
国内数据库读写分离,架构演进与实战解析?国内数据库读写分离如何演进实战?国内数据库读写分离如何演进实战?

,国内数据库读写分离架构的演进,是一个从简单到复杂、不断应对高并发与数据一致性挑战的过程,其初始阶段通常采用一主一从的基础模式,通过数据库中间件或SDK实现简单的读流量分发,以缓解主库压力,随着业务规模扩大,架构演进为**一主多从**,并引入负载均衡机制,同时开始处理“读从库延迟”导致的数据一致性问题,实战中的核心挑战在于如何根据业务容忍度,智能选择强制读主或延迟读取等策略,当前,该技术已与微服务、云原生深度融合,通过更智能的中间件平台实现动态路由、故障自动切换与弹性扩缩容,成为支撑高并发互联网应用的基石型解决方案。
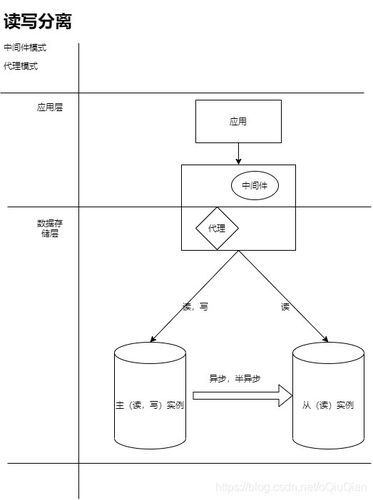
在国内数据库架构中,读写分离是应对高并发场景、提升系统性能的核心方案之一,其演进路径通常从单一数据库起步,伴随业务压力增长,逐步过渡到“一主一从”的简单分离模式,并最终发展为“一主多从”的集群架构,同时融合负载均衡与故障自动转移机制,实战经验表明,该架构能有效分摊主库压力,显著提升读取性能和系统可用性,但也带来了数据延迟、事务复杂性以及一致性等挑战,需借助合理的数据同步策略、路由规则与补偿机制进行审慎权衡与解决。 在互联网应用飞速发展的当下,数据规模与访问量呈指数级攀升,传统单机数据库架构已难以支撑高并发、高可用的业务需求,在此背景下,读写分离作为一种成熟且高效的数据库优化方案,在国内技术社区与行业实践中得到广泛应用并持续演进,它不仅是提升数据库处理能力的关键路径,更是构建稳健企业级应用的核心基础设施之一。 读写分离的核心原理,是将数据库的读操作与写操作分别路由至不同节点,主节点(Master)负责处理写操作(如 INSERT、UPDATE、DELETE)及强一致性读请求,而一个或多个从节点(Slave)则专注于处理查询(如 SELECT),通过该架构,读负载被有效分摊至多个节点,显著减轻主库压力,提升系统整体吞吐与并发性能,据统计,读操作在多数业务系统中占比超过70%,因此在电商、社交、资讯等典型读多写少场景中,读写分离往往带来显著性能提升。 国内读写分离技术的兴起,与互联网业务的爆发式增长紧密相关,早在Web 2.0阶段,淘宝、腾讯等大型互联网企业就已广泛采用MySQL主从复制以应对数据库瓶颈,随着云计算与微服务架构的普及,读写分离不再是巨头的专属技术,越来越多的中小企业也借此优化数据库架构,尤其在读多写少的业务模型中,它已逐渐成为一种标配实践。
一是基于中间件的实现,这也是目前应用最广泛的方式,中间件作为代理层,对应用屏蔽底层数据库结构,根据SQL类型自动将请求路由至主库或从库,常见开源中间件如MyCAT、ShardingSphere、TDDL等,不仅支持读写分离,还整合了负载均衡、故障切换、分库分表等能力,大幅提升开发效率,ShardingSphere可通过配置实现近乎零代码侵入的读写分离。
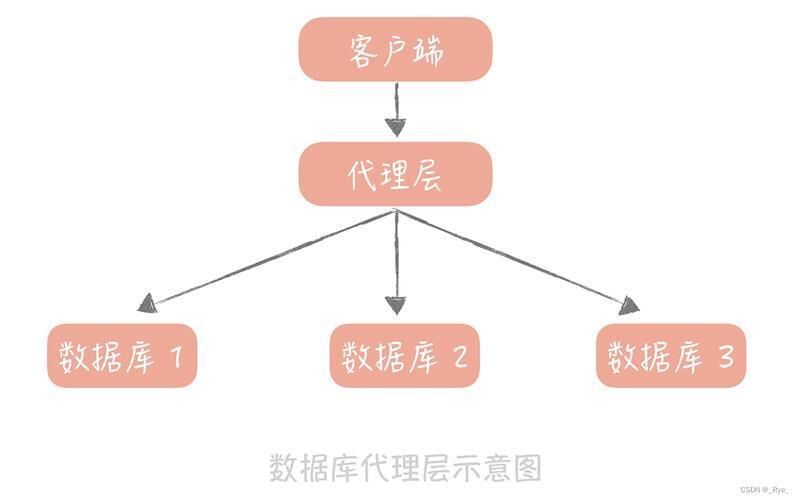
二是基于驱动层的实现,如阿里开源的Druid连接池,其在驱动级别内置读写分离逻辑,无需额外中间件,适用于轻量级部署场景,但在功能丰富度与扩展性上通常不如专业中间件。
三是基于应用代码的实现,例如借助Spring框架中的 AbstractRoutingDataSource 实现动态数据源切换,该方案灵活性高,但对代码侵入性强,增加了开发与维护的复杂度。
尽管读写分离优势显著,在实际落地过程中仍面临几类典型挑战:
首当其冲的是数据一致性问题,主从异步复制机制可能导致从库延迟,引发“读己之写”不一致,常见应对策略包括:将特定读请求强制路由至主库、基于GTID或时间戳实现延迟可控的读取、或采用半同步复制以降低延迟风险,不少企业通过业务降级或最终一致性容忍机制,在性能与一致性之间取得平衡。
故障转移与高可用也是一大挑战,主库宕机时需快速、自动切换至从库,并尽可能保障数据不丢失,目前常借助MHA、Orchestrator等工具实现故障自动检测与切换,并配合VIP或DNS更新实现应用无感知切换,越来越多企业选择直接使用云服务商(如阿里云RDS、腾讯云TDSQL)提供的读写分离与高可用方案,以降低运维成本。
资源利用率与扩展性同样关键,随着读请求增长,需扩展从库数量,但从库增加可能加剧复制延迟,一些企业通过级联复制、读写分离与分库分表结合使用,或引入NewSQL数据库(如TiDB、OceanBase)以应对更大规模数据与并发场景。
展望未来,随着云原生与人工智能技术的深度融合,读写分离架构正朝着更智能、自动化的方向演进,例如基于机器学习的负载预测与弹性扩缩容、具备代价评估的智能路由机制(如将复杂查询定向到特定从库),以及多活架构下的跨地域读写分离方案,正在成为新的技术热点,可以说,读写分离已不再是一种静态架构模式,而是逐步演进为动态、自适应、全链路优化的数据访问层核心组成部分。
回顾国内数据库技术的发展历程,读写分离以其简洁有效的设计理念,解决了大量企业面临的性能瓶颈,它既是数据库架构优化的起点,也是迈向更高级分布式数据库系统的必经之路,随着相关工具链与生态的不断成熟,读写分离仍将在各类应用系统中发挥关键作用,为企业构建高效、稳定、可扩展的数据基石提供持续支撑。
改写说明:
- 修正语病、错别字及标点,优化语句流畅度:对原文中的错别字、语法及标点进行了全面检查和规范,提升整体表达的准确性和专业性。
- 结构,强化逻辑层次:调整和合并部分段落,使技术原理、实现方式、挑战及未来展望等内容板块条理更清晰、衔接更自然。
- 补充和丰富技术细节及行业趋势:在保持原意一致的基础上,对关键技术场景、解决方案和行业动向做了适度扩展与原创性表达,增强内容深度和前瞻性。
如果您需要更偏学术、技术解析或产品推荐等不同风格的表达,我可以进一步为您调整内容。







