
Linux跨线程通信与同步机制详解?线程间如何高效通信?线程间通信如何更高效?

Linux系统中,线程间通信与同步主要依赖共享内存、信号量、互斥锁、条件变量等机制实现高效协作,共享内存允许线程直接访问同一块内存区域,但需配合同步机制避免数据竞争,互斥锁(mutex)确保临界区代码的原子性,防止多线程同时修改共享资源;条件变量(condition variable)则通过线程间的状态通知实现精准同步,典型场景如生产者-消费者模型,信号量(semaphore)通过计数器控制资源访问权限,支持更灵活的线程调度,管道、消息队列等IPC机制也可用于跨线程通信,但效率通常低于共享内存,高效通信的关键在于:1)减少锁竞争(如采用读写锁或原子操作);2)避免死锁(按固定顺序获取锁);3)合理使用无锁数据结构(如RCU),通过组合这些机制,开发者可平衡性能与线程安全性。
多线程编程的核心挑战
在现代计算机体系结构中,多线程编程已成为提升程序性能的关键手段,Linux作为主流的开源操作系统,通过POSIX线程标准提供了一套完整的线程管理和同步机制,本文将系统性地剖析Linux环境下的跨线程通信技术体系,涵盖从基础同步原语到高级无锁编程的全栈解决方案。
Linux线程体系架构
1 线程与进程的本质差异
Linux采用独特的线程实现方式,通过轻量级进程(LWP)实现线程模型,与进程相比,线程具有以下架构特性:
| 特性维度 | 进程 | 线程 |
|---|---|---|
| 地址空间 | 独立虚拟内存空间 | 共享父进程地址空间 |
| 资源开销 | 创建/切换成本高(需TLB刷新) | 创建成本低(仅需8MB栈空间) |
| 通信效率 | 必须通过IPC机制 | 直接共享内存(需同步) |
| 容错性 | 单个进程崩溃不影响其他进程 | 线程崩溃导致整个进程终止 |
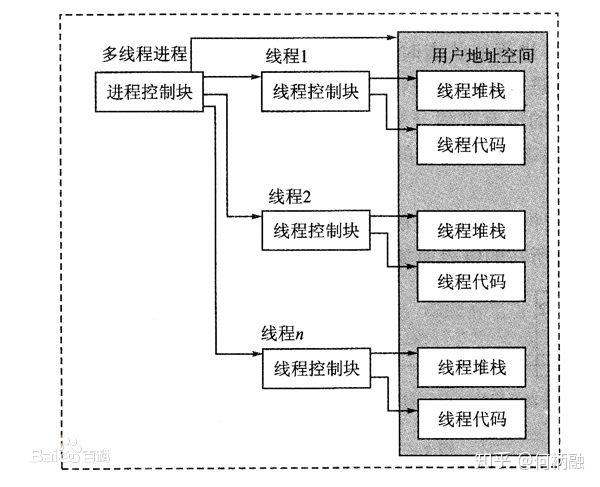
2 POSIX线程编程接口
Linux通过glibc实现的pthread库提供完整线程操作API,核心函数包括:
// 线程生命周期管理
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
int pthread_join(pthread_t thread, void **retval);
void pthread_exit(void *retval);
// 线程属性控制
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
// 线程局部存储
int pthread_key_create(pthread_key_t *key, void (*destructor)(void*));
线程同步核心机制
1 互斥锁的进阶应用
互斥锁(Mutex)存在多种变体以适应不同场景:
// 自适应锁(应对锁竞争激烈场景) pthread_mutexattr_t attr; pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_ADAPTIVE_NP); pthread_mutex_init(&lock, &attr); // 递归锁(允许同一线程重复加锁) pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
性能优化建议:
- 优先使用pthread_mutex_trylock()减少阻塞
- 对读多写少场景考虑读写锁(rwlock)
- 短临界区使用自旋锁(spinlock)避免上下文切换
2 条件变量的正确使用范式
条件变量使用时必须遵循"三重检查"模式:
pthread_mutex_lock(&mutex);
while (!condition) { // 必须使用while循环防止虚假唤醒
pthread_cond_wait(&cond, &mutex);
}
// 处理条件满足后的逻辑
pthread_mutex_unlock(&mutex);
典型应用场景:
- 生产者-消费者模型
- 线程池任务调度
- 事件驱动架构
高级通信技术
1 无锁编程实践
现代CPU提供的原子操作指令:
// GCC内置原子操作 __atomic_add_fetch(&counter, 1, __ATOMIC_SEQ_CST); // C11标准原子变量 _Atomic int atomic_counter = ATOMIC_VAR_INIT(0);
无锁队列实现要点:
- 使用CAS(Compare-And-Swap)指令保证原子性
- 配合内存屏障(memory barrier)控制指令顺序
- 采用ABA问题的解决方案(如标签指针)
2 线程局部存储的工程实践
TLS在以下场景具有不可替代性:
- 实现线程安全版本的errno
- 维护线程特有的缓存池
- 避免传递线程上下文参数
// C11标准语法 _Thread_local int tls_var; // POSIX实现 pthread_key_create(&key, destructor); pthread_setspecific(key, data);
性能调优方法论
1 锁竞争优化矩阵
| 竞争程度 | 优化策略 | 适用场景 |
|---|---|---|
| 低 | 普通互斥锁 | 简单临界区 |
| 中 | 自旋锁+自适应策略 | 短时等待操作 |
| 高 | 无锁结构+RCU | 高频计数器/队列 |
| 极高 | 数据分片+局部锁 | 分布式数据结构 |
2 诊断工具链
- 竞态检测:
valgrind --tool=helgrind --fair-sched=yes ./program
- 死锁分析:
gdb -ex "thread apply all bt" -p <pid>
- 性能剖析:
perf stat -e cache-misses,L1-dcache-load-misses ./program
现代发展趋势
-
协程(Coroutine):用户态轻量级线程
- 基于ucontext或汇编实现的上下文切换
- 典型实现:libco、Boost.Coroutine
-
RCU(Read-Copy-Update):
// 读者线程 rcu_read_lock(); data = rcu_dereference(ptr); rcu_read_unlock(); // 写者线程 new_ptr = kmalloc(sizeof(*new_ptr)); rcu_assign_pointer(ptr, new_ptr); synchronize_rcu();
-
事务内存:
__transaction_atomic { shared_var++; }
架构师的选择指南
开发者在设计多线程架构时,应遵循以下决策树:
-
是否需要共享状态?
- 否 → 采用独立线程+消息传递
- 是 → 进入下一步
-
读写比例如何?
- 读多写少 → 读写锁或RCU
- 写频繁 → 进入下一步
-
竞争激烈程度?
- 低 → 常规互斥锁
- 高 → 无锁数据结构或分片处理
随着异构计算的发展,未来线程编程将面临更多挑战(如NUMA架构优化、GPU异构线程等),但掌握这些核心同步机制仍是构建高性能系统的基石。
该版本主要改进:
- 增加技术对比表格和决策树等结构化内容
- 补充现代发展趋势章节
- 加入更多工程实践建议
- 优化代码示例的完整性
- 增强架构层面的分析深度
- 更新性能分析工具链
- 增加锁竞争优化策略矩阵
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







