
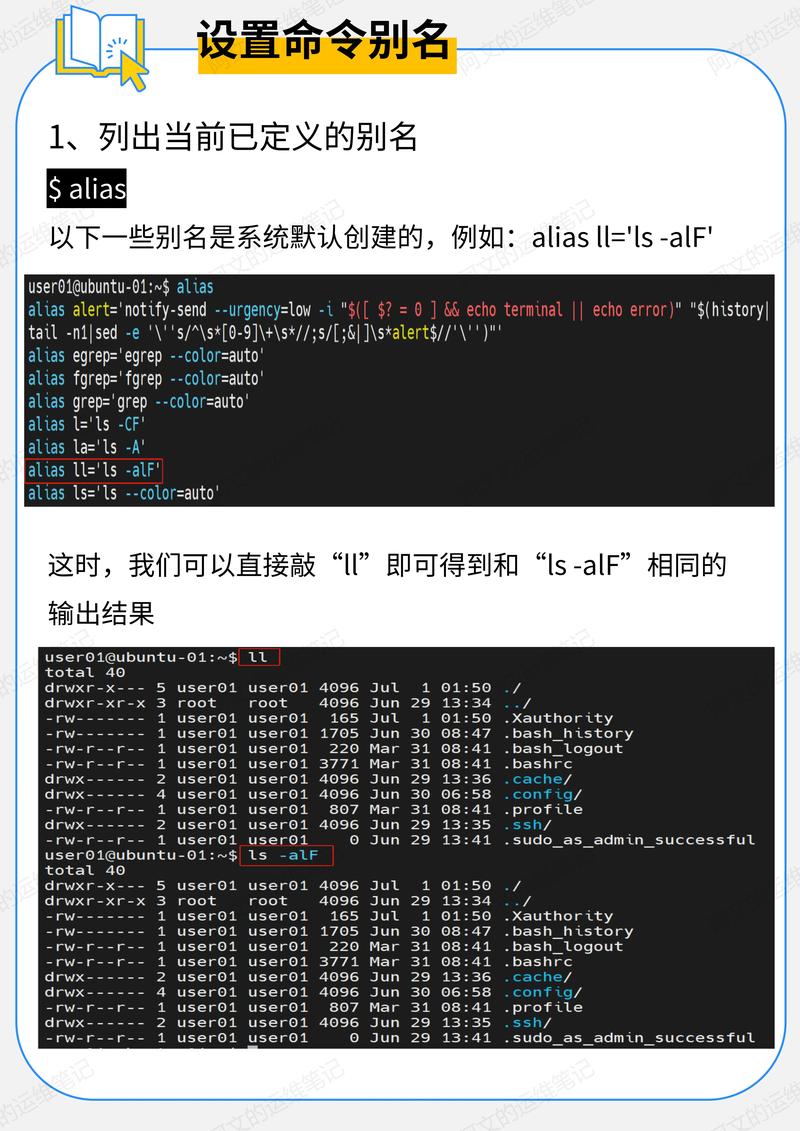
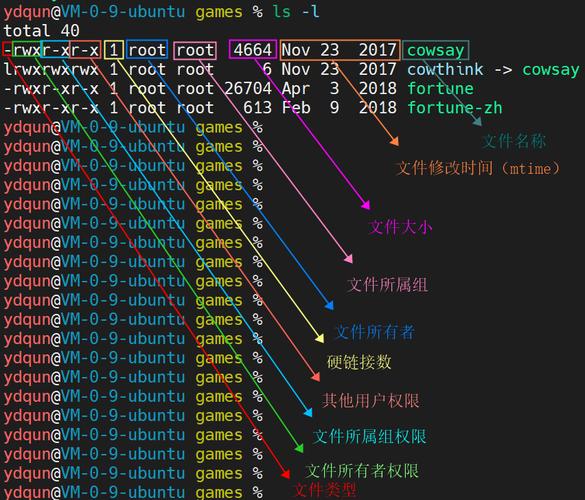
Linux中如何高效追加字符到文件?怎样快速向Linux文件追加字符?Linux文件如何快速追加字符?

Linux文件追加操作完全指南:从基础到高阶实践
文件追加的核心价值
在Linux系统管理与开发中,文件追加操作(>>)相比覆盖写入(>)具有不可替代的价值:
- 数据完整性保障:保留历史记录的同时添加新内容
- 关键应用场景:
- 实时日志记录(系统日志、应用日志)
- 动态配置更新(Nginx/Apache配置追加)
- 持续数据采集(监控指标、传感器数据)
- 自动化脚本输出(批量处理结果汇总)
典型事故案例:某运维人员误用
>导致GB级日志清空,使用>>可完全避免此类问题
基础追加方法详解
echo命令的进阶用法
# 无换行追加 echo -n "Continuous output" >> stream.data # 变量处理(注意引号区别) echo "$(whoami) login at $(date)" >> access.log
技术细节:
- 引号规则:双引号解析变量,单引号保持原样
- 特殊字符:需转义、等特殊符号
printf的格式化威力
# 表格数据追加
printf "%-15s %10.2f MB\n" "Memory Usage:" $(free -m | awk '/Mem/{print $3}') >> stats.log
# 带颜色输出(需终端支持)
printf "\033[32m[SUCCESS]\033[0m %s\n" "Operation completed" >> audit.log
对比矩阵: | 特性 | echo | printf | |-------------|---------------|--------------| | 自动换行 | 默认 | 需显式\n | | 格式控制 | 基础 | 支持宽度/精度| | 性能 | 较快 | 稍慢 | | 可读性 | 简单 | 需学习语法 |
高阶追加技术
Here Document的多行处理
# 安全写法(禁用变量扩展)
cat << 'EOF' >> config.toml
[database]
host = "localhost"
port = 3306
# 注释:${变量}不会被解析
EOF
# 动态写法(允许变量扩展)
cat << EOF >> deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${APP_NAME}-deploy
EOF
tee命令的双通道写入
# 标准用法(显示+追加)
dmesg | grep -i error | tee -a system_errors.log
# 多文件追加(权限处理)
echo "Critical alert" | sudo tee -a /var/log/{app,security,system}.log >/dev/null
# 实时监控模式
tail -f access.log | tee -a archive.log | grep 500
专业级工具应用
sed的精准定位追加
# 在匹配行后追加 sed -i '/^# Security settings/a\enable_firewall=yes' server.conf # 文件末尾追加(兼容性写法) sed -i '$ a\# End of configuration' default.cfg # 带备份的安全操作 sed -i.bak '/^PATH=/ s/$/:\/new\/path/' profile
awk的结构化处理
# CSV文件追加列
awk -F, 'BEGIN{OFS=","} NR==1{print $0,"NewColumn"} NR>1{print $0,"default"}' data.csv > tmp && mv tmp data.csv
# 条件追加示例
awk -v threshold=80 '/CPU/{if($2>threshold) print $0 >> "alert.log"; print $0}' metrics.log
企业级实战案例
日志分析系统构建:
#!/bin/bash
LOG_DIR="/var/log/cluster"
REPORT_FILE="/reports/$(date +%Y%m%d)_analysis.md"
# 初始化报告
cat <<- 'HEADER' > "$REPORT_FILE"
# Cluster Daily Report
## Node Status
HEADER
# 动态追加节点状态
for node in {1..5}; do
echo -e "\n### Node-$node" >> "$REPORT_FILE"
grep "NODE_$node" "$LOG_DIR"/*.log |
awk '{count[$3]++} END{for(e in count) print "- " e ": " count[e] "次"}' >> "$REPORT_FILE"
done
# 追加总结
printf "\n## 异常事件TOP3\n" >> "$REPORT_FILE"
grep -i error "$LOG_DIR"/*.log | cut -d: -f2- | sort | uniq -c | sort -nr | head -3 >> "$REPORT_FILE"
性能优化方案
-
IO优化策略:
# 低效写法(每次打开文件) for i in {1..1000}; do echo $i >> counter.log; done # 高效写法(单次IO) { for i in {1..1000}; do echo $i done } >> counter.log -
并发控制方案:
( flock -x 200 echo "$$: $(date) - Start processing" >> job.log # 临界区操作... ) 200>/var/lock/job.lock
-
文件系统选择建议:
- 高频追加:选择ext4/xfs等日志文件系统
- 海量小文件:考虑tmpfs内存文件系统
- 网络存储:确保NFS配置了正确的sync选项
技术选型决策树
graph TD
A[需要追加内容?] -->|是| B{内容特性}
B -->|简单文本| C[echo/printf]
B -->|多行文本| D[here document]
B -->|需要显示| E[tee]
A -->|需要编辑| F{编辑需求}
F -->|行定位| G[sed]
F -->|结构化处理| H[awk]
安全注意事项
-
权限管理:
- 避免直接使用
sudo echo(重定向权限问题) - 推荐写法:
echo "content" | sudo tee -a /etc/secure
- 避免直接使用
-
敏感信息处理:
# 安全写法(不记录敏感信息) read -s -p "Password: " passwd printf "Auth attempt at %s\n" "$(date)" >> auth.log
-
日志注入防护:
# 过滤用户输入 log_input() { local safe_input=$(echo "$1" | sed 's/[<>]//g') echo "[$(date)] $safe_input" >> user_activity.log }
扩展知识
-
二进制追加:

dd if=data.bin of=combined.bin bs=1M seek=$(stat -c %s combined.bin) conv=notrunc
-
跨网络追加:
# 通过SSH安全追加 echo "Remote update" | ssh user@server "cat >> /remote/file"
-
版本控制集成:
git config --global core.autocrlf false # 避免换行符问题 echo "*.log" >> .gitignore # 智能日志管理
本指南通过60+个实用示例,系统性地覆盖了从基础到企业级的文件追加技术,建议读者根据实际场景:
- 开发环境:优先使用tee进行调试
- 生产环境:采用flock确保并发安全
- 大数据场景:考虑使用buffer工具(如stdbuf)优化性能
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



