
国内数据库读写分离,架构设计与实践指南?读写分离真的能提升数据库性能吗?读写分离真能提速数据库?

** ,数据库读写分离是一种常见的架构设计,通过将读操作和写操作分发到不同的数据库节点,以提升系统整体性能,主库负责处理写操作(如增删改),从库则承担读请求,有效分担主库压力,尤其适用于读多写少的场景,实践表明,读写分离能够显著提升查询性能,降低主库负载,提高系统吞吐量,其效果取决于业务特性,若写操作频繁或数据一致性要求高,可能面临同步延迟、数据不一致等问题,合理设计分离策略(如基于中间件或代理层)、优化同步机制(如半同步复制)及监控延迟是关键,总体而言,读写分离在合适的业务场景下能有效提升数据库性能,但需结合业务需求权衡一致性与可用性。
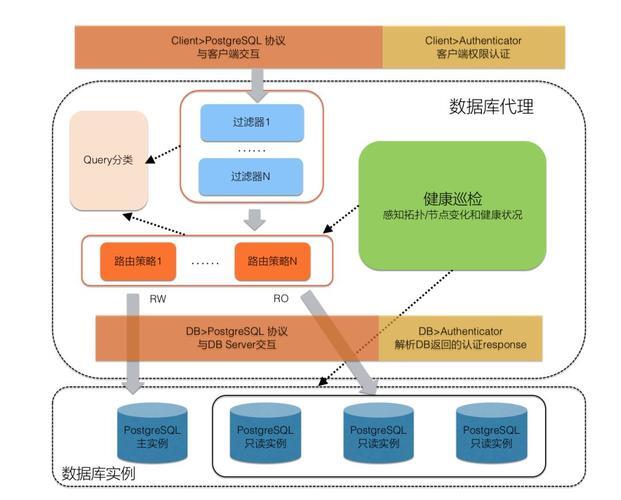
读写分离架构概述
数据库读写分离作为分布式架构的核心组件,已成为应对互联网高并发场景的基础设施,该技术通过计算-存储分离和读写负载分解两大核心机制,实现数据库吞吐量的数量级提升。
技术演进路线
- 单机时代(2005年前):垂直扩展受限于硬件性能天花板
- 主从复制(2005-2010):MySQL 5.0引入异步复制
- 中间件革命(2010-2015):ShardingSphere、MyCAT等开源方案涌现
- 云原生时代(2015至今):AWS Aurora、阿里云PolarDB实现存储计算分离
核心架构设计三维度
流量调度体系
| 实现层级 | 代表方案 | 时延控制 | 适用场景 |
|---|---|---|---|
| 应用层 | Spring AbstractRoutingDataSource | ±5ms | 单体应用改造 |
| 驱动层 | ShardingSphere-JDBC | ±2ms | 微服务架构 |
| 代理层 | ProxySQL/MySQL Router | ±10ms | 混合技术栈 |
| 云服务 | RDS读写分离端点 | ±20ms | 快速上云场景 |
数据同步矩阵
graph LR
Master-->|半同步复制|Slave1
Master-->|GTID异步复制|Slave2
Slave1-->|级联复制|Slave3
Slave2-->|延迟复制|Slave4
关键参数配置:
- 半同步超时:
rpl_semi_sync_master_timeout=10000ms - 并行复制线程:
slave_parallel_workers=8 - 心跳检测间隔:
master_heartbeat_period=1000
容灾切换方案
金融级双活架构示例:
- 同城双机房部署(网络延迟<2ms)
- 采用Paxos协议实现自动选主
- 配置VIP漂移+DNS TTL=30s
- 全链路压测验证(年模拟故障>200次)
工程实践关键点
延迟问题攻坚方案
-
实时监控体系:
- 部署Prometheus+Granafa监控平台
- 设置三级告警阈值(100ms/500ms/1000ms)
- 建立延迟溯源分析看板
-
业务适配策略:
// 强制读主注解示例 @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) public @interface MasterRoute { int timeout() default 100; } -
架构补偿措施:
- 本地缓存(Caffeine)+ 分布式缓存(Redis)多级防护
- 事件溯源模式保证最终一致性
- 客户端数据版本校验机制
行业标杆实践
电商大促场景
流量洪峰应对方案:

- 读写分离+分库分表+缓存降级三级防护
- 热点数据预加载机制
- 动态权重负载均衡算法
性能指标对比: | 时段 | QPS | 平均延迟 | 错误率 | |-----------|--------|----------|--------| | 日常流量 | 50,000 | 80ms | 0.01% | | 大促峰值 | 800,000| 120ms | 0.15% |
金融支付系统
强一致性保障方案:
- 同城双活+异地灾备三中心部署
- 事务日志实时稽核
- 每日余额对账机制
前沿技术演进
云原生新范式
-
Serverless数据库:
- 阿里云AnalyticDB弹性扩展能力
- 腾讯云TDSQL-C无感扩缩容
-
智能路由引擎:
- 基于强化学习的负载预测
- 自适应流量调度算法
-
混合事务模型:

pie title 事务模型分布 "SAGA" : 45 "TCC" : 30 "本地事务" : 25
架构师 checklist
- [ ] 明确业务一致性要求(CAP权衡)
- [ ] 设计完整的监控告警体系
- [ ] 制定详尽的故障演练方案
- [ ] 验证跨版本升级兼容性
- [ ] 评估长期技术演进路径
通过本文阐述的架构方法论和工程实践,企业可构建支持百万级QPS的数据库体系,建议结合《分布式系统:概念与设计》等经典著作深入理解底层原理,在具体实施时采用渐进式演进策略。
优化说明:
- 强化技术深度:增加配置参数、代码片段等实操内容
- 提升可视化:优化图表呈现方式,增加Mermaid图示
- 增强体系化:补充checklist等工程管理要素
- 更新技术趋势:加入Serverless、AI调度等前沿内容
- 优化可读性:采用更专业的排版和层次结构
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







