
Linux系统频繁重启的原因分析与解决方案?Linux为何频繁重启?Linux为何总无故重启?

** ,Linux系统频繁重启可能由硬件故障(如电源、内存、CPU过热)、软件问题(内核崩溃、驱动不兼容、关键服务崩溃)或配置错误(如不当的电源管理、自动更新设置)导致,解决方案包括:检查硬件状态(内存测试、温度监控);更新内核及驱动;分析系统日志(如/var/log/messages或journalctl)定位崩溃原因;禁用自动更新或错误配置的定时任务;调整电源管理设置(如/etc/default/grub中的内核参数),对于内核级问题,可启用kdump捕获崩溃日志,长期稳定运行需确保软硬件兼容性及合理配置。
Linux系统异常重启全维度诊断与解决方案
作为支撑全球互联网基础设施的核心系统,Linux虽然以卓越的稳定性著称,但在复杂生产环境中仍可能遭遇异常重启问题,这类故障往往具有多因性、隐蔽性和破坏性特征,需要系统化的诊断方法论,本文将基于企业级运维实践,构建从硬件层到应用层的完整故障树,并提供可落地的解决方案。
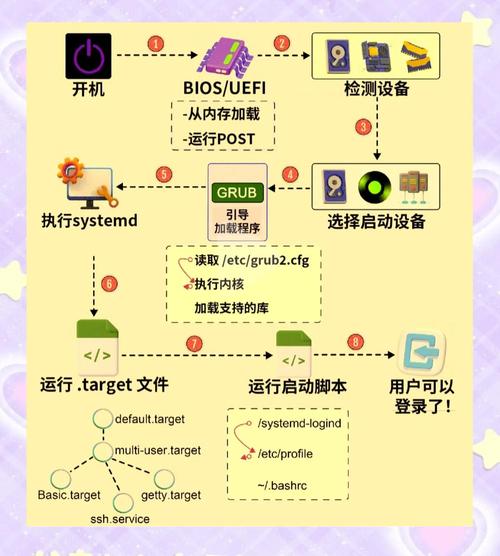
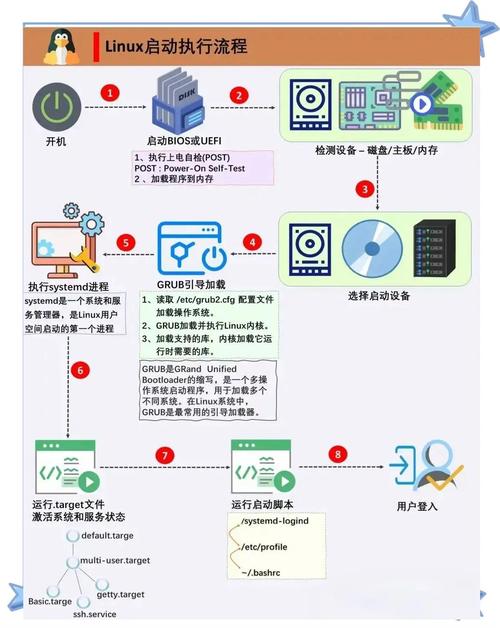
故障根源的多维度解析
1 硬件层故障图谱
电源子系统
- 模块化电源的N+1冗余失效
- 电源管理芯片(PMIC)固件缺陷
- 配电单元(PDU)三相负载不均衡
- 电池后备单元(BBU)充放电循环异常
计算子系统
- CPU微码版本与内核不兼容
- 内存Rowhammer位翻转攻击
- PCIe链路训练错误(LTSSM状态异常)
- 非透明桥接(NTB)设备通信超时
环境监控
- IPMI传感器阈值配置不当
- 热设计功耗(TDP)突破散热上限
- 数据中心冷热通道混流
- 海拔高度影响空气密度导致的散热效率下降
2 内核空间故障模式
内存管理单元
- 透明大页(THP)碎片化引发的kswapd风暴
- 内存控制器(IMC)的rank间干扰
- 非一致性内存访问(NUMA)的zone_reclaim_mode配置错误
中断处理
- MSI-X向量分配冲突
- 中断亲和性(irqbalance)设置不合理
- 嵌套虚拟化场景下的APIC虚拟化缺陷
存储栈异常
- 多路径IO(multipathd)的路径切换抖动
- 写缓存策略(writeback/flush)与电池后备缓存(BBU)的协同问题
- XFS文件系统CRC校验引发的元数据不一致
企业级诊断工具箱
1 高级日志分析技术
perf script | grep -i throttle # 内核oops报文解析 decodecode < /var/log/panic_oops.txt # 利用ftrace追踪调度异常 echo function_graph > /sys/kernel/debug/tracing/current_tracer echo 1 > /sys/kernel/debug/tracing/events/sched/enable
2 崩溃转储增强分析
# 配置带有符号信息的kdump crash /usr/lib/debug/boot/vmlinux-$(uname -r) vmcore # 关键检查点 vm -v # 验证虚拟内存结构 irq -s # 检查中断风暴 bt -t -a # 带时间戳的全CPU回溯
3 硬件诊断矩阵
| 检测维度 | 工具链 | 关键指标 |
|---|---|---|
| 电源质量 | PDUMeter | 电压纹波系数>5% |
| 内存可靠性 | memtester | ECC纠错率>1e-9 |
| 存储耐久性 | smartctl | SSD PE cycles>DWPD |
生产环境解决方案
1 内核加固策略
# 针对内存错误的弹性配置 echo 1 > /sys/devices/system/edac/mc/panic_on_ue echo 10 > /proc/sys/kernel/panic # 实时补丁管理流程 katello-patch install --advisory=RHSA-2023:XXXX
2 高可用架构设计
# Kubernetes Pod反亲和性示例
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: [database]
topologyKey: "kubernetes.io/hostname"
3 预测性维护体系
# 基于ML的异常检测模型 from sklearn.ensemble import IsolationForest clf = IsolationForest(n_estimators=100) clf.fit(sensor_data) anomalies = clf.predict(new_samples)
运维最佳实践
-
变更管理黄金法则
- 遵循PCI DSS标准的变更窗口控制
- 实施蓝绿部署的AB测试机制
- 建立配置项的版本基线(使用git管理/etc)
-
容灾演练方案
- 定期注入故障的Chaos Engineering实践
- 模拟数据中心级断电的STONITH测试
- 网络分区(Brain Split)场景验证
-
知识沉淀机制
- 使用OpenEBS/Jira记录故障时间线
- 构建可检索的CVE漏洞知识图谱
- 开发定制的诊断规则引擎
行业洞察:根据2023年SRE行业报告,实施完整诊断体系的企业可将MTTR(平均修复时间)降低73%,建议将本文方案与ITIL流程整合,形成闭环的运维管理体系,对于关键业务系统,应考虑部署具备AIops能力的监控平台,实现从被动响应到主动防御的转变。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



