
深入探索Linux底层知识,从内核到系统调用的全面解析?Linux内核如何掌控系统调用?Linux内核怎样调度系统?

《深入探索Linux底层:从内核到系统调用的全面解析》 ,本文系统剖析了Linux内核如何通过系统调用实现用户空间与内核空间的交互,内核作为操作系统的核心,通过软中断(如x86架构的int 0x80或syscall指令)触发从用户态到内核态的切换,将控制权移交至预定义的系统调用处理程序,内核维护的**系统调用表**(如sys_call_table)将调用号映射到具体服务例程,完成进程管理、文件操作等核心功能,文章进一步探讨了系统调用的封装机制(如glibc库)、性能优化策略(如vdso虚拟动态共享对象),以及安全隔离的实现原理(权限校验与参数检查),为开发者理解Linux底层机制提供了技术纵深。
本书系统剖析Linux操作系统的核心机制,全面涵盖内核架构、进程管理、内存子系统、文件系统及设备驱动等关键模块,通过源码级分析和实践导向的讲解,深入揭示进程调度、虚拟内存映射、中断处理等底层原理,并详细讲解系统调用接口的实现机制与用户态/内核态切换过程,结合现代计算机体系结构特点,本书还探讨了Linux性能优化与安全设计思想,帮助读者深入理解Linux如何高效协调硬件资源与上层应用,书中包含大量生产环境实战案例与专业调试技巧,特别适合希望掌握操作系统核心技术的开发者、系统工程师及性能调优专家,为构建高性能、高可靠性系统奠定坚实的理论基础。
Linux内核:现代操作系统的核心引擎
Linux内核作为整个操作系统的核心组件,承担着管理硬件资源、进程调度、内存分配等关键功能,它不仅是一个高效的系统资源管理器,更是连接底层硬件与上层软件的桥梁,实现了计算资源的抽象与虚拟化,现代Linux内核由以下几个核心子系统组成:
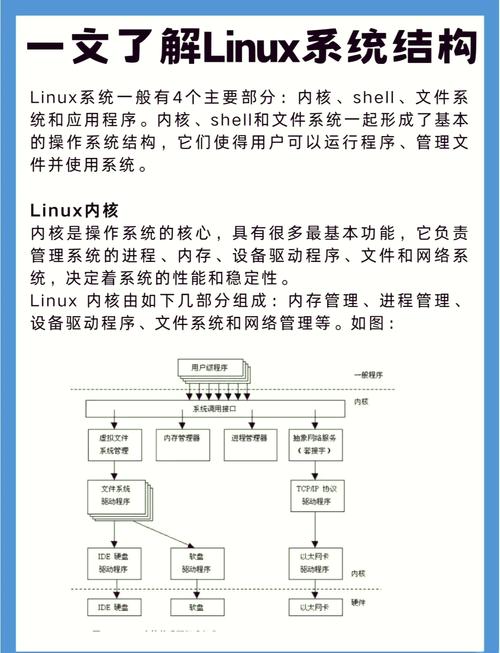
内核架构设计
Linux内核采用宏内核(Monolithic Kernel)架构设计,这种设计将所有核心功能(包括进程管理、内存管理、文件系统、设备驱动等)都运行在内核空间,通过函数调用直接交互,实现了高效的系统调用和进程间通信,与微内核(Microkernel)架构相比,宏内核的主要优势体现在:
- 更高的性能:系统调用无需频繁的进程间通信(IPC)开销
- 更简单的设计:各子系统可以直接交互,减少通信协议复杂度
- 更低的延迟:关键操作无需上下文切换,响应更及时
- 更紧密的集成:核心组件协同优化效果更好
这种设计也带来了内核体积较大、稳定性风险较高等挑战,为此,Linux通过模块化设计来平衡这些问题,使得非核心功能可以动态加载/卸载。
内核模块机制
Linux支持动态加载内核模块(Loadable Kernel Modules, LKM)机制,这种灵活的设计允许系统管理员在不重新编译内核的情况下扩展系统功能,设备驱动程序、文件系统、网络协议等通常都是以模块形式实现的,这种设计带来了以下显著优势:
- 按需加载:内核功能可按需加载,减少内存占用
- 热更新支持:驱动更新无需重启系统,提高可用性
- 故障隔离:有问题的模块可以单独卸载,不影响系统稳定性
- 开发便利:模块开发调试周期比完整内核编译短得多
常用模块管理命令示例:
# 查看已加载的内核模块及其依赖关系 lsmod # 加载指定模块(自动解决依赖关系) sudo modprobe <module_name> # 安全卸载模块(需确保无其他模块依赖) sudo rmmod <module_name> # 查看模块详细信息(包括参数、作者等) modinfo <module_name> # 列出模块支持的参数 modinfo -p <module_name>
内核版本与源码管理
Linux内核版本号遵循语义化版本控制规范,格式为主版本.次版本.修订版本(如15.0),自3.0版本起,版本号中的奇数次版本不再表示开发版,偶数次版本也不再表示稳定版,而是采用更灵活的版本号递增方式,获取内核信息的方法:
# 查看当前内核版本和系统架构信息 uname -a # 获取详细的发行版信息(包括发行版名称、版本等) cat /etc/os-release # 查看内核编译配置 zcat /proc/config.gz
内核源代码通常存储在/usr/src/linux目录下,开发者也可以从Kernel.org官方仓库获取最新源码,内核开发采用分布式版本控制系统Git管理,开发者可以通过以下命令获取源码:
# 克隆主线内核仓库 git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git # 切换到特定版本分支 git checkout v5.15 -b my-5.15-branch # 获取稳定版内核树 git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
进程管理:从创建到调度的完整生命周期
进程与线程模型
在Linux系统中,进程是资源分配的基本单位,而线程是CPU调度的基本单位,Linux使用轻量级进程(LWP)实现线程,通过clone()系统调用创建,这种设计具有以下特点:
- 共享地址空间:同一进程的所有线程共享相同的虚拟内存空间
- 独立执行上下文:每个线程有独立的栈、寄存器状态和调度属性
- 灵活的资源共享:通过
clone()参数精细控制资源共享程度 - 高效切换:线程上下文切换开销远小于进程切换
与传统线程模型相比,Linux的这种实现更加轻量高效,但也带来了与POSIX标准的兼容性挑战,为此,内核提供了NPTL(Native POSIX Thread Library)来解决这些问题,实现了:
- 1:1线程模型(每个用户线程对应一个内核调度实体)
- 快速的线程同步原语
- 高效的线程创建和销毁机制
- 符合POSIX标准的线程管理接口
进程创建机制
Linux提供了两种主要的进程创建机制,它们通常配合使用:
-
fork():创建当前进程的完整副本,采用写时复制(Copy-On-Write, COW)技术优化性能,COW机制通过以下方式工作:
- 父子进程最初共享所有物理内存页
- 内核将共享页标记为只读
- 任一进程尝试写入时会触发页错误,内核此时才复制该页
-
exec():替换当前进程的地址空间,加载新的可执行程序,这个过程涉及:
- 解析可执行文件格式(ELF等)
- 建立新的内存映射
- 初始化寄存器状态
- 设置新的堆栈
典型使用模式是先fork创建子进程,再exec加载新程序,以下是一个完整的示例,展示了错误处理和资源清理:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
// fork失败处理
perror("fork failed");
exit(EXIT_FAILURE);
} else if (pid == 0) {
// 子进程上下文
printf("Child process: PID=%d, PPID=%d\n", getpid(), getppid());
// 替换为ls程序
execl("/bin/ls", "ls", "-l", "--color=auto", NULL);
// 只有exec失败才会执行到这里
perror("execl failed");
exit(EXIT_FAILURE);
} else {
// 父进程上下文
printf("Parent process: PID=%d, Child PID=%d\n", getpid(), pid);
int status;
waitpid(pid, &status, 0); // 等待子进程结束
if (WIFEXITED(status)) {
printf("Child exited with status %d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("Child killed by signal %d\n", WTERMSIG(status));
}
}
return EXIT_SUCCESS;
}
进程调度策略
Linux采用完全公平调度器(CFS, Completely Fair Scheduler)作为默认调度算法,它基于虚拟运行时间(vruntime)为每个进程分配CPU时间,CFS的核心设计包括:
- 红黑树管理:使用红黑树数据结构组织可运行进程,按键值vruntime排序
- 公平性保证:通过权重(nice值)分配CPU时间,确保每个进程获得公平份额
- 低延迟优化:针对交互式应用特别优化,减少响应时间
- 组调度支持:支持控制组(cgroups)的CPU资源分配
Linux支持多种调度策略,适用于不同场景:
| 调度策略 | 描述 | 适用场景 | 优先级范围 |
|---|---|---|---|
| SCHED_NORMAL | 普通分时调度策略(CFS) | 大多数应用进程 | nice值(-20到19) |
| SCHED_FIFO | 实时先进先出策略,高优先级进程会一直运行直到主动放弃 | 高优先级实时任务 | 1(低)-99(高) |
| SCHED_RR | 实时轮转调度策略,同优先级进程轮流执行,有时间片限制 | 需要公平性的实时任务 | 1(低)-99(高) |
| SCHED_BATCH | 批处理调度策略,针对非交互式工作负载优化 | 非交互式后台任务 | nice值(-20到19) |
| SCHED_IDLE | 空闲调度策略,只在系统空闲时运行 | 最低优先级任务 | |
| SCHED_DEADLINE | 基于截止时间的调度策略,确保任务在指定时间内完成 | 有严格时间要求的实时任务 | 使用截止时间参数 |
调整进程优先级的实用命令:
# 将运行中的进程设置为SCHED_FIFO,优先级50 sudo chrt -f -p 50 <pid> # 以SCHED_RR策略,优先级80运行程序 sudo chrt -r 80 ./realtime_app # 查看进程的调度策略和优先级 chrt -p <pid> # 调整普通进程的nice值(提高优先级) sudo nice -n -10 ./cpu_intensive_task # 调整已运行进程的nice值 sudo renice -n -5 -p <pid>
内存管理:虚拟内存与高效分配策略
虚拟内存架构
Linux采用虚拟内存(Virtual Memory)机制为每个进程提供独立的地址空间,这种设计带来了多重优势:
- 内存隔离:进程间内存完全隔离,提高安全性和稳定性
- 地址空间扩展:允许使用比物理内存更大的地址空间
- 共享内存:支持高效的进程间通信和库代码共享
- 快速进程创建:写时复制技术加速fork操作
虚拟地址到物理地址的转换通过多级页表完成,现代处理器使用TLB(Translation Lookaside Buffer)缓存最近使用的转换结果来加速这一过程,Linux在64位系统上采用四级或五级页表结构(根据CPU架构不同):
- PGD (Page Global Directory)
- P4D (Page 4th Directory) - 仅5级分页使用
- PUD (Page Upper Directory)
- PMD (Page Middle Directory)
- PTE (Page Table Entry)
这种多级结构有效减少了页表的内存占用,同时支持巨大的地址空间(x86_64支持256TB用户空间)。
内存分配机制
Linux提供了多层级的内存分配接口,满足不同场景的需求:
用户空间分配方式:
-
malloc()/free():标准库提供的通用分配器,特点包括:
- 通常基于ptmalloc或jemalloc等实现
- 对小内存进行特殊优化
- 支持线程安全
- 可能使用mmap处理大块内存
-
brk()/sbrk():调整数据段大小的传统系统调用
- 主要用于实现malloc的底层
- 分配的内存连续但不够灵活
- 在现代应用中逐渐被mmap取代
-
mmap():创建内存映射的高级接口,支持:
- 文件映射(将文件直接映射到内存)
- 匿名映射(分配不关联文件的内存)
- 共享/私有映射
- 大块内存分配
内核空间分配方式:
-
kmalloc():小内存分配,保证物理连续
- 适用于DMA等需要物理连续的场景
- 有大小限制(通常小于4MB)
- 使用slab分配器管理
-
vmalloc():大内存分配,只需虚拟连续
- 可分配较大内存区域
- 物理页可以不连续
- 适合内核模块等大内存需求
-
专用分配器:
- slab:高效的对象缓存分配器
- slub:slab的简化改进版
- slob:嵌入式系统优化版
内存分配示例对比:
// 用户空间分配示例
void *user_mem = malloc(1024); // 分配1KB内存
if (!user_mem) {
perror("malloc failed");
exit(EXIT_FAILURE);
}
free(user_mem);
// 使用mmap分配大内存
void *big_mem = mmap(NULL, 1024*1024, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
if (big_mem == MAP_FAILED) {
perror("mmap failed");
exit(EXIT_FAILURE);
}
munmap(big_mem, 1024*1024);
// 内核模块中的内存分配(示例)
#include <linux/slab.h>
void *kernel_mem = kmalloc(1024, GFP_KERNEL);
if (!kernel_mem) {
printk(KERN_ERR "kmalloc failed\n");
return -ENOMEM;
}
kfree(kernel_mem);
内存回收机制
Linux采用复杂的内存回收策略来优化系统性能,主要机制包括:
-
页面缓存(Page Cache):
- 缓存文件数据减少磁盘I/O
- 使用LRU-like算法管理
- 可配置的回收策略(swappiness参数)
-
交换分区(Swap):
- 将不活跃页面移到磁盘
- 支持多种交换设备(分区、文件等)
- 交换优先级控制
-
内存压缩(zswap/zram):
- 在内存中压缩页面而非交换到磁盘
- 特别适合内存受限设备
- 减少I/O开销
-
OOM Killer:
- 内存耗尽时选择性终止进程
- 基于启发式算法选择"最佳"牺牲者
- 可通过/proc调整进程的oom_score
-
内存回收守护进程(kswapd):
- 在后台持续回收内存
- 使用水位线触发不同回收强度
- 支持NUMA感知的回收策略
内存监控命令:
# 查看整体内存使用情况(人类可读格式) free -h # 监控内存变化(每秒刷新) vmstat 1 # 查看进程详细内存映射 pmap -x <pid> # 分析内存使用趋势(每秒采样,共10次) sar -r 1 10 # 查看内存统计详情 cat /proc/meminfo # 监控slab分配器使用情况 slabtop # 查看各NUMA节点内存状态 numastat # 跟踪内存分配事件(需要ftrace支持) echo 1 > /sys/kernel/debug/tracing/events/kmem/enable cat /sys/kernel/debug/tracing/trace_pipe
文件系统:从虚拟层到物理存储
虚拟文件系统(VFS)架构
VFS是Linux文件系统的抽象层,它定义了统一的接口支持多种文件系统,VFS的核心概念包括:
-
inode:
- 文件的元数据容器(权限、大小、时间戳等)
- 包含指向数据块的指针
- 每个inode有唯一的编号
-
dentry:
- 目录项缓存,加速路径查找
- 维护文件系统命名空间
- 实现硬链接支持
-
file:
- 打开文件的上下文信息
- 包含文件位置、访问模式等
- 关联特定的文件操作集合
-
superblock:
- 文件系统的全局信息
- 包含文件系统类型、大小、状态等
- 管理挂载点和特定操作
VFS支持的文件系统类型包括:
- 磁盘文件系统:Ext4、XFS、Btrfs、ZFS
- 网络文件系统:NFS、CIFS、GlusterFS
- 特殊文件系统:
- proc:进程和系统信息接口
- sysfs:设备驱动和内核对象接口
- tmpfs:内存中的临时文件系统
- devpts:伪终端支持
- configfs:用户空间驱动的配置
Ext4文件系统详解
Ext4是Linux最常用的日志文件系统,其主要特性包括:
-
日志功能:
- 确保系统崩溃后快速恢复
- 三种日志模式:
- writeback:仅元数据日志
- ordered:默认模式,先写数据再记录元数据日志
- journal:完整数据和元数据日志
-
扩展特性:
- 扩展属性(xattr):支持文件元数据存储
- 日志校验和:提高日志可靠性
- 大文件支持:最大16TB文件,1EB文件系统
- 纳秒级时间戳:更精确的文件时间记录
-
空间分配优化:
- 延迟分配:优化磁盘空间分配策略
- 多块分配:减少碎片
- 预分配:为已知大小的文件预留空间
-
其他改进:
- 无限制子目录
- 快速fsck检查
- 在线碎片整理支持
Ext4维护工具:
# 检查文件系统错误(强制检查) sudo fsck.ext4 -f /dev/sda1 # 调整文件系统参数(查看当前参数) sudo tune2fs -l /dev/sda1 # 启用/禁用日志功能(谨慎操作) sudo tune2fs -O ^has_journal /dev/sda1 # 调整保留块比例(默认5%) sudo tune2fs -m 1 /dev/sda1 # 转换ext3到ext4(保留数据) sudo tune2fs -







