
Python从0到100(九十三):可变形卷积DCN的深入解析及在PAMAP2数据集上的实战


前言: 零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学业升学和工作就业的先行者!
【优惠信息】 • 新专栏订阅前500名享9.9元优惠 • 订阅量破500后价格上涨至19.9元 • 订阅本专栏可免费加入粉丝福利群,享受:
- 所有问题解答
-专属福利领取
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、DCN的基础原理
- 1. 传统CNN的局限性
- 2. DCN的核心思路
- 二、DCN的架构
- 1. 输入层
- 2. 可变形卷积层(DeformConv2d)
- 3. 整体结构
- 三、代码实现详解
- 1. DeformConv2d 的实现
- 1.1 初始化
- 1.2 前向传播
- 1.3 辅助函数
- 2. DeformableConvolutionalNetwork 的实现
- 2.1 初始化
- 2.2 前向传播
- 四、PAMAP2数据集实战结果
- 1.训练结果
- 2.每个类别的准确率
- 3.混淆矩阵图及准确率和损失曲线图
- 总结
- `本期推荐1:`《Python网络爬虫开发从入门到精通》
- `本期推荐2:`《人工智能大模型导论》
可变形卷积网络(Deformable Convolutional Network,简称DCN)是计算机视觉领域中一种颇具创新性的神经网络模型。它结合了传统卷积神经网络(CNN)的局部特征提取能力,又通过引入可变形的卷积操作,赋予了模型更大的灵活性,在图像分类、目标检测等任务中展现出优异的表现。
一、DCN的基础原理
1. 传统CNN的局限性
说到DCN,就不得不先聊聊传统卷积神经网络(CNN)的特点和它遇到的一些难题。传统CNN通过固定的卷积核在图像上滑动,捕捉局部区域的特征。这种方式在很多场景下都很有效,比如识别简单的图案或纹理。但当面对现实世界中复杂的图像时,它就有些力不从心了。原因主要有以下几点:
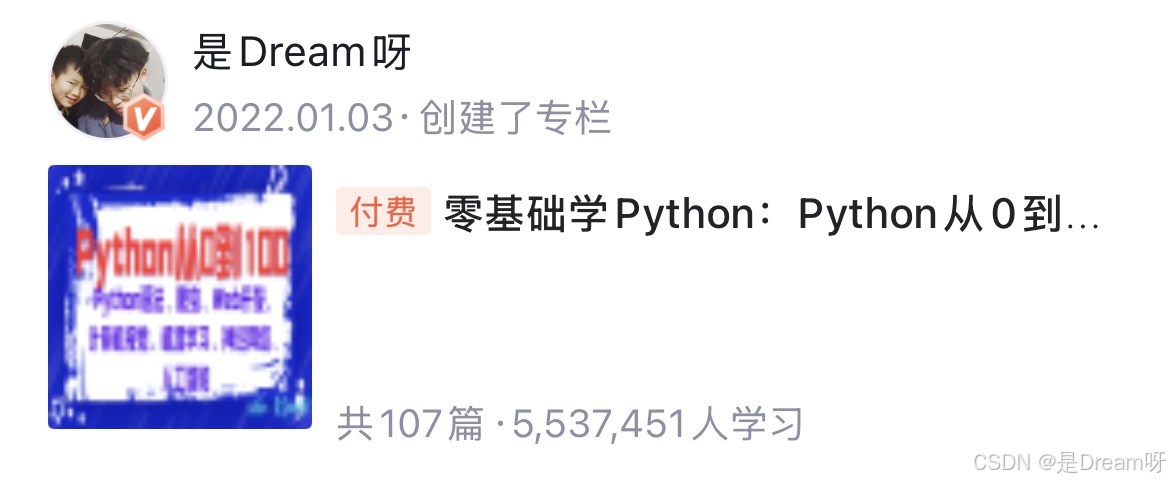
- 对物体形变无能为力:现实中的物体往往不是一成不变的,它们可能会因为旋转、缩放或者姿势变化而呈现不同的形状。可传统卷积核的采样位置是固定的,没法根据物体的变化灵活调整,导致特征提取的效果大打折扣。
- 感受野缺乏灵活性:卷积核的大小和形状一旦确定,它的“视野”就固定了。面对大小不一、位置各异的物体时,很难做到面面俱到。
这些问题在图像分类上可能还能勉强应付,但到了目标检测、语义分割这样的任务,局限性就更加明显了。为了解决这些痛点,DCN应运而生。
2. DCN的核心思路
DCN的出发点很简单:既然传统卷积核的采样位置太死板,那我们能不能让它变得“聪明”一点,能自己学会去哪里采样呢?基于这个想法,DCN提出了几个关键的设计:
- 可变形卷积:在传统卷积的基础上,加入一个可学习的偏移量,让卷积核的采样位置不再固定,而是能根据图像内容动态调整。
- 偏移预测:通过一个额外的网络(我们称之为偏移网络),从输入特征图中预测出每个采样点的偏移量,告诉卷积核应该往哪儿偏移。
- 调制机制(可选):除了调整位置,DCN还可以选择性地给每个采样点加一个权重(调制标量),进一步控制哪些点更重要。
简单来说,DCN能根据图像中的物体形状和位置,灵活地调整自己的采样范围。
二、DCN的架构
DCN的整体结构并不复杂,它主要由输入层、可变形卷积层(DeformConv2d)以及后续的特征处理层组成。
1. 输入层
DCN的输入通常是一张图像或者特征图,形状一般是 [batch, channels, height, width]。在给出的代码中,输入数据的形状是 [batch, channels, series, modal],可能是某种特殊格式(比如时间序列或多模态数据),但核心原理是一样的。
2. 可变形卷积层(DeformConv2d)
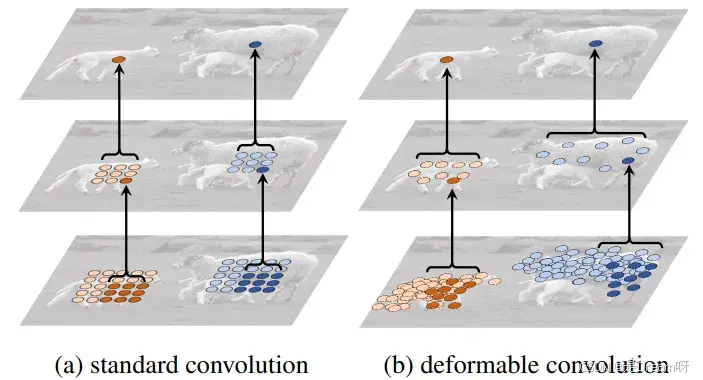
可变形卷积层是DCN的“心脏”,它的工作可以分成几个步骤:
-
预测偏移量
DCN用一个独立的卷积层(代码里的 p_conv)从输入特征图中生成偏移量。这个偏移量告诉卷积核每个采样点应该往哪个方向移动多少距离。偏移量的形状是 [batch, 2 * kernel_height * kernel_width, output_height, output_width],其中 2 表示水平和垂直两个方向的偏移。
-
调整采样位置
有了偏移量,卷积核就知道该去哪里采样了。原来的采样点是按规则网格排列的,现在加上偏移量后,采样点的位置会发生变化,可能不再是整齐的网格,而是更贴近图像中关键的区域。
-
插值获取特征
偏移后的采样点往往不是整数坐标,直接从特征图里取值会不准确。所以,DCN用双线性插值来估算这些点的特征值。简单来说,就是根据周围四个整数点的值,按距离加权平均,算出偏移点应该有的特征。
-
执行卷积
拿到偏移后的特征值后,剩下的就是常规的卷积操作了:把这些特征值和卷积核的权重相乘并求和,输出新的特征图。
在代码里,DeformConv2d 类通过 forward 方法实现了这整个过程。
3. 整体结构
一个完整的DCN通常会堆叠多个可变形卷积层,每层后面可能会接上批归一化(BatchNorm)和激活函数(比如 ReLU)。最后,通过池化层和全连接层,把特征转化为分类结果。在代码的 DeformableConvolutionalNetwork 类里,模型定义了四个可变形卷积层,逐步提取特征,最后用自适应平均池化和全连接层完成分类。
三、代码实现详解
1. DeformConv2d 的实现
DeformConv2d 是可变形卷积层的核心类,下面我们分步骤看看它是怎么实现的。
1.1 初始化
在 __init__ 方法里,定义了几个关键的参数:
- inc 和 outc:输入和输出通道数。
- kernel_size:卷积核大小,可以是整数(比如 3)或者元组(比如 (3, 3))。
- stride 和 padding:步幅和填充,用于控制卷积的输出尺寸。
- modulation:是否启用调制机制。
- p_conv:偏移网络,用来预测偏移量。
- m_conv:调制网络(如果启用),用来预测调制标量。
- conv:主卷积层,执行最后的卷积操作。
偏移网络 p_conv 的输出通道数是 2 * kernel_height * kernel_width,因为每个采样点需要水平和垂直两个偏移值。调制网络 m_conv 的输出通道数是 kernel_height * kernel_width,对应每个采样点的权重。
1.2 前向传播
forward 方法是可变形卷积的执行流程,我们一步步拆解:
-
计算偏移量
offset = self.p_conv(x) # (256, 18, 128, 9)
通过 p_conv 从输入 x 中预测偏移量。假设卷积核是 3x3,输出通道就是 18(9 个采样点 × 2 个方向)。
-
计算调制标量(可选)
if self.modulation: m = torch.sigmoid(self.m_conv(x))如果启用了调制,用 m_conv 预测调制标量,并用 sigmoid 函数归一化。
-
调整采样位置
p = self._get_p(offset, dtype) # (256, 18, 6, 512)
_get_p 方法结合原始采样点和偏移量,计算出调整后的采样坐标。原始采样点是一个规则网格(由 _get_p_n 生成),加上偏移量后变成灵活的分布。
-
双线性插值
x_q_lt = self._get_x_q(x, q_lt, N) x_q_rb = self._get_x_q(x, q_rb, N) x_q_lb = self._get_x_q(x, q_lb, N) x_q_rt = self._get_x_q(x, q_rt, N) x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \ g_rb.unsqueeze(dim=1) * x_q_rb + \ g_lb.unsqueeze(dim=1) * x_q_lb + \ g_rt.unsqueeze(dim=1) * x_q_rt这里先算出偏移点周围的四个整数坐标(左上、右下等),然后根据距离计算权重(g_lt 等),用加权平均得到偏移点的特征值。
-
应用调制
if self.modulation: x_offset *= m如果启用了调制,把调制标量乘到特征值上,调整每个采样点的重要性。
-
重塑并卷积
x_offset = self._reshape_x_offset(x_offset, ks) out = self.conv(x_offset)
_reshape_x_offset 把偏移后的特征重塑成适合卷积的形状,然后通过 conv 层完成卷积操作。
1.3 辅助函数
- _get_p_n:生成卷积核采样点的相对位置,比如 3x3 核会有 9 个点的坐标。
- _get_p_0:生成输出特征图每个位置的中心坐标。
- _get_p:结合偏移量,算出最终的采样坐标。
- _get_x_q:用双线性插值获取偏移点的特征值。
- _reshape_x_offset:把插值后的特征重塑为卷积需要的形状。
2. DeformableConvolutionalNetwork 的实现
DeformableConvolutionalNetwork 是整个DCN模型的封装,结构如下:
2.1 初始化
self.layer = nn.Sequential( DeformConv2d(1, 64, 3, 2, 1, modulation=True), nn.BatchNorm2d(64), nn.ReLU(), DeformConv2d(64, 128, 3, 2, 1, modulation=True), nn.BatchNorm2d(128), nn.ReLU(), DeformConv2d(128, 256, 3, 2, 1, modulation=True), nn.BatchNorm2d(256), nn.ReLU(), DeformConv2d(256, 512, 3, 2, 1, modulation=True), nn.BatchNorm2d(512), nn.ReLU() ) self.ada_pool = nn.AdaptiveAvgPool2d((1, 4)) self.fc = nn.Linear(512*4, category)- layer:四个可变形卷积层,通道数从 1 增加到 512,步幅为 2,逐步降低分辨率。
- ada_pool:自适应平均池化,把特征图压缩到 [batch, 512, 1, 4]。
- fc:全连接层,输出分类结果。
2.2 前向传播
def forward(self, x): x = x.permute(0, 1, 3, 2) # [b, c, modal, series] x = self.layer(x) x = self.ada_pool(x) # [b, 512, 1, 4] x = x.view(x.size(0), -1) x = self.fc(x) return x- 先调整输入维度,把 [b, c, series, modal] 变成 [b, c, modal, series]。
- 通过 layer 提取特征。
- 用池化和全连接层输出分类结果。
四、PAMAP2数据集实战结果
DCN的出现,很好地弥补了传统CNN在处理复杂场景时的不足。它在图像分类、目标检测、语义分割等任务中都有广泛应用,下面我们将以PAMAP2数据集为例,实现DCN在PAMAP2数据集上的实际应用结果。
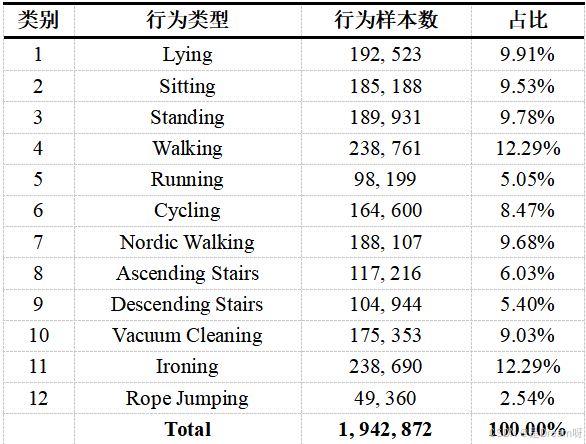
PAMAP2行为识别数据集由德国研究团队构建,通过多模态传感器记录人体日常活动特征。研究团队在9名受试者的胸部、右手腕和右脚踝处安装Trivisio Colibri无线传感装置,该设备以100Hz采样率同步捕获三轴加速度、角速度及磁场强度等9维运动数据,形成总规模达194万条的连续行为记录库。数据集涵盖躺卧、坐姿、站立等静态姿势,以及步行、跑步、骑行等12类动态活动,各类别样本分布均衡且具有典型性,为算法训练提供了丰富的现实场景数据。针对不同行为的时间跨度特征,实验采用170个采样点的窗口长度配合85点的滑动步长进行数据分割,在确保单个窗口完整包含行为周期特征的同时,通过数据重叠策略有效扩充训练样本规模,显著提升后续模型的识别性能。
1.训练结果
| Metric | Value |
| Parameters | 1,684,587 |
| FLOPs | 113.48 M |
| Inference Time | 7.81 ms |
| Val Accuracy | 0.9880 |
| Test Accuracy | 0.9807 |
| Accuracy | 0.9807 |
| Precision | 0.9811 |
| Recall | 0.9807 |
| F1-score | 0.9806 |
2.每个类别的准确率
每个类别的准确率:
Lying: 1.0000
Sitting: 0.9790
Standing: 1.0000
Walking: 0.9728
Running: 0.9868
Cycling: 0.9764
Nordic Walking: 1.0000
AscendStairs: 0.9889
DescendStairs: 0.9012
VacuumClean: 0.9926
Ironing: 0.9784
RodeJump: 0.9211
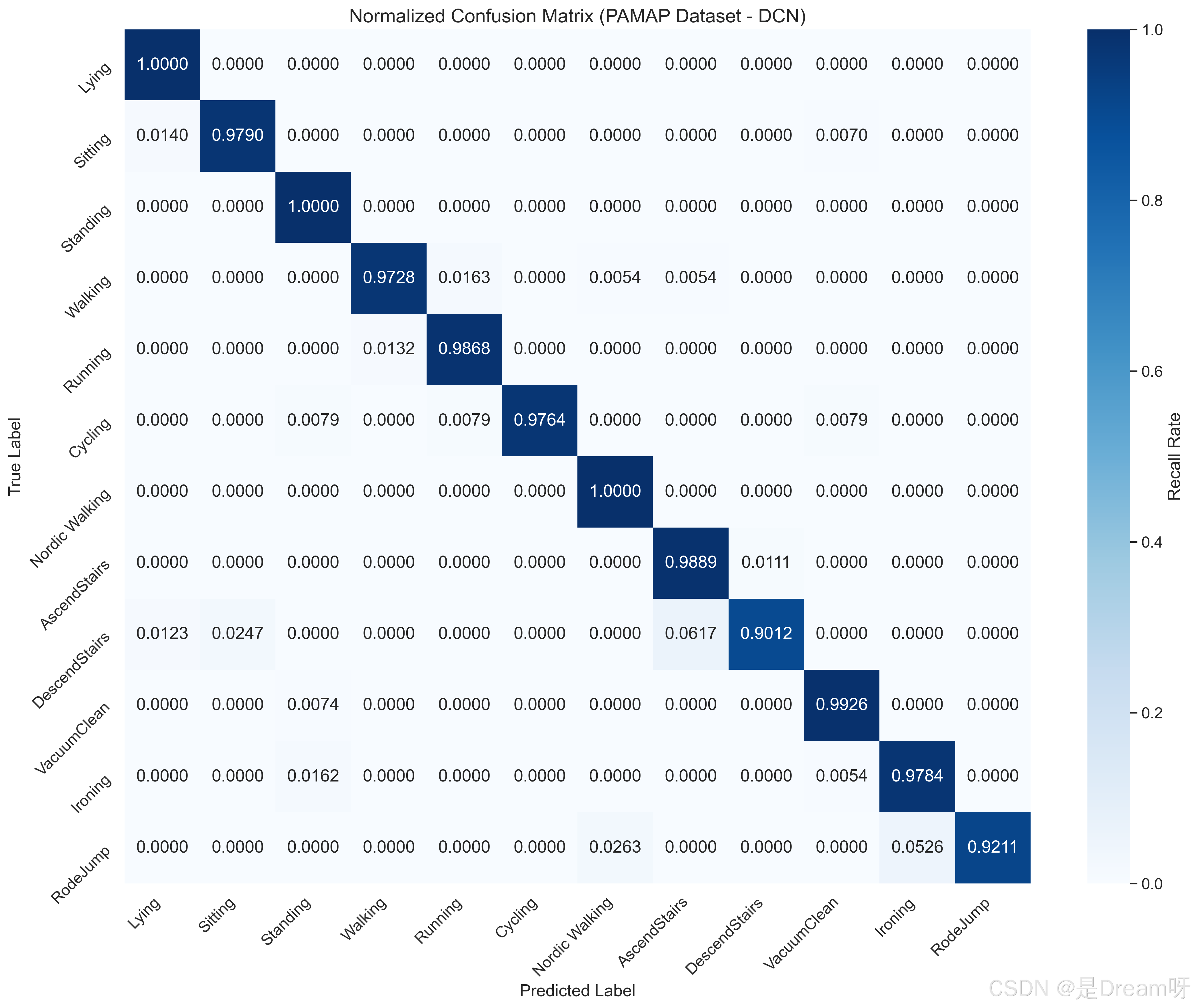
3.混淆矩阵图及准确率和损失曲线图
对角线表现:对角线上的值表示正确分类的比例。大多数类别的对角线值接近1.0,例如Lying(1.000)、Standing(1.000)、Nordic Walking(1.000)和Cycling(1.000),显示出模型的高准确率。
误分类情况:
AscendStairs:61.7%的样本被误分类为Nordic Walking,这可能是因为两者都涉及腿部运动和向上移动的模式,导致传感器数据相似。
RodeJump:52.6%的样本被误分类为Ironing,可能由于手臂运动的相似性或数据模式的混淆。
DescendStairs:7.4%的样本被误分类为Standing,这可能与下楼时的短暂稳定状态类似站立有关。
这些误分类表明,DCN在处理某些动态或相似的动作时仍有改进空间。未来可以通过引入时序信息、增加传感器维度或数据增强来减少混淆。
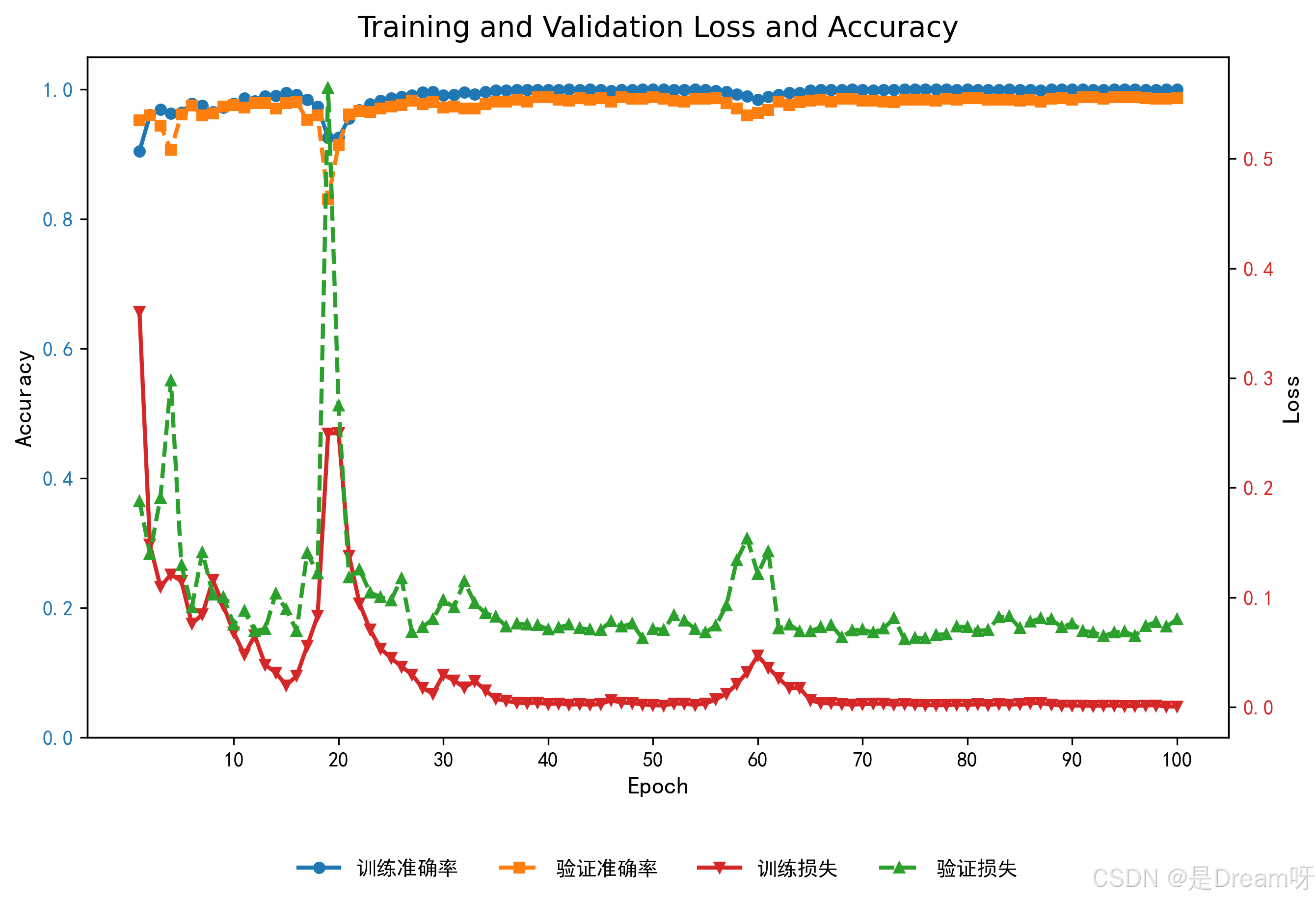
在前10个epoch内,训练和验证准确率迅速从约0.1上升至0.9,损失从0.7下降至0.2以下,显示出DCN对数据集的快速适应能力。在10-50个epoch间,准确率稳定在0.95-1.0,损失逐渐下降,但验证损失在某些epoch(如20和60)出现波动,可能由于验证集中某些类别样本分布不均。最终验证准确率为0.9880,测试准确率为0.9807,表明模型泛化良好,过拟合程度低。
总结
可变形卷积网络(DCN)在PAMAP2数据集上表现出色,测试准确率达到0.9807,F1-score为0.9806,验证准确率为0.9880。其参数量(1,684,587)、FLOPs(113.48M)和推理时间(7.81ms)显示出高效的计算性能,使其非常适合实时活动识别应用,例如可穿戴设备。
尽管DCN已展现出优越的性能,未来仍可通过以下方式进一步优化:
- 改进误分类:针对DescendStairs和RodeJump等类别,引入时序建模(如RNN或LSTM)或数据增强,增强模型对动态动作的区分能力。
- 提升鲁棒性:增加多模态数据或上下文特征,进一步提高模型对复杂场景的适应性。
总的来说,DCN通过其灵活的采样机制,很好地弥补了传统CNN在处理物体形变和多尺度变化时的不足,在PAMAP2数据集上的成功应用证明了其在活动识别领域的巨大潜力。
本期推荐1:《Python网络爬虫开发从入门到精通》
《Python网络爬虫开发从入门到精通》
学爬虫、抓数据、提内容、存数据、懂反爬、学框架、用A1、会部署、重实战……

京东:https://item.jd.com/14391507.html
便于决策:获取大量数据深入分析,为业务决策提供更有力支持。
利于竞争:收集竞争信息,更好地了解市场动态和竞争对手策略。
学术研究:获取研究数据,在多个领域发挥重要作用。
开发应用:创建个性化应用,满足特定需求。
技能提升:掌握爬虫技能,帮助在求职中脱颖而出。
AI助力:借助AI,轻松学习爬虫技能
前景广泛:随着大数据和人工智能的发展,有助于适应未来技术发展趋势。
内容简介
本书共分4篇,针对Python爬虫初学者,从零开始系统地讲解了如何利用Python进行网络爬虫程序开发。
第1篇快速入门篇:主要介绍了Python环境搭建和基础语法知识、爬虫入门知识及基本的使用方法、Ajax数据的分析和抓取、动态渲染页面数据的爬取、网站代理的设置与使用、验证码的识别与破解,以及App数据抓取、数据的存储方法等内容。
第2篇技能进阶篇:主要介绍了PySpider和Scrapy两个常用爬虫框架的基本使用方法、爬虫的部署方法,以及数据分析、数据清洗常用库的使用方法。
第3篇项目实战篇:以2个综合实战项目,详细讲解了Python数据爬虫开始与实战应用。本篇对全书内容进行了总结回顾,强化读者的实操水平。
第4篇技能拓展篇:从数据爬取、数据清洗和数据分析三个角度,介绍了一常用AI技术的实用技巧。运用这些技巧,读者可以提高网络爬虫程序的编写速度和数据分析效率。
本书案例丰富,注重实战,既适合Python程序员和爬虫爱好者阅读学习,也适合作为广大职业院校相关专业的教学用书。
本期推荐2:《人工智能大模型导论》
《人工智能大模型导论》
涵盖人工智能大模型的技术发展、模型微调与部署、在各领域的应用,详解人工智能大模型基础理论,辅以实训案例,聚焦核心技术与应用,引领AI技术新潮流

京东:https://item.jd.com/14963104.html
全面解读基础知识:介绍人工智能大模型基础知识,适合新手入门
详细介绍大模型底层逻辑:详解语言模型、神经网络语言模型、与训练语言模型、大模型的技术发展、微调与部署,以及大模型在各领域的优化应用
深入解析场景应用:在各领域进行优化,深入浅出解析人工智能应用
清晰介绍实战步骤:有理论有实训,介绍了人工智能大模型底层逻辑与技术,以及在实际中的应用,步骤清楚,条理清晰,即学即用
内容简介
本书采用理论与实训案例相结合的形式,深入浅出地介绍了大模型的基础知识。本书共分为8章,内容涵 盖大模型的基础知识、传统语言模型基础知识、神经网络基础知识、大模型的主要技术、大模型的微调与部署、 大模型的应用,以及面对的挑战和未来发展等。
本书不仅适合作为高等院校人工智能、计算机科学与技术或相关专业学习大模型的入门教材,也适合从事相关工作的人工智能爱好者和工程师学习阅读。
-
-



