
Hive 分桶(Bucketing)深度解析:原理、实战与核心概念对比

一、分桶的意义:比分区更细的粒度管理
1.1 解决分区数据不均匀问题
分区的局限性:分区基于表外字段(如时间字段)划分数据,但可能导致部分分区数据量过大,部分过小,无法进一步细化。
分桶的定位:通过表内字段(如用户 ID、订单 ID)将数据划分为更细的 “桶”(Bucket),每个桶是数据文件的子集,实现数据的均衡分布与精细化管理。
1.2 分桶与分区的关系
两者均为数据分治技术,分区是粗粒度划分(如按天分区),分桶是细粒度划分(如每个分区内再按用户 ID 分桶)。
分桶可与分区结合使用,进一步提升查询效率。
二、分桶原理:哈希算法的应用
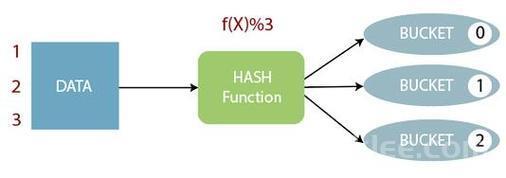
2.1 核心逻辑:哈希取余
对分桶字段的值进行哈希计算,再通过公式 hash(value) % num_buckets 确定数据所属的桶。
示例:若分桶字段为id,桶数为 4,则id=5的哈希值hash(5)=1234,1234 % 4=2,该数据存入第 2 个桶。
2.2 与 MapReduce 分区的关联
分桶原理类似 MapReduce 中Partitioner的分区逻辑,通过哈希算法将数据分配到不同 Reducer,实现并行处理。
三、分桶的核心优势
3.1 大表 JOIN 性能优化
当两张分桶表按相同字段分桶时,JOIN 操作可仅在相同桶内进行,减少跨节点数据 Shuffle,大幅提升查询速度。
原理:相同分桶字段的记录必然分布在相同桶中,无需全表扫描。
3.2 高效数据抽样
通过桶编号直接定位数据子集,支持TABLESAMPLE语法快速抽样(如抽取第 1 个桶的数据)。
3.3 数据均衡分布
避免分区数据倾斜,每个桶的数据量相对均衡,提升任务并行性。
四、实战操作:从建表到数据加载
4.1 建表语法:指定分桶字段与桶数
CREATE TABLE stu_bucket ( id INT, name STRING ) CLUSTERED BY (id) -- 指定分桶字段 SORTED BY (id DESC) -- 每个桶内数据按id降序排序 INTO 4 BUCKETS -- 分为4个桶 ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
4.2 数据加载:使用CLUSTER BY或DISTRIBUTE BY + SORT BY
方式 1:CLUSTER BY(分桶 + 默认升序排序)
INSERT INTO TABLE stu_bucket SELECT * FROM student CLUSTER BY (id);
INSERT INTO TABLE stu_bucket SELECT * FROM student DISTRIBUTE BY (id) SORT BY (id);
方式 2:自定义排序字段
INSERT INTO TABLE stu_bucket SELECT * FROM student DISTRIBUTE BY (id) SORT BY (name ASC);
4.3 关键配置与注意事项
- 设置 Reduce 数量:
- 确保 Reduce 数≥桶数,或设为-1让 Hive 自动决定(推荐)。
SET mapreduce.job.reduces = -1; -- 自动确定Reduce数
- 关闭本地模式:
SET hive.exec.mode.local.auto = false; -- 避免本地模式影响分桶
- 配置 Hive 分桶属性(在hive-site.xml中):
hive.enforce.bucketing true -- 强制启用分桶
- 确保 Reduce 数≥桶数,或设为-1让 Hive 自动决定(推荐)。
五、分桶查询:抽样与 JOIN 优化
5.1 数据抽样:按桶编号快速获取子集
-- 抽取第1个桶的数据(桶编号从0开始) SELECT * FROM stu_bucket TABLESAMPLE(BUCKET 1 OUT OF 4 ON id);
5.2 分桶表 JOIN 优化
-- 两张表按id分桶,JOIN时仅在相同桶内操作 SELECT a.id, a.name, b.age FROM stu_bucket a JOIN stu_score_bucket b ON a.id = b.id;
六、核心概念对比
6.1 分桶 vs 分区
| 维度 | 分桶(Bucketing) | 分区(Partitioning) |
|---|---|---|
| 字段类型 | 表内字段(如 id、name) | 表外字段(如日期、地域) |
| 粒度 | 细粒度(单个分区可包含多个桶) | 粗粒度(每个分区是独立目录) |
| 核心作用 | 数据均衡分布、JOIN 优化、抽样 | 数据过滤、层级管理 |
6.2 相关命令对比
| 命令 | 作用 |
|---|---|
| CLUSTER BY | 分桶 + 默认升序排序(等价于DISTRIBUTE BY + SORT BY同一字段) |
| DISTRIBUTE BY | 仅分桶(控制数据分布),不排序 |
| SORT BY | 局部排序(每个 Reducer 内排序) |
| ORDER BY | 全局排序(仅允许 1 个 Reducer,数据量大时慎用) |
| PARTITIONED BY | 建表时定义分区字段 |
| PARTITION BY | 开窗函数中用于分区(与分桶无关) |
(图片来源网络,侵删)
(图片来源网络,侵删)

(图片来源网络,侵删)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







