
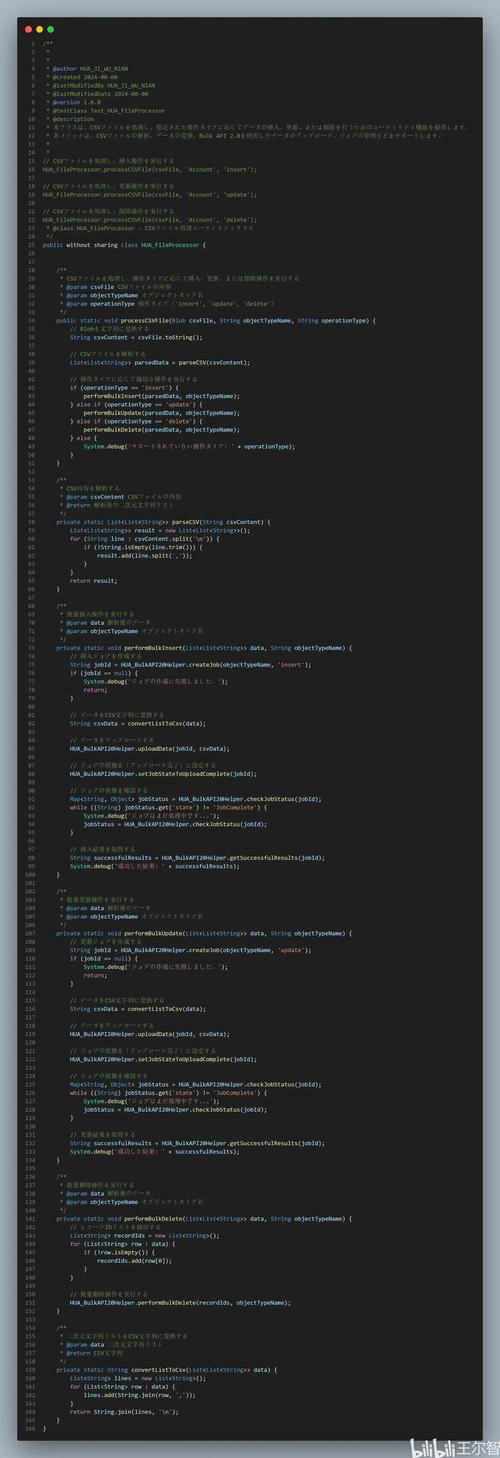
linux csv api?

,在Linux环境下,处理CSV文件可通过多种API和工具实现。 ,1. **Python库**(如csv模块或pandas)提供跨平台支持,适合脚本处理; ,2. **命令行工具**(如awk、sed或csvkit)支持快速文本操作; ,3. **C/C++库**(如libcsv或fast-cpp-csv-parser)适用于高性能场景; ,4. **数据库工具**(如SQLite的.import命令)可直接导入CSV。 ,开发者可根据需求选择:轻量级任务推荐命令行或Python,而大规模数据处理可能需要C++库或数据库集成,注意处理编码、分隔符等兼容性问题。
Linux环境下高效处理CSV文件的全面指南
CSV文件处理的重要性与挑战
在当今数据驱动的时代,CSV(Comma-Separated Values)文件因其简单、通用和跨平台特性,已成为数据交换的事实标准格式,无论是数据分析师、系统管理员还是开发人员,掌握高效的CSV文件处理技术都是必备技能,Linux环境提供了丰富的工具链和API,能够满足从简单查询到复杂数据处理的各种需求。
本文将系统介绍Linux环境下处理CSV文件的多种方法,涵盖以下核心内容:
- 命令行工具的高效运用 - 快速数据提取与转换
- Python生态的强大支持 - 灵活的数据处理方案
- API集成与自动化 - 现代数据获取与处理流程
- 性能优化与最佳实践 - 处理大规模数据的专业技巧
命令行工具:CSV处理的瑞士军刀
1 基础工具组合应用
Linux命令行提供了一系列专为文本处理设计的工具,它们组合使用可以高效处理CSV文件:
# 查看文件前5行
head -n 5 data.csv
# 统计文件行数
wc -l data.csv
# 查看文件结构
awk -F ',' 'NR==1{print NF " columns detected"}' data.csv
2 高级awk技巧
awk是处理结构化数据的终极工具,其内置编程能力支持复杂数据处理:
# 计算某列统计值
awk -F ',' 'NR>1 {sum+=$3; count++} END {print "Average: " sum/count}' data.csv
# 处理带引号的CSV
awk -F ',' 'BEGIN {FPAT = "([^,]+)|(\"[^\"]+\")"} {print $1, $3}' quoted_data.csv
# 多文件关联处理
awk -F ',' 'NR==FNR{a[$1]=$2; next} $1 in a{print $0, a[$1]}' file1.csv file2.csv
3 专业CSV处理工具
对于复杂CSV文件,专用工具能更好处理特殊情况:
# 使用csvkit工具集 csvcut -c 1,3,5 data.csv # 列提取 csvgrep -c 2 -m "pattern" data.csv # 模式匹配 csvstat data.csv # 统计信息 # 使用Miller进行类数据库操作 mlr --csv filter '$age > 30' then sort -n age data.csv
Python生态系统:数据处理的工业级方案
1 标准库的进阶用法
Python的csv模块支持多种高级特性:
import csv
from collections import defaultdict
# 处理含特殊字符的CSV
with open('complex.csv', newline='') as f:
reader = csv.reader(f, delimiter='|', quotechar='"', escapechar='\\')
for row in reader:
print(row)
# 列聚合计算
sales = defaultdict(float)
with open('sales.csv') as f:
reader = csv.DictReader(f)
for row in reader:
sales[row['region']] += float(row['amount'])
2 Pandas的高效数据处理
Pandas提供了DataFrame这一强大抽象:
import pandas as pd
# 内存映射处理超大文件
df = pd.read_csv('large.csv', memory_map=True)
# 分块处理
chunk_iter = pd.read_csv('huge.csv', chunksize=10000)
results = []
for chunk in chunk_iter:
results.append(chunk.groupby('category').sum())
final_result = pd.concat(results)
# 多文件并行处理
from concurrent.futures import ThreadPoolExecutor
def process_file(file):
return pd.read_csv(file).query('value > 100')
with ThreadPoolExecutor() as executor:
results = list(executor.map(process_file, ['file1.csv', 'file2.csv']))
3 类型优化与性能提升
# 优化数据类型减少内存
dtypes = {
'id': 'int32',
'price': 'float32',
'category': 'category'
}
df = pd.read_csv('data.csv', dtype=dtypes)
# 使用PyArrow引擎加速
df = pd.read_csv('data.csv', engine='pyarrow')
# 预处理后再解析日期
df = pd.read_csv('dates.csv', parse_dates=['timestamp'], date_parser=pd.to_datetime)
现代数据管道:API集成与自动化
1 高效API交互模式
import requests
import pandas as pd
from retrying import retry
@retry(stop_max_attempt_number=3, wait_exponential_multiplier=1000)
def fetch_csv_data(url, params=None):
headers = {
'User-Agent': 'DataProcessor/1.0',
'Accept': 'text/csv'
}
response = requests.get(url, headers=headers, params=params, timeout=30)
response.raise_for_status()
return pd.read_csv(StringIO(response.text))
# 流式处理API响应
def stream_large_csv(url):
with requests.get(url, stream=True) as r:
r.raise_for_status()
for line in r.iter_lines():
if line:
yield line.decode('utf-8')
2 自动化工作流设计
from prefect import flow, task
from datetime import timedelta
@task(retries=3, retry_delay_seconds=10)
def extract_data(url):
return pd.read_csv(url)
@task
def transform_data(df):
return df[df.quality_score > 0.8]
@flow
def etl_flow():
raw_data = extract_data("https://api.example.com/data.csv")
clean_data = transform_data(raw_data)
clean_data.to_csv("processed_data.csv")
# 定时调度
etl_flow.schedule = interval_schedule(interval=timedelta(hours=1))
性能优化与异常处理
1 大规模数据处理策略
| 策略 | 适用场景 | 实现方法 |
|---|---|---|
| 分块处理 | 内存不足 | pandas.read_csv(chunksize=) |
| 内存映射 | 快速随机访问 | pandas.read_csv(memory_map=True) |
| 列式读取 | 只需部分列 | usecols参数 |
| 数据类型优化 | 减少内存占用 | 指定dtype参数 |
| 多进程处理 | CPU密集型 | concurrent.futures |
2 健壮性增强技巧
def safe_csv_reader(file):
try:
with open(file, newline='') as f:
dialect = csv.Sniffer().sniff(f.read(1024))
f.seek(0)
reader = csv.reader(f, dialect)
return list(reader)
except csv.Error as e:
print(f"CSV parsing error: {e}")
return None
except FileNotFoundError:
print("File not found")
return None
可视化与报告生成
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('sales.csv')
summary = df.groupby('region')['amount'].agg(['sum', 'mean', 'count'])
# 自动生成报告
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
summary.plot.bar(ax=axes[0], title='Sales by Region')
df['amount'].plot.hist(ax=axes[1], bins=20, title='Amount Distribution')
plt.tight_layout()
plt.savefig('sales_report.png')
summary.to_csv('sales_summary.csv')
构建高效数据处理体系
掌握Linux环境下CSV处理的完整技术栈,您将能够:

- 根据场景选择最佳工具组合
- 处理从KB到TB级别的CSV数据
- 构建自动化数据管道
- 优化处理性能与资源使用
无论是临时数据分析还是生产级数据处理系统,这些技能都将大幅提升您的工作效率,建议从简单任务开始实践,逐步构建更复杂的处理流程,最终形成适合自己的高效工作模式。
扩展阅读方向:
- 分布式CSV处理(Dask、Spark)
- 云原生数据处理架构
- 实时流式CSV处理
- 数据质量验证框架
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



