
Python 爬虫之requests 模块的应用

requests 是用 python 语言编写的一个开源的HTTP库,可以通过 requests 库编写 python 代码发送网络请求,其简单易用,是编写爬虫程序时必知必会的一个模块。
requests 模块的作用
发送网络请求,获取响应数据。
中文文档: https://docs.python-requests.org/zh_CN/latest/index.html
requests 模块的安装
安装命令如下:
pip install requests 或者 pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
具体安装运行如下图所示:
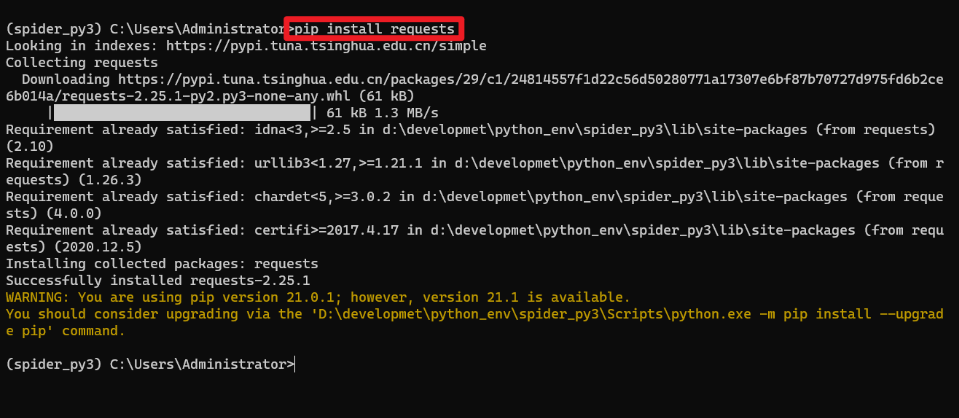
查看安装好的 requests 模块的信息
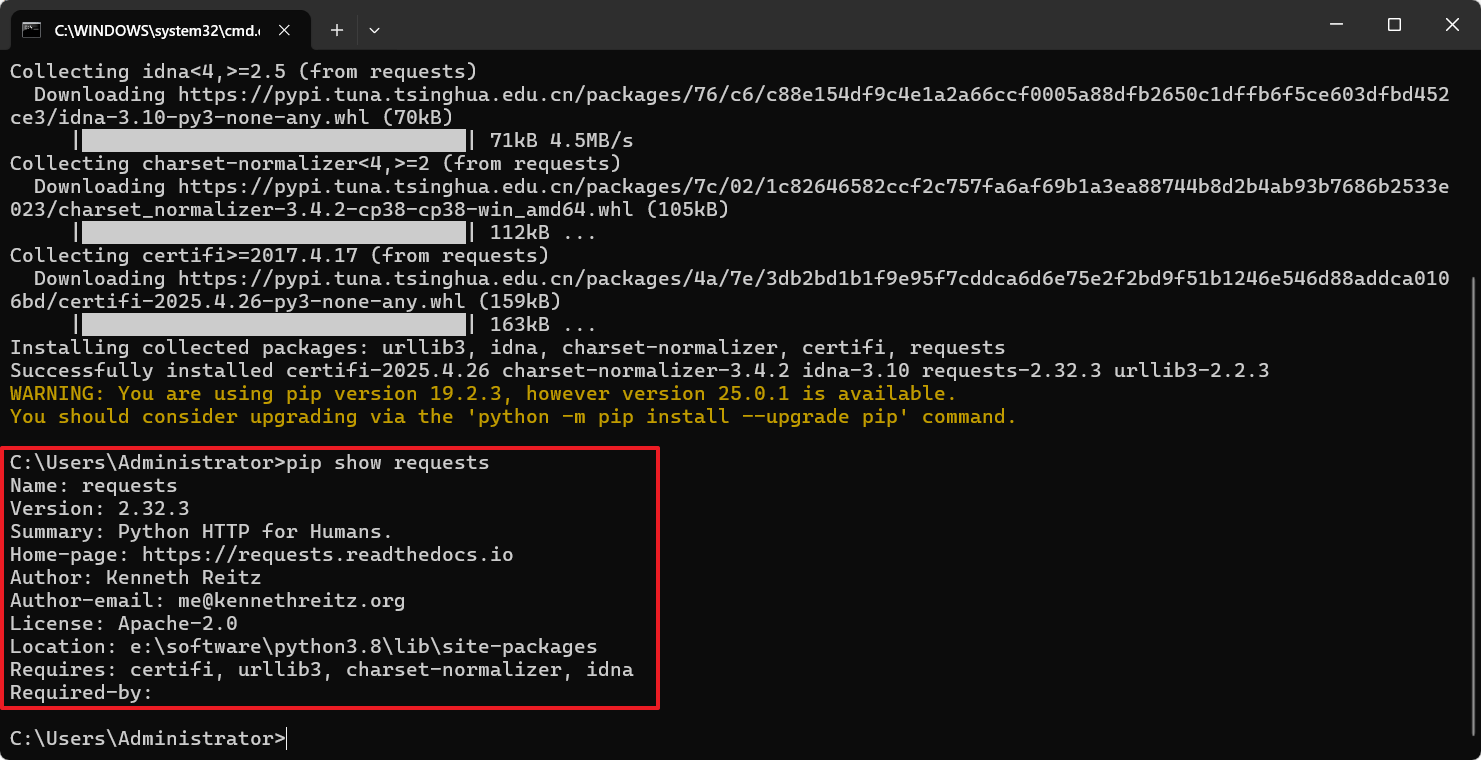
pip show requests
具体运行如下图所示:
requests 模块的基本使用
知识点:
- 掌握 requests 发送 GET 请求
- 掌握 response 对象的基本属性
- 掌握 response.text 和 response.content 的区别
- 掌握 requests 发送自定义请求头的方式
- 掌握 requests 发送带参数的get请求
1. requests 发送 GET 请求
使用 requests 模块发送 GET 请求的语法是: requests.get(url), 调用完该方法之后会返回一个 response 响应对象。
需求:通过 requests 向百度首页发送请求,获取百度首页的数据。
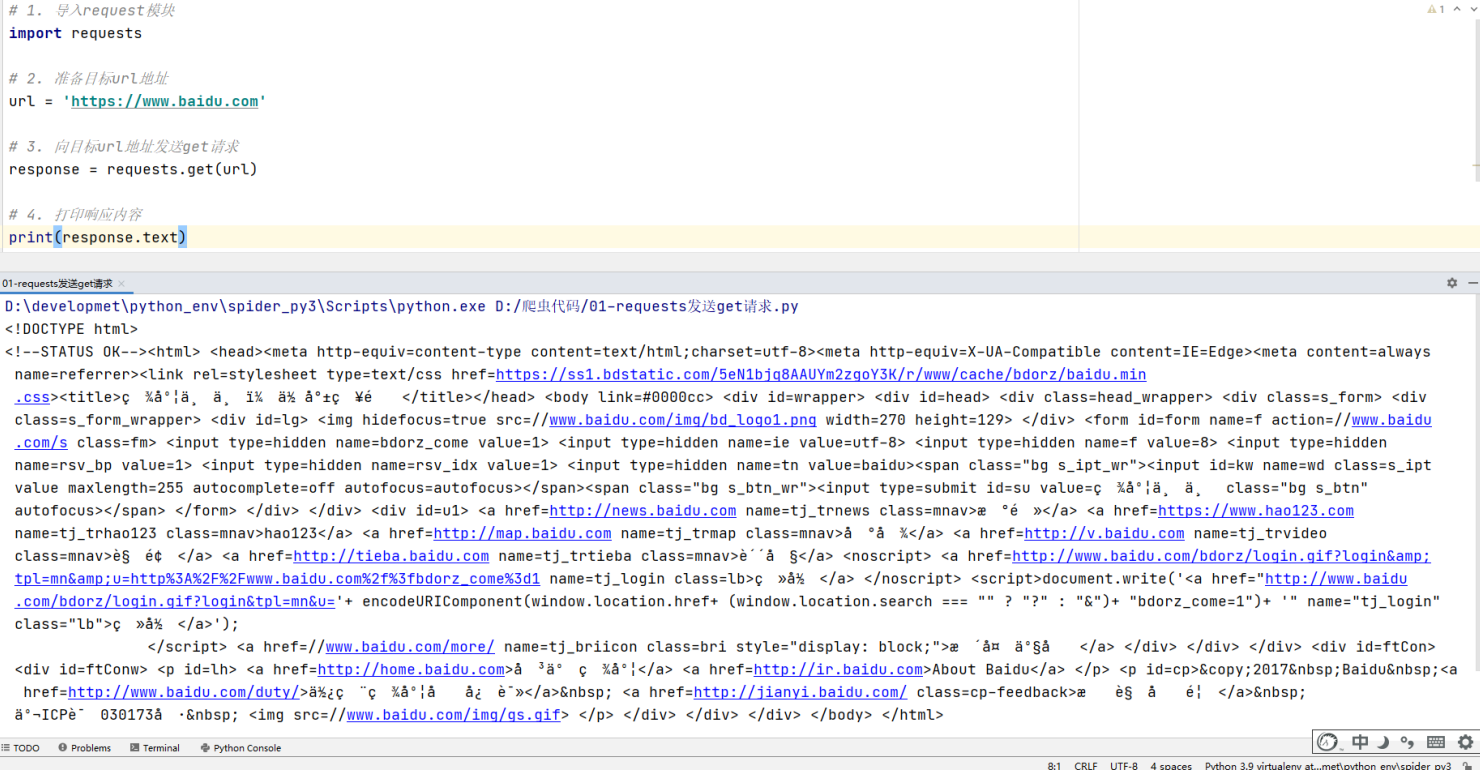
# 1. 导入request模块 import requests # 2. 准备目标url地址 url = 'https://www.baidu.com' # 3. 向目标url地址发送get请求 response = requests.get(url) # 4. 打印响应内容 print(response.text)
运行代码结果如下:
2. response 响应对象
观察上边代码运行结果发现,有好多乱码;这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题。
代码如下:
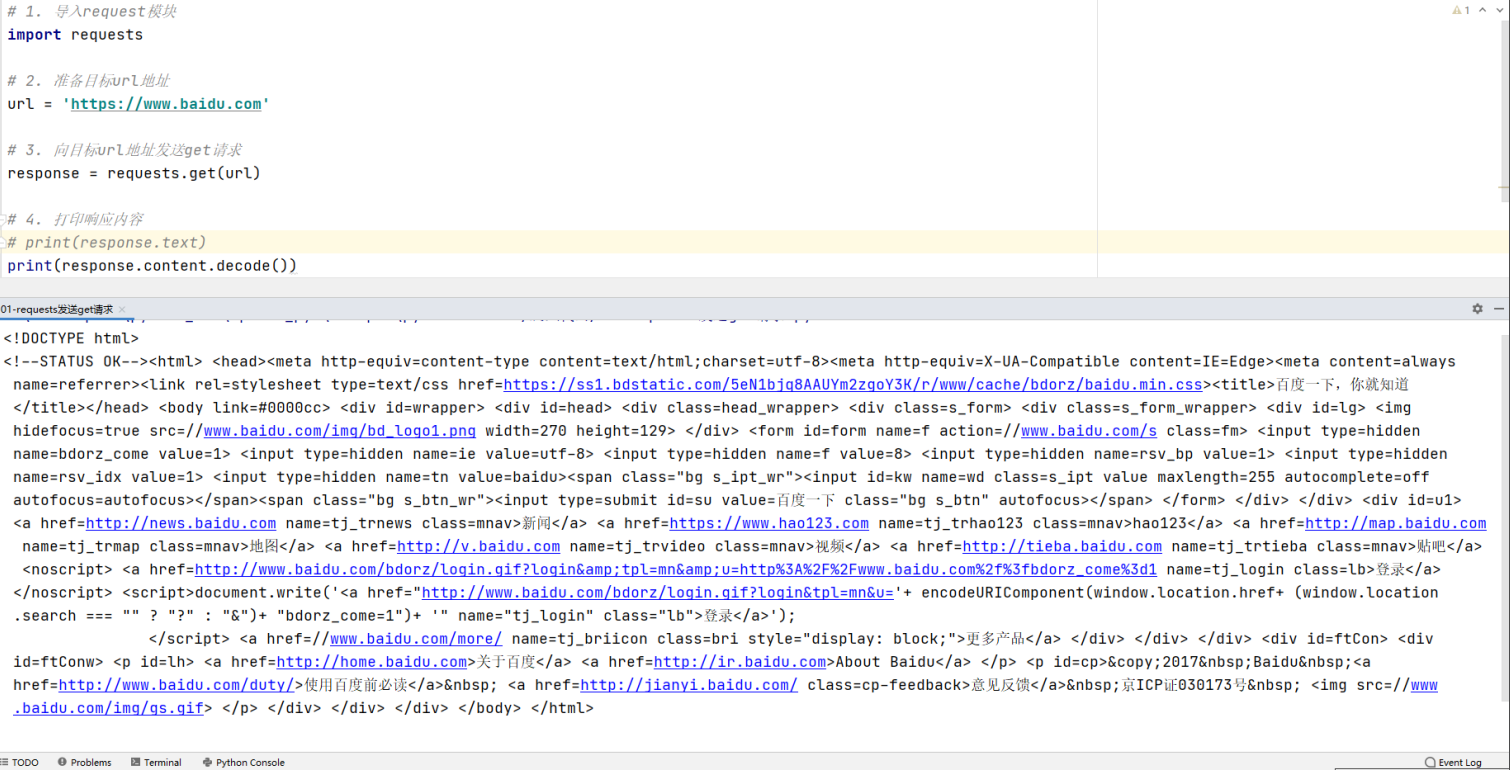
# 1. 导入request模块 import requests # 2. 准备目标url地址 url = 'https://www.baidu.com' # 3. 向目标url地址发送get请求 response = requests.get(url) # 4. 打印响应内容 # print(response.text) print(response.content.decode()) # 原始响应内容,类型bytes:没有进行解码响应内容 # 注意:爬虫程序默认不会自动保存cookie,爬虫程序请求时默认也不会自动携带cookie
运行代码结果如下:
2.1 response.content 和 response.text 的区别
response.content
- 返回类型: bytes
- 解码类型: 没有指定,原始响应内容,没有进行解码
- 指定编码方式: response.content.decode('指定编码字符集')
- 注意: response.content.decode() 默认使用 utf-8 编码方式
response.text
- 返回类型: str
- 解码类型: requests 模块自动根据 HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- response.text = response.content.decode('推测出的编码字符集')
获取网页源码的方式:
- response.content.decode()
- response.content.decode('gbk')
- response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题, 推荐优先使用: response.content.decode()
2.2 response 响应对象其他属性和方法
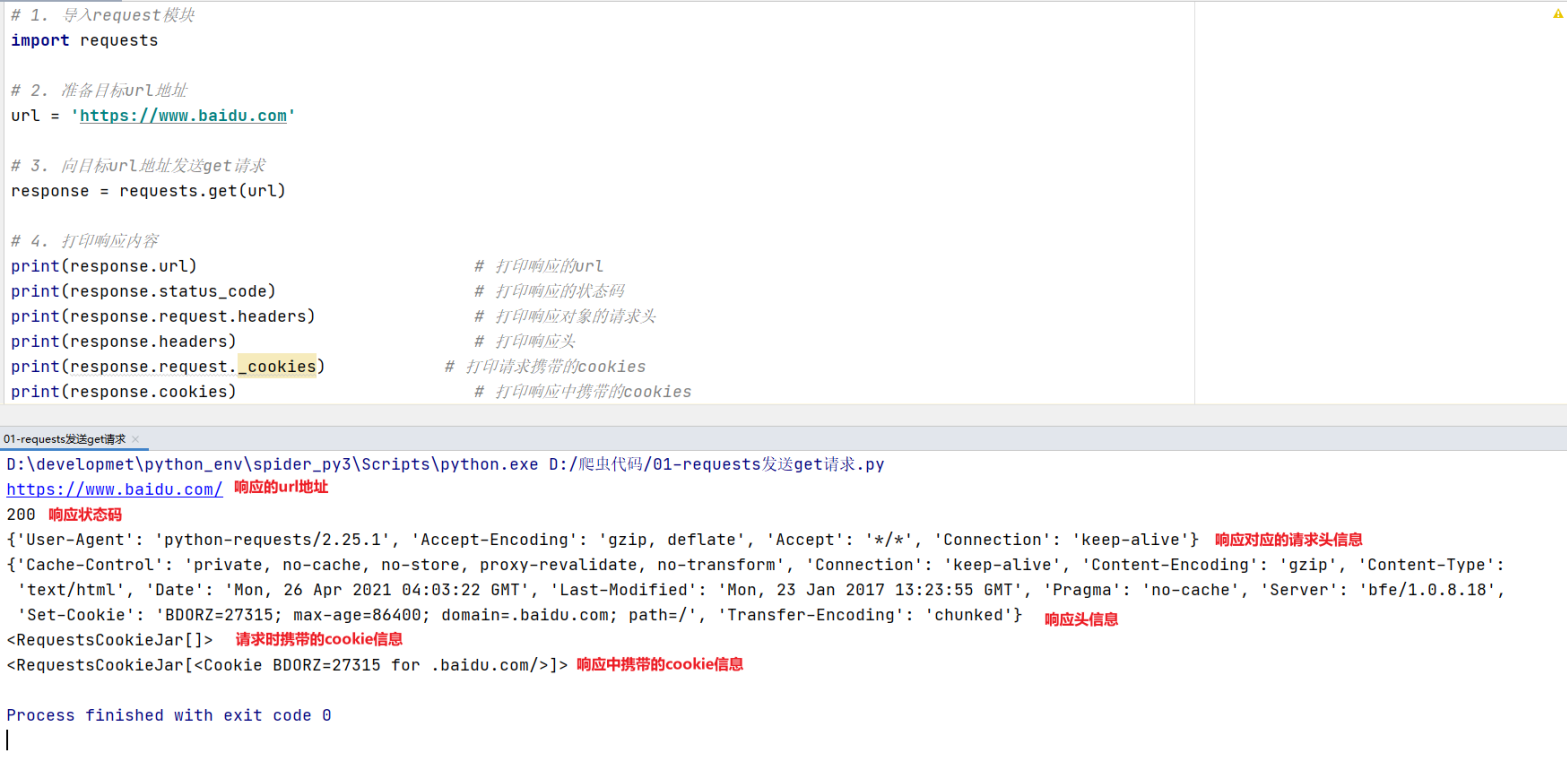
- response.url : 响应的url地址,有时候响应的 url 地址和请求的 url 地址不一样。
- response.status_code : 获取响应状态码。
- response.request.headers : 获取响应对应的请求头信息。
- response.headers : 获取响应头信息。
- response.request._cookies : 响应对应请求携带的cookie,返回cookieJar类型。
- response.cookies : 响应时设置的 cookie,返回cookieJar类型。
- response.json() : 自动将 json 字符串类型的响应内容转换为 python 对象(dict or list)。
示例代码如下:
# 1. 导入request模块 import requests # 2. 准备目标url地址 url = 'https://www.baidu.com' # 3. 向目标url地址发送get请求 response = requests.get(url) # 4. 打印响应内容 print(response.url) # 打印响应的url print(response.status_code) # 打印响应的状态码 print(response.request.headers) # 打印响应对象的请求头 print(response.headers) # 打印响应头 print(response.request._cookies) # 打印请求携带的cookies print(response.cookies) # 打印响应设置的cookies
示例代码运行结果如下:
2.3 练习-保存网络图片
需求: 将图片https://i-blog.csdnimg.cn/direct/d145c8acdfac46f0bf9ab2c9316c22e0.png 保存到本地。
思考:
- 以什么方式打开文件。
- 保存什么格式的内容。
分析:
- 图片的url地址: https://i-blog.csdnimg.cn/direct/d145c8acdfac46f0bf9ab2c9316c22e0.png
- 利用 requests 模块发送请求,获取到图片的响应。
- 以二进制的方式打开文件,并将 response 响应的二进制内容写入到文件。
完整代码如下:
# 1. 导入request模块 import requests # 2. 准备目标url地址 url = 'https://i-blog.csdnimg.cn/direct/d145c8acdfac46f0bf9ab2c9316c22e0.png' # 3. 向目标url地址发送get请求 response = requests.get(url) # 4. 打开文件,将数据写入到文件中 with open('itcast.png', 'wb') as f: # 写入响应内容的二进制数据 f.write(response.content)代码运行结果如下:
图片已保存在同一目录下。
2.4 练习-保存多张网络图片
需求: 将网页中的图片保存到本地。
地址:https://www.tupianzj.com/meinv/20210219/224797.html
思考:
- 以什么方式打开文件。
- 保存什么格式的内容。
分析:
- ① 先请求 https://www.tupianzj.com/meinv/20210219/224797.html,获取响应内容
- ② 从上一步的响应内容中提取所有图片的地址
- ③ 遍历每一个图片地址,向每个图片地址发送请求,并将响应的内容保存成图片文件
完整代码如下:
import re import requests # 思路 # ① 先请求 https://www.tupianzj.com/meinv/20210219/224797.html,获取响应内容 # ② 从上一步的响应内容中提取所有图片的地址 # ③ 遍历每一个图片地址,向每个图片地址发送请求,并将响应的内容保存成图片文件 # ① 先请求 https://www.tupianzj.com/meinv/20210219/224797.html,获取响应内容 url = 'https://www.tupianzj.com/meinv/20210219/224797.html' # 发送请求 response = requests.get(url) # 获取响应的内容 html_str = response.content.decode('') HTML1 = response.text print(html_str) print(HTML1) # ② 从上一步的响应内容中提取所有图片的地址 image_url_list = re.findall('
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







