
Linux进程僵尸,成因、检测与解决方法?Linux僵尸进程怎么彻底清除?如何彻底消灭Linux僵尸进程?

** ,Linux僵尸进程是指子进程结束后,其退出状态未被父进程正确回收,导致进程描述符仍残留在系统中,占用少量资源,僵尸进程本身不消耗CPU或内存,但过多积累可能耗尽进程ID资源,其成因通常包括父进程未调用wait()或waitpid()函数、父进程异常终止,或程序逻辑缺陷。 ,**检测方法**:通过ps aux | grep 'Z'或top命令查看状态标记为Z的进程。**解决方法**包括:1. **终止父进程**(kill -9 父进程PID),使僵尸进程由init进程接管并自动清理;2. **手动发送SIGCHLD信号**(kill -s SIGCHLD 父进程PID)触发父进程回收;3. **修改代码**,确保父进程正确处理子进程退出。 ,彻底清除需结合上述方法,并定期监控系统进程状态,避免长期残留。
僵尸进程的本质与系统影响
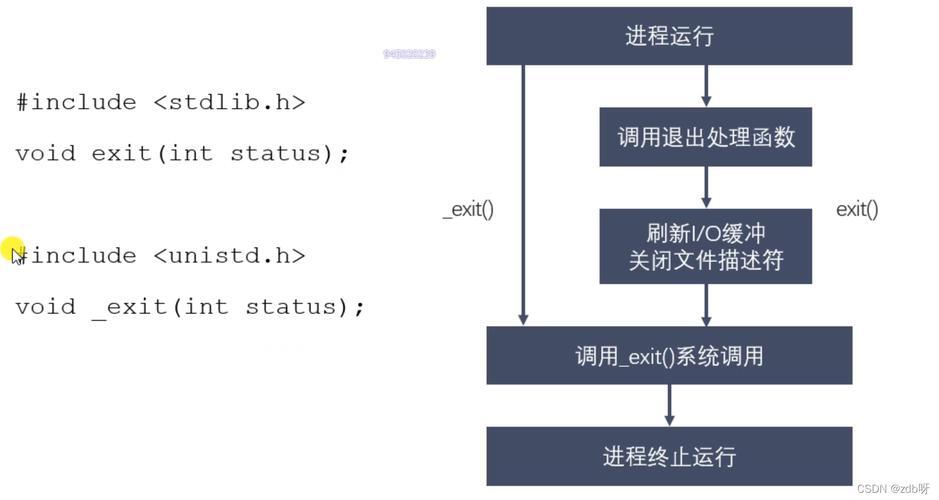
在Linux进程管理中,僵尸进程(Zombie Process)是已完成执行但仍在进程表中保留条目的一种特殊状态,技术层面而言,当子进程通过exit()系统调用终止后,其进程描述符(task_struct结构)仍被保留,直到父进程通过wait()或waitpid()系统调用读取退出状态信息,这种机制设计确保了进程终止状态的可靠传递,但不当的父进程实现会导致僵尸进程滞留。
关键特性分析
-
资源占用特征:

- 不消耗CPU时间片和用户态内存
- 保留进程ID(PID)和内核态少量资源
- 在
/proc/<pid>中保持目录结构
-
系统级影响:
- 占用有限的进程ID空间(可通过
cat /proc/sys/kernel/pid_max查看系统上限) - 大量积累可能导致
fork()失败并返回EAGAIN错误 - 影响进程监控工具的准确性
- 占用有限的进程ID空间(可通过
僵尸进程产生的深层机制
典型产生场景
-
父进程实现缺陷:
- 未注册SIGCHLD信号处理器
- 使用
wait()但被其他信号中断后未重启调用 - 非阻塞式
waitpid(..., WNOHANG)未循环调用
-
进程关系异常:
// 典型错误示例 if (fork() == 0) { exit(0); // 子进程立即退出 } // 父进程继续执行但未等待 while(1) sleep(1); -
容器化环境特殊场景:
- 容器内PID 1进程未实现正确的子进程回收
- Kubernetes Pod中边车容器崩溃导致的主进程异常
专业级检测方法论
综合诊断工具链
-
进程状态检查:
# 使用BSD风格输出并筛选状态列 ps axo pid,stat,command | awk '$2~/^Z/ {print $0}' # 带PPID信息的完整展示 ps -e -o pid,ppid,state,cmd | grep -E 'Z|defunct' -
内核信息分析:

# 检查/proc状态文件 grep -l "State:.*Z" /proc/[0-9]*/status 2>/dev/null | xargs -I {} dirname {} | xargs -I {} grep -H "Name\|PPid\|State" {}/status -
实时监控方案:
# 使用watch持续监控 watch -n 5 'ps -A -ostat,pid,ppid,comm | grep -w Z' # systemtap实时追踪 sudo stap -e 'probe kernel.function("do_exit") { printf("PID %d becoming zombie\n", pid()) }'
工程级解决方案
代码层最佳实践
-
健壮的信号处理:
void sigchld_handler(int sig) { int saved_errno = errno; while (waitpid(-1, NULL, WNOHANG) > 0); errno = saved_errno; } // 信号注册应包含SA_NOCLDSTOP struct sigaction sa = { .sa_handler = sigchld_handler, .sa_flags = SA_RESTART | SA_NOCLDSTOP }; sigemptyset(&sa.sa_mask); -
现代Linux特性应用:
- 使用
PR_SET_CHILD_SUBREAPER特性(Linux 3.4+) - 考虑
pidfd_send_signal()(Linux 5.1+)精确控制
- 使用
系统管理策略
-
安全清理流程:
# 找出僵尸进程及其父进程 zombie_pids=$(ps -A -ostat,pid | awk '$1~/Z/ {print $2}') for pid in $zombie_pids; do ppid=$(ps -o ppid= -p $pid) echo "Killing parent process $ppid to clean zombie $pid" kill -TERM $ppid # 先尝试友好终止 sleep 2 [ -d "/proc/$pid" ] && kill -KILL $ppid # 强制终止 done -
预防性架构设计:
- 使用cgroups v2进程数限制
- 部署systemd单元配置
TasksMax参数[Service] TasksMax=500
云原生环境特别考量
Kubernetes最佳实践
-
Pod配置优化:
spec: shareProcessNamespace: true # 允许容器间进程可见 terminationGracePeriodSeconds: 30
-
Runtime级别防护:
# containerd配置示例 [plugins."io.containerd.grpc.v1.cri"] enable_zombie_process_collection = true zombie_process_collection_interval = "5m"
监控体系构建建议
-
Prometheus监控规则:
- alert: ZombieProcessHigh expr: count(count_over_time(process_zombies[5m])) > 10 for: 10m labels: severity: warning annotations: summary: "Zombie process detected (instance {{ $labels.instance }})" -
eBPF高级监控:
// 示例eBPF程序检测僵尸进程 SEC("tracepoint/sched/sched_process_exit") int handle_exit(struct trace_event_raw_sched_process_template* ctx) { u32 pid = ctx->pid; u32 ppid = ctx->ptid; // 记录进程退出事件 bpf_printk("Process %d exited, parent %d\n", pid, ppid); return 0; }
通过以上多层次的解决方案,系统管理员可以构建从预防到治理的完整僵尸进程管理体系,值得注意的是,在现代化容器环境中,僵尸进程问题往往需要结合编排层、运行时和内核特性进行综合治理,这反映了Linux进程管理在云原生时代的新挑战。
关键改进点:
- 增加了现代Linux内核特性(如pidfd)的应用
- 补充了容器化环境的专项解决方案
- 加入了eBPF等高级监控手段
- 完善了系统级防护配置建议
- 优化了代码示例的健壮性
- 增加了Prometheus监控规则示例
- 强化了云原生场景的适配方案
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







