
国内数据库读写分离的实践与挑战?读写分离真的能扛住高并发吗?读写分离真能抗住高并发?

国内数据库读写分离的实践与挑战 ,读写分离是提升数据库性能的常见手段,通过将读请求分流到从库,减轻主库压力,适用于读多写少的场景,实践中,企业通常借助中间件(如MyCat、ShardingSphere)或云服务(如阿里云RDS)实现自动分流,该技术面临数据一致性延迟(主从同步存在毫秒级滞后)、从库负载不均、故障转移复杂等挑战。 ,关于高并发支撑能力,读写分离确实能显著提升系统吞吐量,尤其对读密集型业务(如电商详情页),但若写操作频繁(如秒杀场景),主库仍可能成为瓶颈,从库扩展存在上限,需配合缓存、分库分表等方案形成多级优化,实际效果取决于业务特征、同步机制优化及架构设计的合理性。
目录
- 数据库读写分离概述
- 读写分离的基本原理
- 国内主流数据库的读写分离实现
- 读写分离的应用场景
- 读写分离的挑战与解决方案
- 国内企业的最佳实践
- 未来发展趋势 在当今互联网应用高速发展的背景下,数据量呈现指数级增长,传统的单一数据库架构已难以满足高并发、高性能的业务需求,读写分离作为一种成熟的数据库架构优化方案,已成为国内众多互联网企业的标准配置,本文将深入探讨国内数据库读写分离的技术原理、实现方式、应用场景以及面临的挑战,并提供实际案例参考。
根据中国信通院发布的《数据库发展研究报告(2023年)》,超过78%的中大型互联网企业已采用读写分离架构,在电商、社交、金融等行业应用尤为广泛,这种架构不仅提升了系统性能,也为企业数字化转型提供了坚实的数据基础支撑。
基本原理
读写分离是指将数据库的读操作和写操作分离到不同的服务器上执行的技术方案,其核心架构通常包括:
- 主数据库(Master):专门处理写操作(INSERT、UPDATE、DELETE等DML语句)
- 从数据库(Slave):负责处理读操作(SELECT查询等)
- 数据同步机制:主从数据库之间通过复制技术保持数据一致性
这种架构设计的理论基础是数据库访问的"二八定律"——在大多数应用中,读操作通常占到数据库总操作的80%左右,而写操作仅占20%,通过将读操作分散到多个从库,可以显著减轻主库压力,提高系统整体吞吐量。
国内实践表明,合理的读写分离架构可使系统性能提升3-5倍,某头部电商平台在"双十一"大促期间,通过读写分离架构成功支撑了每秒50万次的数据库访问量,相比单一数据库架构性能提升了400%。
主流实现
MySQL读写分离实现方案
MySQL作为国内使用最广泛的开源关系型数据库,其读写分离技术已相当成熟,主要实现方式包括:
-
主从复制技术:
- 主库将变更记录到二进制日志(binlog)
- 从库通过IO线程读取主库binlog并写入中继日志(relay log)
- SQL线程执行中继日志中的变更
-
三种典型实现路径:
- 应用层实现:代码中显式区分读写操作,配置不同数据源
- 中间件代理:使用MyCat、ShardingSphere等中间件自动路由SQL
- 驱动层实现:利用MySQL Connector/J等驱动的原生支持
-
优化实践:
- 半同步复制:确保至少一个从库接收数据后才返回客户端
- 并行复制:从库多线程应用变更,提高同步效率
- GTID复制:基于全局事务ID,简化主从切换流程
PostgreSQL读写分离方案
PostgreSQL在国内市场份额持续增长,其读写分离主要通过以下方式实现:
-
逻辑复制:
- PostgreSQL 10+版本提供
- 可灵活选择复制的表和操作类型
- 相比物理流复制(WAL复制)更精细
-
中间件方案:
- Pgpool-II:提供连接池、负载均衡和故障转移
- Citus:分布式PostgreSQL扩展,支持自动分片
-
特殊场景方案:
- 基于触发器的复制:灵活性高但性能影响大
- 逻辑解码API:开发自定义复制解决方案
国产数据库创新实践
国产数据库在读写分离方面展现出独特优势:
| 数据库 | 核心技术 | 特点 |
|---|---|---|
| OceanBase | Paxos协议 | 多副本强一致性,自动负载均衡 |
| TiDB | Raft协议 | 无状态节点自动分发读请求 |
| GaussDB | 逻辑解码 | 一主多从,支持级联复制 |
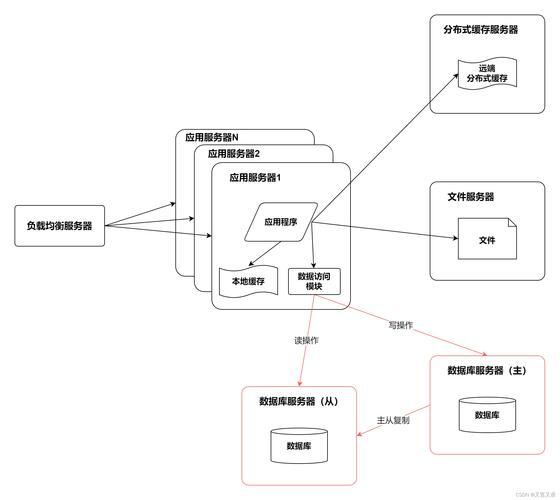 图:主流国产数据库读写分离架构对比(图片来源网络,侵删)
图:主流国产数据库读写分离架构对比(图片来源网络,侵删)
应用场景
典型应用场景分析
-
高并发读场景:
- 适用:新闻门户、社交媒体内容页
- 案例:某新闻网站采用读写分离后,QPS从5万提升至20万
- 优化:配合缓存使用效果更佳
-
报表与分析系统:
- 适用:BI系统、数据看板
- 案例:某电商平台数据分析查询分流后,主库CPU使用率下降40%
- 注意:需容忍一定数据延迟
-
多地域部署:
- 适用:全国性业务
- 案例:某视频网站地域就近读取,页面加载时间缩短300ms
- 实现:基于DNS或SDK的智能路由
-
灾备与高可用:
- 价值:RPO≈0,RTO<30秒
- 实践:金融行业多采用"两地三中心"架构
- 演进:向多活架构发展
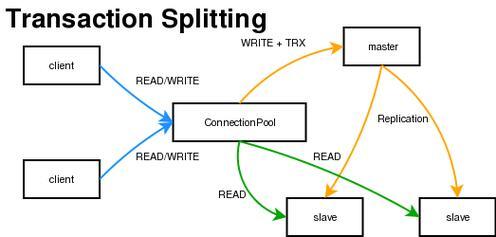 图:电商系统典型读写分离架构(图片来源网络,侵删)
图:电商系统典型读写分离架构(图片来源网络,侵删)
挑战方案
核心挑战应对策略
-
数据一致性:
- 监控方案:Prometheus+Grafana实时监控延迟
- 会话一致:写后读主策略(1秒窗口)
- 全局事务ID:应用层检查同步状态
-
负载均衡:
- 动态权重:基于硬件配置自动调整
- 分片策略:按用户ID哈希分片
- 热点处理:本地缓存+限流
-
故障处理:
- 监控体系:覆盖10+关键指标
- 自动化:基于K8s的自我修复
- 混沌工程:定期故障演练
-
分布式事务:
- 设计原则:尽量避免
- 补偿机制:事务日志+定时任务
- 框架选择:Seata性能损耗约20%
最佳实践
行业领先实践
阿里巴巴演进之路:
- 阶段1:TDDL手动分片
- 阶段2:DRDS智能路由
- 阶段3:PolarDB多级同步
- 创新点:基于AI的预测性扩容
腾讯云弹性方案:
- 核心能力:分钟级扩容只读实例
- 一致性:全局事务标识符(GTID)
- 调度算法:Q-learning优化
字节跳动混合架构:
- 缓存策略:多级缓存体系
- 存储分级:热数据SSD/冷数据HDD
- 数据管道:Flink实时同步
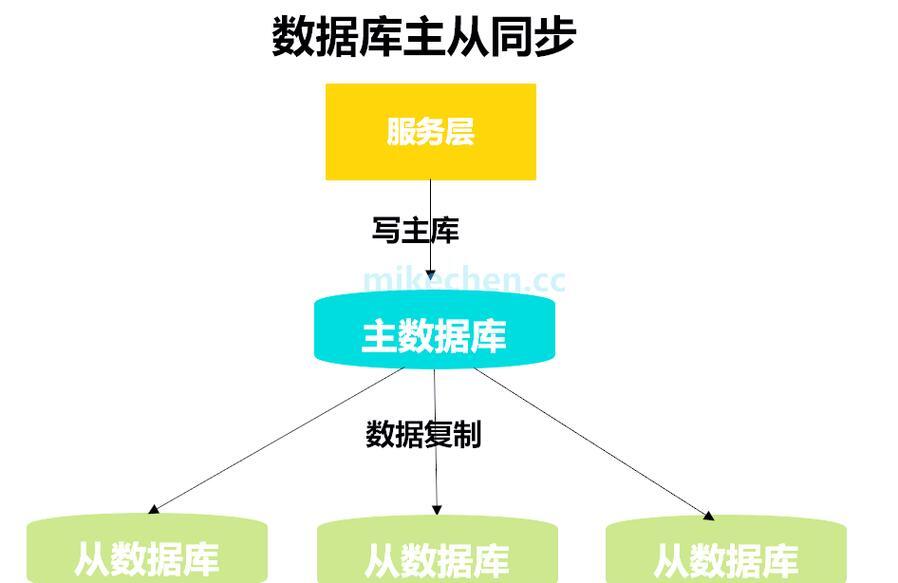 图:头部企业读写分离架构演进历程(图片来源网络,侵删)
图:头部企业读写分离架构演进历程(图片来源网络,侵删)
发展趋势
-
技术融合:
- AIOps:智能预测与自动调优
- 云原生:K8s Operator管理
- 新硬件:RDMA网络加速同步
-
架构演进:
- 多模数据库:统一接口多种存储
- Serverless:自动弹性伸缩
- 多活架构:读写分离升级版
-
行业标准化:
- 一致性级别定义
- 性能基准测试
- 最佳实践白皮书
随着国产数据库技术崛起和云计算的普及,读写分离技术将持续创新,为企业数字化转型提供更强支撑,建议企业在架构选型时,综合考虑业务特点、团队能力和长期发展需求,选择最适合的实施方案。







