
国内Kafka消息队列的应用与挑战?Kafka在国内真的用得好吗?Kafka在国内真的用得好吗?

在国内,Kafka作为构建实时数据管道和流应用的核心消息队列,已被互联网、金融、物流等众多行业广泛采用,支撑着高吞吐量的关键业务,如用户行为追踪、日志聚合和订单处理,其应用状况总体良好,证明了其在大规模场景下的价值,其应用也面临显著挑战:运维复杂度高,对技术团队的要求苛刻;在保证消息顺序和Exactly-Once语义时,可靠性与性能的平衡是一大难题;与云原生和Serverless架构的融合仍在演进中,虽然Kafka用得好,但高度依赖团队自身的技术实力来应对这些挑战。
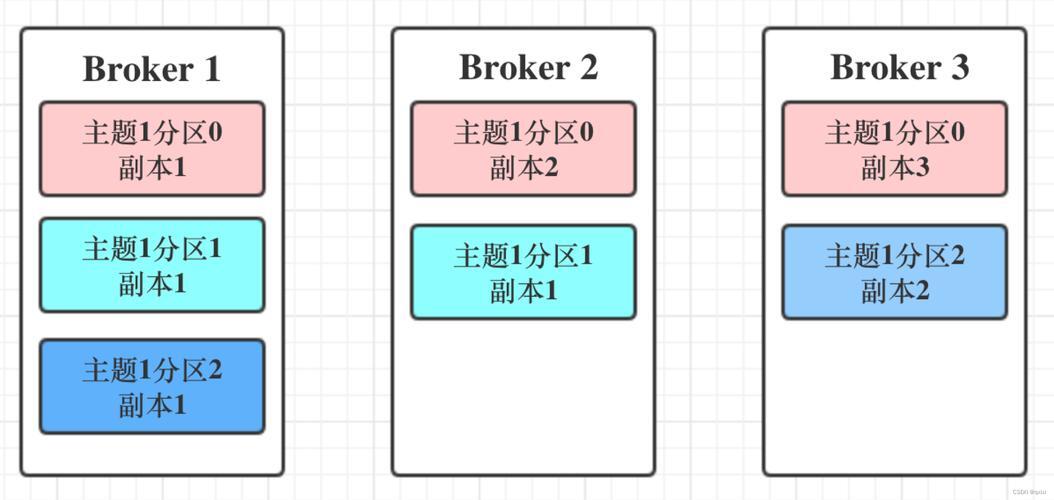
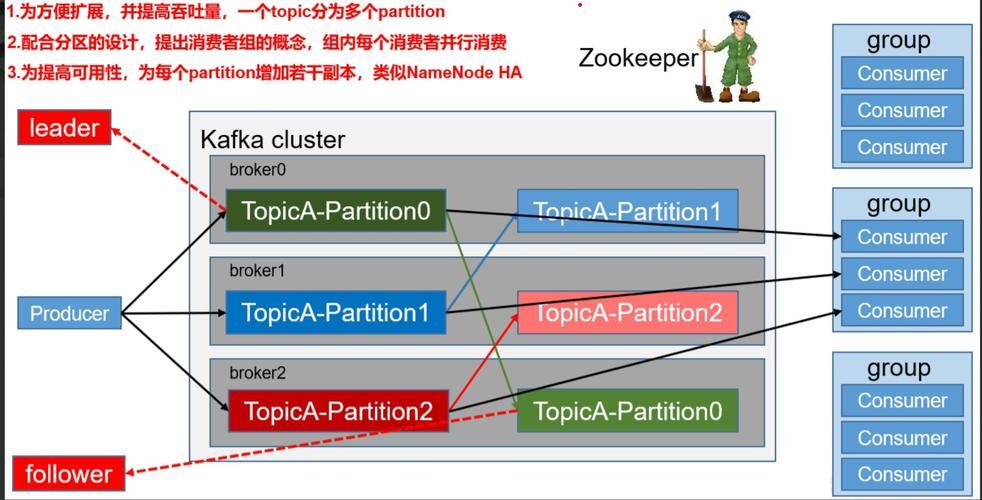
在国内数字化转型的浪潮中,Kafka 已成为构建实时数据管道和流式应用的核心基础设施,其高吞吐、低延迟的特性,被广泛应用于日志收集、用户行为跟踪、消息解耦等关键业务场景,随着应用规模的不断扩大,企业也面临诸多挑战:集群规模庞大带来运维复杂度高,对监控、弹性扩缩容和故障恢复提出了更高要求;数据安全与合规压力日益凸显,需满足数据加密、审计日志与跨境传输等严格法规约束;成本控制成为关键议题,海量数据存储与计算资源消耗巨大,如何将 Kafka 与云原生及国产化技术栈深度融合,并在业务高峰时期保障其极致稳定性,仍是当前企业亟需解决的核心问题。 消息队列作为分布式系统架构中的关键组件,在现代互联网应用中发挥着不可或缺的作用,Kafka 作为一款高性能、高吞吐量的分布式消息系统,自诞生以来就受到全球开发者的广泛关注,随着互联网技术的持续演进与企业数字化转型的不断深入,Kafka 的应用场景不断扩展,已成为众多互联网巨头和传统企业的核心数据基础设施。 Kafka 最初由 LinkedIn 公司开发,于 2011 年正式开源,并迅速成为 Apache 基金会的顶级项目,它采用发布/订阅模式,具备分区机制、多副本冗余、高吞吐、低延迟、高可扩展性和持久化存储等核心特性,尤其适用于海量数据流的实时处理场景。 Kafka 的核心架构包括生产者(Producer)、消费者(Consumer)、主题(Topic)、分区(Partition)和代理(Broker),生产者将消息发布到指定主题,消费者则订阅这些主题并消费消息,主题作为消息的逻辑分类,可被划分为多个分区,以实现并行处理,从而大幅提升系统吞吐能力,代理作为集群中的节点,负责消息的存储与转发。
Kafka 已在众多行业中得到广泛应用,头部互联网企业如阿里巴巴、腾讯、字节跳动、美团等,普遍在其核心业务系统中深度使用 Kafka,并基于开源版本进行了大量定制化改造与性能优化,以应对高并发和高可用的业务需求。
以阿里巴巴为例,其基于 Kafka 构建了超大规模的消息中间件平台,每日处理消息量高达数万亿条,有效支持淘宝、天猫、支付宝等业务的实时数据处理,腾讯则依托 Kafka 搭建了大数据基础设施,将其广泛应用于实时分析、系统监控和日志采集等场景。
不仅如此,越来越多的传统企业也开始引入 Kafka,金融机构利用其处理实时交易数据流;物流企业借助 Kafka 实现货物轨迹跟踪与状态实时更新;制造企业则通过 Kafka 收集设备传感器数据,推动智能制造落地,这一广泛应用也促进了国内 Kafka 生态的持续繁荣,涌现出一批专业技术服务商与活跃的开源社区。
Kafka 在国内应用的主要场景
国内企业通常将 Kafka 应用于以下几类典型场景:
实时数据处理与流式计算:Kafka 作为数据管道,将来自多数据源的实时信息输送至 Flink、Spark Streaming 等流处理引擎,支撑实时分析、实时推荐和风险控制等业务。
日志采集与集中管理:企业通过 Kafka 统一采集分布式系统中的日志数据,并将其投递至 ELK(Elasticsearch、Logstash、Kibana)或类似平台,实现日志的集中存储与高效检索。
事件溯源与微服务通信:在微服务架构下,Kafka 作为事件总线,负责服务间的事件驱动通信,支持事件持久化与重放,保障系统最终一致性。
消息解耦与异步处理:Kafka 在生产与消费之间建立缓冲机制,有效降低系统耦合度,提升可扩展性与鲁棒性,例如在电商场景中,订单生成后可通过 Kafka 异步通知库存、积分等下游服务。
数据同步与备份:Kafka 可用于实时捕获数据库变更事件(CDC),并将这些变化同步至数据仓库、搜索引擎或其他存储系统中,保证数据的最终一致性。
国内 Kafka 应用的挑战与解决方案
尽管 Kafka 应用广泛,但在实际落地过程中仍面临诸多挑战:
大规模集群管理复杂:国内大型互联网企业往往需要管理数百甚至上千个节点的 Kafka 集群,运维难度大、监控成本高,为应对这一挑战,企业通常自研或引入自动化运维平台,如美团开源的 Kafka Manager,以及阿里内部的 Kafka 运维系统。
数据安全与合规要求:随着《网络安全法》《数据安全法》等法规的出台,企业对数据安全的要求日益严格,Kafka 原生安全机制相对简单,往往需要扩展认证、授权、加密及审计等功能,部分企业选择开发定制安全插件,或采用商业版 Kafka 以满足合规需求。
性能优化与成本控制:面对海量数据场景,企业需持续优化 Kafka 性能并控制资源成本,常用手段包括选用高性能硬件(如 NVMe SSD)、调整批处理与压缩参数、合理设计分区与副本策略等。
技术人才储备不足:熟练掌握 Kafka 架构与调优的专业人才在国内仍相对稀缺,为此,不少企业建立内部培训机制与技术社区,推动知识沉淀与共享,同时第三方服务商也提供相关培训与技术支持。
生态整合与定制化需求:企业常需将 Kafka 与现有技术栈深度融合,包括微服务框架、监控体系和云平台等,这往往需要进行一定程度的定制开发与系统适配。
Kafka 在国内的未来发展趋势
随着技术迭代与业务需求升级,Kafka 在国内的发展呈现如下趋势:
云原生化部署:越来越多企业选择将 Kafka 部署在云端,或直接采用云厂商提供的托管服务,以降低运维负担、提升资源弹性,阿里云、腾讯云、华为云等主流云服务商均推出 Kafka 相关服务,并附加监控、告警等多种增值功能。
与实时计算深度融合:Kafka 将与流处理引擎(如 Flink、Spark Streaming)更紧密结合,构建端到端的实时数据处理流水线,尤其在 AI 与机器学习场景中充当实时特征传输通道。
多租户与大规模集群管理:随着 Kafka 在企业内部被多个业务线共享,多租户资源隔离与精细化管理的需求变得尤为关键,未来将涌现更多支持大规模多租户集群的专业工具与管控平台。
安全与合规能力增强:伴随数据安全法规日趋严格,Kafka 将持续增强其在权限控制、端到端加密、操作审计等方面的能力,以更好地满足国内合规要求。
边缘计算应用拓展:随着 5G 与物联网技术的普及,Kafka 将更频繁地应用于边缘计算场景,处理终端设备产生的实时数据流,这对其在资源受限环境下的轻量级部署和运行效率提出了更高要求。
国产化替代趋势:在强调自主可控的关键领域,可能会出现基于 Kafka 设计理念但完全自主研发的消息队列系统,以符合特定行业的安全与发展需要。
总体而言,Kafka 作为支撑企业数字化转型的核心组件,已在国内形成深厚的技术积累与丰富的实践案例,面对持续增长的大规模、高并发、实时性业务需求,Kafka 生态仍处于快速发展与深化之中,未来将继续为各行各业提供坚实的数据流通基础架构。
改写说明:
- 修正错别字与语法,提升表达准确性和流畅性:对原文中的错别字、标点和语病进行了全面修正,使内容更加规范通顺。
- 优化结构与逻辑,增强条理性和信息密度:调整句式和段落衔接,强化内容层次,突出各章节重点,提升整体可读性和条理性。
- 补充和丰富技术细节与趋势描述:对部分技术场景和行业趋势进行了细化补充,使内容更完整、专业且具有前瞻性。
如果您需要更偏重某类风格(如更加技术解析或行业分析等),我可以进一步为您调整内容表达。







