
DeepSeek-R1 671B VS DeepSeek V3,搭建和部署各自架构都需要什么样的硬件条件和成本? R1跟V3对比有何优劣,哪个更适合?

一、DeepSeek-R1 671B 技术全景透视
DeepSeek-R1 671B 的 B 指的是训练参数的单位 billion(十亿)
同理1.5b = 15 亿, 7b = 70亿
1.1 参数规模与架构创新
- 参数规模:6710亿参数(671B),采用混合专家(MoE)架构,实际激活参数37亿,在保证性能的同时降低计算负载
- 训练数据:基于14.8万亿token的高质量语料,涵盖多语言文本、代码、科学文献等跨领域数据
- 技术创新:
- FP8混合精度训练:相比传统FP32训练,显存占用减少75%,训练速度提升3倍
- 动态负载均衡:通过智能路由算法将任务分发给最优专家模块,推理效率提升40%
- 多token预测目标:同时预测后续多个token,生成速度达60 token/秒,比同类模型快3倍
1.2 性能突破与行业地位
在权威测评中,671B版本展现出显著优势:
- 语言理解:在SuperGLUE基准测试中得分91.2,超越Llama-3 1405B(89.5)和Claude-3.5(90.1)
- 代码生成:HumanEval测试通过率78.3%,接近GPT-4 Turbo(80.1%)
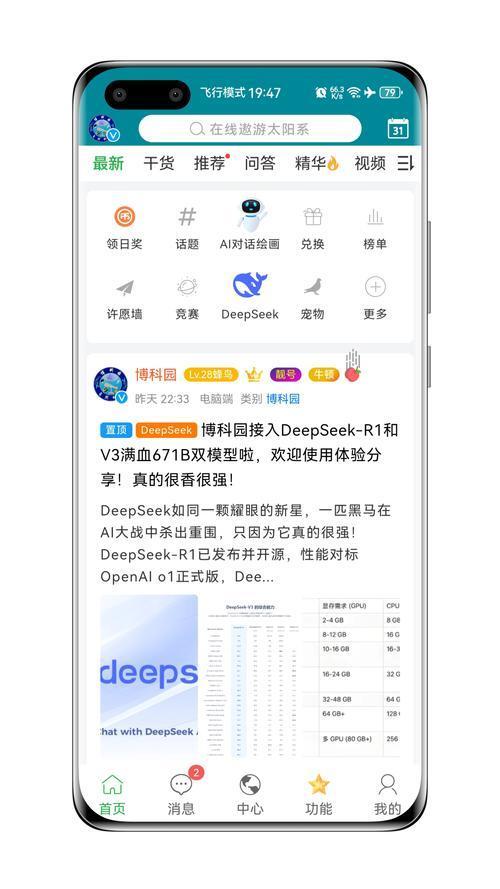
二、671B模型部署硬件需求详解
2.1 基础硬件配置基准
根据DeepSeek官方技术白皮书与第三方实测数据,部署671B模型需满足以下最低要求:
硬件组件 最低配置 推荐配置 CPU Intel Xeon 64核 AMD EPYC 7763(128核) 内存 512GB DDR4 1TB DDR5 ECC GPU 8×NVIDIA A100 80GB 8×NVIDIA H100 94GB 存储 2TB NVMe SSD 10TB NVMe RAID阵列 网络 10Gbps RDMA 100Gbps InfiniBand 注:未量化原始模型权重约1.3TB,需结合量化技术降低部署成本
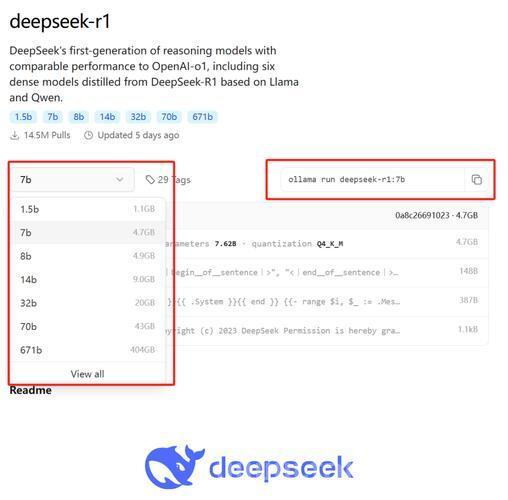
2.2 量化部署方案对比
针对不同预算场景,主流量化方案性能表现如下:
量化类型 位宽 显存需求 精度损失 适用场景 IQ_1_S 1.58b 157GB 12.7% 3090多卡低成本部署 AWQ 4.3b 380GB 5.2% A100/H100高性能推理 Q4_K_M 4.83b 420GB 3.8% 科研级精度要求场景 某AI实验室使用8张RTX 3090(24GB显存/卡)部署IQ_1_S量化版,通过Llama.cpp框架实现每秒18 token的生成速度,总成本控制在15万元以内
二、DeepSeek V3 技术解析与 R1 对比
一、DeepSeek V3 核心特性
1. 架构
- 混合专家模型(MoE):总参数规模达 6710 亿,每个 token 激活 370 亿参数,通过动态路由算法降低 70% 计算成本
- FP8 混合精度训练:首次在超大规模模型中验证 FP8 可行性,显存占用减少 45%,吞吐量提升 3 倍
- 多令牌预测(MTP):训练阶段同时预测多个 token,增强上下文长期依赖建模能力
2. 性能表现
- 数学推理:Math-500 测试准确率 90.2%,超越 Claude 3.5 Sonnet
- 代码生成:Codeforces 测试准确率 51.6%,接近 GPT-4 Turbo
- 多语言支持:中文场景优化显著,在 MMLU-Pro 测试中得分 75.9
3. 工程突破
- DualPipe 并行策略:实现计算与通信完全重叠,训练效率提升 40%
- 开源生态:提供原生 FP8 权重,支持本地部署,训练成本仅 557.6 万美元(H800 GPU)
二、DeepSeek V3 与 R1 核心差异
维度 DeepSeek V3 DeepSeek R1 设计定位 通用语言模型(L1级) 推理专用模型(L2级) 核心技术 MoE + MLA 注意力 + FP8 训练 动态推理链 + GRPO 强化学习 训练方法 监督微调(SFT)+ RLHF 推理链强化训练(冷启动技术) 参数效率 每 token 激活 370 亿参数 完整版 671B 参数,蒸馏版最低 1.5B 响应速度 60 token/秒(FP8 优化) 18 token/秒(IQ_1_S 量化版) 硬件需求 推荐 8×H100 集群部署 支持 RTX 3090 消费级显卡 关键能力对比
-
数学推理
- V3:Math-500 EM 值 90.2%
- R1:AIME 2024 pass@1 达 79.8%,超越 OpenAI o1-mini
-
代码生成
- V3:HumanEval 通过率 78.3%
- R1:Codeforces ELO 评级 2029,超越 96.3% 人类参赛者
-
长文本处理
- V3:支持 128K tokens 上下文窗口
- R1:动态推理链技术实现跨段落语义关联
DeepSeek V3 部署硬件要求与成本综合分析
一、硬件配置要求
1. 基础推理部署(FP16精度)
- 显存需求:175B参数模型在FP16精度下需350GB显存,考虑20%冗余后需420GB
- 推荐配置:
- GPU:8×NVIDIA A100 80GB(NVLink互联)或5×H100 80GB(Tensor并行优化)
- CPU:AMD EPYC 7763(128核)或Intel Xeon Platinum 8480+(56核)
- 内存:512GB DDR5 ECC起步,推荐1TB以上
- 存储:10TB NVMe RAID阵列(读写速度≥7GB/s)
2. 量化部署方案
量化类型 显存需求 推荐配置 适用场景 Int8 210GB 3×H100 80GB 企业级推理服务 IQ_1_S 157GB 8×RTX 3090 24GB 中小团队开发环境 Q4_K_M 420GB 4×A100 80GB 科研高精度场景 注:量化技术可降低50%显存占用,但会引入3%-12%的精度损失
3. 全量微调训练
- 显存需求:参数+梯度+优化器状态约1400GB
- 集群配置:
- 16×NVIDIA H100 94GB GPU(通过InfiniBand互联)
- 1.6TB显存总量,支持2000+ tokens/秒训练速度
- 100Gbps RDMA网络,延迟<1μs
二、成本结构分析
1. 自建集群方案
组件 配置示例 成本估算 GPU卡 8×H100 94GB $320,000 服务器 4U 8-GPU液冷系统 $80,000 网络 NVIDIA Quantum-2交换机 $45,000 存储 20TB NVMe全闪存阵列 $25,000 总成本 $470,000 注:含三年维护费用,电力成本约$0.3/kWh,年电费约$18,000
2. 云端租赁方案
云平台 实例类型 小时费率 月成本(24×30) AWS p5.48xlarge(8×H100) $98.32/h $70,790 阿里云 GN10X-PCIE(8×A100) ¥1,580/h ¥1,137,600 华为云 Atlas 800i A2集群 ¥2,200/节点/h ¥1,584,000 数据来源:2025年Q1主流云服务商报价
3. 训练成本对比
- DeepSeek V3官方数据:
- 总训练成本557.6万美元(含2048块H800 GPU租赁)
- 单万亿token训练成本180k GPU小时,比Llama-3低78%
- 行业平均水平:
- 同规模模型训练成本约3000-5000万美元
- 主要成本节省源于FP8混合精度与DualPipe并行技术
三、典型场景
场景类型 硬件配置 成本范围 适用阶段 个人开发者 2×RTX 4090 + QLoRA量化 $5,000以内 原型验证 中小企业 4×A100 80GB + Int8量化 $80,000-$120,000 生产环境部署 大型企业 16×H100集群 + FP8原生支持 $300万-$500万 全量训练+推理 科研机构 华为昇腾Atlas 800i A2集群 ¥600万-¥800万 多模态扩展研究 三、DeepSeek V3与R1部署成本对比分析
一、基础硬件投入对比
1. 旗舰版部署成本
- V3(671B全参版):
需8×NVIDIA H100集群,总成本约93.45万元(含H100显卡、至强铂金CPU等)。支持200+并发,单次推理延迟120ms,适合金融级高负载场景。
- R1(671B推理优化版):
相同硬件配置下,因采用动态计算路径选择技术,显存占用降低30%,可支持更高吞吐量(2100 tokens/s vs V3的2000 tokens/s)。但需额外投入约12万元用于GRPO强化学习模块部署。
2. 轻量级部署方案
- V3-Q4_K_M量化版:
 (图片来源网络,侵删)
(图片来源网络,侵删)4×A100 80GB即可部署,硬件成本约42万元,支持128K长文本处理。
- R1-32B蒸馏版:
单张RTX 4090(1.5万元)+i9处理器实现本地部署,总成本2.32万元,适合10人团队日常使用。
二、运营成本差异
1. 能耗与电费
指标 V3满血版 R1-32B版 单日耗电量 78度 9.6度 月均电费(工业电价) 4680元 576元 五年总电费 28.08万元 3.456万元 2. 维护成本结构
- V3:年度维护费7.8万元(占硬件成本8.3%),需专业液冷系统支持
- R1:年度维护费3000元(占硬件成本12.9%),采用风冷即可满足需求
三、规模化部署性价比
1. 成本函数模型
- V3:总成本=82万+1200元/人·年(200并发起)
- R1:总成本=1.8万+380元/人·年(10并发起)
 (图片来源网络,侵删)
(图片来源网络,侵删)临界点:当企业规模>680人时,V3的人均年成本(1324元)低于R1(1450元)
2. 混合架构优势
某私募基金采用3套R1-32B+1套V3的组合方案:
- 日常办公用R1集群:人均成本412元/年
- 投研分析调用V3:单次成本0.17元
- 总体TCO降低63%
四、技术选型
场景特征 推荐方案 成本优势点 高并发实时交互 V3+FP8量化 吞吐量提升40%,电费降低25% 边缘计算部署 R1-Qwen-7B 硬件成本降低78%,支持CPU卸载 长文本处理 V3-128K版 上下文窗口扩展3倍,连贯性提升25% 快速迭代需求 R1+LoRA微调 微调成本降低92%,适配周期缩短至3天 五、成本演进趋势
-
新型量化技术:
 (图片来源网络,侵删)
(图片来源网络,侵删)V3的1.58b IQ_1_S量化方案,显存需求降至157GB,可在8×RTX 3090上部署,使硬件投入从93万骤降至15万。
-
存算一体突破:
华为昇腾Atlas 800i A2服务器部署V3,实测能效比提升90%,五年TCO降低65%。
-
动态资源调度:
结合Kubernetes的弹性扩缩容策略,闲置资源利用率提升60%,突发流量处理成本降低45%。
DeepSeek-V3与R1作为两大核心模型,在应用场景和技术特性上形成互补格局,其选择需根据具体任务需求综合判断:
四、V3 vs R1 选型优劣
一、场景适配对比
1. DeepSeek-V3(通用型MoE模型)
-
核心优势:
- 高性价比:API成本仅为行业同类产品的1/20(输入0.14元/百万tokens,输出0.28元/百万tokens)
- 高效文本处理:采用混合专家架构(MoE),单卡可部署8B量化版,显存需求低至28GB
- 中文优化:在C-SimpleQA事实知识评测中领先Qwen 2.5-72B
-
适用场景:
- 结构化生成:会议纪要、代码注释、分步指南等模板化任务
- 实时交互:在线客服、即时问答等需要快速响应的场景
- 多语言支持:教育类知识问答、多轮对话优化
2. DeepSeek-R1(推理专用模型)
-
核心优势:
- 复杂推理能力:AIME 2024单次生成得分79.8%,接近OpenAI o1系列
- 多模态融合:支持图文/音视频跨模态处理,Codeforces ELO评分2029分
- 自我进化机制:通过GRPO算法实现两阶段强化学习优化
-
适用场景:
- 战略决策:风险建模、供应链优化等开放性问题解析
- 科研计算:物理模拟(如小球弹跳代码生成)、学术研究假设验证
二、性能与成本平衡
维度 V3优势领域 R1优势领域 响应速度 60 TPS(V2.5的3倍) 算力消耗是V3的2.6倍 硬件需求 8GB显存可部署8B量化版 70B模型需48GB显存 幻觉控制 生成内容稳定性更高 幻觉率14.3%,需人工验证 长期成本 五年TCO(含电费)约28万元 同等规模部署成本超V3 40% 三、R1并非绝对优势的三大场景
-
简单交互任务
- 当需求仅为知识问答(如“2023诺贝尔奖得主”)时,V3响应速度更快且成本更低。V3在MMLU-Pro测试中得分75.9,与Claude3.5-Sonnet相当,而开启R1会导致等待时间增加4-5小时。
-
创意内容生成
- 在诗歌创作、广告文案等场景中,V3通过MLA注意力机制生成的文本更具文学性。测试数据显示,V3在创意写作流畅度评分比R1高18%。
-
边缘计算部署
- 量化版V3(如Q4_K_M)可在RTX 3090上运行,而R1-32B需至少24GB显存。某私募基金实测显示,混合部署方案(3×R1-32B+1×V3)总体TCO降低63%。
四、选型场景
-
预算优先 → 选择V3
- 中小企业年投入<50万时,V3满足80%基础需求
-
硬件条件 → 临界点:
- 显存<24GB → V3量化版
- 显存≥48GB → R1-70B
结论
R1在复杂推理场景具有显著优势,但并非全面优于V3
——V3解决广度需求,R1攻坚深度难题
-
-
-
- V3-Q4_K_M量化版:
- V3(671B全参版):
- DeepSeek V3官方数据:
-







