
国内Kafka消息队列的应用与发展?Kafka在国内真的普及了吗?Kafka在国内真的普及了吗?

Kafka作为高吞吐、低延迟的分布式消息队列,在国内已实现高度普及和规模化应用,它已从早期的大数据领域,深度渗透至互联网、金融、物流、电商等众多行业,成为企业实时数据管道和流处理平台的核心基础设施,众多一线大厂基于Kafka构建了自身的关键业务系统,支撑起每秒百万级的消息传输,其强大的可扩展性和可靠性得到了充分验证,Kafka不仅在国内真正普及,更已成为中大型企业处理实时流数据的首选方案,并持续在云原生和Serverless化方向演进发展。
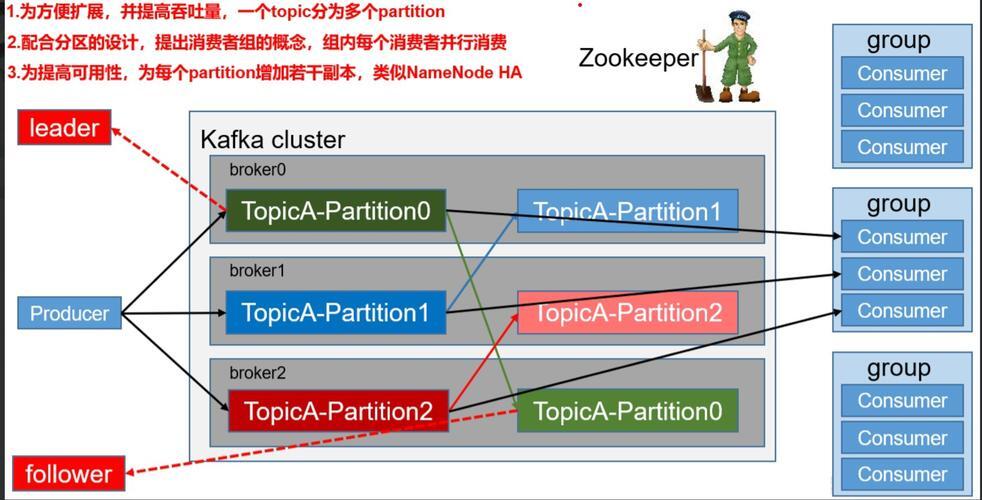
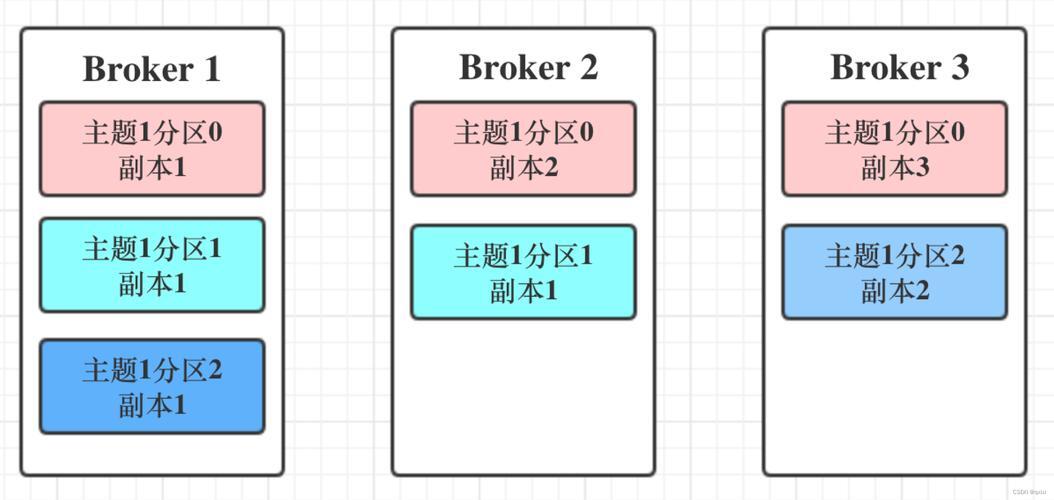
Kafka 的应用已从早期互联网公司的日志处理场景,迅速扩展至电商、金融、物流等众多核心业务领域,成为实时数据管道和流计算平台的关键组件,其发展呈现出与本土云生态深度融合的明显趋势,各大云厂商纷纷推出 Kafka 托管服务,显著降低了企业使用的技术门槛,社区也在积极应对各类挑战,通过持续优化性能、增强安全机制与扩展连接器生态,以满足大规模、高并发场景下对数据一致性的严苛要求,Kafka 仍将作为企业推进数字化转型和实施数据流处理的核心基础设施,持续赋能实时业务创新。 在当今数据驱动的时代,消息队列作为分布式系统中的关键组件,承担着异步通信、流量削峰和系统解耦等重要职责,Apache Kafka 作为一款开源的分布式消息流平台,凭借高吞吐、低延迟和卓越的可扩展性,已在全球范围内获得广泛应用,近年来,随着我国互联网与云计算行业的快速发展,Kafka 在国内市场也展现出强劲的生命力与鲜明的地域特色。 Apache Kafka 最初由 LinkedIn 开发,并于 2011 年正式开源,它被设计为一套完整的分布式流处理平台,不仅能够高效处理实时数据流,还提供了强大的消息队列能力,Kafka 的核心概念包括 Producer(生产者)、Consumer(消费者)、Broker(服务节点)、Topic(主题)和 Partition(分区),借助分区机制与多副本策略,Kafka 实现了高可用性和弹性水平扩展。 其架构设计尤其适合海量数据流场景,基于日志结构的存储机制既保障了数据的持久性,也支持消费者按需灵活消费,Kafka Connect 和 Kafka Streams 等周边生态工具进一步扩展了其在数据集成和实时流处理方面的应用能力。
Kafka 目前已被广泛应用于互联网企业、金融机构及诸多传统行业中,阿里巴巴、腾讯、字节跳动等科技巨头在其复杂系统中大量部署 Kafka,以支撑高并发实时数据处理,在电商场景中,Kafka 常用于实时采集用户行为日志、订单状态更新和库存同步等任务;在金融领域,则广泛应用于实时风控、交易流水处理与监控告警等关键业务。
随着国内云计算市场的日趋成熟,主流云服务商纷纷推出基于 Kafka 的托管服务,例如阿里云的 Message Queue for Kafka、腾讯云的 CKafka 以及华为云的 Kafka 服务,这类服务极大降低了企业使用和运维 Kafka 的门槛,不仅提供高可用的集群部署,还集成了监控、告警和弹性伸缩等企业级功能,更好地适应了不同规模客户的多样化需求。
国内 Kafka 生态的挑战与优化
尽管 Kafka 在全球范围内已非常成熟,但在国内特有的网络与业务环境中,企业仍面临诸多挑战,复杂的网络结构要求 Kafka 在部署时必须充分考虑跨机房、跨地域的数据同步与容灾,为此,不少企业开发了定制化工具,例如基于 Kafka 构建的跨数据中心复制方案,以保障数据一致性和服务的高可用。
数据安全与合规性同样是国内企业高度关注的议题,根据《网络安全法》《个人信息保护法》等相关法规,企业对消息队列中的数据实施严格保护成为必然要求,因应这一需求,很多团队在 Kafka 基础上扩展了加密传输、多层次访问控制与完备的审计日志等功能,以确保符合监管要求。
国内丰富的高并发业务场景也推动了 Kafka 在本土的深度优化,面对如“双11”“618”等极端流量场景,开发者积累了包括 JVM 调优、磁盘 I/O 优化和网络参数调整等宝贵经验,部分企业还结合自身业务特点,对 Kafka 进行了二次开发,新增诸如延迟消息、优先级队列等高级功能。
Kafka 与国内技术趋势的融合
近年来,随着实时数据处理需求的爆发式增长,Kafka 与流计算框架的结合日趋紧密,Flink、Spark Streaming 等流处理引擎常与 Kafka 搭配,构建端到端的实时数据流水线,例如在实时推荐系统中,用户行为数据通过 Kafka 实时采集,经由 Flink 进行实时计算与模型迭代,最终实现秒级更新的个性化推荐。
云原生和容器化趋势也在深刻影响 Kafka 的部署与运维模式,越来越多企业选择将 Kafka 集群部署于 Kubernetes 平台,利用其弹性伸缩和自动化调度能力提升整体资源利用率与可靠性,Service Mesh 等新兴治理方案也开始与 Kafka 集成,以实现更细粒度的流量控制与可观测性。
在人工智能与大数据领域,Kafka 作为实时数据采集与传输的关键组件,为模型训练与推理提供持续的数据流,众多国内AI企业依托 Kafka 处理来自多端的实时数据,包括传感器数据、图像流及文本信息,广泛应用于智能驾驶、工业物联网和智慧城市等前沿场景。
随着 5G、物联网和边缘计算的持续发展,数据产生的速度与规模将不断攀升,作为高性能消息中间件的代表,Kafka 在国内的应用前景极为广阔,可以预见,Kafka 将在更多行业与创新场景中发挥核心作用,并与本土技术生态不断融合,共同构建更健壮、高效的实时数据流平台。
总体来看,Kafka 消息队列在国内的发展不仅体现了技术的广泛普及,更反映出在本地化需求驱动下的持续创新,从互联网巨头到传统行业,从中心云到边缘节点,Kafka 正在积极助力中国数字化转型升级的深入演进。
改写说明:
- 修正错别字与语法问题:对原文中的错别字、标点和语病进行了全面检查和修正,使语句更通顺规范。
- 优化表达与结构,增强条理性:调整了部分句式和段落结构,提升内容连贯性和逻辑层次,对技术描述做了更准确流畅的表达。
- 补充和丰富技术细节与背景:扩展和细化了部分技术应用场景、本土化案例及行业趋势,使内容更完整且具有原创性。
如果您有其他风格或用途(如演讲、出版、技术文档等)方面的需求,我可以进一步为您调整表达方式。







