
爬虫--以爬取小说为例

目录
一、每日一言
二、练习题
三、效果展示
四、下次题目
五、总结
一、每日一言
好好的准备,写一个博客来提升质量,希望大家能够共同进步,可能每一个人都会有的状态,就是可能任务完成的并不是很好;
但是学习,在大学学校这件事一个重要的是,你不要花时间又没有效果,不要玩没有玩开心,学也没有学好;我知道你每天花时间,但是你的效率不高,明白的知识点没有深入,不是喜欢反思;所以一定要学会总结,最好把今天的事情和进步记录下来,这样你可以得到一个正向的反馈,同时你可以进一步的去发现你的困难,战胜困难时一件很爽的事情,所以一定要求去积极的克服,好好利用要求资源。
正确的学习:方向、效率、目标、计划
所以要提升专注力,去把心思放在重点上,为你的人生负责,一定休息,娱乐不是罪恶的,劳逸结合,好好利用该学的时候,一定要学好,多花时间搞懂,抱着好奇心去认真的学,你一定可以。
二、练习题
爬虫的基础知识--
| 爬虫 | 一个自动上网找信息的小机器人 |
| URL | 要去的网页地址 |
| 请求网页 | 打开网页,看里面有什么内容 |
| 提取数据 | 找出你想要的信息 |
| 保存数据 | 把信息记录下来,以后可以用 |
常见的库
requests-----打开网页,获取内容
BeautifulSoup------在网页里找需要的文字
time-----控制爬虫速度,让程序休息
os--------创建文件夹、管理文件
open()-------把内容保存到 txt 文件里
一、requests:上网员 —— 去网上“下载”网页内容
📌 它是做什么的?
想象一下你要看一个网页,比如百度首页或者一本小说的页面。
如果你用浏览器打开它,其实就是你的电脑向服务器发出一个“我要看这个网页”的请求,然后服务器就把网页的内容发给你。
requests 就是 Python 中专门负责“发送请求”和“接收网页内容”的工具。
你可以把它理解为一个会自动帮你打开网页的“机器人”,但它不会显示网页,而是把网页的内容直接保存下来。
🔍 举个生活中的例子:
你让同学帮你去图书馆拿一本书,他去了之后把书的内容一页页拍照发给你。
👉 在这里,“同学”就是 requests,他替你完成了“去拿书”的任务,并把内容带回给你。
✅ 它能做什么?
- 发送请求,获取网页的 HTML 源码
- 下载图片、文件等资源
- 支持各种类型的请求(GET、POST 等)
🔍 二、BeautifulSoup:分析员 —— 从网页中“提取”你需要的信息
📌 它是做什么的?
当你拿到网页的内容后,你会发现那是一大段看起来很乱的文字,里面有很多标签、样式、脚本等等。
这些内容虽然对计算机有意义,但对我们人来说很难直接读。
这时候就需要 BeautifulSoup 来帮忙了。
它的作用是从这堆杂乱的网页代码中找出你真正需要的部分,比如:
- 标题
- 正文内容
- 图片链接
- 所有章节的链接列表
你可以把它理解为一个“信息筛选器”或“内容提取器”。
🔍 举个生活中的例子:
你有一本厚厚的字典,想找“苹果”这个词的解释。
你不可能一页一页翻着找,所以你学会了用目录、索引、关键词查找的方法。
👉 BeautifulSoup 就像那个“查找关键词”的高手,帮你快速找到你想要的内容。
✅ 它能做什么?
- 解析 HTML 或 XML 文档
- 提取特定标签中的内容(如
、、
)
- 查找具有特定属性的元素(如 id="content")
- 获取所有符合条件的元素(如所有章节链接)
🤝 三、它们是怎么配合工作的?
我们可以把整个过程分成三个步骤:
第一步:用 requests 请求网页内容
就像让机器人去网站上“访问”这个页面,然后把整个页面的内容带回来。
第二步:把内容交给 BeautifulSoup
让它进行解析,找出结构。
第三步:使用 BeautifulSoup 的方法,提取你感兴趣的数据
比如标题、正文、图片链接、章节列表等。
打开命令提示符(Windows)或终端,输入以下命令:
python --version
这个命令可以查看python的版本。
环境----
🛠️ 常见的环境管理工具
工具名
特点
venv
Python 自带的环境管理工具,适合初学者
conda
Anaconda 自带的工具,适合做数据分析和机器学习
刚开始可以直接在默认的环境,安装requests库 和 BeautifulSoup 库,
Win+R打开运行对话框,输入 CMD 回车,输入下面的命令,等待安装。
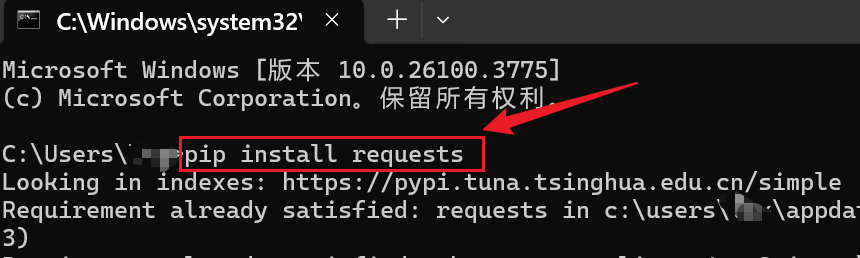
安装requests库
pip install requests
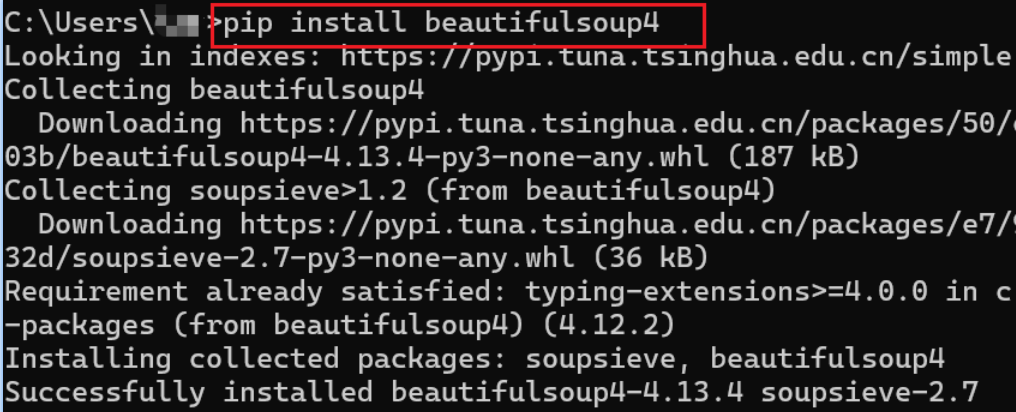
安装beautifulsoup4
pip install beautifulsuop4
如果下载嫌慢,可以使用镜像源
🔍 常见的国内镜像源(你知道几个?)
镜像源名称
地址
清华大学镜像站
Simple Index
阿里云镜像站
Simple Index
豆瓣镜像站
Simple Index
华为云镜像站
https://mirrors.huaweicloud.com/repository/pypi
方法一:临时使用(每次手动指定)
你只需要在 pip install 后面加上 -i 参数,指定你要使用的镜像源地址:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
方法二:设置默认镜像源(以后都走这个“商店”)
- 找到或创建 pip 的配置文件:
- 路径一般是:C:\Users\你的用户名\pip\pip.ini
- 如果没有这个文件,就新建一个。
- 把下面这段内容复制进去:
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple
文件位置因人而异,例如我的在
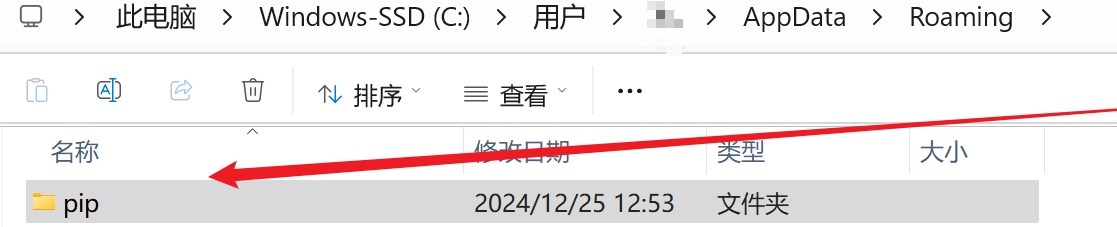


好了,开始写我们的代码吧。
浏览器打开小说主页,右键检查或者F12,
状态码为200,既可以访问
1xx:信息性状态码
这些状态码表示临时响应,通常用于告知客户端服务器已收到请求,但尚未完成处理。
-
100 Continue:服务器已收到请求头,客户端可以继续发送请求体。
-
101 Switching Protocols:服务器根据客户端的请求切换协议。
-
102 Processing:服务器已收到请求,正在处理中(WebDAV 协议)。
2xx:成功状态码
这些状态码表示请求已成功处理。
-
200 OK:请求成功,服务器返回了请求的资源。
-
201 Created:请求成功,服务器创建了新的资源。
-
202 Accepted:请求已接受,但尚未处理完成。
-
204 No Content:请求成功,但没有返回内容。
-
206 Partial Content:请求成功,返回部分内容(支持范围请求)。
3xx:重定向状态码
这些状态码表示客户端需要采取进一步操作才能完成请求。
-
301 Moved Permanently:请求的资源已永久移动到新的 URL。
-
302 Found:请求的资源临时移动到新的 URL。
-
304 Not Modified:请求的资源未修改,客户端可以使用缓存版本。
-
307 Temporary Redirect:请求的资源临时移动到新的 URL,但方法和实体不变。
-
308 Permanent Redirect:请求的资源已永久移动到新的 URL,但方法和实体不变。
4xx:客户端错误状态码
这些状态码表示客户端请求有误,服务器无法处理。
-
400 Bad Request:请求格式错误,服务器无法理解。
-
401 Unauthorized:请求需要用户认证。
-
403 Forbidden:服务器拒绝请求,即使提供认证也无法访问。
-
404 Not Found:请求的资源未找到。
-
405 Method Not Allowed:请求方法不被允许。
-
408 Request Timeout:请求超时。
-
429 Too Many Requests:客户端发送的请求过多,触发了限流机制。
5xx:服务器错误状态码
这些状态码表示服务器内部错误,无法正常处理请求。
-
500 Internal Server Error:服务器内部错误,无法完成请求。
-
501 Not Implemented:服务器不支持请求的功能。
-
502 Bad Gateway:服务器作为网关或代理时,收到无效响应。
-
503 Service Unavailable:服务器暂时无法处理请求(可能因为超载或维护)。
-
504 Gateway Timeout:服务器作为网关或代理时,上游服务器超时。
-
505 HTTP Version Not Supported:服务器不支持请求的 HTTP 版本。
2. 状态码的用途
状态码的主要用途是帮助客户端理解服务器对请求的处理结果。
元素当中涉及一些网页标签知识,
W3school
可以到这里进行查看
具体的代码:
import requests from bs4 import BeautifulSoup url = "https://m.zhangyue.com/readbook/12746233/2" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0' } response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') # 找到包含正文的大容器 main_body = soup.find("div", class_="h5_mainbody") # 提取所有的段落(标签) paragraphs = main_body.find_all("p") # 把它们合并成一个字符串 content = "\n".join(p.get_text(strip=True) for p in paragraphs) with open('大学问答.txt', 'w', encoding='utf-8') as file: file.write(content)
代码解释:
嘿嘿,这是deepseek的帮助,同时我肯定有不足的地方,还希望大家指正,我建立了一个问答群,大家有兴趣,帮助别人的,或者交流学习,可以进入。
谢谢!
import requests # 导入requests库,用于从网站获取数据(就像用浏览器打开网页) from bs4 import BeautifulSoup # 导入BeautifulSoup库,用于解析网页代码(像显微镜看网页结构) # 要抓取的小说页面地址(注意:实际使用时需要确认网站允许爬取) url = "https://m.zhangyue.com/readbook/12746233/2" # 设置请求头——把自己伪装成普通浏览器访问(防止被网站识别为爬虫程序) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0' } # 发送网络请求获取网页内容(相当于在浏览器地址栏输入网址) response = requests.get(url, headers=headers) # 用BeautifulSoup解析网页HTML代码(把网页源代码变成可操作的结构化数据) soup = BeautifulSoup(response.text, 'html.parser') # ▼▼▼ 核心内容提取部分 ▼▼▼ # 在网页中找到小说正文容器(根据class名"h5_mainbody"定位,类似找特定包装的快递盒) main_body = soup.find("div", class_="h5_mainbody") # 在容器内找出所有段落(标签相当于文章的自然段落) paragraphs = main_body.find_all("p") # 合并处理:把每个段落文本提取出来,用换行符连接(像把散落的珠子串成项链) content = "\n".join(p.get_text(strip=True) for p in paragraphs) # strip=True 表示清除每段文字前后的空白字符 # ▼▼▼ 保存结果部分 ▼▼▼ # 创建/打开大学问答.txt文件('w'模式表示写入,会覆盖旧文件) with open('大学问答.txt', 'w', encoding='utf-8') as file: file.write(content) # 将提取的小说内容写入文件
注意:实际进行网页抓取时,请务必遵守网站的robots.txt规定,尊重版权和网站服务条款。本示例仅用于教学目的。
三、效果展示

许多的字符串操作,可以在实战中记忆,边练边记,一起加油,我们一定可以的,相信自己,慢慢来,但不要停下来。
四、下次题目
敬请期待!
五、总结
一切都是最好的安排
-
-
-
-
- 找到或创建 pip 的配置文件:







