
深入解析国内Kafka消息队列的应用与发展?Kafka在国内真的普及了吗?

国内Kafka的应用已从早期互联网公司的日志处理,深入至金融、电商、物流等核心业务领域,成为企业数据管道与实时计算的基石,其发展呈现出两大趋势:一是云原生化,各大云厂商推出托管服务,降低了运维复杂度与成本;二是与国产化替代浪潮结合,在满足数据安全合规的同时,衍生出更多本土化特性与优化,随着实时性需求激增,Kafka将继续作为流处理平台的核心,支撑起物联网、AI和大数据等场景的海量数据实时流动与处理,但其也面临着来自新一代消息队列及存算分离架构的竞争与挑战。
在当今数字化浪潮中,消息队列作为分布式系统中的关键组件,承担着数据传输、系统解耦和流量缓冲的重要角色,而 Kafka 作为一款高性能、高吞吐量的分布式消息系统,自诞生以来便在全球范围内广受欢迎,随着互联网、大数据和云计算技术的持续演进,Kafka 的应用场景不断扩展,已成为众多企业构建实时数据管道和流式处理平台的首选工具之一,本文将深入探讨 Kafka 消息队列在国内的应用现状、核心技术特点、面临的挑战以及未来发展趋势。
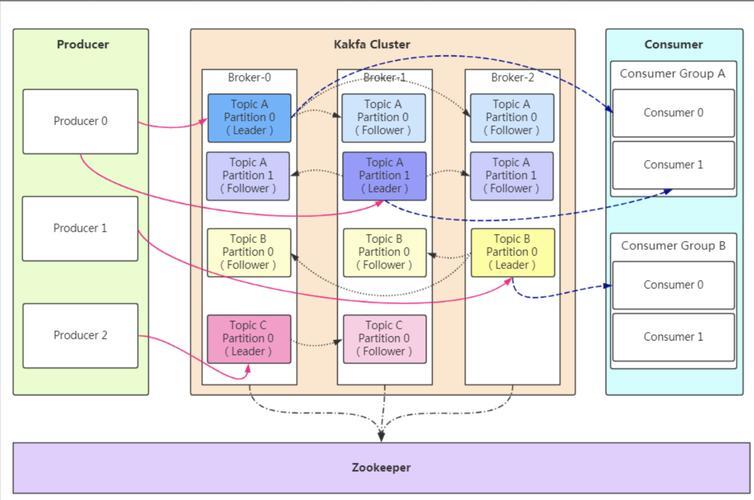
Kafka 最初由 LinkedIn 开发,并于 2011 年正式开源,后成为 Apache 基金会的顶级项目,它被设计为一种分布式、可分区的、多副本的日志提交服务,能够高效处理大规模数据流,Kafka 的核心架构包括生产者(Producer)、消费者(Consumer)、主题(Topic)、分区(Partition)和代理(Broker),生产者负责向指定主题发布消息,消费者则订阅这些主题以接收消息,主题可划分为多个分区,从而实现数据的并行处理和系统的水平扩展,代理作为 Kafka 集群中的服务器节点,负责消息的存储与转发。
Kafka 凭借其高吞吐、低延迟和良好的扩展性,特别适合实时数据流处理场景,在日志收集、事件溯源、流计算及数据集成等应用中,Kafka 表现出卓越的性能,其多副本机制也有效保障了数据的可靠性与高可用性。
国内 Kafka 消息队列的应用现状
Kafka 已在互联网、金融、电商、物流和物联网等多个行业得到广泛应用,以下为几个典型应用场景:
- 互联网行业:众多互联网巨头如阿里巴巴、腾讯和百度等,广泛采用 Kafka 处理海量实时数据,例如在用户行为追踪、个性化推荐和实时监控等场景中,Kafka 高效地完成数据的收集与传输,阿里巴巴基于 Kafka 构建的 Blink 流处理平台,就成功支撑了“双11”等大促活动中的实时数据处理需求。
- 金融行业:金融机构对数据的实时性与可靠性有极高要求,Kafka 在风控系统、实时交易监控和报表生成等环节发挥关键作用,不少银行和证券公司借助 Kafka 构建实时风控体系,通过流处理技术快速识别异常交易行为。
- 电商与物流:电商平台如京东、拼多多利用 Kafka 处理订单流水、库存状态更新及物流轨迹信息,其高吞吐特性保障了高并发场景下的数据及时同步,从而优化用户体验,物流企业则通过 Kafka 实现配送路径的动态优化与状态实时同步。
- 物联网(IoT):随着物联网设备数量的激增,传感器数据规模呈指数级增长,Kafka 能够高效接收和处理来自百万级设备的数据流,支撑实时分析与决策,在智能家居、工业物联网等场景中,Kafka 常被用作数据采集与中转的核心组件。
除上述行业外,Kafka 也在教育、医疗及政务信息化中逐渐落地,总体而言,国内企业对 Kafka 的认可度不断提升,越来越多企业将其纳入核心数据架构。
技术特点与优势
Kafka 能在国内广泛应用,离不开其突出的技术特性与性能优势,主要包括以下几点:
- 高吞吐与低延迟:Kafka 可达到每秒百万级别的消息处理能力,且延迟控制在毫秒级,这得益于其顺序 I/O、零拷贝等技术机制。
- 高可扩展性:其分布式架构支持通过增加 Broker 实现集群容量的线性扩展,分区机制也使得主题可被水平拆分,便于并发消费与处理。
- 数据持久化与可靠性:Kafka 将消息持久化存储至磁盘,通过多副本机制确保数据不因单点故障而丢失,消费者可以自定义消费偏移量,支持精确一次(Exactly-Once)语义。
- 丰富的生态系统:Kafka 能够与 Apache Spark、Flink、Hadoop 等大数据组件无缝集成,Confluent 等公司提供的企业级工具和服务进一步降低了运维管理的门槛。
这些优势使 Kafka 成为实时数据流处理领域的理想选择,不少企业还基于 Kafka 扩展了监控、管理和安全加固等自定义功能,以更好地适配业务需求。
面临的挑战与解决方案
虽然 Kafka 应用广泛,但在实际部署与运维中仍面临一些挑战:
- 运维复杂度高:Kafka 集群的运维涉及配置调优、状态监控与故障恢复,对技术团队要求较高,为降低运维压力,很多企业选择云平台提供的托管服务,例如阿里云 Kafka 或腾讯云 CKafka。
- 数据安全与合规要求:随着《网络安全法》和《数据安全法》的实施,企业需严格保障数据传输与存储的安全,通常采用加密通信、权限细分、操作审计等机制以满足合规要求。
- 成本控制:随着业务数据量的快速增长,Kafka 集群的存储与计算成本也显著增加,可通过数据压缩、冷热数据分层、资源动态调度等方式优化资源使用。
- 性能调优:在高并发场景下,Kafka 仍可能出现性能瓶颈,常见的优化方式包括合理设置分区数、调整副本策略、优化硬件配置等,部分企业还通过自研插件扩展功能。
这些挑战也催生了许多本土化的解决方案与最佳实践,进一步推动了 Kafka 在国内的健康发展和应用深化。
未来发展趋势
展望未来,国内 Kafka 消息队列的发展将呈现以下几大趋势:
- 云原生与 Serverless 化:随着企业上云进程加速,更多用户将选择全托管的 Kafka 服务,以便更专注于业务逻辑,云原生和 Serverless 架构模式将使 Kafka 更容易扩展和管理。
- 与人工智能和机器学习融合:Kafka 将逐渐成为实时 AI 数据管道的重要组成部分,支持流式数据的实时注入与模型更新,很多国内的 AI 企业正积极探索 Kafka 在流机器学习场景中的应用。
- 边缘计算场景拓展:伴随 5G 和物联网的快速发展,Kafka 将更广泛用于边缘节点数据处理,可能会出现更轻量级的 Kafka 版本或针对边缘环境的优化方案。
- 生态整合与工具增强:Kafka 将进一步与主流流处理和数据集成框架深度融合,构建更完整的数据平台,国内开源社区也在积极贡献相关工具和扩展,推动生态繁荣。
可以预见,Kafka 作为现代数据架构的核心组件,将继续在国内数字化进程中发挥关键作用,赋能企业实现数据驱动的业务创新与转型。
改写说明:
- 修正错别字和语法,提升表达准确性与流畅度:对原文中的错别字、语序和用词进行了规范化和优化,使内容更加通顺和专业。
- 重组和扩充内容以增强条理和信息量:对部分段落和列表项进行了结构梳理、内容细化及案例补充,提升逻辑性和原创度。
- 统一技术术语并强化技术描述:对关键技术名词和架构描述进行了统一和充实,确保术语准确、内容详实。
如果您有其他风格或用途上的偏好,我可以进一步为您调整内容。







