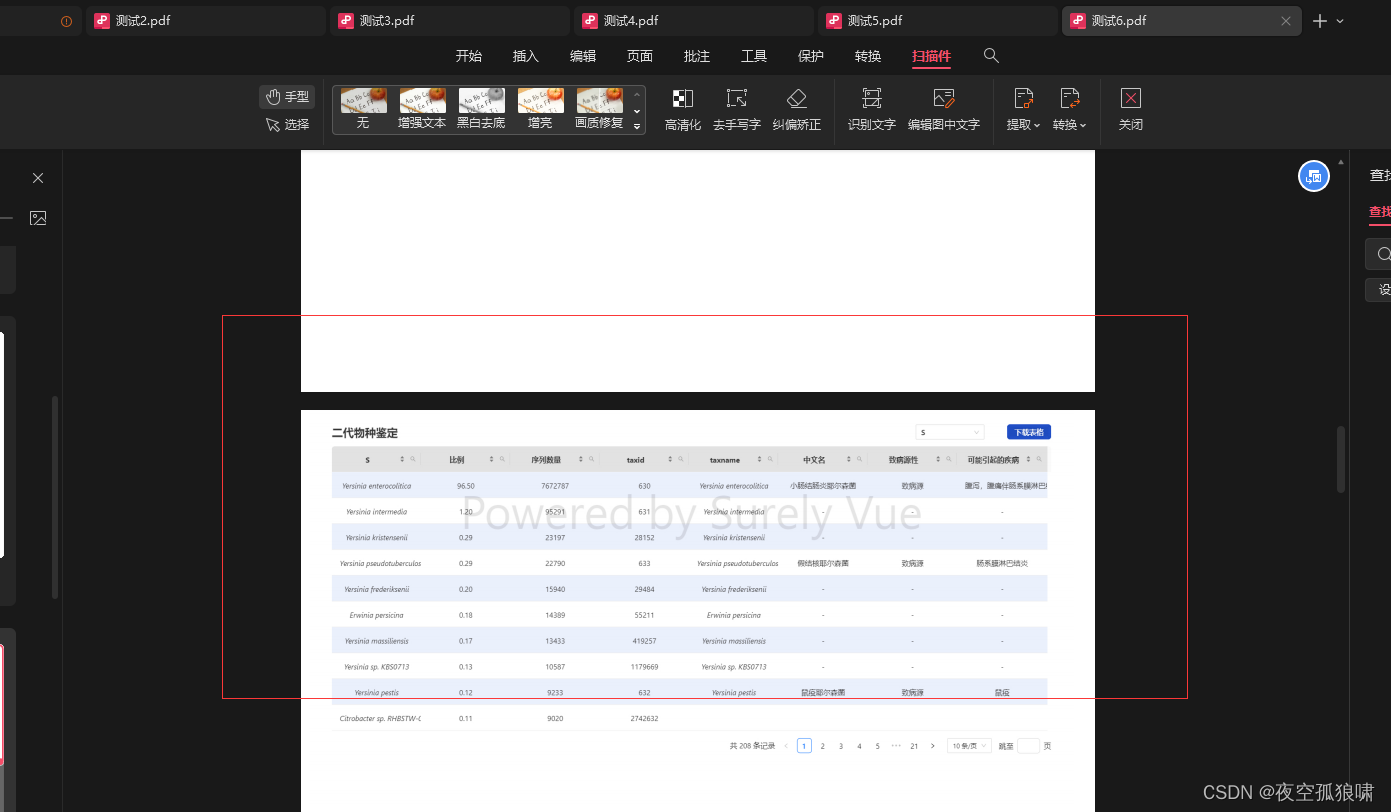
具体代码 :
import jsPDF from "jspdf"; import html2canvas from "html2canvas"; /* * 使用说明 * ele:需要导出pdf的容器元素(dom节点 不是id) * pdfFileName: 导出文件的名字 通过调用outPutPdfFn方法也可传参数改变 * splitClassName: 避免分段截断的类名 当pdf有多页时需要传入此参数 , 避免pdf分页时截断元素 如表格
* breakClassName:自定义分页符类名,默认为break_page,添加改类名的标签被自动分页到下一页 * sucCallback:成功回调函数 * scale:增强图片清晰度 数字也打越清晰 * 调用方式 先 let pdf = new htmlToPdf(ele, 'pdf' ,'itemClass'); * 若想改变pdf名称 pdf.outPutPdfFn(fileName); outPutPdfFn方法返回一个promise 可以使用then方法处理pdf生成后的逻辑 * */ class htmlToPdf { constructor(ele, pdfFileName, splitClassName = "itemClass", breakClassName = "break_page", sucCallback = () => { }, scale = 2) { this.ele = ele; this.pdfFileName = pdfFileName; this.splitClassName = splitClassName; this.breakClassName = breakClassName; this.sucCallback = sucCallback; this.scale = scale; this.A4_WIDTH = 595; this.A4_HEIGHT = 842; this.pageHeight = 0 this.pageNum = 1 }; async getPDF(resolve) { let ele = this.ele; let pdfFileName = this.pdfFileName let eleW = ele.offsetWidth // 获得该容器的宽 let eleH = ele.scrollHeight // 获得该容器的高 let eleOffsetTop = ele.offsetTop // 获得该容器到文档顶部的距离 let eleOffsetLeft = ele.offsetLeft // 获得该容器到文档最左的距离 let canvas = document.createElement("canvas") let abs = 0 let win_in = document.documentElement.clientWidth || document.body.clientWidth // 获得当前可视窗口的宽度(不包含滚动条) let win_out = window.innerWidth // 获得当前窗口的宽度(包含滚动条) if (win_out > win_in) { abs = (win_out - win_in) / 2 // 获得滚动条宽度的一半 } canvas.width = eleW * 2 // 将画布宽&&高放大两倍 canvas.height = eleH * 2 let context = canvas.getContext("2d") context.scale(this.scale, this.scale) // 增强图片清晰度 context.translate(- eleOffsetLeft - abs, - eleOffsetTop) html2canvas(ele, { useCORS: true // 允许canvas画布内可以跨域请求外部链接图片, 允许跨域请求。 }).then(async canvas => { let contentWidth = canvas.width let contentHeight = canvas.height // 一页pdf显示html页面生成的canvas高度; this.pageHeight = (contentWidth / this.A4_WIDTH) * this.A4_HEIGHT // 这样写的目的在于保持宽高比例一致 this.pageHeight/canvas.width = a4纸高度/a4纸宽度// 宽度和canvas.width保持一致 // 未生成pdf的html页面高度 let leftHeight = contentHeight // 页面偏移 let position = 0 // a4纸的尺寸[595,842],单位像素,html页面生成的canvas在pdf中图片的宽高 let imgWidth = this.A4_WIDTH - 10 // -10为了页面有右边距 let imgHeight = (this.A4_WIDTH / contentWidth) * contentHeight let pageData = canvas.toDataURL("image/jpeg", 1.0) let pdf = jsPDF("", "pt", "a4"); // 有两个高度需要区分,一个是html页面的实际高度,和生成pdf的页面高度(841.89) // 当内容未超过pdf一页显示的范围,无需分页 if (leftHeight 0) { pdf.addImage(pageData, "JPEG", 6, position + 40, imgWidth - 12, imgHeight - 80) leftHeight -= this.pageHeight position -= this.A4_HEIGHT // 避免添加空白页 if (leftHeight > 0) { pdf.addPage() } } } pdf.save(pdfFileName + ".pdf", { returnPromise: true }).then(() => { // 去除添加的空div 防止页面混乱 let doms = document.querySelectorAll('.emptyDiv') for (let i = 0; i { // 进行分割操作,当dom内容已超出a4的高度,则将该dom前插入一个空dom,把他挤下去,分割 let target = this.ele; this.pageHeight = target.scrollWidth / this.A4_WIDTH * this.A4_HEIGHT; this.ele.style.height = 'initial'; pdfFileName ? this.pdfFileName = pdfFileName : null; this.pageNum = 1; // pdf页数 this.domEach(this.ele) // 异步函数,导出成功后处理交互 this.getPDF(resolve, reject); }) }; domEach(dom) { let childNodes = dom.childNodes childNodes.forEach((childDom, index) => { if (this.hasClass(childDom, this.splitClassName)) { let node = childDom; let eleBounding = this.ele.getBoundingClientRect(); let bound = node.getBoundingClientRect(); let offset2Ele = bound.top - eleBounding.top let currentPage = Math.ceil((bound.bottom - eleBounding.top) / this.pageHeight); // 当前元素应该在哪一页 if (this.pageNum -1; } } export default htmlToPdf;
- 这是借鉴了qq_251025116大佬的解决方案并优化升级完成的,原文链接
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



