
RAGFlow从理论到实战的检索增强生成指南

目录
前言
一、RAGFlow是什么?为何需要它?
二、RAGFlow技术架构拆解
三、实战指南:从0到1搭建RAGFlow系统
步骤1:环境准备
步骤2:数据接入
步骤3:检索与生成
四、优化技巧:让RAGFlow更精准
五、效果评估:如何衡量RAGFlow性能?
六、未来展望:RAGFlow的进化方向
前言
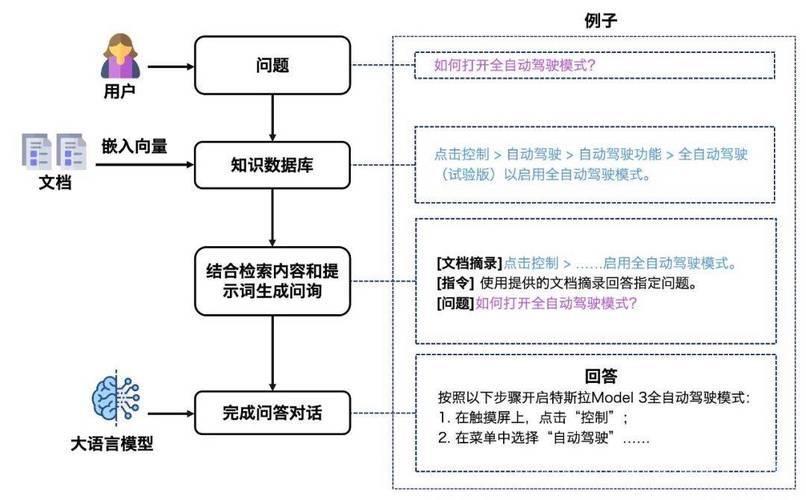
在AI大模型时代,如何让LLM(大型语言模型)摆脱“幻觉”并输出可信内容?答案藏在RAG(检索增强生成)技术中,而RAGFlow作为开源框架,正成为企业级知识检索的核心工具。本文将带你从零开始掌握RAGFlow的核心逻辑与实战技巧。
一、RAGFlow是什么?为何需要它?
定位:基于深度文档理解的开源RAG框架,专为解决大模型知识更新滞后、专业领域回答不准确等问题设计。
核心优势:
(图片来源网络,侵删)
- 多模态解析:支持PDF/Word/图片/扫描件等格式,通过OCR+布局分析还原文档结构。
- 深度语义检索:结合BM25+向量检索,支持段落级、表格、公式等细粒度内容召回。
- 企业级适配:提供API接口、批量处理、权限控制,适配私有化部署场景。
二、RAGFlow技术架构拆解
- 文档解析层
- 智能切片:将长文档按语义分段(如章节、段落),避免传统分块导致的上下文断裂。
- 多模态处理:
- 公式识别:通过Mathpix或LaTeX解析数学内容。
- 表格解析:提取表头、数据关系,支持跨页表格合并。
- 图片OCR:识别图表中的文字与结构化信息。
- 向量存储层
- 双引擎架构:
- 稀疏检索(BM25):快速定位关键词相关文档。
- 稠密检索(向量数据库):如Milvus、Pinecone,捕捉语义相似性。
- 混合索引:结合文档级、段落级、实体级索引,提升召回率。
- 检索增强层
- 动态重排:基于RRF(倒数排名融合)算法,合并多检索器结果。
- 上下文优化:自动截断冗余内容,保留关键上下文(如前文段落+当前问题相关内容)。
- 生成层
- Prompt工程:注入检索到的文档片段,指导LLM生成回答。
- 引用溯源:输出结果附带原文引用,增强可信度。
- 双引擎架构:
三、实战指南:从0到1搭建RAGFlow系统
步骤1:环境准备
bash
# 安装依赖 pip install ragflow langchain pymilvus transformers # 启动向量数据库 docker run -p 19530:19530 --name milvus milvusdb/milvus
步骤2:数据接入
python
 (图片来源网络,侵删)
(图片来源网络,侵删)from ragflow import DocumentParser # 解析PDF并切片 parser = DocumentParser() docs = parser.parse("research_paper.pdf", chunk_size=512, overlap=32) # 存储到Milvus from pymilvus import connections, Collection connections.connect(host="localhost", port="19530") collection = Collection("ragflow_docs") collection.insert(docs.embeddings) # 假设已生成向量步骤3:检索与生成
python
from ragflow import RAGPipeline # 初始化RAG流程 rag = RAGPipeline( retriever="bm25+milvus", # 混合检索 llm="gpt-3.5-turbo", top_k=5 # 检索前5个相关片段 ) # 执行查询 response = rag.query("量子计算的最新进展是什么?") print(response.generated_text) print(response.citations) # 输出引用来源四、优化技巧:让RAGFlow更精准
- 查询扩展(Query Expansion)
- 同义词替换:将“AI”扩展为“人工智能、机器学习、深度学习”。
- 实体识别:提取查询中的关键实体(如“Transformer架构”)并强化检索权重。
- 结果重排(Reranking)
- 使用Cross-Encoder模型对初始检索结果二次评分,过滤低相关片段。
- 混合检索(Hybrid Search)
- 结合稀疏+稠密检索:
python
hybrid_retriever = HybridRetriever( sparse_retriever=BM25Retriever(), dense_retriever=DenseRetriever(model="bge-large-en") )
- 动态分块(Dynamic Chunking)
- 根据文档类型调整分块策略:
- 论文:按章节分块
- 合同:按条款分块
- 代码:按函数/类分块
- 根据文档类型调整分块策略:
- 结合稀疏+稠密检索:
五、效果评估:如何衡量RAGFlow性能?
指标 计算方法 目标值 召回率(RR@K) 检索结果中包含正确答案的比例(K=5,10) ≥85% 准确率 生成答案与标准答案的重叠度(ROUGE-L) ≥0.6 引用覆盖率 输出结果中附带引用来源的比例 ≥90% 延迟 端到端响应时间(含检索+生成) - 文档解析层
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







