
【MySQL】第三章:表的操作


本章节的目标是:认识和理解MySQL表结构的增删查改
一、创建表结构
语法介绍
CREATE TABLE if not exists table_name (
column_name1 datatype,
column_name2 datatype,
column_name3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
字段和选项的介绍
- column_name:字段名称,也就是所谓的列名。(每一列代表一个属性,如 name、age、number)
- data_type:列的数据类型,如int、varchar等。
- character set :字符集,如utf8、utf8mb4,如果没有指定字符集,则以所在数据库的字符集为准
- collate: 指定字符集的校验规则,如utf8_general_ci,如果没有指定校验规则,则以所在数据库的校验规则为准
- engine:指定存储引擎,如InnoDB、MyISAM等
- if not exists :表示如果表不存在就创建,存在则不会创建。(可选择是否加上,但一般建议加上)
说明
-
每个字段都以, 作为分隔符,最后一列不需要加, (和枚举类一样 enum, 最后一个字段无需逗号)
-
整体的字段用圆括号包围,不像结构体那样用花括号
-
表选项的另一种写法:加上等号
charset=字符集 collate=校验规则 engine=存储引擎
创建表案例
基础样例
create table if not exists users ( id int, name varchar(20) comment '用户名', password char(32) comment '密码是32位的md5值', birthday date comment '生日' ) charset=utf8 engine=MyISAM;说明:
- comment:是对该字段的描述(类似可显示的注释)
- date:日期类型
- varchar(32):varchar长度可变字符串,32是指定最大长度。
- [if not exists]可选项:编写创建表结构的SQL语句时,建议带上[if not exists]可选项,这样容错率提高。
- SQL语句可以一行可以多行:以往出现的SQL语句都是一行写完,但是编写创建表结构的SQL语句时希望可以分成多行来写。
不同的存储引擎的影响
我们下面创建两个表结构:分别使用不同的存储引擎
create table if not exists user1 ( id int, name varchar(20) comment '用户名', password char(32) comment '密码是32位的md5值', birthday date comment '生日' ) charset=utf8 collate=utf8_general_ci engine=MyISAM; // 存储引擎为MyISAM create table if not exists user2 ( id int, name varchar(20) comment '用户名', password char(32) comment '密码是32位的md5值', birthday date comment '生日' ) charset=utf8 collate=utf8_general_ci engine=innoDB; // 存储引擎为innoDB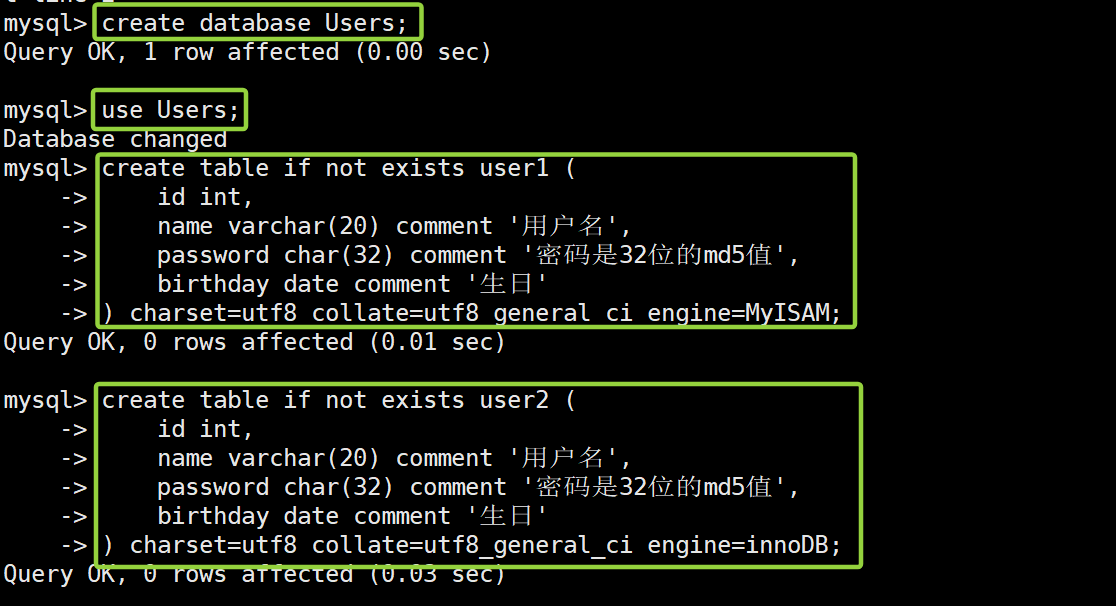
我们查看一下数据库在文件系统中的变化:
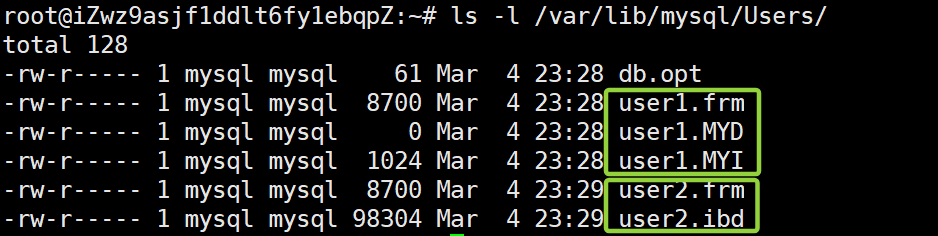
创建 user1 表指定 engine=MyISAM 时,MySQL 服务在/var/lib/mysql/Users/创建了3个文件;
创建 user2 表指定 engine=innoDB 时,MySQL 服务在/var/lib/mysql/Users/创建了2个文件;
可以发现配置不同存储引擎的表结构,形成的文件都不一样(这些文件就是和你使用的存储引擎相关,至于这些文件的具体含义,有机会再讲解)
二、查看表结构
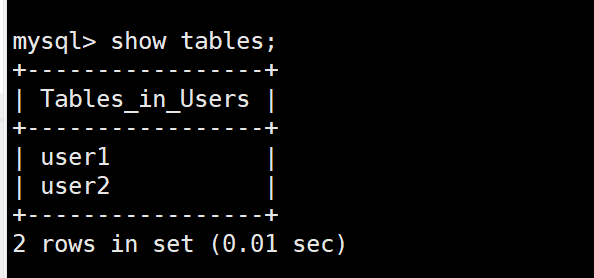
查看当前数据库里的表结构
show tables;
查看表结构的详细信息
desc table_name;
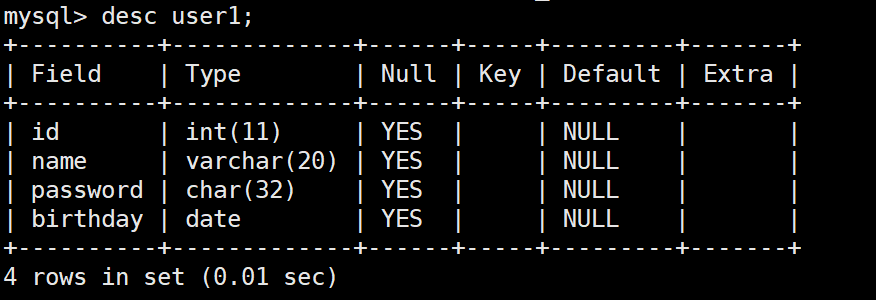
在 DESC user1; 查询结果中,各个字段的含义如下:
- 列名(Field):表示表中的字段名称(列名称)。例如 id、name、password 和 birthday。
- 类型(Type):表示字段的数据类型及其长度限制。比如 int(11) 表示整型数据,varchar(20) 表示最多可存储 20 个字符的可变长度字符串。
- 是否允许为空(NULL):表示该字段是否允许为空值。YES 表示允许为空,NO 表示不允许为空。
- 索引类型(Key):用于标记索引类型。常见的有:
- PRI:主键,标识唯一记录。
- UNI:唯一索引,保证字段唯一性。
- MUL:普通索引,可以重复。
- 默认值(Default):表示字段的默认值,在记录插入时没有赋值的情况下,默认填入的值。若为 NULL,则表示没有默认值。
- 额外属性(Extra):表示字段的额外属性。常见的有:
- auto_increment:表示该字段会自动递增(通常用于主键)。
- 空白:表示没有特别的额外属性。
图示化如下
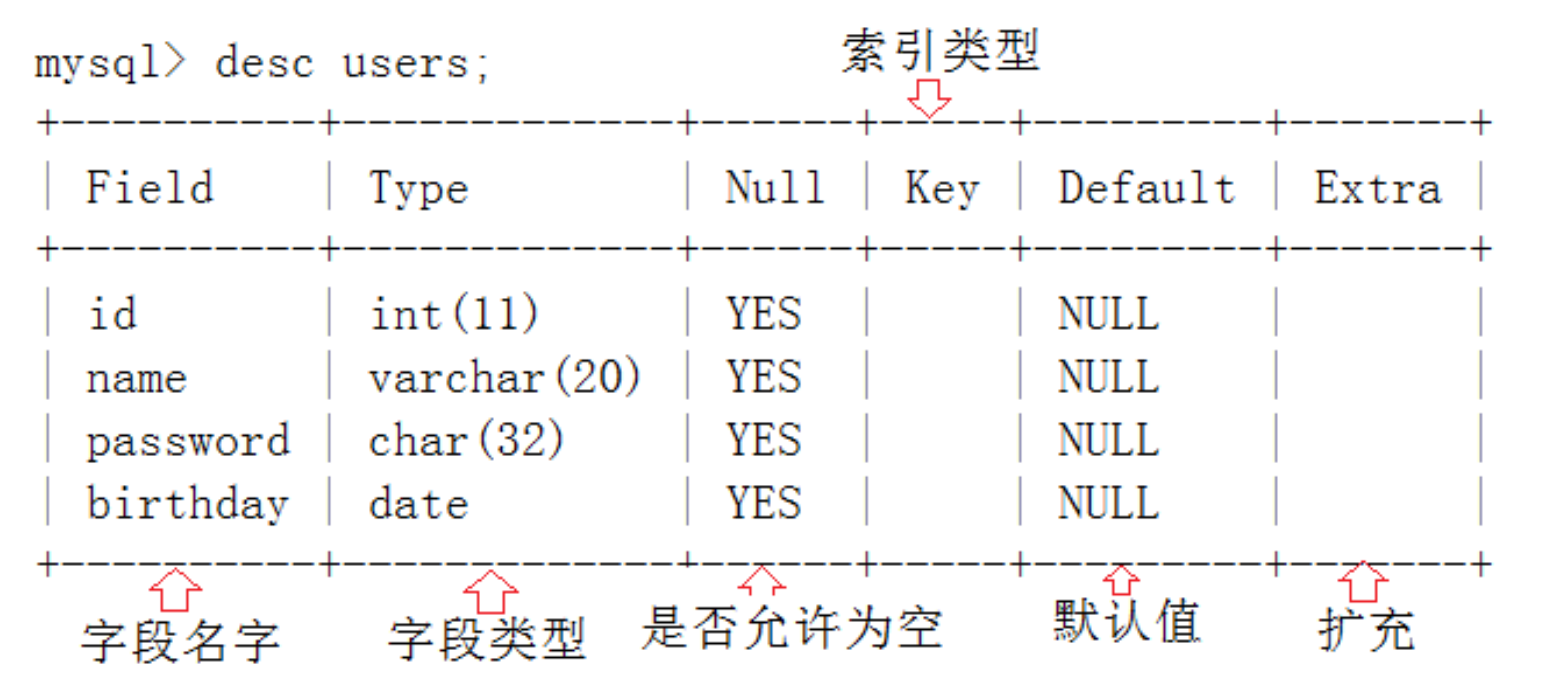
查看表结构的创建
show create table table_name;
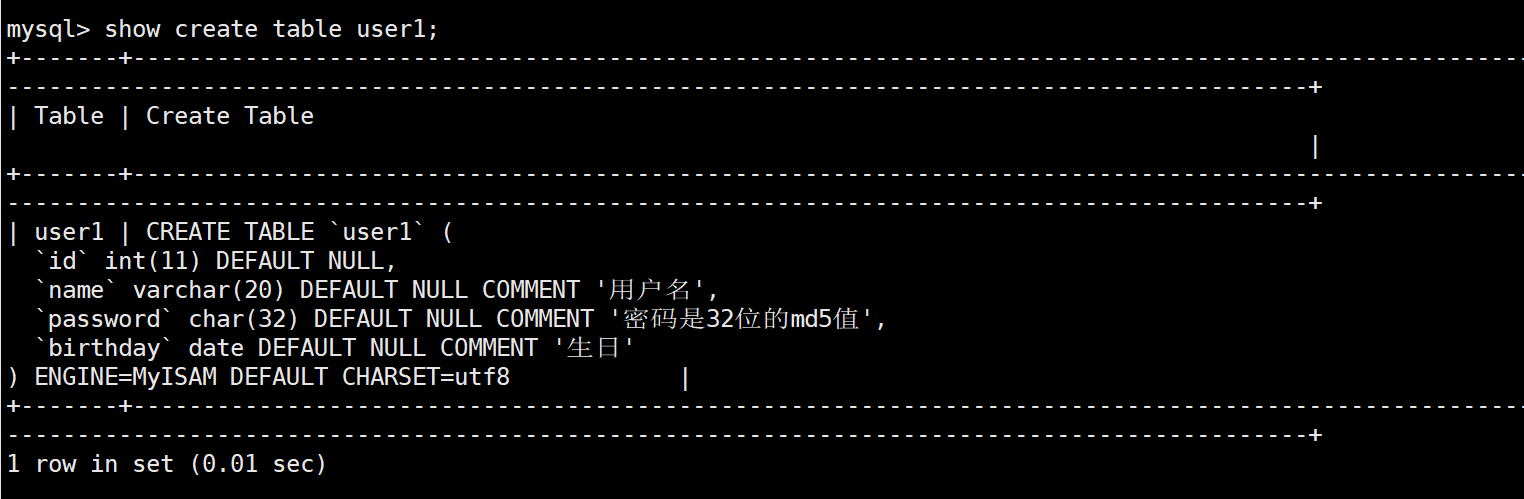
优化:\G 替代分号
直接使用 show create table user2; 的话会看到 SQL 语句的执行结构一言难尽。这是因为当 SQL 语句以分号结尾时,默认以“表格格式”显示,这样的显示方式对于包含许多列的数据及其不友好。因此,MySQL 还提供了另一种叫做“竖排格式”的显示方式,命令末尾使用 \G 替代分号即可。
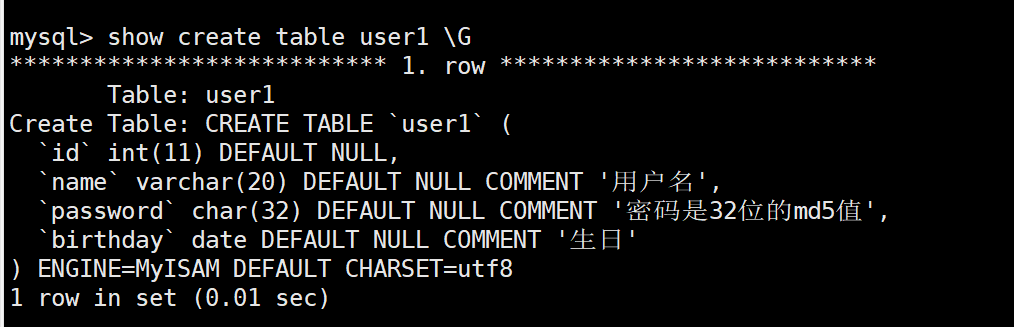
仔细观察的话能够发现 show create table user1; 查询到的创建 user1 表的 SQL 语句和我们之前编写的 SQL 语句有点出入,因为这是正常的。我们自己编写的 SQL 语句在 MySQL 服务的词法分析、语法分析模块来看是不标准的,MySQL 服务会将用户输入的不标准的 SQL 语句转化为标准的格式记录下来,也就是我们查询到的结果。
三、修改表结构
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
声明:修改表结构的所有操作,基本都已 alter table table_name 为开头,之后的就根据选项的不同修改不同部分
增加列
alter table table_name add column column_name data_type [AFTER existing_column];
- table_name:表名称,表示你要在该表下新增一列。
- column_name:列名称,表示你要新增的那一列的列名称。
- data_type:新列的数据类型。
- data_type之后其实还有附加选项、约束之类的,不过暂时不介绍了。
- [AFTER existing_column]:可选项,显式使用表示将新列插入指定列之后。省略表示将新列添加至表的末尾。
示例
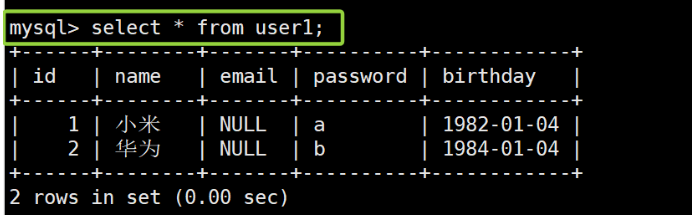
-- 查看表结构 desc user1; -- 插入两条数据 insert into user1 values(1,'小米','a','1982-01-04'),(2,'华为','b','1984-01-04'); -- 修改表结构:新增email列(指明该列的数据类型) alter table user1 add column email varchar(50) AFTER name; -- 查看修改后的表结构 desc user1; -- 查询修改表结构后的内容 select * from user1;
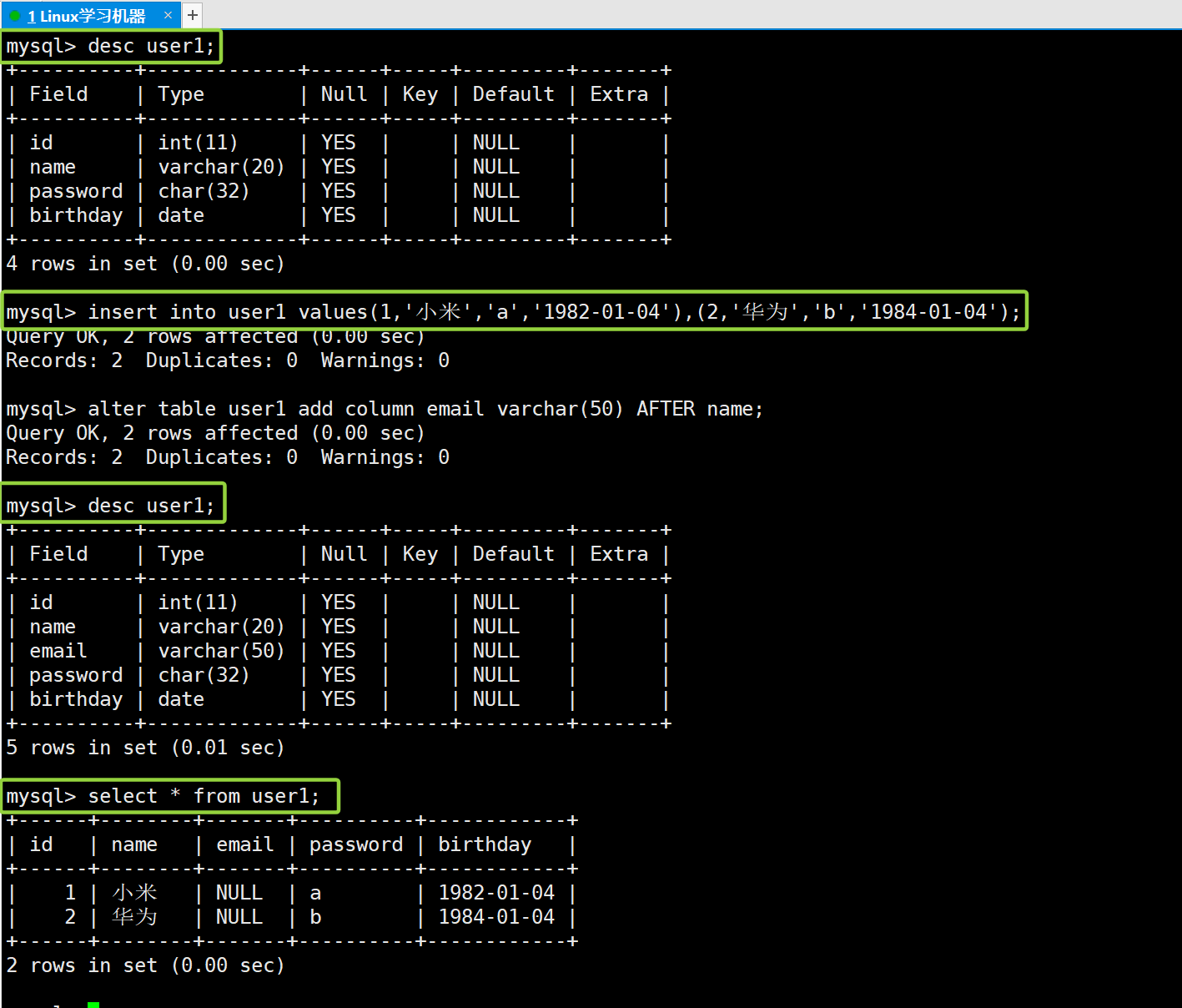
从这里可以看出,为什么我们说增加列,其实就是增加这个表的 列(增加了一列属性)
修改列
修改列属性
alter table table_name modify column column_name new_data_type;
- alter table table_name :固定开头
- modify column :修改列的选项(这个选项一般是修改 列的数据类型)
- column_name new_data_type :指定要修改的列名字,指定要修改列的新数据类型和约束条件。
- 修改列的本质是对某一个字段的覆盖式重定义,接下来会举例子说明。
示例:
-- 这是修改前的user2表的创建语句 show create table user2 \G -- 将name字段的类型由varchar(20)改为varchar(60) alter table user1 modify column name varchar(60); -- 这是修改后的user2表的创建语句 show create table user2 \G
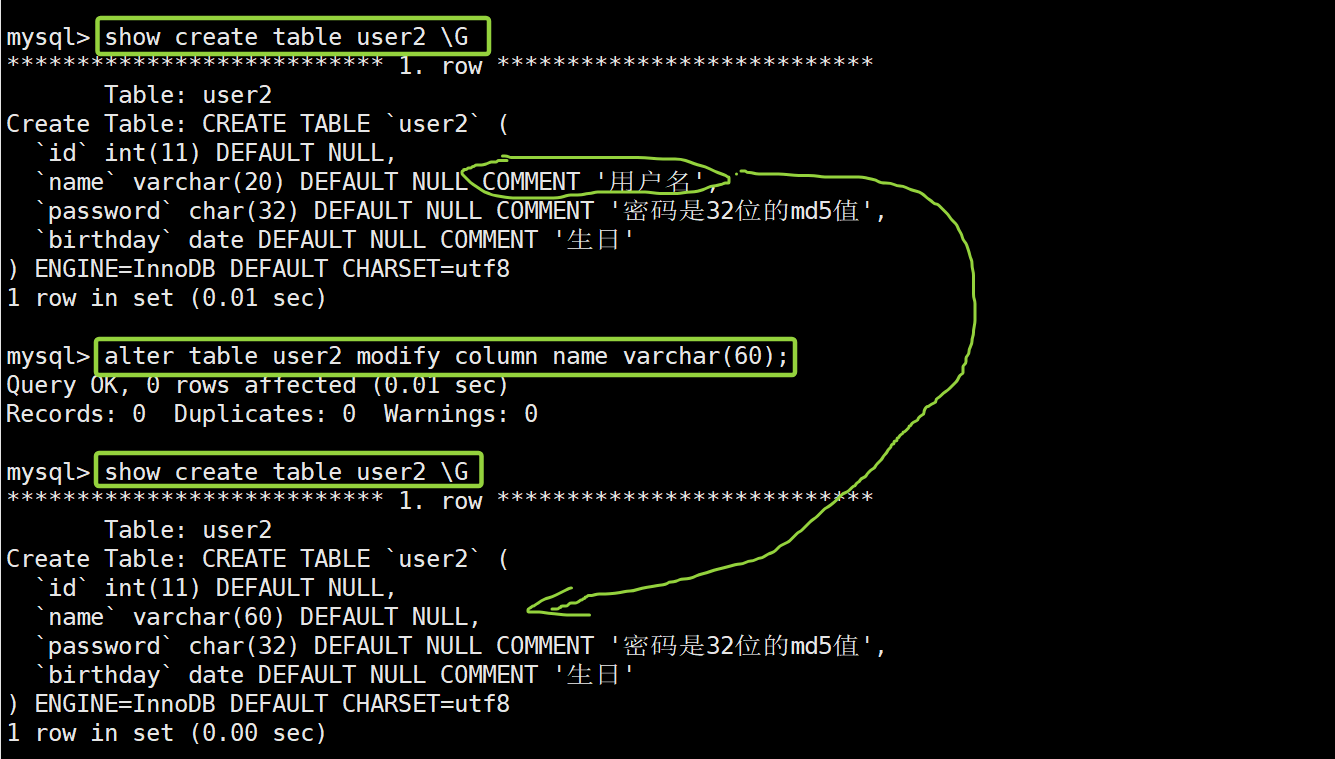
原本只是打算将name字段的数据类型由varchar(20)改为varchar(60),并没有打算修改其余部分,你对比修改前和修改后,发现在 show create table user2 \G 展示的信息中,字段 name 原本写的 comment '用户名' ,消失不见了!
前后的对比说明,MySQL是不提供对某一个列的指向性修改的,一旦针对某一个列进行修改就是覆盖式修改,需要重新编写字段的完整的定义,一般的操作操作如下:要将原本所有的信息写齐了!
- 复制name varchar(20) comment '用户名'。
- 改成name varchar(60) comment '用户名'。
- 最后写成完整SQL语句alter table user1 modify column name name varchar(60) comment '用户名'。
修改列名称
alter table table_name change column old_column_name new_column_name new_data_type;
-
alter table table_name :固定开头
-
change column :修改列的选项(这个选项一般是修改 列的名称 + 数据类型)
-
old_column_name new_column_name new_data_type; :指定要修改的列旧名字,指定要修改列的新名字和新数据类型。
-
覆盖式:这句SQL语句在用法上和alter table table_name modify column是差不多的,都是复制保存,修改,粘贴成修改后的SQL语句,唯一的区别就是提供修改列名称的作用。
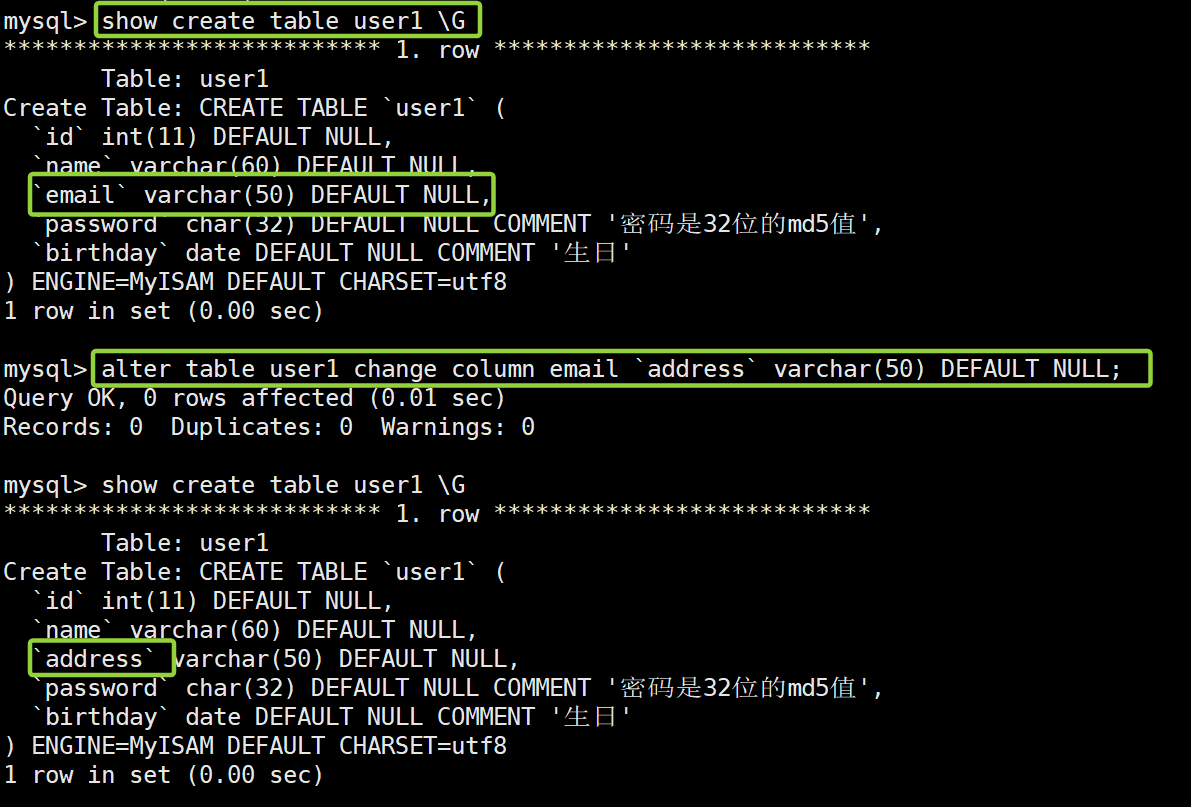
示例:
-- 查看user1表的创建语句 show create table user1 \G -- 将email列的名称修改为address (注意要将原有的其他属性写齐全了) alter table user1 change column email `address` varchar(50) DEFAULT NULL; -- 查看user1表修改后的创建语句 show create table user1 \G
删除列
alter table table_name drop column column_name;
- alter table table_name :固定开头
- drop column :删除列的选项
- column_name :指定要删除的列的名字
示例:
alter table user1 drop column email;
修改表名称
alter table old_table_name rename to new_table_name;
- alter table :固定开头
- rename to :修改表名称的选项
- old_table_name:旧的表名称。
- new_table_name:新的表名称。
- 补充:不要 to 也行
四、删除表结构
drop table [if exists] table_name;
- drop table:固定搭配。
- [if exists]:可选项,表结构存在则删除,不存在则报一个警告。
- table_name:要删除的表的名称。
- 删除字段一定要小心,删除字段及其对应的列数据都没了
五、数据库名称和表名称不要随意修改和删除
- 代码和工具链的紧密依赖
数据库名称和表名称不仅仅是结构标识符,它们贯穿整个项目、工具链和运行环境,是关键依赖。在代码中,表名和数据库名通常会被直接引用,涉及 SQL 查询、数据模型定义、ORM(对象关系映射)配置等核心部分。一旦名称发生更改,所有相关引用都需要逐一更新,并重新测试以确保功能正常。这不仅显著增加了开发人员的工作量,还可能引入潜在的错误。
- 外部系统的广泛影响
在实际开发中,数据库名称和表名称往往被外部系统或服务引用,例如报表系统、自动化任务调度、数据仓库集成以及监控工具等。一次名称修改意味着这些依赖系统也需要同步更新和适配。这种改动的影响范围广泛,涉及多个环节的一致性调整,容易引发问题,增加维护成本。
- 版本控制与协作难题
数据库结构的更改通常需要纳入版本控制系统进行管理。在多团队协作和持续集成的项目中,频繁的结构调整可能导致分支间的版本冲突,给版本管理带来额外的复杂性。此外,这种变动还容易导致开发、测试和生产环境之间的不一致,使问题排查变得更加困难,进而影响项目的稳定性和交付效率。
- 规划的重要性
为了避免上述问题,在设计数据库结构时应提前做好充分规划,确保名称的清晰性、模块化和可扩展性。合理的命名规范不仅能减少后续修改的需求,还能提高代码的可读性和维护性,从而降低因随意修改带来的繁琐操作和潜在风险。
- 代码和工具链的紧密依赖
-
-







