
Golang基础语法

1.Golang介绍与环境搭建
1.1Golang介绍
golang又称go language简称golang, go语言是谷歌推出的一种编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。谷歌首席软件工程师罗勃派克说:‘’我们之所以开发go,是因为过去十年间软件开发的难度令人沮丧‘’。派克表示,和今天C和C++一样,go是一种系统语言。使用它可以快速开发,同时它还是一个真正的编译语言,我们之所以将它开源,原因是我们认为它已经非常有用和强大。
1)计算机硬件更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理的利用多核多CPU的优势来提升软件系统的性能。
2)软件系统的复杂度越来越高,维护成本越来越高,目前需要一个足够简洁高效的编程语言。
3)企业运行维护很多C/C++的项目,C/C++运行速度快但是编译速度却很慢。同时还存在内存泄漏等一系列困扰需要解决。
1.2Golang安装
1.官网下载SDK(运行go的前提)
2.一直下一步
1.3Windows下常用的命令
1)dir:查看当前目录下的文件列表
2) D: 进入D盘
3) MD/md/mkdir fileName :创建文件名目录
RD fileName :删除目录
4) cls :清空DOS命令窗口内容
5) copy file1 file2 :将file1的内容复制到file2中
6) cd .. :返回上级目录
7) ./ :当前目录
8) del fileName :删除文件
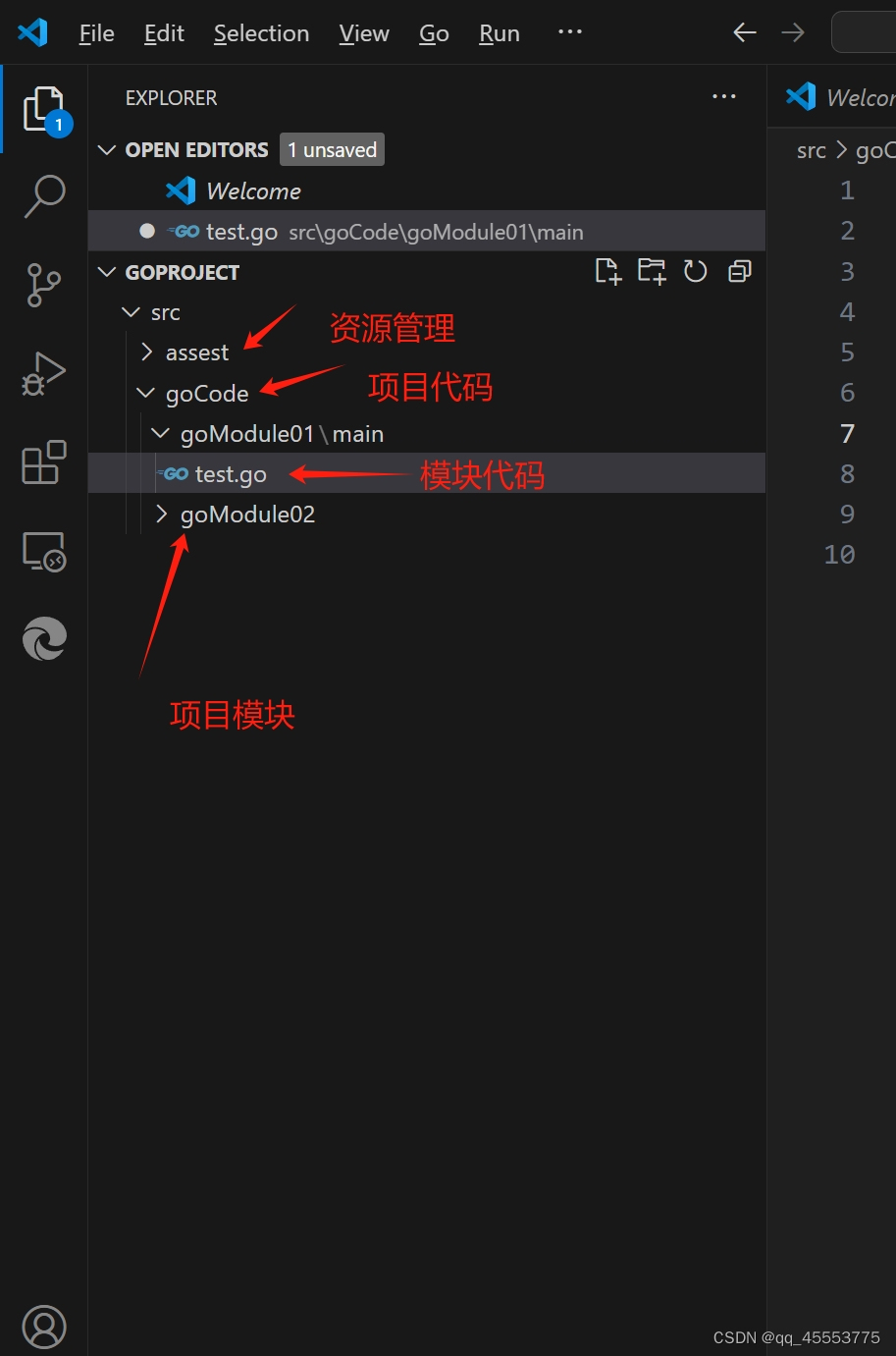
1.4Golang项目的大致目录结构
文件手动创建
1.5Golang的hello world
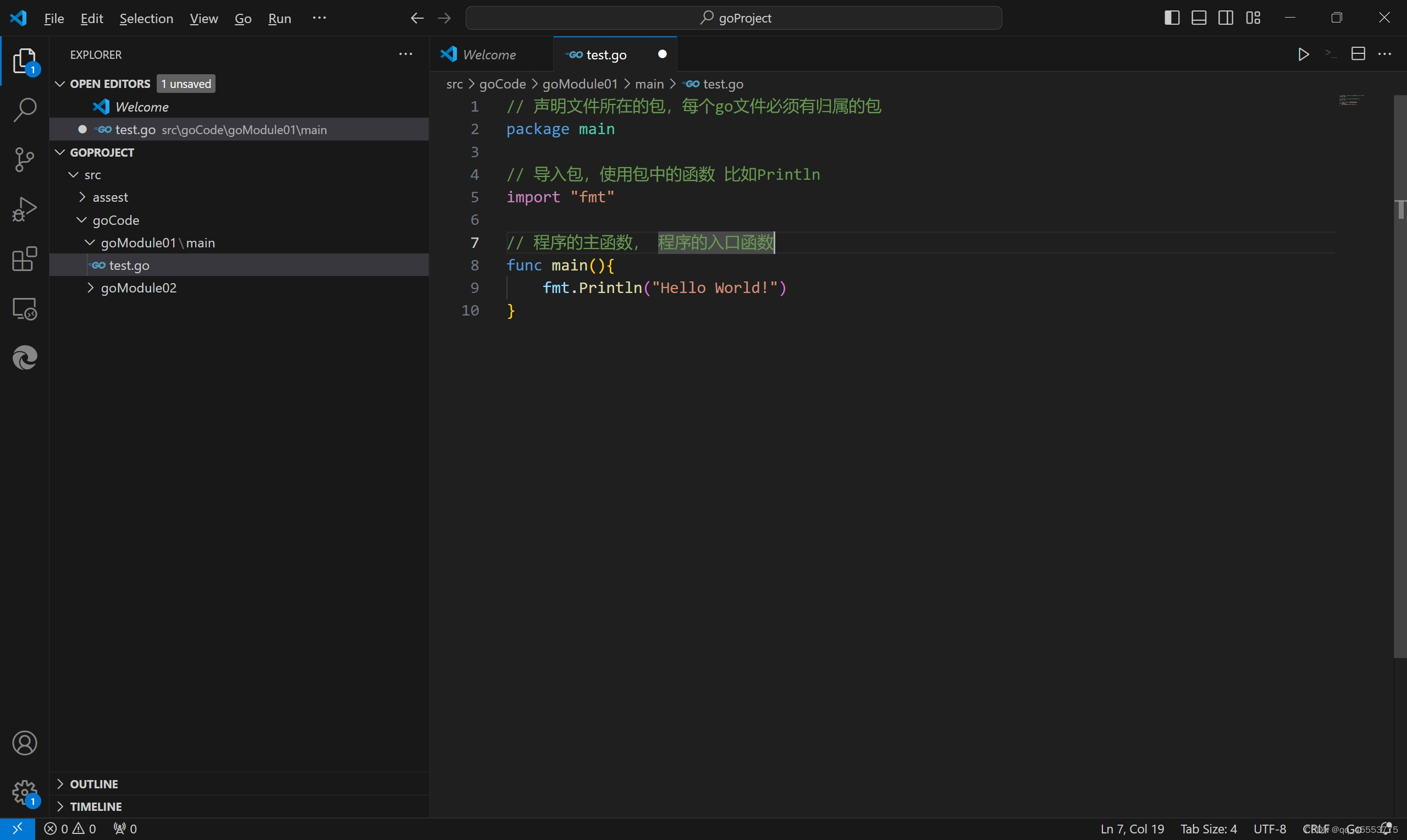
注意:
1) 在go语言里命名为main的包具有特殊的含义,Go语言的编译程序会试图把这种命名的包编译成二进制的可执行程序文件
2)所有用Go语言编译的可执行程序都必须要有一个名叫main的包
3)一个可执行程序有且只有一个main包
4)当编译器发现某一个包为main时,它一定会发现main() 函数 ,否则不会创建可执行文件
5)程序编译时,会使用声明main包代码所在目录的目录名为二进制可执行程序的文件名
6)源文件以go为拓展名
7)源文件字母严格区分大小
8)方法由语句构成,每条语句末尾不需要“;”结尾
9)go的编译器是一行一行进行编译,因此每行只能写一条语句,否则报错,或者使用';'进行隔开,但是失去代码简洁性
10)定义的变量或者import包没有使用到则编译不能通过,体验简洁性
1.6Golang的文件编译
使用命令窗口 进入主程序目录下
-
使用命令: go build test.go 在当前目录下生成test.exe二进制可执行文件
-
使用.\test.exe可运行该编译文件,或者使用go run test.go直接编译执行源文件
-
说明:编译之后生成的二进制可执行文件变大是因为是编译程序把程序所依赖的库文件打包编译。
-
直接go run 运行文件不可迁移至非go环境上运行,而go build之后的文件能够运行在其他环境上
-
编译时可以额外指定名字,默认使用main函数文件名,使用go build -o name.exe test.go 可指定编译后生成的二进制可执行文件的文件名
1.7前置知识
1) 缩进:
Tab键向后缩进
Shift + Tab键向后缩进
格式化命令:格式效果展示 gofmt test.go 效果写入源文件 gofmt -w test.go
Ctrl + s 保存。在vscode中会附带格式化
2)格式统一。声明函数同一行中必须要由{,以下代码是错误示范:
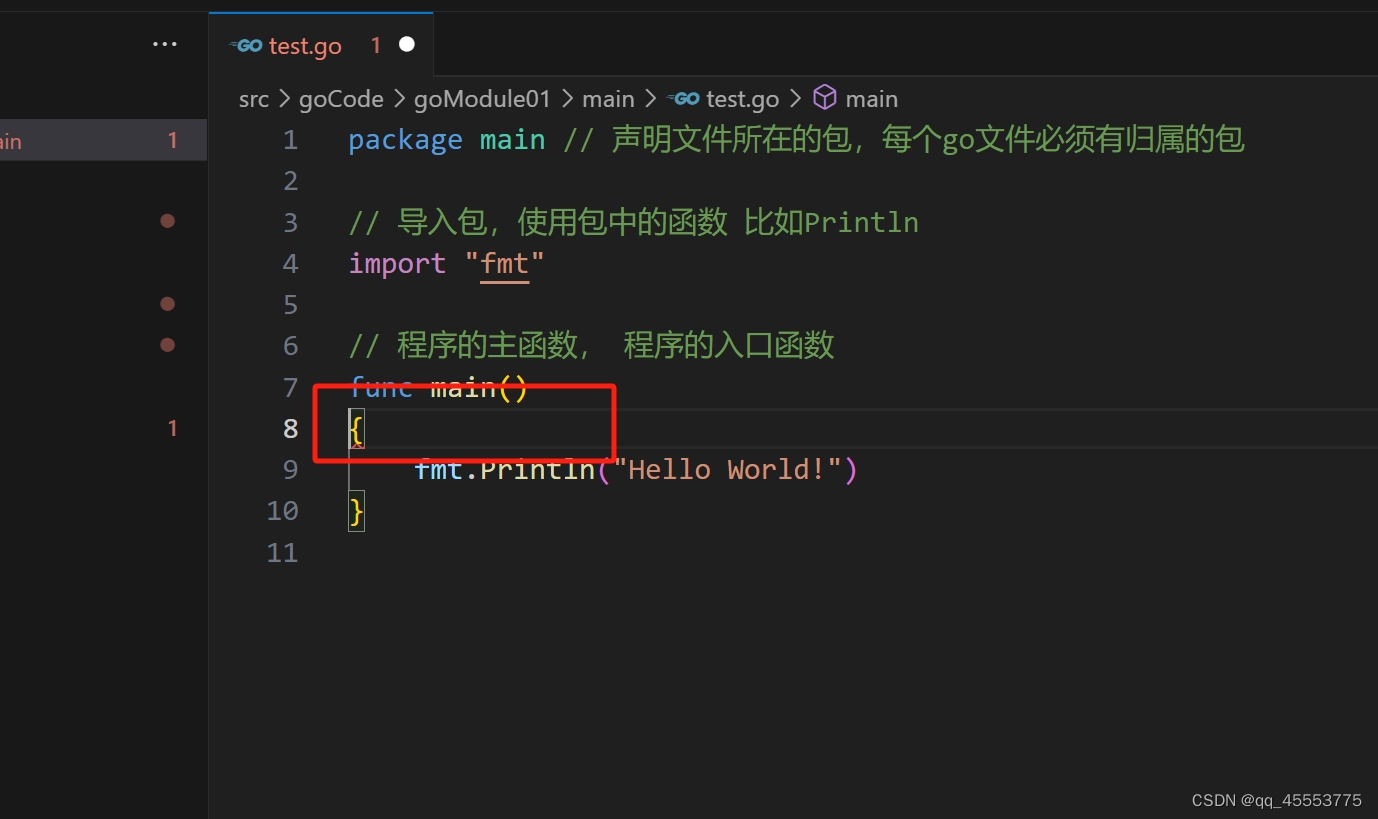
一行尽量不要超过80个字符,Println函数可以输出多个,使用‘,’进行隔开。
3)Go语言的API文档Go语言标准库文档中文版 | Go语言中文网 | Golang中文社区 | Golang中国
源码查看方式:
对应官方文档:
2.Golang的变量与运算
2.1Golang的变量
Golang是一种强制类型定义的语言。其变量类型如下:
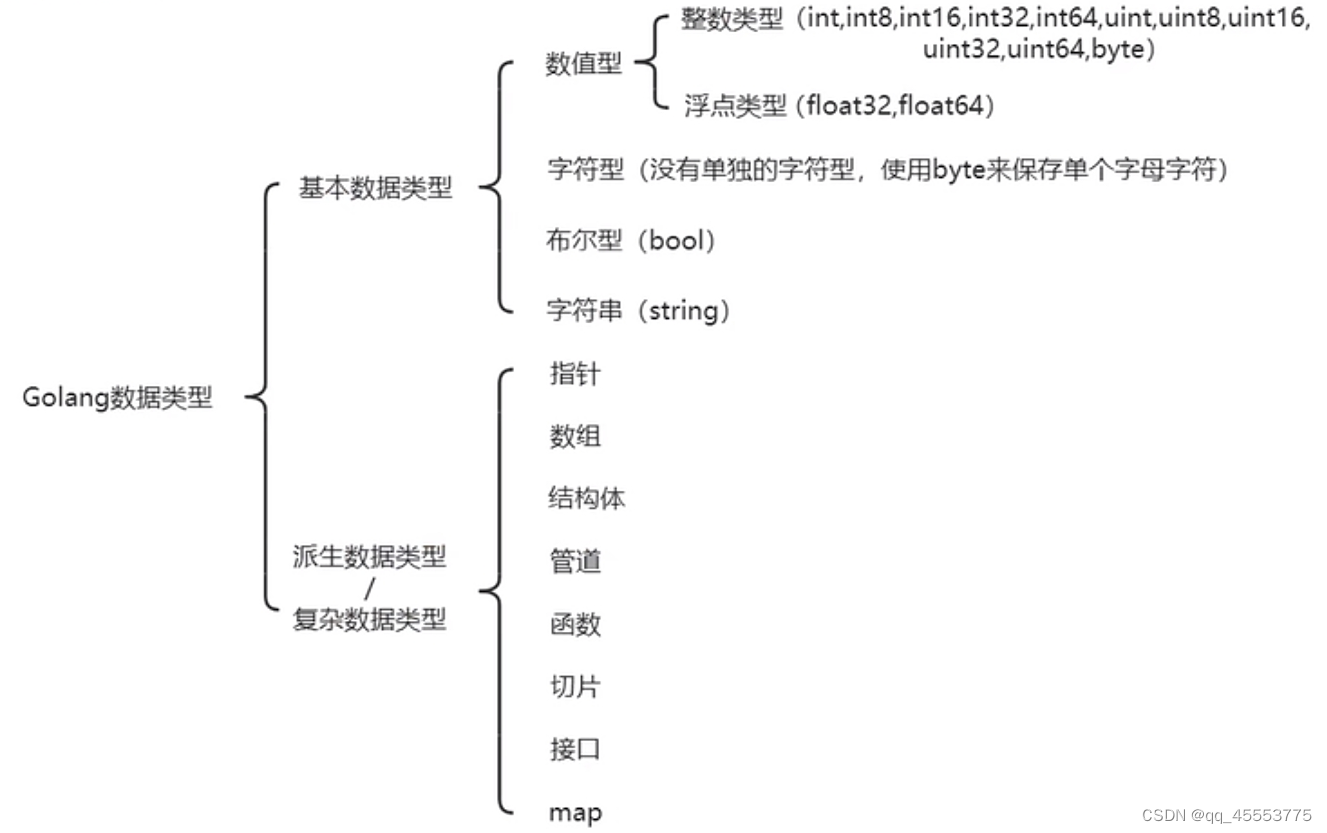
(1) 整型
| 类型 | 有无符号 | 占用存储空间 | 表示范围 |
|---|---|---|---|
| int | 有 | 32位操作系统4字节/64位操作系统8字节 | -2**31~-2**31-1/-2**63~2**63-1 |
| int8 | 有 | 1字节8位 | -2**7~2**7-1 |
| int16 | 有 | 2字节16位 | -2**15~2**15-1 |
| int32 | 有 | 4字节32位 | -2**31~2**31-1 |
| int64 | 有 | 8字节64位 | -2**63~2**63-1 |
| uint | 无 | 32位操作系统4字节/64位操作系统8字节 | 0~-2**32-1/0~2**64-1 |
| uint8 | 无 | 1字节8位 | 0~2**8-1 |
| uint16 | 无 | 2字节16位 | 0~2**16-1 |
| uint32 | 无 | 4字节32位 | 0~2**32-1 |
| uint64 | 无 | 8字节64位 | 0~2**64-1 |
注意:使用适当的变量类型能够节约内存空间
package main
import (
"fmt"
"math"
)
func main() {
// 声明int类型
var num1 int
// 、= 、 3)
fmt.Println("2=3 : ", 2 >= 3)
fmt.Println("2>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数
a = 60 # 二进制位 0011 1100
b = 13 # 二进制位 0000 1101
'''
a&b 按位与:两位都为1,结果为1,否则为0
a 0011 1100
b 0000 1101
二进制结果 0000 1100
十进制结果 12
'''
fmt.Println(a & b)
'''
a|b 按位或:只要有一位为1,结果就为1
a 0011 1100
b 0000 1101
二进制结果 0011 1101
十进制结果 61
'''
fmt.Println(a | b)
'''
a^b 按位异或:两对应的二进位相异时,结果为1
a 0011 1100
b 0000 1101
二进制结果 0011 0001
十进制结果 49
'''
fmt.Println(a ^ b)
'''
> 右边的数字指定了移动的位数
a 0011 1100
a >> 2 0000 1111
十进制结果 15
'''
fmt.Println(a >> 2)
(6) 键盘录入Scanf
可查看fmt包下的相关介绍。
package main
import "fmt"
func main() {
// 键盘录入值
var age int
var name string
fmt.Println("请录入学生的年龄:")
// 将age的地址传递给该函数,函数扫描输入传递给该地址
num1, _ := fmt.Scanln(&age) // 录入数据式类型应该匹配,底层会自动判别
fmt.Println("获取到的输入:", num1)
fmt.Printf("输入的类型:%T\n", age)
fmt.Println("输入的值:", age)
fmt.Println("请录入学生的姓名:")
// 将age的地址传递给该函数,函数扫描输入传递给该地址
num2, _ := fmt.Scanln(&name)
fmt.Println("获取到的输入:", num2)
fmt.Printf("输入的类型:%T\n", name)
fmt.Println("输入的值:", name)
// 方式2:
var age2 int
var name2 string
var score float32
var isVip bool
fmt.Println("请按照 “年龄-姓名-成绩-是否是VIP” 输入学生 年龄、姓名、成绩以及是否是VIP!")
fmt.Scanf("%d %s %f %t", &age2, &name2, &score, &isVip)
fmt.Println("输入学生信息为:年龄-", age2, ";姓名-", name2, ";成绩-", score, ";是否是VIP-", isVip)
}
3.流程控制与函数
3.1流程控制
(1) 分支结构
package main
import "fmt"
func main() {
// 单分支结构
// if (3 > 2) { go语言建议不写括号,简洁
// fmt.Println("3>2")
// }
if 3 > 2 {
fmt.Println("3大于2")
}
//双分支
if 5 == 6 {
fmt.Println("5等于6")
} else {
fmt.Println("5不等于6")
}
//多分支
if 10
(2) 循环结构
package main
import (
"fmt"
)
func main() {
// 循环结构
for i := 0; i 0 {
j -= 10
fmt.Print("\t", j)
}
fmt.Print("\n")
/*
for true {
死循环
}
*/
// 键值循环
lists := []int{1, 2, 3, 4}
for index, value := range lists {
fmt.Printf("下标%d的元素为:%d\n", index, value)
}
s := "我是中国人"
// 使用普通for循环
// for i := 0; i
(3) 控制流程 关键字
-
break: 跳出本层循环,
-
continue : 本轮循环碰到continue结束本次循环,直接跳到下次循环
-
goto:直接跳到指定行执行,不建议使用
-
return: 直接跳出当前函数
3.2函数
函数的定义语法,函数不支持重载
func functionName(parameter1 type1,parameter2 type2...) returnType{ // 函数逻辑 return returnType }-
参数:可以是值传递也可以是引用传递。另外go语言也支持可变参数传递
-
返回值:返回值可以是单个的,也可以是多返回值
-
一等公民:go语言中的函数作为一等公民可以被当作变量一样被传递,被赋值、被当作参数传递给函数、被当作返回值返回
-
函数名:函数名首字母不能是数字,若是大写字母可以被外部包引用,若是小写则是私有的不能被外部引用
函数作用:提高代码的复用性
package main import "fmt" func main() { // 求和函数 a := 10 b := 19 fmt.Println(sum(a, b)) fmt.Println("===========") //交换两数需要传递引用类型 n1 := 10 n2 := 80 fmt.Printf("调用函数前 a:%d \t b:%d \n", n1, n2) exchange(&n1, &n2) fmt.Printf("调用函数后 a:%d \t b:%d \n", n1, n2) fmt.Println("===========") l, s := multSum(1, 2, 4, 5, 6) fmt.Println("共有:", l, "个数;\t 总和:", s) myfunc("占山", "为王", 12, 22, "李四") fmt.Println("===========") fun := myfunc fmt.Printf("fun对应的类型%T,以及函数对应的类型:%T\n", fun, myfunc) reFunc := feedBack(100, callFunc) reFunc() fmt.Println("===========") // 起别名 type myInt int var x1 myInt = 10 var x2 int = 10 // fmt.Println("x1==x2?",x1==x2) fmt.Println("x1==x2?", x1 == myInt(x2)) type myfunction func(string, ...interface{}) var myfunct myfunction = callFunc feedBack(100, myfunct)() } // 对返回值直接命名 func sum(x int, y int) (sum int) { sum = x + y return } func exchange(num1 *int, num2 *int) { temp := *num1 *num1 = *num2 *num2 = temp } func multSum(Samples ...int) (int, int) { sum := 0 l := 0 for k, value := range Samples { l++ sum += value fmt.Printf("第%d个元素值:%d\n", k, value) } return l, sum } // 任意参数的传递 func myfunc(args ...interface{}) { for key, value := range args { fmt.Println("======", key, "\t", value, "=====") } } // 一等公民 func feedBack(inNum int, call func(string, ...interface{})) func() { // 返回一个匿名函数 return func() { outNum := float32(inNum + 10) call("传递输入值:%f,类型:%T", outNum, outNum) } } func callFunc(formatS string, li ...interface{}) { fmt.Printf(formatS, li[0], li[1]) }封装函数集合时,导包注意事项:
-
go文件的package声明原则上需要和go文件所在目录同名
-
引入包的过程:
1.先创建项目 go mod init moduleName
2.import “包所在的目录/包”
-
一个目录下不能有重复的函数名
-
一个目录下的go文件归属一个包
-
包的底层:
1.在程序层面,所有报名相同的源文件组成的代码块
2.在源文件层面 指的是文件夹
-
导入的包在使用时可通过别名进行使用
-
init函数:程序执行前的初始化函数,执行顺序:
初始化导入的包(包括初始化包里面的变量函数)-----》初始化包作用域变量-----》init函数------》main函数
package main import ( u "demo02/utils" f "fmt" ) var T1 func() = myFunc var T2 int = myFunc2() func myFunc() { f.Println("函数执行了") } func myFunc2() int { f.Println("函数执行了,返回10") return 10 } // 该函数会在所有包执行开始前被调用,通常用于注册程序所需要的依赖。如mysql注册和配置文件加载 func init() { f.Println("init函数被执行了!") } func main() { f.Println("main函数被执行了!") u.GetInfo() // 匿名函数,被定义时就被调用 sum := func(a int, b int) int { return a * b } f.Println(sum(99, 9)) func() { // 形参是空的,返回值也是空 f.Println("匿名函数执行===") }() //实参也是空 }闭包:匿名函数+外部数据
package main import "fmt" /* 闭包产生的条件: 1.在函数A直接或者间接返回一个函数B 2.B函数内部使用着A函数的私有变量 3.A函数要被调用且由变量接收着B形成闭包 闭包的优点: 1.延长了变量的声明周期,闭包允许函数捕获外部作用域的变量,形成一个封闭的环境,函数执行 空间不销毁,变量也不会销毁 2.保护私有变量,通过闭包我们可以访问函数的私有变量,同时保证函数的私有变量不会被外界访问 3.延迟执行,闭包可以用于延迟执行一些操作,使其在某一个特定时刻执行。需要函数执行后再执 行某些操作时非常有用 4.闭包可以用作回调函数,将特定的行为传递给其他函数。 闭包的缺点: 1.资源泄露,闭包捕获大量外部资源时,或者长时间不释放,会造成内存泄漏等问题 2.性能损耗,闭包的外部资源可能需要在内存堆上进行分配,因此会导致内存分配和垃圾回收等性能消耗 3.代码可读性,使用复杂的闭包可能降低代码的可读性 */ func getMethod() func(int) int { // 闭包所需的外部资源或者称作环境 sum := 0 // 闭包所需要的函数 return func(i int) int { // 对外部资源进行处理管理 sum += i fmt.Println("sum:", sum) return sum } } func main() { // 调用getMethod函数,将返回值赋值给f,随后结束getMethod()方法 // 但是返回值中包含sum局部变量,而被封装至匿名函数中 f := getMethod() f(1) // 1 f(2) // 3 // 重新返回一个匿名函数并附带所需要的外部资源 f1 := getMethod() f1(1) //1 f1(2) //3 }defer关键字:
声明延迟函数,能够在创建资源之后及时释放资源,会将defer声明的语句或者函数放到当前函数的栈中。
当程序执行一个函数时,会将函数的上下文(输入参数、输出参数、返回值等)作为栈帧放在程序内存的栈中,当函数执行完之后,设置返回值,然后返回调用方,此时栈帧已经退出栈,函数才算真正的执行完成。或者异常中断之后。而defer声明过的语句或者代码片段会在return 语句之后或者函数结束处执行,遵循先声明后执行的原则。另外带有return语句的函数,defer需要声明在return语句之前。
package main import "fmt" func test1() { fmt.Println("执行6==") defer fmt.Println("执行4==") return } // defer函数的传递参数在被定义时就已经明确,无论传入的时变量还是语句还是函数,在声明时就被计算确定, // 随后头插法将该_defer结构体(函数栈帧)插入链表,在最后结束时再从链表头取出延迟结构体执行。 func test2() (i int) { i = 0 defer fmt.Println("i:", i) // 被计入defer表时是0,取出表时仍然是0 i++ return } func main() { //defer 关键字 defer fmt.Println("执行1==") defer fmt.Println("执行2==") test1() defer fmt.Println("执行3==") defer fmt.Println(test2()) }常用的系统函数:
统计字符串的长度:len(str)
字符串的遍历函数:r := []rune(str) rune是int32的别名
字符串转整数:num,err := strconv.Atoi("1234")
整数转字符串:str := strconv.Itoa(1234)
查找子串是否在字符串中: b := strings.contains("golang","go")
统计字符串有几个子串:n = strings.Count("golang","g")
不区分大小写的字符串比较: b := strings.EqualFold("g","G")
返回子串在字符串第一次出现的索引值,没有返回-1:strings.Index("golang","an")
替换字符串的某些子串:strings.Replace("golanggood","go","do",n)
切割字符串:strings.Split("go-go-goo","-") 返回切割数组
字符串大小写切换:strings.ToLower() strings.ToUpper()
字符串去除左右两边的空格:strings.TrimSpace()
获取当前时间:time.Now() 返回Time结构体,Time结构体包含一些方法可以用于获取具体的成员变量
builtin包下有很多内置的函数 :
package main import ( "fmt" "strconv" "strings" "time" "unsafe" ) func main() { // 常用的字符串命令 s1 := "zhangsan" s2 := "中国二年" s3 := []byte{} fmt.Println(len(s1)) //8 英文采用ASCLL编码 每个字母占用一个字节 fmt.Println(len(s2)) //12 中文每个字符占用三字节 fmt.Println(unsafe.Sizeof(s2)) //16 这里由两个值决定了16,8字节的地址和8字节的长度 fmt.Println(unsafe.Sizeof(s3)) //24 这里由于切片的数据结构决定,首元素地址、切片长度、切片容量 fmt.Println([]rune(s1)) // 对字符串进行遍历返回切片 fmt.Println(strconv.Atoi("123")) // 将字符串装成整数 fmt.Println(strconv.Itoa(123)) // 将数字转成字符串 fmt.Println(strings.Contains("golang", "go")) // 查找字符串是否包含子串 fmt.Println(strings.Count("anbdhskjdfhj", "j")) // 查找字符串包含几个子串 fmt.Println(strings.EqualFold("Go", "gO")) //不区分大小比较字符串是否相等 fmt.Println(strings.Index("asdfghjkl", "df")) //返回子串第一次出现的下标 fmt.Println(strings.Replace("golanggood", "go", "do", -1)) //替换字符串中的某些字串 fmt.Println(strings.Split("go-go-do-good", "-")) //切割某字符串返回数组 fmt.Println(strings.ToLower("HJjkk")) // 字符串转小写 fmt.Println(strings.ToUpper("HJjkk")) //字符串转大写 fmt.Println(strings.TrimSpace(" hdghkd ")) //去除左右两边的字符空格 fmt.Println(time.Now()) //获取当前时间,返回Time结构体 fmt.Println("======================") // 特别注意rune,作为int32的别名使用。常用统计包含中文字符的字符串长度和字符串的截取 s4 := "hhhh中国" fmt.Println(len(s4)) //10 占用10个字节 fmt.Println(len([]rune(s4))) //6 总共6个字符 fmt.Println(string([]rune(s4)[2:5])) //hh中 截取下标2、3、4的字符 fmt.Println("======================") // builtin包的内置函数 // new用于分配内存使用,主要用于分配值类型(int系列、float系列、bool、string、数组和结构体) ptr := new(int) *ptr = 10 fmt.Println(*ptr) fmt.Printf("ptr类型:%T,ptr的值:%v,关联的值是:%d\n", ptr, ptr, *ptr) // make用于分配内存使用,常用于切片、map和管道的分配 ptr1 := make([]int, 9, 10) ptr1[0] = 100 fmt.Println(ptr1) }错误处理:不会轻易的结束程序运行
错误处理/错误捕获机制:使用defer+recover处理
// 使用panic抛出一个异常 func triggerPanic() { panic("a problem occurred") } // 使用recover捕获并处理异常 func recoverFromPanic() { defer func() { if r := recover(); r != nil { fmt.Println("Recovered from a panic", r) } }() triggerPanic() }自定义错误:使用errors报下的new函数自定义错误
// 函数可能会返回错误 func mightFail() error { // 如果发生错误,返回一个错误信息 if someCondition { return errors.New("some error message") } return nil // 表示没有错误发生 } // 在函数调用中检查错误 if err := mightFail(); err != nil { fmt.Println("Error:", err) }4.数组、切片和Map
4.1数组
package main import ( "fmt" ) func main() { // 数组定义 /* var 数组名 [数组大小]数据类型 数据名 := [数组大小]数据类型{num1,num1……} var 数组名 = [数组大小]数组类型{num1,num2,num3,……} */ var n1 = [3]int{1, 2, 3} var n2 = [...]int{1, 2, 3, 4, 5} var n3 = [...]int{2: 4, 3: 9} // 下标2的值为4,下标3的值为9,未定义的值默认0 fmt.Println(n1) fmt.Println(n2) fmt.Println(n3) nums1 := [5]int8{1, 2, 3, 4, 5} for i := 0; i4.2切片
对数组连续片段的引用
package main import "fmt" func main() { // 定义一个数组 nums1 := [5]int{1, 2, 3, 4, 5} // 切片 sp1 := nums1[2:4] var sp2 []int = []int{1, 2, 3} fmt.Printf("sp1的数据类型:%T\n", sp1) fmt.Printf("sp2的数据类型:%T\n", sp2) fmt.Printf("sp1的数据:%d\n", sp1) fmt.Printf("sp1的数据长度:%d\n", len(sp1)) fmt.Printf("sp1的数据容量:%d\n", cap(sp1)) /* 切片结构体: 1.切片首元素地址 2.切片长度 3.切片容量 */ fmt.Printf("sp1的数据地址:%p\n", sp1) //切片属于引用类型 可以直接使用%p进行取地址 fmt.Printf("nums1的数据地址:%p\n", &nums1) // 数组属于值类型,需要使用&去取地址 // 改变切片sp1的值,nums1的值也改变 sp1[1] = 10 fmt.Printf("nums1的数据:%d\n", nums1) // 使用make()进行切片创建,使用append()函数对切片末尾添加元素 sp3 := make([]int8, 0, 10) sp3 = append(sp3, 8, 9) sp3[1] = 10 fmt.Printf("切片sp3的类型:%T\n", sp3) fmt.Printf("切片sp3数据:%v\n", sp3) // 切片遍历同数组遍历一样 for i := 0; i注意:使用for range进行遍历时,其value值只是对元素的复制,因此不能修改值。
4.3映射(Map)
包含key-value键值对的集合,且key-value是无须的
key通常为int、string等基本类型,指针也可以作为key,另外接口、数组也可以作为key,只要是可比较的且不能改变的都能作为key
注意:只声明了map,但是内存中没有分配实际地址,因此不能使用
package main import "fmt" func main() { // 映射(map) // var map1 map[int]string // 这里只声明了map,但是内存中没有分配实际地址,因此不能使用 var map1 map[int]string = map[int]string{} // 需要进行申请 map2 := map[int]int{1: 2} //方式1 map3 := make(map[string]int) //方式2 map4 := map[[2]int]string{ //方式3 {1, 2}: "张三", {2, 3}: "李四", } fmt.Println("map4值:", map4) fmt.Println("map3值:", map3) fmt.Println("map2值:", map2) // 新增键值对 map1[1] = "张三" // 新增键值对1:"张三" // 删除键值对 delete(map2, 1) // 清空 map3 = make(map[string]int) // 直接清空 // 访问键值对 value, ok := map1[1] if ok { fmt.Println("map1[2]的值:", value) } else { fmt.Println("不存在map1[2]的值") } fmt.Println("map1[2]的值:", map1[2]) // 当不存在时使用0作为默认值 fmt.Println("map4长度:", len(map4)) // 对数组进行遍历 s := "kjasdghkiqwe" fmt.Println(getCounts(s)) } func getCounts(s string) map[string]int { res := make(map[string]int, 0) for _, char := range s { res[string(char)]++ } return res }5.Golang的“面向对象”
go语言使用结构体(struct)和接口(interface)作为对象,因此go语言基于结构体和接口实现面向对象,go语言不是面向对象语言,也不是面向过程语言,只是支持面向对象。
目的:易于数据的管理和维护,代码简洁性。
5.1结构体
结构体定义与使用:
package main import ( "demo01/model" "fmt" ) // 定义一个结构体 type Address struct { city string } type Student struct { name string age int addr Address } // 带有引用类型的声明都是传递地址,不带引用类型都是值传递 func (s Student) test1() { fmt.Println("学生测试一===") } func (s Student) test2() { s.name = s.name + "学生" } func (s *Student) test3() { s.addr.city = s.addr.city + "城市" } func test4(s Student) { s.addr.city = s.addr.city + "城市" s.age += 5 } func main() { // 实例化一个结构体 t1 := Student{"张三", 18, Address{"安徽合肥"}} fmt.Println("0t1: ", t1) t1.test1() fmt.Println("1t1: ", t1) t1.test2() fmt.Println("2t1: ", t1) t1.test3() //底层实现 (*t1).test3() fmt.Println("3t1: ", t1) test4(t1) fmt.Println("4t1: ", t1) t1.name = "李四" fmt.Println("5t1: ", t1) var t2 *Student = new(Student) (*t2).name = "王五" // go语言提供了简化的复制方式,底层自动把t2转换成(*t2) t2.age = 26 t2.addr.city = "太原市" fmt.Println("0t2: ", t2) fmt.Println("0t2: ", *t2) // 使用外部包导入 teacher1 := model.NewTeacher("张三", 68) teacher1.Show() // fmt.Println(&teacher1) }model下的包:
package model import "fmt" /* 封装的实现:某些变量采用首字母采用小写(private),某些变量首字母采用大写(public) */ /* 使用方法实现 工厂模式,类似构造函数 */ type teacher struct { name string age int } // 注意这里返回的是引用,teacher的引用而不是值类型,只有返回引用类型才能算是工厂模式 func NewTeacher(name string, age int) *teacher { // return &teacher{ // name, // age, // }c 这里会有赋值顺序的限制 return &teacher{ age: age, name: name, } } // 这里的Show首字母必须大写,否则外界无法使用 func (t *teacher) Show() { fmt.Println("当前实列数据:", t) } // 当结构体实现String()方法时,Println时会自动调用String方法 func (t teacher) String() string { return fmt.Sprintf("老师的信息包括 姓名:%v; 年龄:%v", t.name, t.age) }继承注意事项:
显示嵌入:外部实列dog需要通过dog.A来访问结构体animal的变量,如果animal结构体内的变量首字母是大写,则在由于外部dog实列能访问到A,也就是能访问到A的对外可见变量(首字母大写),如果A改成a则,外部dog实列不管animal中的变量首字母是否大写都不能访问到animal内嵌结构体,这里与声明animal的大小写无关。
type dog struct { A animal }匿名嵌入:这种嵌入方式更像继承,animal所有的变量都将是Cat的一部分,外部Cat实例可以直接访问animal的可见变量
type Cat struct { animal }另外。go语言支持多继承,但是可能导致代码混乱,当出现不同父类的包含相同命名的变量时,可使用 ‘父类.相同变量’ 区分。匿名嵌入的结构体还支持基本数据类型
type A struct{ a int b string int32 } type B struct{ c int b string int32 } type C struct{ B A string } c := C{B{1,"b",64},A{12,"张",32},"张三"} fmt.Println(c.string, c.B.b, c.A.int32)5.2接口
目的:为了定义规范、定义规则或者定义某种能力
1.一个结构体可以实现多个接口
2.接口本身不能实例化,但是可以指向实现了接口的结构体实列
3.只要是自定义数据类型都可以实现接口
4.接口之间也可以继承,一个接口可以继承多个接口
5.接口是一个引用数据类型
举个列子:
A接口: a,b方法
B接口:a,b方法
C结构体实现了a,b方法,则可以说C结构体实现了A接口和实现了B结构,所有需要A,B接口能力规范或者 规则的函数,C都能够作为参数传入,执行A,B所具备的方法。
package main import ( "demo02/model" "fmt" ) type A interface { a() } type B interface { a() } type Ainterface interface { A B Ainter() } type s struct{} func (s s) a() { fmt.Println("实现了a接口的a函数") } func (s s) Ainter() { fmt.Println("实现了Ainter接口的Ainter函数") } func main() { // 使用工厂创建类 Af := model.AnimalFactory{} A1 := Af.CreateObject("王五", 29) A1.AnimalRun() D1 := model.DogFactory{}.CreateObject("李四", 10) D1.A.AnimalRun() // 由于dog结构体采用显示嵌入,需要通过A来访问animal的实现接口。 // fmt.Println(D1) Cf := model.CatFactory{} C1 := Cf.CreateObject("张三", 10) // 接口可以指向实现了接口的结构体实列,但是自身不能实列化 var r model.Run = C1 r.AnimalRun() sport(C1) fmt.Printf("c1的类型:%T", *C1) // 接口的继承 var i Ainterface = new(s) i.a() i.Ainter() var b B = new(s) b.a() var a A = new(s) a.a() // 多态数组,可以定义一个空接口,通过空接口可以实现多种数据类型的融合数组 rs := [3]model.Run{} rs[0] = *model.AnimalFactory{}.CreateObject("动物", 0) rs[1] = *model.CatFactory{}.CreateObject("狗", 1) fmt.Println(rs) var mult []interface{} = []interface{}{"zhangsan", 10, 'c'} fmt.Println(mult) } // 函数用于接收具备特定能力(实现了接口的结构体)的变量r参数,传入的参数是实现了接口的结构体(体现出多态) // 多态参数 func sport(r model.Run) { r.AnimalRun() }model包:
package model import "fmt" type Run interface { AnimalRun() } type Factory interface { CreateObject(name string, age int) *animal } type animal struct { name string age int } /* 以下是给结构体起别名 不同于继承 type dog animal type cat animal */ type dog struct { A animal } type cat struct { animal } // 实现接口所有的方法 func (a animal) AnimalRun() { fmt.Printf("动物%v在跑:\n", a.name) } // 定义一个狗的实现接口工厂 type DogFactory struct{} func (d DogFactory) CreateObject(name string, age int) *dog { return &dog{animal{ name, age, }, } } type CatFactory struct{} func (c CatFactory) CreateObject(name string, age int) *cat { return &cat{ animal{ name, age, }, } } type AnimalFactory struct{} func (a AnimalFactory) CreateObject(name string, age int) *animal { return &animal{ name, age, } }5.3断言
目的:用于判断某个接口实列是否是是它的某一个类型 value,ok := element.(T)
语法含义:当element(变量)是T(实现了element接口的结构体)类型时,将转换成T类型并赋值给value,并把ok赋值成true
package main import ( "fmt" ) type i interface { iF() } type c struct { name string } func (c c) l() { fmt.Println("结构体c独有的函数") } type d struct { name string } func (d d) p() { fmt.Println("结构体d独有的函数") } func (d d) iF() { fmt.Println("d结构体实现了i接口") } func (c c) iF() { fmt.Println("c结构体实现了i接口") } func doIt(i i) { i.iF() v, ok := i.(c) if ok { v.l() } } func main() { // 判断接口实列是否是某一个类型 c1 := c{"展示噶"} var r i = c1 // 将c1向上转型为接口实列 v, ok := r.(c) //判断接口实列是否是d类型,如果是的化就将接口实列转换成d的实列 if ok { fmt.Printf("r是c类型,值为:%v\n", v) fmt.Printf("v的类型:%T\n", v) } else { fmt.Print("r并不是c结构体的实列") } var s interface{} = "结婚三大件哈桑" _, isString := s.(string) fmt.Println("是否是字符串:", isString) // 使用switch进行判别 // type是go语言的关键字,switch type固定用法 switch r.(type) { case c: c1 := r.(c) c1.l() case d: d1 := r.(d) d1.p() } }注意:数组和结构体都是值类型,而切片、管道、指针、映射、接口和函数都是引用类型
package main import "fmt" func Qie(a []int) { a[0] = 10 } func St(s test) { s.x = 10 } type test struct { x int y int } func main() { b := []int{1, 2, 3} fmt.Println(b) Qie(b) fmt.Println(b) t := test{1, 2} fmt.Println(t) St(t) fmt.Println(t) }6.文件操作
文件操作,os包下的type File结构体,
一般使用os包下的Open函数打开只读文件,当要写入文件时可采用os包下的OpenFile函数,os报下的File结构体,实现了io包下的一些函数接口,file结构体本身也具有一些函数,Read函数和Write函数,另外bufio包下还有一些关于利用缓存进行读写的操作。
package main import ( "bufio" "fmt" "io" "os" "syscall" ) func main() { //os // 使用os包进行读写 // 使用Open打开的文件一般只用于读取,需要写入时还需要OpenFile f, err := os.Open("./test.txt") if err != nil { fmt.Print("打开文件失败:", err) } readData := make([]byte, 24, 24) n, reErr := f.Read(readData) if reErr != nil { fmt.Print("读取文件失败:", err) } fmt.Printf("总共读取%d个字节数据:%q\n", n, readData) f.Close() // io/ioutil // 使用os包ReadFile进行读写,不需要Open再Close // re, err := ioutil.ReadFile("./test.txt") //ioutil已经被弃用 re, _ := os.ReadFile("./test.txt") fmt.Printf("总共读取%d个字节数据:%q\n", len(re), re) fmt.Printf("总共读取%d个字节数据:%q\n", len(re), string(re)) // bufio // 当文件较大时,可以采用带缓冲的,使用bufio,带缓冲的io留进行读写 bufOut := []string{} readerIn, _ := os.Open("./test2.txt") defer readerIn.Close() bfRead := bufio.NewReader(readerIn) // 当系统无法读入更多内容时候,会返回io.EOF for line, _, errBuf := bfRead.ReadLine(); errBuf != io.EOF; line, _, errBuf = bfRead.ReadLine() { fmt.Printf("line的类型是%T,内容是:%s\n", line, string(line)) bufOut = append(bufOut, string(line)) } // os包 //使用os包下的OpenFile打开一个用于写入的文件,再使用io流进行写入,这里的后面参数可以参考指导文献 wF, errF := os.OpenFile("./test3.txt", syscall.O_WRONLY|os.O_APPEND|os.O_CREATE, 0666) if errF != nil { fmt.Println(errF) } defer wF.Close() // 直接写入 // fmt.Println(bufOut) // for _, value := range bufOut { // wF.WriteString("\n") // wF.WriteString(value) // } wbF := bufio.NewWriter(wF) fmt.Println(bufOut) for _, value := range bufOut { wbF.WriteString("\n") wbF.WriteString(value) // wbF.Flush() // 将缓冲区的内容写入到底层的io.Writer,刷新缓冲流之后才算写成功 } wbF.Flush() // 将缓冲区的内容写入到底层的io.Writer,刷新缓冲流之后才算写成功 }7.协程和管道
7.1前置概念
-
CPU核心:计算机中央处理的一个单元,能够执行计算机程序指令,CPU核心包括: 算数逻辑单元(负责执行所有的算数逻辑运算)、寄存器(数据在CPU的临时中转站)、控制单元(负责协调控制指令执行过程)、缓存(提供寄存器和内存之间临时存储,减少内存访问次数)
-
单核CPU:单个核心的中央处理器,只能进行并发。
-
多核CPU:多个核心的CPU,并行处理的关键。
-
并发:同一时间段内,多个任务在轮流使用单个计算资源(通常指单核CPU),宏观上同时执行,微观上顺序执行
-
并行:一组程序或者任务按照独立异步的速度执行,多个任务有多个计算资源承担(多核CPU或者多CPU),宏观同时执行,微观上也是同时执行。
-
程序:为了完成某些任务,使用机器语言编写的一组代码的集合,程序是静态的。
-
进程:进程是指正在运行的程序,进程是资源分配的基本单位,操作系统会为每个进程实时分配一些资源比如内存、CPU和磁盘读写的通道等。
-
线程:线程是细分的进程,一个进程同一时间需要完成多个任务执行多段代码,每段代码就代表一个线程,另外说明该进程是支持多线程的。也是后端程序需要的能力(并行),线程是由操作系统进行调度的。
-
内核态:内核态是操作系统中的一种特权状态或者运行模式,在内核态下,操作系统拥有最高权限和访问资源的能力,可以执行特权指令或者直接访问硬件资源。内核态下操作系统能够对资源进行分配、管理、释放和调度。
-
用户态:用户态是操作系统中的一种较低特权级别的一种状态,这种状态下,操作系统不能使用特权指令,也不能进行CPU状态改变,只能访问自己的内存资源。不能直接访问一些硬件资源。当程序需要访问一些资源或者执行特权指令时,需要通过系统调用请求操作系统内核来完成这些操作。系统调用是一种特殊的函数调用,它会将应用程序从用户态切换至内核态,并把控制权交给操作系统内核,内核态下的操作系统会执行中断程序,并将执行的结果返回给应用程序,完成操作之后,内核会将控制权交还给应用程序,内核态切换成用户态。
-
进程切换:进程切换包括进程调度和上下文切换,用于在不同进程之间进行CPU的调度和分配,当一个进程运行时,它占用了CPU和其他资源。当操作系统需要执行其他进程时,就会发生进程切换,进程切换需要保存当前进程的上下文信息和恢复调度构建下一个进程所需的上下文信息,上下文信息包括:CPU寄存器、程序计数器、内存地址映射表、进程控制块信息和栈指针等。
-
PCB:进程控制块,操作系统为了方便进程管理,为每个进程构建的数据结构。
-
线程切换:为了减少进程切换时上下文信息量,将进程再切分成独立的任务就是线程进行调度,进程切换时只要需要切换内存寄存器,线程控制块信息等,不需要切换完整的进程地址映射。
-
栈:线程独有的,每个线程被创建时都会获得一个独立的栈空间,用于存放局部变量、函数参数和返回地址等,栈具有先进后出的特点,主要用于函数调用时的上下文管理。每个线程的栈空间有固定大小,超过这个大小就会导致栈溢出。
-
堆:堆是进程的所有线程共有的空间,通常用于动态内存分配,不同线程可以并发的访问堆,因此堆的访问需要同步控制。
-
协程:协程是微线程,又称轻量级线程,其调度在用户态上运行,协程执行时能够保持当前的上下文(如局部变量和执行点),并在适当的时候挂起,稍后从挂起的地方继续执行。因为不涉及内核资源,协程切换时上下文信息切换的较少。协程占用的内存比线程少,因此相同的条件下能够运行更多的协程。
-
Go语言的协程调度方式:Go的协程调度是非抢占式调度,基于协作的调度模型,称为M:N调度(多个协程被多个OS线程管理)
7.2 Go语言的协程
package main import ( "fmt" "sync" "time" ) func worker(n int, w *sync.WaitGroup) { defer w.Done() for i := 0; i
-
-
-







