
深入剖析HBase架构

一、 HBase请求全流程分析
HBase 从客户端发起请求到返回结果的过程,涉及多个核心组件的协作,包括客户端库、ZooKeeper、HBase Master、RegionServer、WAL、MemStore、HFile 等。下面我们以一次完整的读请求与一次写请求为例,深度剖析整个系统的组件交互流程及底层实现。
🔁 1. 全景架构概览
┌───────────────┐
│ Client │
└──────┬────────┘
│
┌──────────────▼──────────────┐
│ ZooKeeper │
└──────────────┬──────────────┘
│
┌────────────▼─────────────┐
│ HBase Master │
└────────────┬─────────────┘
│
┌─────────────────▼──────────────────┐
│ RegionServer 集群 │
└────┬────────┬────────┬─────────────┘
│ │ │
┌──▼──┐ ┌──▼──┐ ┌──▼──┐
│RS-1 │ │RS-2 │ │RS-n │
└──┬──┘ └──┬──┘ └──┬──┘
│ │ │
┌────▼──┐ ┌────▼──┐ ┌───▼────┐
│Region1│ │Region2│ │RegionX │
└──┬────┘ └──┬────┘ └───┬────┘
▼ ▼ ▼
[ MemStore | WAL | HFile | Bloom | BlockCache ]
🧪 2. 一次 读请求流程:Client 查询某个 RowKey
假设查询语句为:
Get get = new Get(Bytes.toBytes("user_123"));
Result r = table.get(get);
📌 步骤详解:
✅ Step 1:Client 初始化连接(首次请求)
-
Client 通过配置的 ZooKeeper 地址连接到 ZooKeeper。
-
获取:
-
ROOT 表位置信息(.META 表)
-
.META 表中保存所有表的 Region → RegionServer 映射。
✅ Step 2:定位目标 Region
-
Client 从 .META 表中查出:
-
"user_123" 属于哪个 Region?
-
该 Region 当前由哪个 RegionServer 管理?
注:Client 具有缓存,后续访问不会再查询 ZooKeeper 或 META 表,提升性能。
✅ Step 3:向对应 RegionServer 发起 Get 请求
-
请求被路由到目标 RegionServer。
-
RegionServer 按如下顺序查找数据:
1. MemStore(内存最新数据) 2. BlockCache(热点数据缓存) 3. HFile(持久化文件)+ BloomFilter + BlockIndex 精确定位
✅ Step 4:构造返回结果
-
RegionServer 返回 Result 给客户端,包含多版本、列族、具体字段等。
✏️ 3. 一次 写请求流程:Client 写入某条数据
Put put = new Put(Bytes.toBytes("user_123")); put.addColumn("info", "name", Bytes.toBytes("Alice")); table.put(put);📌 步骤详解:
✅ Step 1:Client 查找目标 Region
-
同样从 ZooKeeper → .META 查找 RowKey 所属 Region。
✅ Step 2:向对应 RegionServer 发送 Put
-
客户端将数据打包后发送到目标 RegionServer。
 (图片来源网络,侵删)
(图片来源网络,侵删)✅ Step 3:RegionServer 写入数据(以下操作是原子性的)
-
写 WAL(Write-Ahead Log)
-
写入磁盘日志文件,确保数据可恢复。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
顺序写,性能高。
-
写 MemStore
 (图片来源网络,侵删)
(图片来源网络,侵删)-
将数据写入内存中的跳表结构(SkipList)。
-
是一个写后读先缓存,数据按 RowKey 排序。
-
返回客户端 OK
-
一旦 WAL 和 MemStore 写入完成,立即返回成功。
-
-
-
✅ Step 4:Flush 到磁盘(后台异步触发)
-
当 MemStore 达到阈值(如 128MB),会被刷写到 HFile。
-
刷盘操作:
-
MemStore → SSTable-like HFile(顺序写磁盘)
-
同时清除 WAL 中对应的日志片段
✅ Step 5:HFile 后续 Compaction(合并)
-
Minor Compaction:多个小 HFile 合并为中等文件
-
Major Compaction:全量合并,清理无效版本、TTL 过期数据
🔁 4. 关键组件之间的交互示意(读写全流程)
Client │ ├──> ZooKeeper:获取 .META 表位置 ├──> .META RegionServer:查找目标 Region 位置信息 │ ├──> 目标 RegionServer: │ ├── 读请求: │ │ ├── MemStore → BlockCache → HFile + Bloom │ │ └── 返回结果 │ └── 写请求: │ ├── 写 WAL(顺序写磁盘) │ ├── 写 MemStore(内存结构) │ └── 返回成功 │ └── 后台: ├── Flush → HFile ├── Compaction(压缩合并) └── Region Split(切分,写多后自动触发)🔍 5. 重要机制深入分析
机制 描述 WAL 顺序写磁盘,记录所有写入,宕机恢复依赖它 MemStore 内存写缓存,按行键排序,写入后先读此处 BlockCache 热数据缓存,命中则无需读磁盘 BloomFilter 判断某行是否在该 HFile 中,减少磁盘读取 HFile 类似 SSTable 的列存文件,按列族分布存储 Compaction 合并 HFile,提高查询效率,清除旧版本 Region Split Region 写入过大自动拆分,提高并发能力 📈 6. 性能优化与负载均衡如何参与
场景 机制 查询热点 BlockCache + BloomFilter 加速 写入压力大 Region 自动 Split,数据打散 RowKey RegionServer 不均衡 HMaster 定期触发 Region Balancer 查询慢 预热缓存 / 使用 Secondary Index 写放大 控制 Compaction 频率,避免过度合并 🧠 7. 总结
阶段 组件 功能 客户端 HBase Client 发起请求、ZooKeeper 寻址、缓存 Region 映射 服务发现 ZooKeeper 提供 .META/ROOT 定位、Master 选举 控制层 HBase Master RegionServer 管理、分裂、负载均衡 数据服务 RegionServer 执行读写请求、缓存、刷盘、压缩 数据层 WAL、MemStore、HFile 提供写入保障与高效查询能力 二、剖析WAL(Write-Ahead Log)写入机制和HFile 结构
我们现在深入剖析 HBase 的两个核心组件:
-
WAL(Write-Ahead Log)写入机制:确保数据写入的持久性和可靠性;
-
HFile 结构:是 HBase 持久化存储的核心格式,支持高效查询和压缩。
📝 1. WAL(Write-Ahead Log)机制
🔧 1. 作用
WAL 是 HBase 中写入操作的日志文件,所有写入操作必须先写 WAL,再写 MemStore,确保:
-
RegionServer 崩溃后能恢复数据;
-
写入顺序一致性;
-
提供持久性(P of CAP)。
📋 2. 写入流程详解
假设客户端执行如下操作:
put.addColumn("info", "age", 18); table.put(put);WAL 写入流程如下:
Client ↓ RegionServer ↓ 1️⃣ 构造 WALEdit: - 包含:rowkey、columnFamily、qualifier、timestamp、value 2️⃣ 写入 WAL(sync/flush) - 顺序写入 HDFS 上的日志文件(hdfs://hbase/WALs/...) - 使用 FSDataOutputStream.sync() 保证持久化 3️⃣ 写入 MemStore 4️⃣ 返回客户端 OK🧱 3. WAL 文件结构(HLog)
每个 WAL 文件由多个 WALEdit 构成,格式如下:
[HLogFile] ├── [Header] ├── [WALEdit 1] ├── [WALEdit 2] ├── ... └── [Trailer]
每个 WALEdit 包含:
-
RowKey(行键)
-
Column Family + Qualifier(列族+字段)
-
Timestamp
-
Value
-
SequenceId(全局递增 ID)
-
TxnId(用于 MVCC 多版本)
🛠 4. WAL 实现特性
特性 描述 顺序写 适合 SSD/HDD,性能稳定 回放机制 崩溃时使用 WAL 进行 MemStore 恢复 Split 多个 Region 共用一个 WAL,但在 split 后 WAL 文件会按 Region 切割 Rolling 超过一定大小自动滚动新文件 多 WAL 允许配置多个 WAL writer 提高并发写入(AsyncFSWAL) 🧊 2. HFile 存储结构
📦 1. HFile 是什么?
-
HBase 的底层文件格式;
-
类似于 SSTable(Sorted String Table);
-
所有 flush 后的数据最终都会落入 HFile。
🧱 2. HFile 结构图
[HFile] ├── Header ├── Data Blocks (K/V 列表) │ ├── RowKey1 → 列族/字段 → Value │ ├── RowKey2 → ... │ └── ... ├── Bloom Filter ├── Meta Block (索引/统计) ├── Block Index (索引所有 Block) └── Trailer (指向各部分的偏移地址)
🔍 3. HFile Block 结构(压缩 + 顺序)
HFile 中的数据按照 “Block” 存储,每个 Block 默认大小为 64KB,可配置。
每个 Block 结构如下:
[DataBlock] ├── Block Header ├── RowKey + CF + Qualifier + Value ├── 压缩块(Snappy/LZO/none) └── 校验码(checksum)
🧮 4. HFile 支持的索引与优化
组件 作用 BlockIndex RowKey → Block 的二级索引,用于定位具体 Block BloomFilter 判断 RowKey 是否存在某个 Block(减少磁盘访问) TimeRange 支持按时间过滤版本 Column Family 索引 支持按 CF 查询优化 块缓存(BlockCache) 热数据常驻内存,减少 IO 访问 💾 5. HFile 是如何被写入的?
当 MemStore 达到阈值时,触发 flush 操作:
MemStore(内存) ↓ HFile.Writer(构造器) ↓ 数据按 RowKey 排序、按列族写入 ↓ 写入 Block → 压缩 → 累积索引 ↓ 输出最终 HFile 文件 → HDFS
🔁 6. HFile 访问流程(查询时)
当查询一个 RowKey 时:
1. 查找 BlockIndex → 得到目标 Block 偏移量 2. 判断 BloomFilter:该行是否可能存在? 3. 定位 Block → 反序列化 + 解压缩 4. 查询对应字段,返回数据
🧠 3. WAL + HFile 协同机制
阶段 作用 组件 写请求 WAL 写入保障事务性、持久性 WAL 写入内存 MemStore 提供写后读 MemStore 刷盘 将 MemStore 写入磁盘 HFile 崩溃恢复 读取 WAL 重建 MemStore WAL 查询 BlockIndex + Bloom + BlockCache HFile ✅ 4. 小结
组件 关键作用 优势 局限 WAL 写前日志,宕机恢复保障 顺序写,稳定可靠 宕机后恢复有延迟 HFile 高效读文件,列存结构 支持压缩、索引、Bloom 写放大(Flush+Compaction) MemStore 写入缓存,顺序排序 快速写入、读命中 内存受限,需及时 flush 三、详细分析HBase是如何做到海量数据秒级查询
HBase 是一个基于 Hadoop HDFS 构建的高性能、分布式、面向列的 NoSQL 数据库,专门为支持大规模数据存储与高效读写设计。它借鉴了 Google Bigtable 的设计思想,具有良好的可扩展性与高吞吐特性,特别适合实时读写和大数据分析。
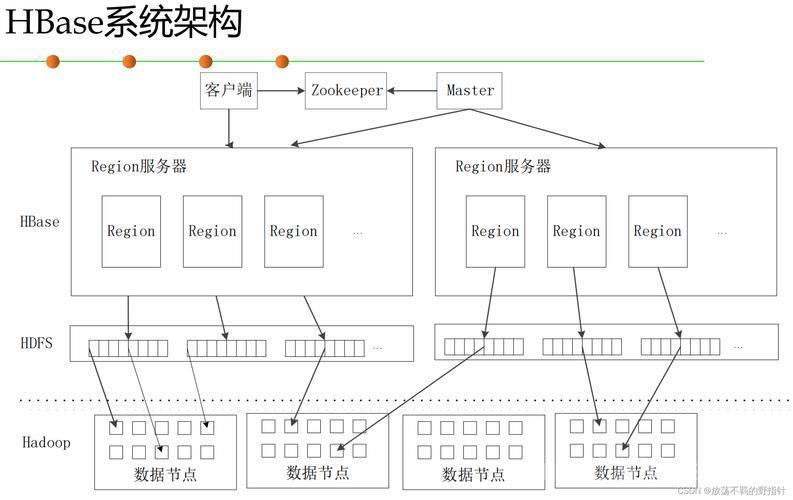
🧱 1. HBase 整体架构图
┌──────────────────────┐ │ 客户端 (Client) │ └────┬─────────┬───────┘ │ │ ┌────────▼──┐ ┌──▼────────┐ │ HBaseMaster│ │ Zookeeper │ └────┬──────┘ └────┬───────┘ │ │ ┌────────▼────────────────▼────────┐ │ RegionServer 集群 │ └────────┬────────┬────────┬────────┘ │ │ │ ┌────▼──┐ ┌────▼──┐ ┌───▼────┐ │Region1│ │Region2│ │RegionN │ └────┬──┘ └────┬──┘ └───┬────┘ ▼ ▼ ▼ ┌──────┐ ┌──────┐ ┌────────┐ │ HFile│ │ MemStore│ │WAL文件│ └──────┘ └──────┘ └────────┘🔍 2. 核心组件剖析
1. HMaster(主控节点)
-
负责管理 RegionServer(RS),如负载均衡、Region 分裂与迁移。
-
不参与读写数据,故单点故障不会影响服务可用性。
-
实际高可用通过 ZooKeeper 协调多 HMaster 实现。
2. RegionServer(数据处理节点)
每个 RS 管理多个 Region(逻辑分片),一个 Region 包含:
-
MemStore:内存中缓存写入数据。
-
HFile:最终落盘文件(以列族为单位组织)。
-
WAL(Write-Ahead Log):预写日志,防止宕机数据丢失。
3. Region(水平切分)
-
每张表按 RowKey 范围划分为多个 Region。
-
每个 Region 存储某一 RowKey 范围内的所有数据。
-
Region 是 HBase 的分区最小单位,可动态分裂。
4. ZooKeeper(协调组件)
-
管理 RegionServer 的注册与发现。
-
帮助 Client 获取表的元数据及 Region 位置信息。
-
保障 Master 的选举与集群元数据一致性。
🧬 3. 数据存储结构
数据模型(面向列的稀疏表)
RowKey ColumnFamily:Qualifier Timestamp Value "user001" info:name 1680000000000 "Alice" "user001" info:email 1680000000001 "alice@example.com" "user001" login:ip 1680000000002 "192.168.1.2"
-
行键(RowKey):主键,按字典序排序,是读取性能的关键。
-
列族(ColumnFamily):数据物理存储单位,存储在不同 HFile 中。
-
列限定符(Qualifier):用户定义的具体列。
-
版本(Timestamp):HBase 原生支持多版本。
⚡ 4. HBase 快速读写的关键机制
✏️ 1. 写入流程(高吞吐 + 容错)
Client → RegionServer → 1. 写 WAL(顺序写磁盘)→ 2. 写 MemStore(内存结构)→ 3. 返回 Client 成功
-
数据写入非常快(只需内存 + 顺序写日志)
-
WAL 保证数据可靠,宕机后可通过 WAL 恢复数据
-
当 MemStore 达阈值时刷盘为 HFile(不可变)
🔎 2. 查询流程(高效率 + 列存结构)
Client → 查找目标 RowKey → 1. 从 MemStore 查(最新数据)→ 2. 从 BlockCache 查(缓存 HFile)→ 3. 查 HFile → BloomFilter & BlockIndex → 精确定位
查询优化关键技术:
技术 描述 Bloom Filter 判断某 Key 是否存在于 HFile,避免无效 IO BlockCache 热点数据缓存到内存,极大加快读性能 RowKey 排序 有序存储 + 范围扫描极快 列簇分离 查询按需读取列簇,避免读无用数据 🧠 5. HBase 是如何支撑海量数据 + 快速查询的?
关键机制 说明 ✅ 水平扩展的 RegionServer 架构 数据自动划分为多个 Region,Region 可自动迁移和负载均衡 ✅ 基于 RowKey 有序存储 可实现 O(log n) 范围扫描,支持前缀、范围查询等 ✅ 列族 + 列限定符组织 仅查询需要列,降低 IO 负载 ✅ Block Index + Bloom Filter + 缓存机制 快速定位数据 block,跳过无关文件块 ✅ 写入 WAL + MemStore,延迟刷盘 提升写性能,避免频繁磁盘 IO ✅ 压缩 + 编码(LZO/Snappy + Prefix Encoding) 提高磁盘利用率 + 提升扫描性能 🛠 6. HBase 的实际吞吐表现
指标 表现(典型) 单节点写入 5~10 万条/s(仅写 WAL + MemStore) 多 RegionServer 横向扩展支持千万级 TPS 查询延迟 毫秒~数十毫秒(RowKey 精确查找) 范围扫描 高速(需合理 RowKey 设计 + filter) 🎯 7. 总结
✅ HBase 适用于:
-
海量数据存储(PB 级别)
-
高并发写入(实时入库)
-
快速的单行/批量查询
-
高可扩展性 + 高容错
❌ 不适用于:
-
复杂多表 join、事务型场景
-
非主键列模糊查询(需要额外索引服务如 Phoenix/ES)
四、热点rowkey 设计优化与负载均衡方案
热点 RowKey 问题是 HBase 中最常见、最容易导致性能瓶颈的场景之一。由于 HBase 是按照 RowKey 的字典序进行存储和查找,如果大量数据集中写入某一类 RowKey(如递增 ID、时间戳),就会导致:
-
写入集中在少数几个 RegionServer 上,引发写热点;
-
MemStore 和 WAL 压力不均衡,造成 RegionServer 崩溃;
-
负载不均衡,影响整体系统吞吐;
-
查询热点也可能导致 RS 负载飙升。
🔥 1. 什么是热点 RowKey?
指大量写操作或读操作集中落到少数几个 RowKey 或同一个 Region 范围内的 RowKey。
典型例子:
RowKey = 用户ID + 时间戳 RowKey = 订单号(自增ID) RowKey = 202505280101 // 固定时间前缀
结果:高并发场景下,全都写入同一个 Region,无法充分利用 HBase 的分布式架构。
🧪 2. 热点 rowkey 问题的表现
表现 影响 RegionServer 瞬间 CPU 飙高 写入压力集中 MemStore flush 频繁 GC 压力大 Query QPS 上不去 因为全靠一个 RS 抗压 Region 分裂过慢 写入集中,其他 Region 空闲 客户端 timeout、WAL 写入延迟 单点压力过大 🎯 3. 热点 RowKey 的优化策略
✅ 1. RowKey 前缀哈希/前缀打散(推荐)
将 RowKey 打散,前缀加随机前缀或 hash 前缀,打散写入热点。
原始 RowKey: user_10001 打散后 RowKey: 03_user_10001 // 03 为前缀哈希(user_id.hash % N)
优点:
-
写入分散到多个 Region
-
不影响精确查找(可通过二级索引或反向前缀组装)
缺点:
-
范围扫描复杂:需扫描多个打散前缀
✅ 2. 时间戳反转 + 前缀扰动
如果是时间排序的数据,可以将时间戳反转 + 打散前缀,避免新数据集中写入末尾 Region。
原始时间戳:202505280101 → 反转后 RowKey:798494719898 加扰动前缀:R03_798494719898
✅ 3. Salt 前缀 + 多 Region 预分区(PreSplit)
结合前缀 + Region 预分区,使得不同 salt 对应不同 Region。
RowKey: salt + "_" + 原始Key 如: 00_userA, 01_userB, ... 99_userZ 建表时: create 'user_table', 'info', SPLITS => ['00', '01', ..., '99']
通常建议 Salt 值为 10~100,根据实际 QPS 调整。
✅ 4. 基于业务字段构造高分散度 RowKey
构造 RowKey 时综合考虑业务高基数字段,例如:
RowKey = hash(用户ID) + 商品ID + 反转时间戳
要求满足:
-
唯一性
-
分散性(高基数字段在前)
-
可按需组装业务字段
✅ 5. 热点数据异构缓存(如:ES / Redis)
-
对热点行或聚合统计信息,使用 Redis/ES 缓存
-
HBase 仅做底层存储,缓存层做热点抗压
⚙️ 4. 负载均衡调优策略(Region 层面)
🔄 1. Region 自动 Split(分裂)
-
每个 Region 写入超过 hbase.region.max.filesize(默认 10GB)时自动分裂
-
配合预分区可以避免写入集中到一个大 Region
🤖 2. Region Rebalancer(自动负载均衡)
-
HMaster 会定期检查各 RegionServer 的 Region 数
-
对过载节点自动迁移部分 Region 到空闲 RS
调优参数:
hbase.balancer.period = 300000 # 默认 5 分钟触发负载均衡 hbase.regionserver.handler.count = 30 hbase.master.loadbalance.bytable = true # 分表均衡
🧠 5. 热点查询优化方案
✅ 1. BlockCache 提升热点数据命中率
-
配置合理的 BlockCache 大小(hfile.block.cache.size)
-
热数据常驻内存,避免频繁读磁盘
✅ 2. 使用 Secondary Index 系统(如 Phoenix)
-
Phoenix 支持二级索引 + SQL 查询接口
-
可加速非 RowKey 条件的查询(但写入时成本增加)
✅ 3. 查询打散(client 侧发起并行请求)
-
对多个前缀扫描打散 RowKey 时,Client 并发发起多个 scan,聚合结果
-
适合 Salt 分区 + 多线程扫描
✅ 6. 小结:热点 rowkey 优化建议清单
场景 优化建议 写入过热 RowKey 加前缀打散 / salt / 反转时间戳 查询过热 BlockCache + 热点缓存层(Redis) 大表初始化 创建时预 split,设置合理的 region 边界 范围查询较多 结构中后部保留顺序字段,组合设计 负载不均衡 启用 balancer,定期检查 Region 数量 五、如何解决Hbase 数据倾斜的问题
HBase 数据倾斜(Data Skew)是指数据在 Region(分区)之间分布不均,导致某些 RegionServer 承载大量请求(热点),而其他空闲,从而严重影响读写性能和系统的可扩展性。
📌 1. HBase 数据倾斜的常见表现
类型 描述 写倾斜 多个客户端写入集中在某些 RowKey,导致单 Region 压力巨大 读倾斜 查询请求集中访问某些热点数据行或列族 Region 热点 某 Region 因数据分布不均被频繁访问,RegionServer CPU 飙升 🧠 2. 数据倾斜的根本原因
-
RowKey 设计不合理
-
顺序 RowKey(如时间戳、递增 ID)导致所有写入集中于最后一个 Region。
-
预分区没做好
-
没有预先创建好 Region 導致所有写入集中于一个 Region,未触发 split。
-
热点查询/更新集中访问某些行或列
-
某些 RowKey(如某个用户ID)读写频率极高。
-
-
-
✅ 3. 解决 HBase 数据倾斜的实战方案
方案 1️⃣:RowKey 盐值打散(Salting)
-
将 RowKey 前加 hash 前缀或固定范围前缀,使其打散到多个 Region。
✅ 示例:
原始 RowKey: 20250528_user123 加盐后 RowKey: 03_20250528_user123
-
“03” 是通过 hash(user123) % 10 计算出的前缀,共有 10 个前缀,对应 10 个 Region。
🧠 查询时需全表扫描所有前缀,可用 Union Scan / RowPrefixFilter 解决。
方案 2️⃣:预分区(Pre-Split Regions)
在建表时通过指定 SPLITS 参数,手动指定 RowKey 范围拆分 Region,避免所有数据集中写入默认 Region。
✅ 示例:
create 'user_log', 'info', SPLITS => ['10', '20', '30', '40', '50']
适合有明显 RowKey 范围规律的数据,如用户ID、时间戳等。
方案 3️⃣:RowKey 倒排设计(Reversed RowKey)
将 RowKey 中高频变动字段放前面,低变动放后面,或做倒排,使写入分布更均匀。
示例:
原始: 20250528_user123 倒排: user123_20250528
方案 4️⃣:利用 Phoenix 自动盐值
如果使用 Phoenix(HBase 的 SQL 层),建表时可加 SALT_BUCKETS 自动打散 rowkey。
✅ 示例:
CREATE TABLE user_activity ( user_id VARCHAR PRIMARY KEY, activity_time TIMESTAMP ) SALT_BUCKETS = 8;
方案 5️⃣:HFile Compaction 优化
-
定期设置 Major Compaction,让 HFile 合并,避免小文件过多;
-
使用 TTL / Delete 清理旧数据减少存储压力。
方案 6️⃣:冷热数据分离 / HBase 归档策略
-
将冷热数据拆分成不同表或不同列族;
-
热数据部署在 SSD + 高性能节点,冷数据可用 HDFS 归档或备份。
🚥 4. 读倾斜优化
技术 描述 BlockCache 热点 Block 预加载进内存,减少磁盘 IO BloomFilter 提高数据 Block 命中率,减少误读 RowFilter/PrefixFilter 精确过滤,减少全表扫描 定期分析热点访问模式 做缓存下沉(如 Redis 缓存热点行) 📈 5. 监控与调优
使用以下工具观察热点行为:
-
HBase UI(/master-status)
-
RegionServer JVM 指标(如 GC、MemStore 使用率)
-
JMX、Prometheus + Grafana 监控 Region 访问模式
-
HDFS Block 分布与 IO 压力分析
🎯 6. 总结
方法 适用场景 优点 缺点 RowKey 盐值 高并发写入 简单直接 查询需打散 预分区 结构化 RowKey 写入均衡 分区需预估 RowKey 倒排 时间序列数据 分布均匀 查询需额外处理 Phoenix 盐桶 SQL 场景 无侵入打散 查询有影响 BloomFilter + BlockCache 热点读优化 快速命中 内存占用大 冷热分层 大数据归档 降低热点压力 实施复杂
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-







